生成模型基础 04 Autoregressive models
Autoregressive models
Probabilistic model in high-dimensional space
概率建模,生成模型:希望采样数据分布达到真实数据类似的效果
问题:高维数据
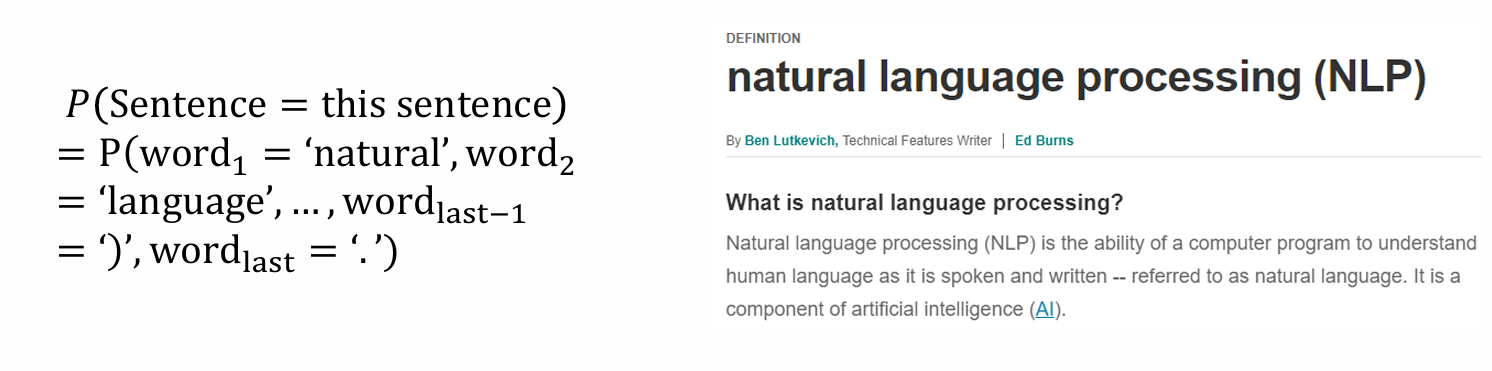
Image:sample出image = 给定image的概率为sample出每个像素概率 = 给定image概率的联合概率

- Sentence:sample出句子的概率 = 给定句子的概率等于sample出每个词的概率 = 给定每个词的联合概率
General setting
高维数据可以由一个高位向量表示:Data 𝑥 = (𝑥1,𝑥2,…,𝑥𝑑):
- Image:d表示image的大小(pixel x pixel),xi代表每个pixel的三通道RGB值
- Language:d表示句子长度,xi表示对应位置的每个词
目标:model 𝑃(𝑋 = 𝑥) -> 联合概率分布:𝑃(𝑋1 = 𝑥1,…,𝑋𝑑 = 𝑥𝑑)
可以通过条件概率的chain rule分解为条件概率密度函数的乘积:

知道条件概率分布可以反推联合概率分布 -> 建模后可以计算数据出现的概率
希望建模每个条件概率,学习模型参数θ,maximize Pθ
Different factorizations
factorization 是数据生成的顺序:
