

智能机器人概论 02 机器人传感器
机器人传感器系统传感器与执行机构
输入:传感器
内部传感器、内部执行器:保证机器人的稳定运行
外部传感器、外部执行器:决定了机器人的功能、类型及规划控制方法
内部传感器:感知机器人自身状态,典型的内部传感器有编码器、IMU、电流传感器、力/扭矩传感器等等
外部传感器:感知外部环境与环境的交互,典型的外部传感器有摄像头、LiDAR、麦克风、超声波
内部传感器
内部传感器:感知“自我”,回答机器人自己处于什么状态、位置、方向、…
外部传感器
外部传感器:感知“世界”,回答机器人周围的环境是什么样的
基于功能的传感器分类
传感器基于功能可以分成三类:感知环境你、感知本体、感知交互
传感器原理介绍
内部传感器(感知本体):运动及位姿估计
编码器(关节\轮位移)
惯性传感器(加速度计、陀螺仪)、惯性测量单元IMU
外部传感器(感知环境):环境感知建模
视觉传感器:2D相机、RGB-D
距离传感器:激光雷达、毫米波雷达
生成模型基础 02 Autoencoders
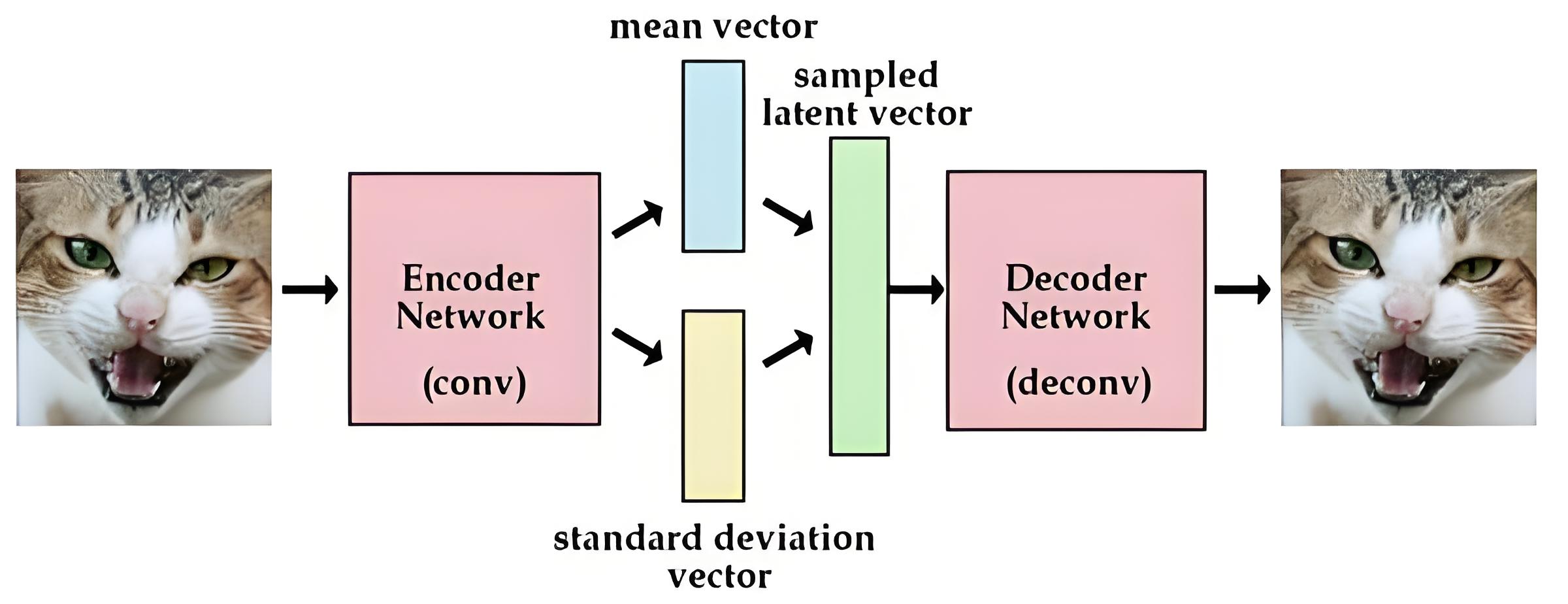
AutoencodersBasicsWhat is autoencoder?
autoencoder 是一种前馈神经网络,其功能是接收输入x并预测x
存在 Trivial (short-cut) solutions:神经网络可以学会恒等映射 𝑥 = 𝑓(𝑥),即输入为x,经过中间的神经网络后,输出也为x
Bottleneck architecture:
使用bottle neck结构:防止过拟合
可以分为encoder(编码、降维、提取特征)和decoder(解码、复原重构x)
Why autoencoder?
将高维数据映射至二维空间以实现可视化
数据压缩(降低通信成本)
无监督学习(预训练),通过加入扰动再去噪
生成模型,生成image
The simplest autoencoder(线性autoencoder)
最简结构的autoencoder包含单个具有linear activations的hidden layer
encoder通过线性投影到更小的空间,而decoder则通过线性投影还原到原来的维度,均为线性变化
...


多智能体基础 深度强化学习部分考试复习
总结版:

NLP from Scratch 自学笔记
NLP From ScratchNLP From Scratch: Classifying Names with a Character-Level RNN
我们将构建并训练一个基础的字符级循环神经网络(RNN)来实现词汇分类
字符级RNN将单词作为字符序列进行读取,在每一步输出预测结果和hidden state,并将其前一步的hidden state输入到下一个步骤。以最终的预测结果作为输出,即判断该词汇属于哪个类别
我们将使用来自18种语源的数千个姓氏进行训练,然后根据拼写来预测名字的来源语言
Preparing Torch
设置 torch 默认使用对应硬件所支持的设备(CPU 或 CUDA)以实现 GPU 加速
1234567891011121314import torch# Check if CUDA is availabledevice = torch.device('cpu')if torch.cuda.is_available(): device = torch.device('cuda')torch.set_de ...
What is torch.nn really? 自学笔记
What is torch.nn really?
PyTorch通过精心设计的模块和类——torch.nn、torch.optim、Dataset及DataLoader——来协助构建和训练神经网络
若要充分发挥其能力并针对具体问题实现定制化,就需要真正理解它们内部的运作机制
为建立这种理解,我们将首先在不使用这些模型中任何功能的情况下,在MNIST数据集上训练一个基础神经网络;初始阶段仅使用最基本的PyTorch张量功能
随后,逐步每次添加一个来自torch.nn、torch.optim、Dataset或DataLoader的功能组件,清晰展示每个部分的作用,以及它们如何使代码更简洁或更灵活
MNIST data setup
使用经典的MNIST数据集,它由手绘数字(0到9之间)的黑白图像组成
使用pathlib处理路径(属于Python 3标准库),并通过requests库下载数据集
1234567891011121314from pathlib import Pathimport requestsDATA_PATH = Path("data") ...

Visual Instruction Tuning
Visual Instruction TuningAbstract
使用机器生成的指令跟随数据对大型语言模型(LLM)进行指令微调已被证明可以提高在新任务上的零样本能力,但这一思路在多模态领域的探索较少
我们首次尝试使用仅语言的GPT-4生成多模态语言-图像指令跟随数据
通过在此类生成数据上进行指令微调,我们提出了LLaVA(大型语言和视觉助手),这是一个端到端训练的大型多模态模型,连接了视觉编码器和LLM,用于通用视觉和语言理解
为了促进未来对视觉指令跟随的研究,我们构建了两个评估基准,包含多样且具有挑战性的应用导向任务
LLaVA展示了强大的的多模态聊天能力,有时在未见过的图像/指令上表现出多模态GPT-4的行为,并在合成多模态指令跟随数据集上达到了GPT-4的85.1%相对分数
在Science QA上微调后,LLaVA与GPT-4的协同作用达到了92.53%的最新准确率
1 Introduction
社区对开发语言增强的基础视觉模型表现出浓厚兴趣,这些模型在开放世界视觉理解(如分类、检测、分割和描述)以及视觉生成和编辑方面具有强大能力
在这类工作中, ...