- Left-to-right factorization:从左向右逐字生成
- Right-to-left factorization:从右向左逐字生成
将image建模为序列时,可以任意方式选择条件概率顺序的路径
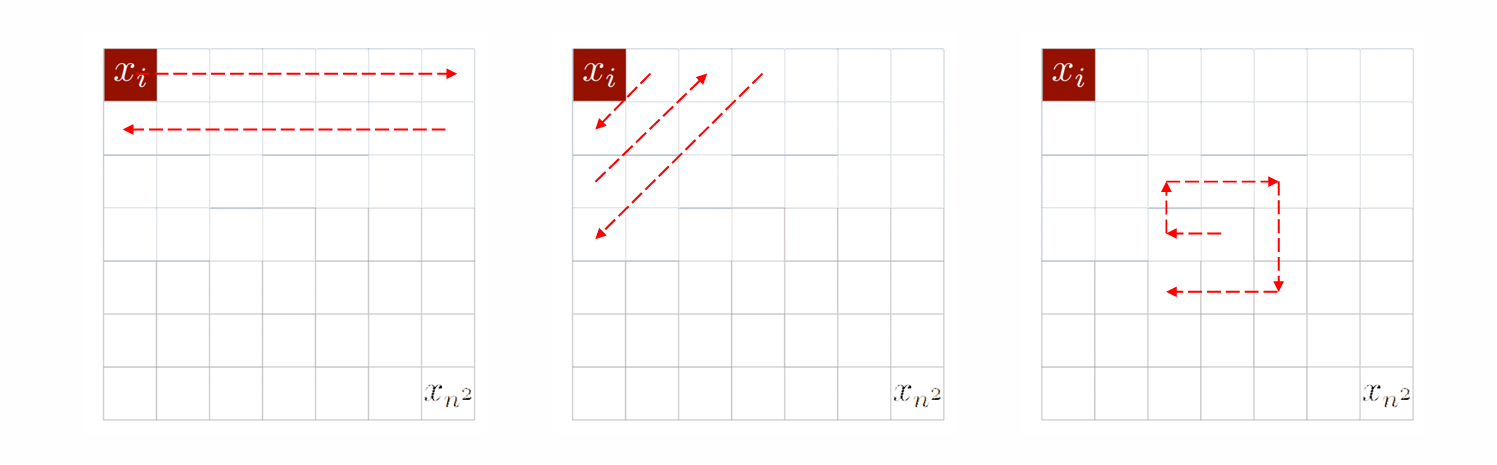
在本课中,只讨论:
- 围绕自然语言的
- 从左到右生成模式的
- 用AR建模的
具备上面三重特征的称为”language model”
研究方面:
- [Method] 如何让它对任何i都通用
- [Optimization] 如何训练它
- [Evaluation] 如何比较两个模型
- [Inference] 如何使用
自然语言处理对”language model”的定义:给定一段上下文,预测下一个token(和自回归模型定义类似)
(oldest non-parametric) N-gram language model
直接从数据进行估计,已知条件概率,不用参数,而是从统计角度”count”
“N”表示连续词语上限:
- Unigram: 只看一个词
- Bigram: 看词+相邻词
- Trigram: 看词+相邻词+前两个词
- ……

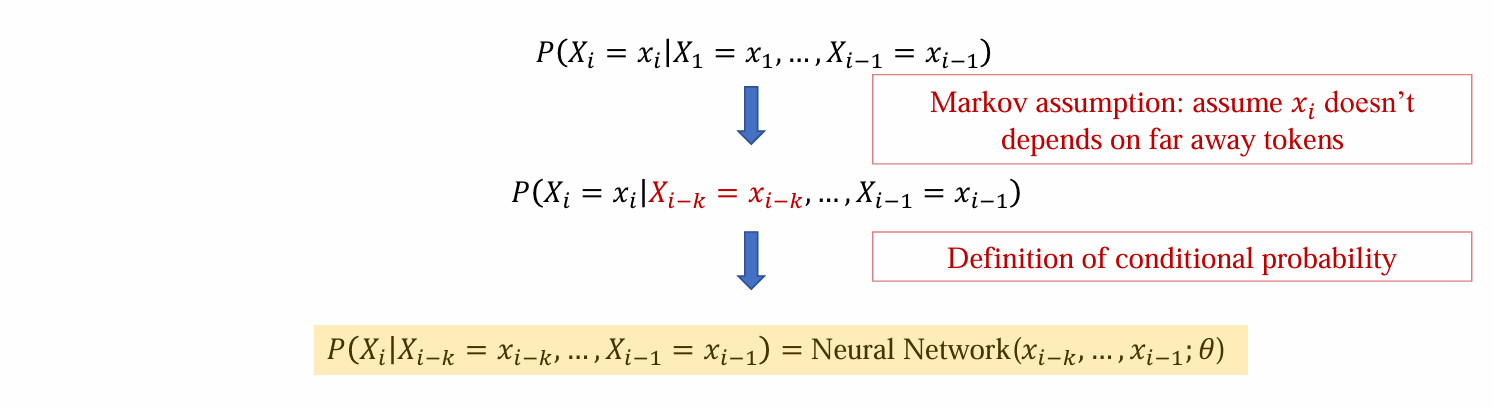
问题:当i很大的时候,需要估计当1,2,…,i-1时,i出现的概率,难度很高计算困难
解决方法:马尔科夫假设,固定当前次只和前k个词有关
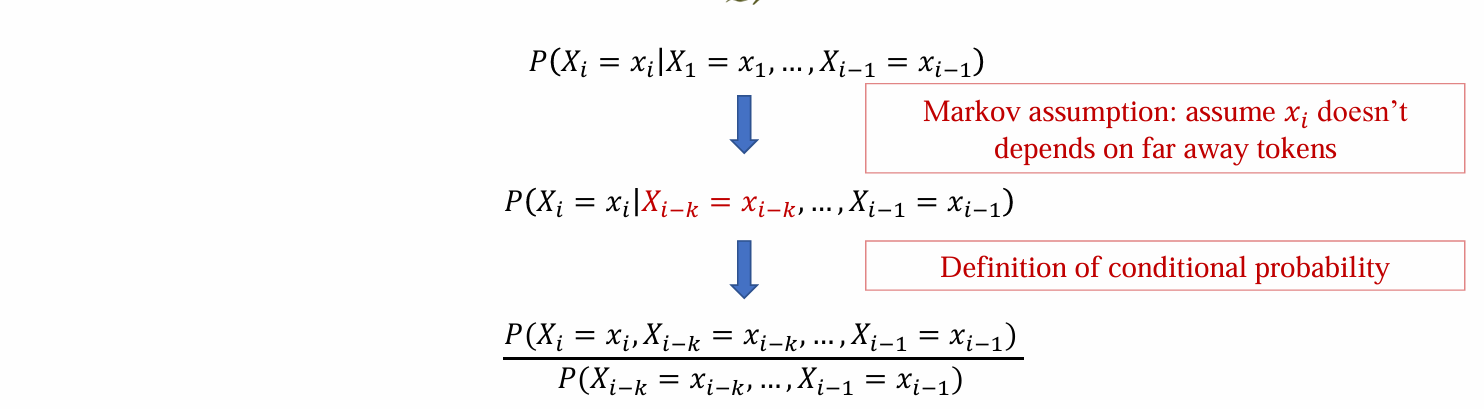
- 从而可以从数据中通过”count”方法估计:k个词片在训练数据中的频率:


- 问题:需要存储连续多个词的所有可能来计算频率,需要很大的空间,v^(n-1)
N-gram language model: example

Disadvantages of n-gram LM
Accuracy, Memory, Sparsity(稀疏性)构成了不可能三角(不可能三者同时最优)
当n增加时:Acc增加,但是需要存储空间v^(n-1)极大增加,稀疏性也增加:

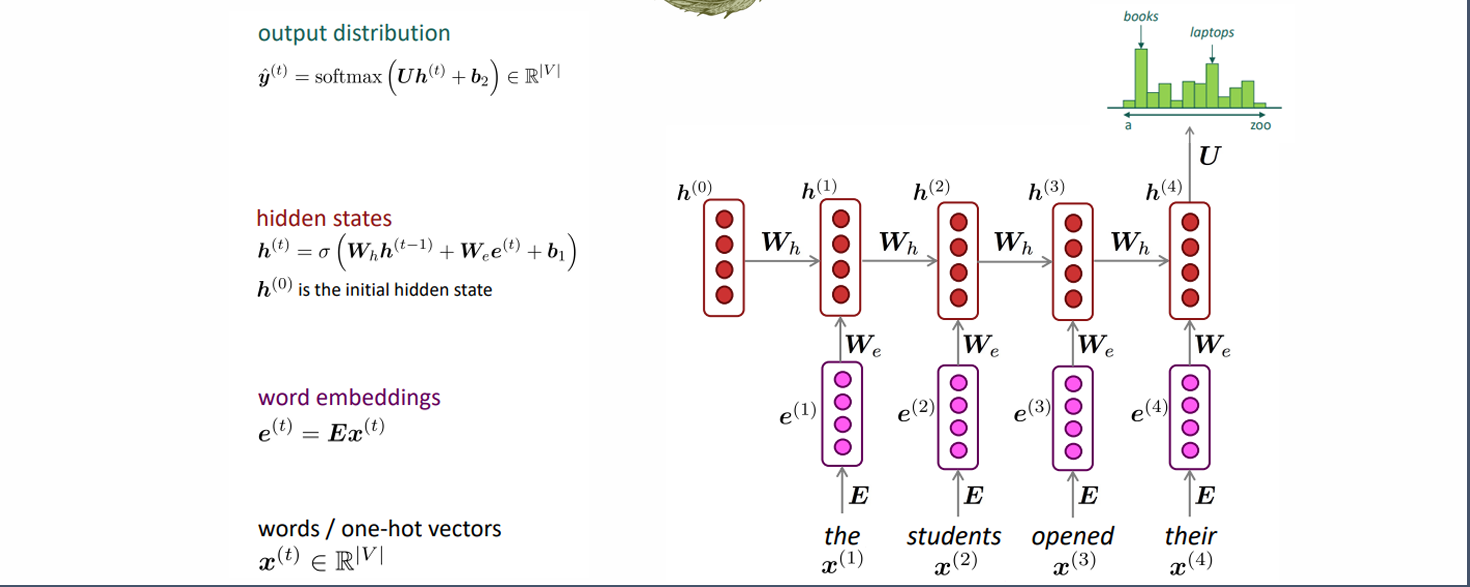
A fixed-window neural language model
和N-gram相同,window的窗口不变
和N-gram的区别:不靠count估计,而是参数化训练,依靠神经网络输出,解决了memory和sparsity问题
输入的word(one-hot vectors)首先经过查表得到需学习的embeddings
由于window size固定,因此神经网络的input size固定,可以直接放入hidden layer,随后经过softmax后进行预测
优点:
- No memory issue:Parameters = embeddings + hidden layer
- No sparsity issue
缺点:
- 窗口大小N固定
- 线性变化,效果较差
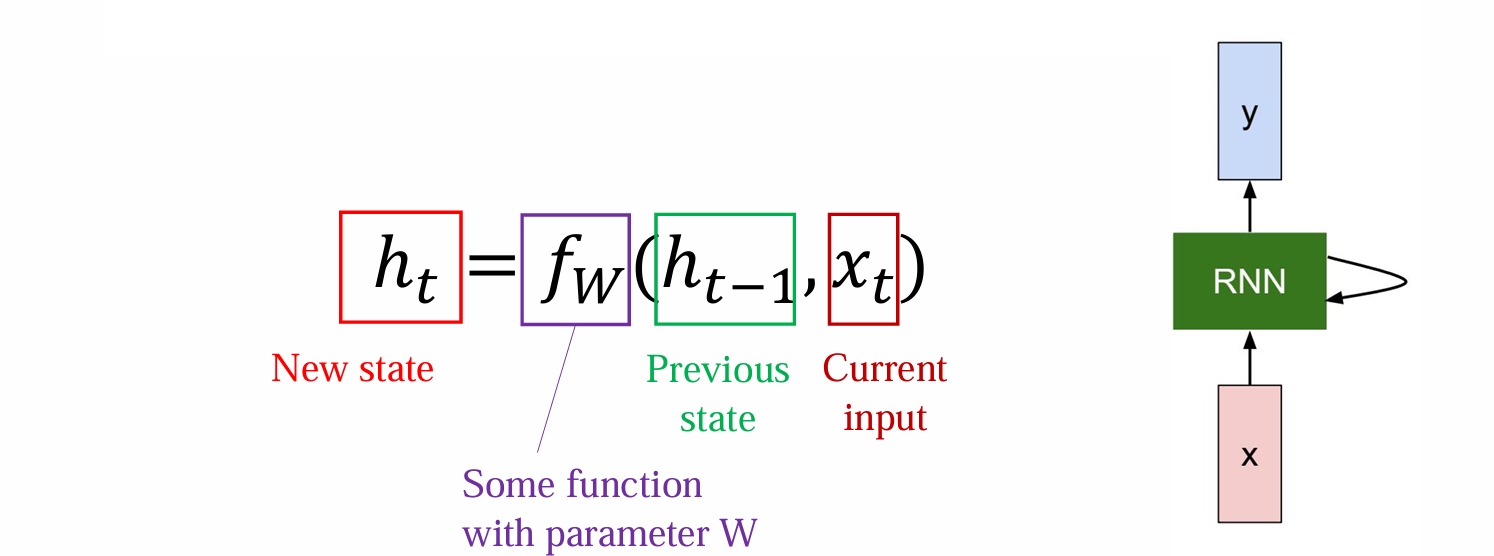
RNN-based neural language model
- 核心思想:希望有一个模块可以提取历史信息H,H需要在新的信息出现后迭代维护更新
RNN-based v.s. fixed-window model
不再受window size的限制
非线性增加,非线性次数与序列长度相关
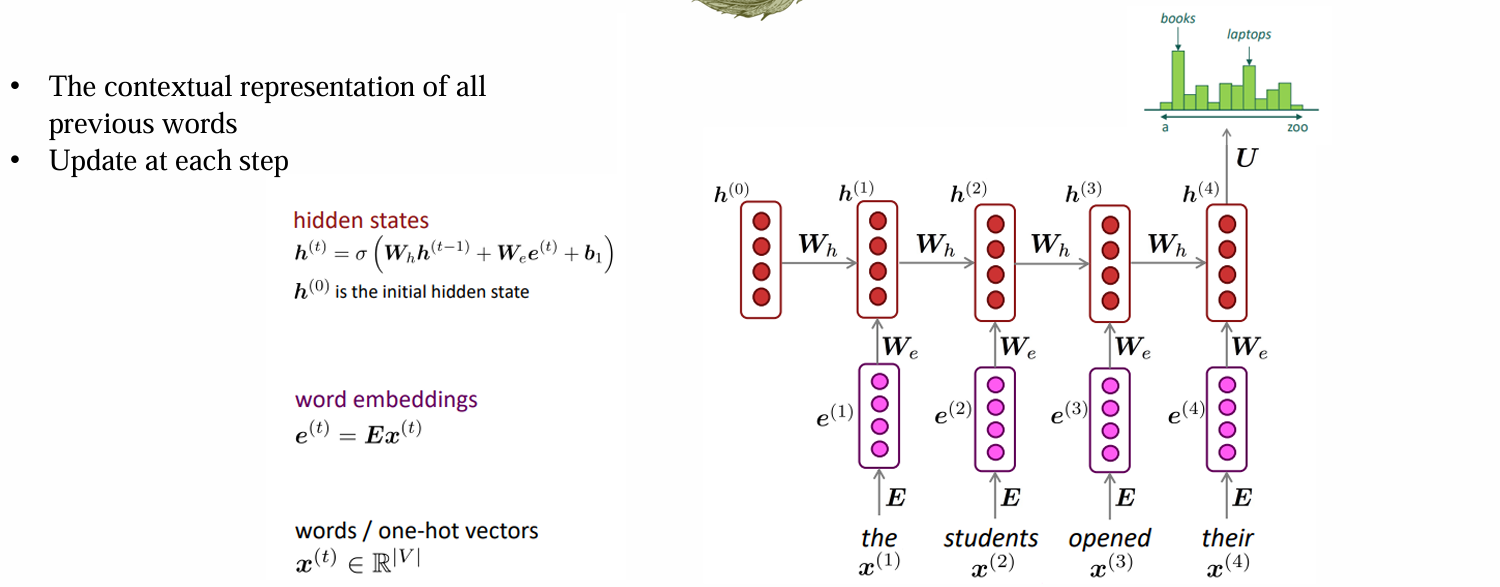
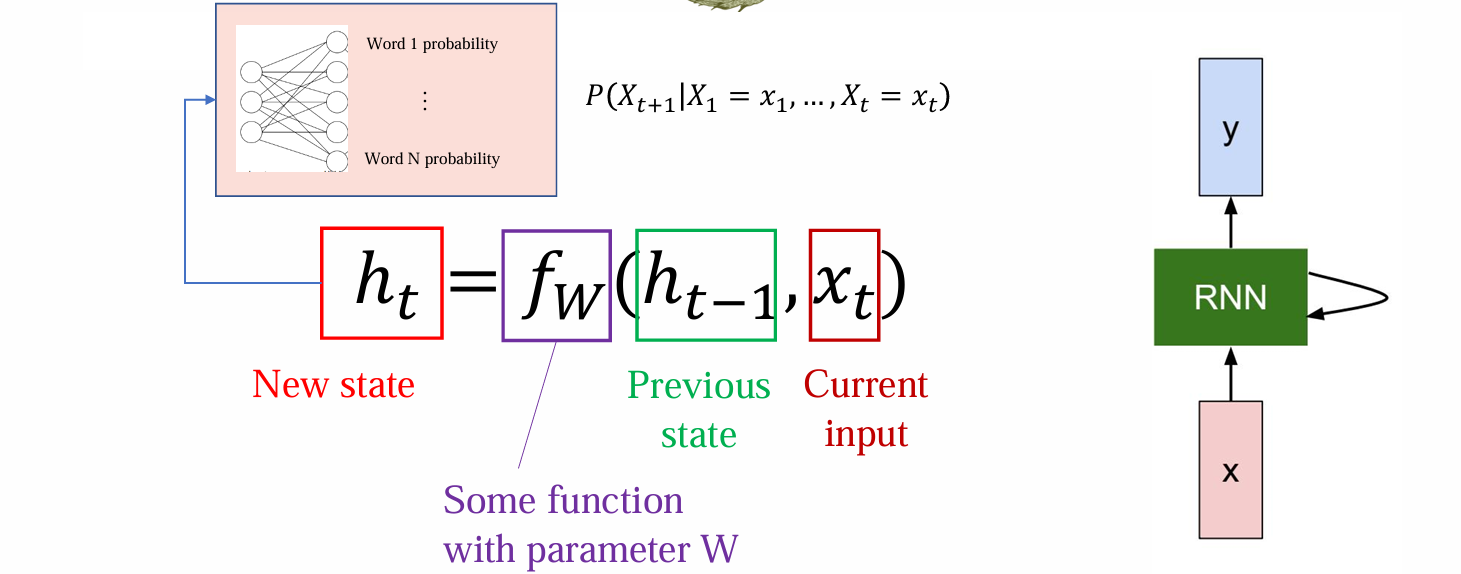
Simple form of RNN LM
- 最后再接一个head,可以输出任意位置预测下一位置token的概率:
(RNN) LM training objective
当已知建模时,参数如何训练
训练数据集𝐷 = {𝑠1, 𝑠2, …, 𝑠𝑁}:由多个相互独立的句子组成
目标:最大化似然𝑃𝜃(𝑆1 = 𝑠1,…,𝑆𝑁 = 𝑠𝑁),模型能够生成D中句子的概率越大,说明其能够还原数据集的能力越强
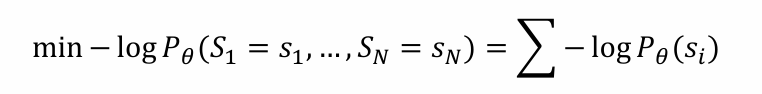
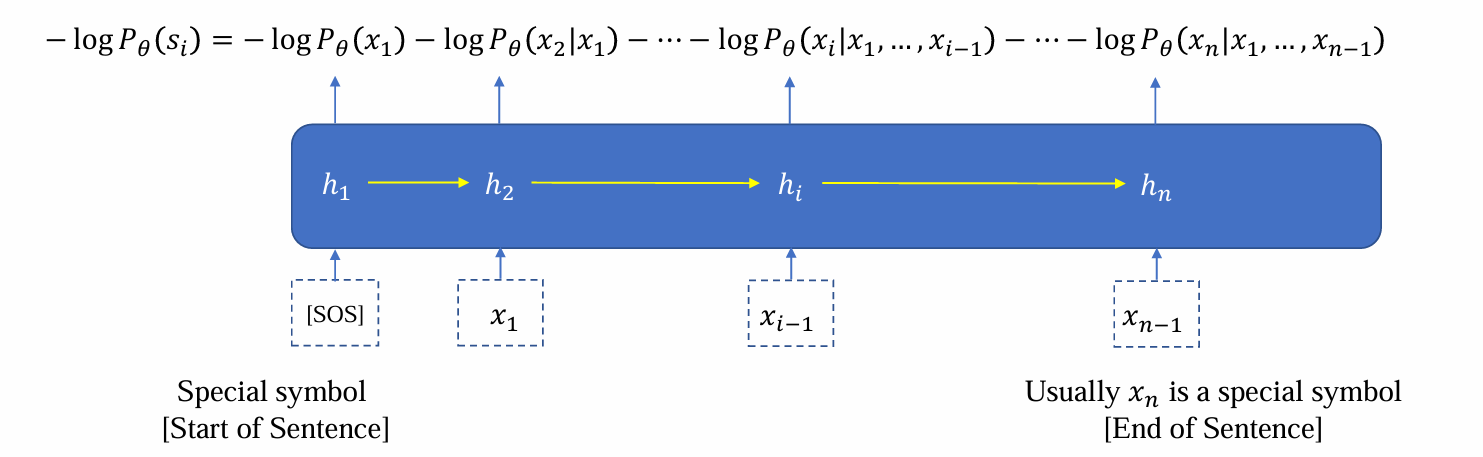
- 在RNN中,将联合概率密度应用chain rule拆成条件概率密度时,在log作用下变为加法:
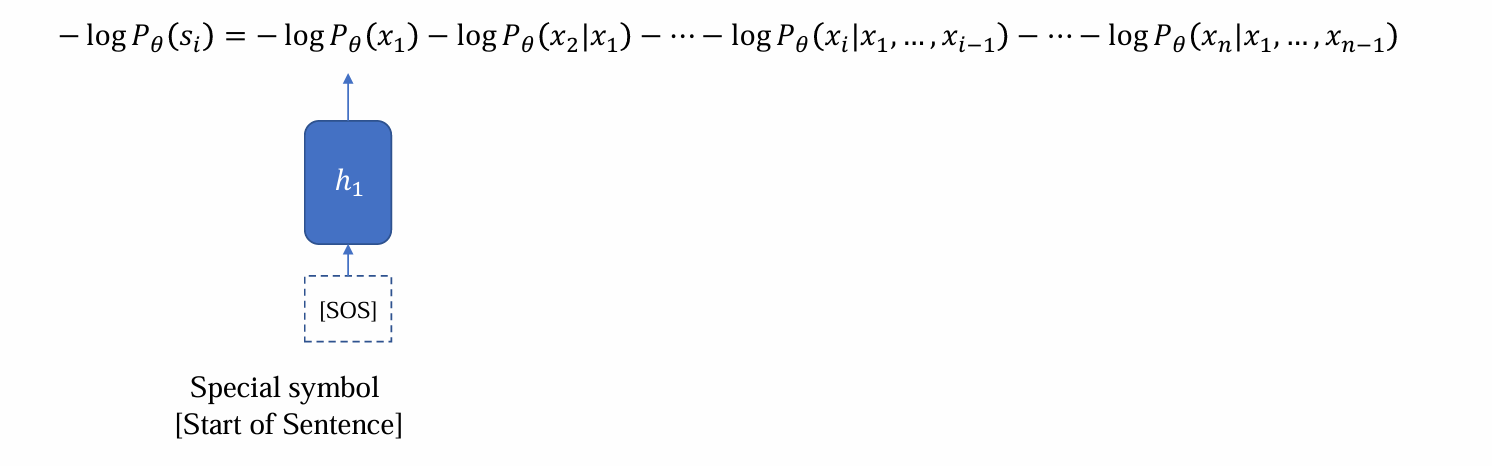
- [SOS]是特殊标记,作为第一个输入引导句子生成,更新h1
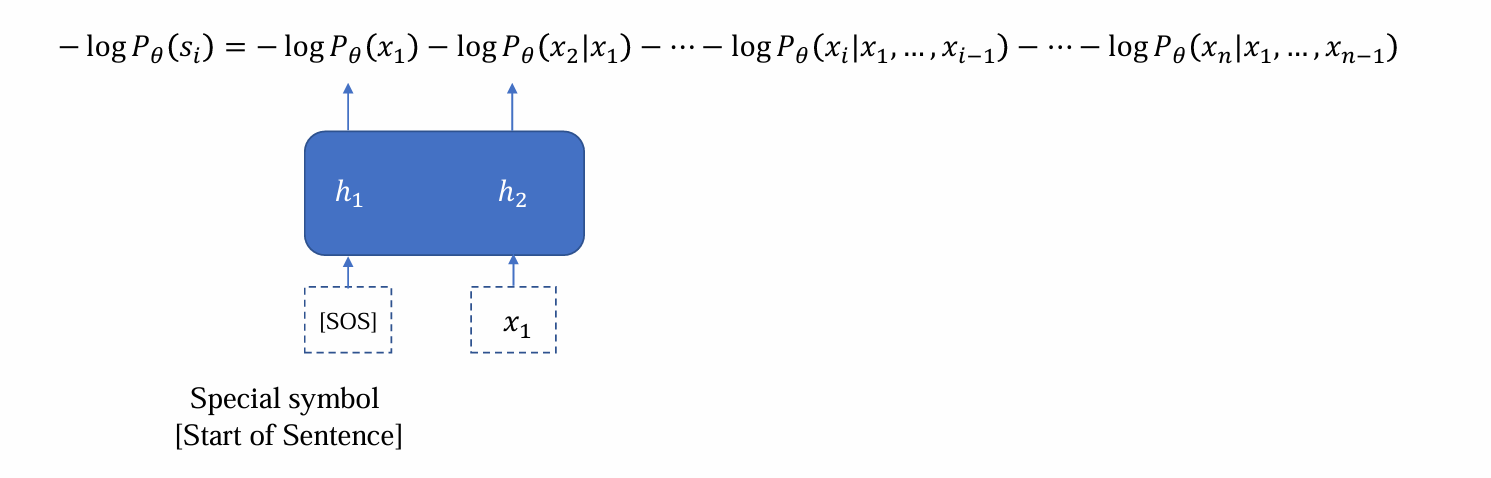
- 连接prediction head输出x1后,将x1与h1应用RNN更新维护得到h2,继续预测x2……重复上述过程,直到得到xn
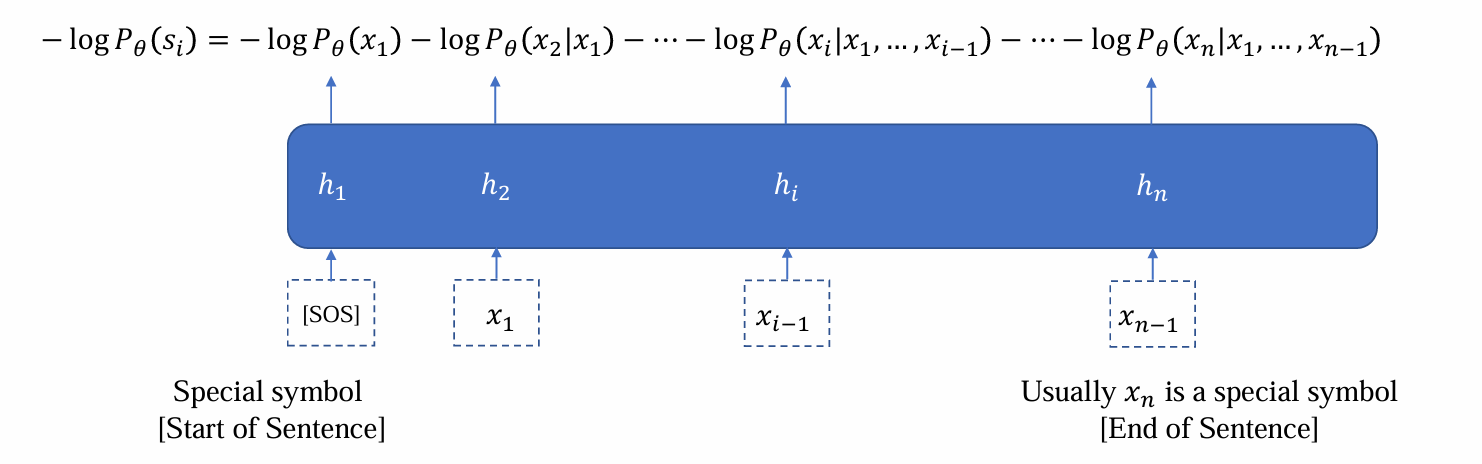
实质是next token pridiction
给定一个句子:
- 逐一的计算loss
- 梯度下降更新模型参数θ
优点:
- 可以适用于任何长度的句子
- 固定的参数量
- 高度非线性
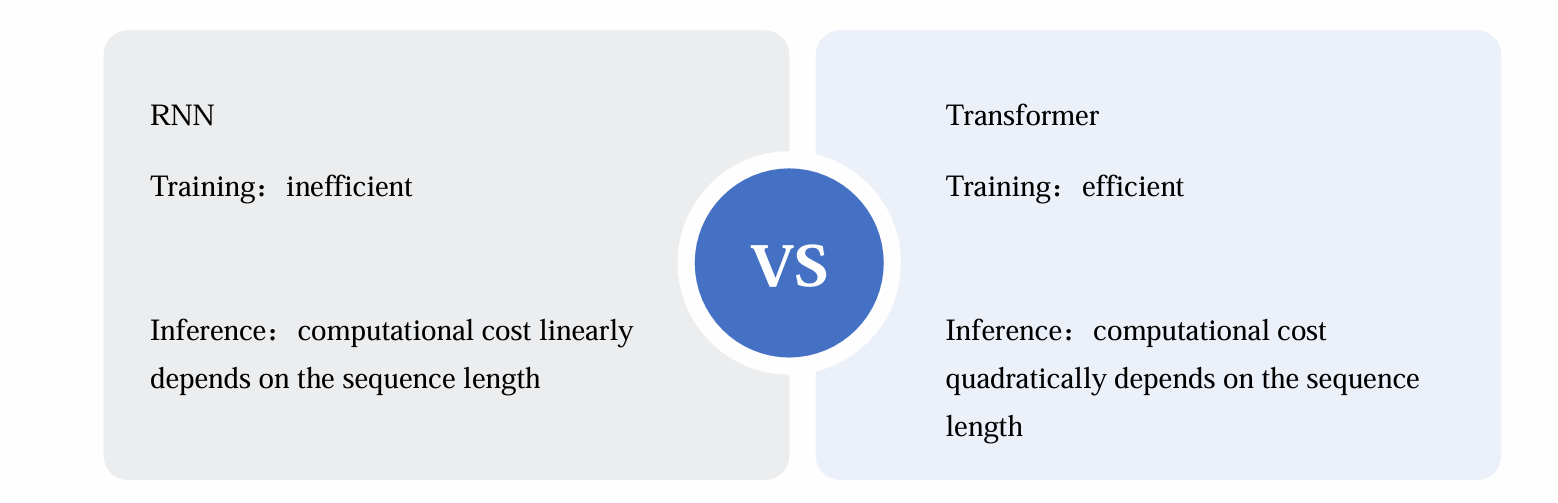
缺点:只有看到前面的词才能够更新hidden state,只能串行无法并行,效率低下
LM Training: Teacher forcing
next token prediction:给定前一个词,预测下一个词
Teacher forcing:
- teacher:假设前面的tokens都是teacher给出的ground truth
- forcing:强制进行下一个词的预测
在LM training中二者相同
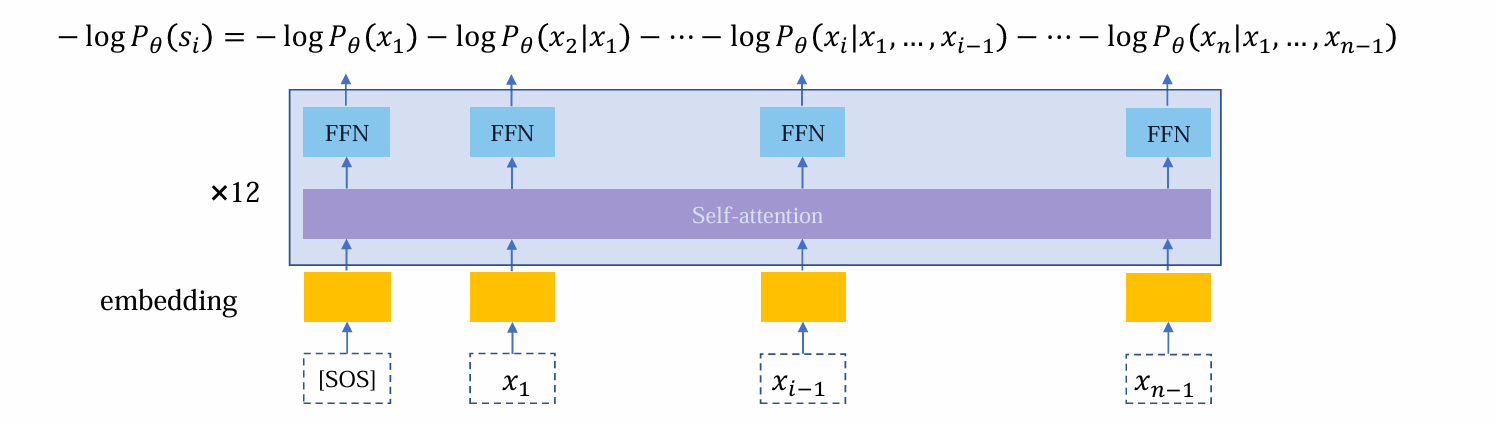
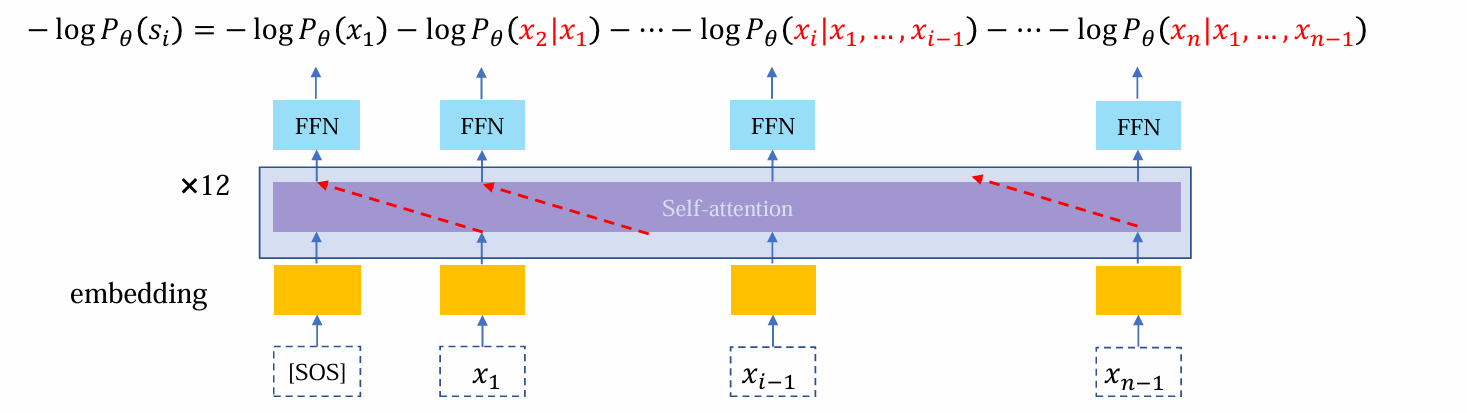
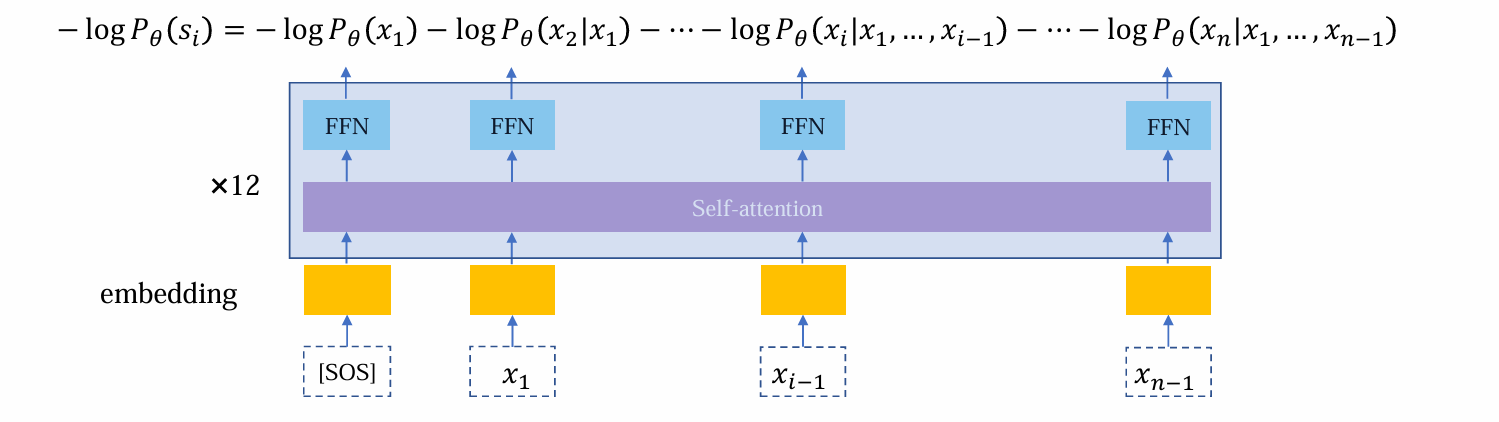
LM Training: Transformer
- 首先,进行embedding准备输入
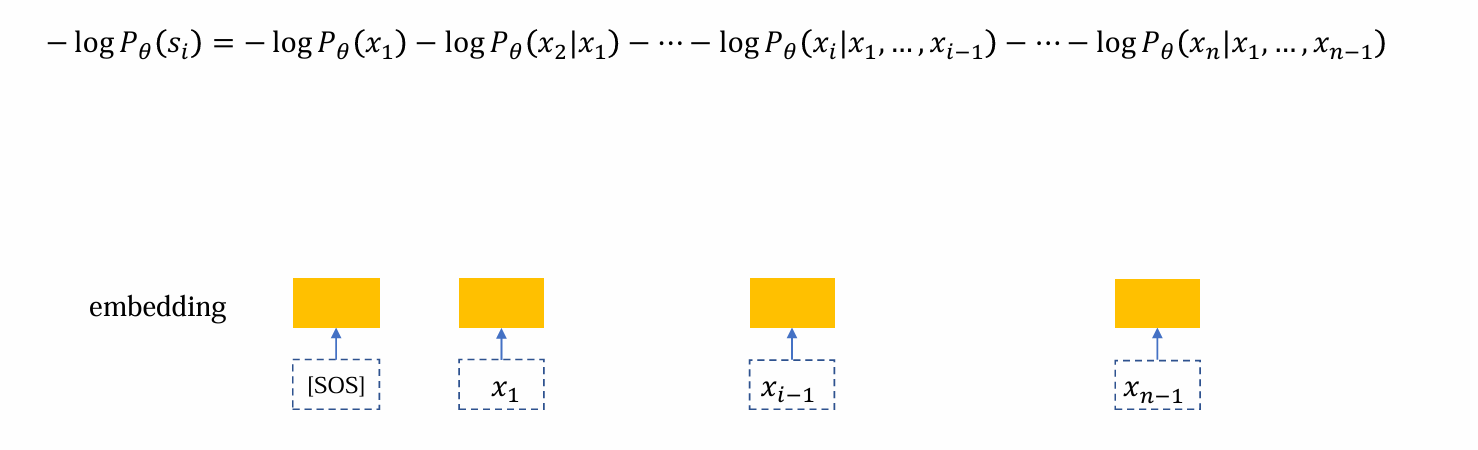
- 将embedding后的向量输入,其中self-attention负责收集、整理数据,而FFN负责加工信息
问题:希望看不到后面的tokens,但是注意力机制使其可以直接看到需要预测的单词
在transformer实现过程中,计算注意力权重矩阵时,加权会加权后面的信息:

因而需要引入attention mask用于掩盖后面的信息
核心思想:由于softmax操作会使得很大的值接近于1,而很小的值接近于0.因而不掩码的部分可以+0,而掩码部分+(-inf),这样归一化后,需要掩码的部分变为-inf归一化到0,从而看不到后面的信息

- decoding only attention的加入attn_mask后的流程如下:
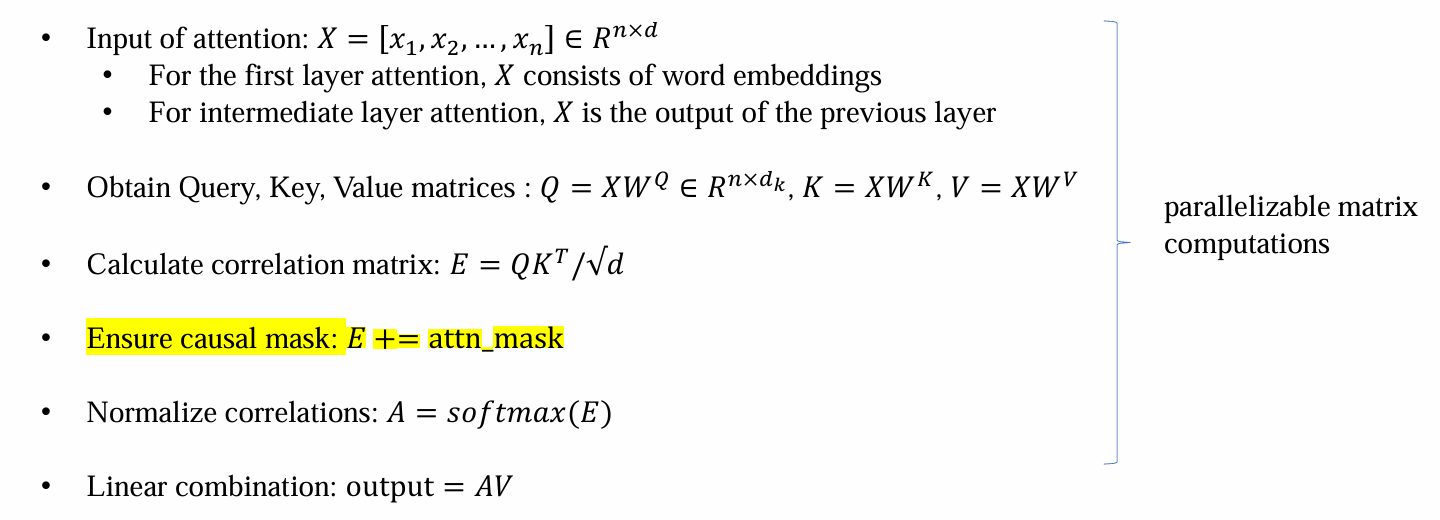
Large-scale LM training must-known tips
Mixed precision training (混合精度训练)
- fp32, fp16 and bf16 (>=A100)
- 不同的部分使用不同的精度:例如前向传播中涉及矩阵乘法可以使用低精度;而涉及到除法的例如layer norm必须使用高精度
- optimizer
Large-batch training (Production-level model):minibatch当batch_size小(加入噪音大)时,导致训练速度很慢
- Training data (3.4B~4T, tokens)
- 1M tokens per batch at least (512 token/sen * 2048 sen)
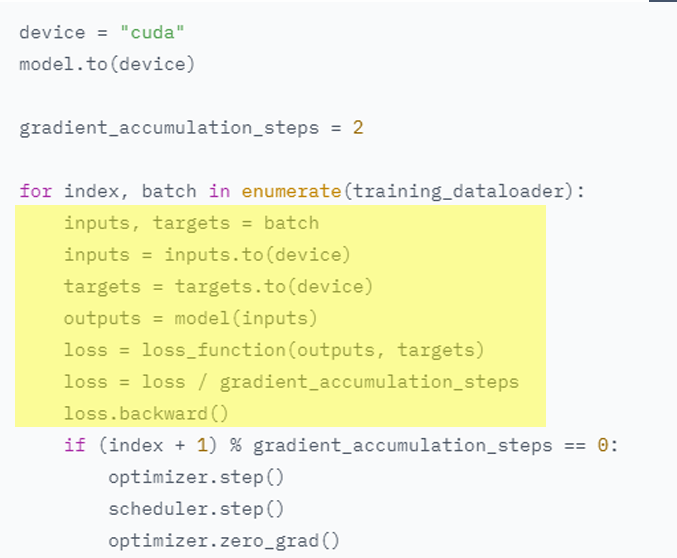
- 由于显存有限,无法同时满足大tokens同时训练,所以需要:Gradient accumulation
Gradient accumulation:时间换空间的体现,先储存梯度不更新,加载多次batch,直到达到某一个tokens数量后才一起更新一次梯度
- Ways to stabilize training (Production-level model):
- Small dropout
- Learning rate warm-up
- Gradient clipping
Evaluation: Perplexity
实质:nLL的变种
给定长度为n的句子s: nLL(𝑠; 𝜃) = −log𝑃𝜃(𝑠)
问题:对长度敏感,长度越长,效果越差,而数据集的长短不同
解决方法: Per-word negative log-likelihood
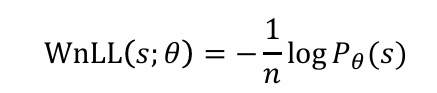
- perplexity:
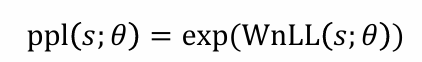
- 其他的评估指标:BLEU, ROUGE…(learn from NLP courses)
What will happen if you do a wrong mask
- If you forget to add the mask in LM…
- Training LM: loss会很低,接近于0,学习到了捷径,即下一个位置已知,下一个input即为prediction的pattern
- Evaluating LM: loss会很低,在test set中仍可应用这个捷径的bug
- Inference: 实际使用时,效果会极差因为捷径不再适用。甚至接近纯随机
- Training LM: loss会很低,接近于0,学习到了捷径,即下一个位置已知,下一个input即为prediction的pattern
Inference
Inference在使用LM时,一个一个词的生成,因而不知道下一个词
常见的采样方法有: (top-k) stochastic sampling, greedy search
Inference (stochastic sampling)
- AR可以给出下一个token的分布,stochastic sampling根据分布随机采样得到结果:
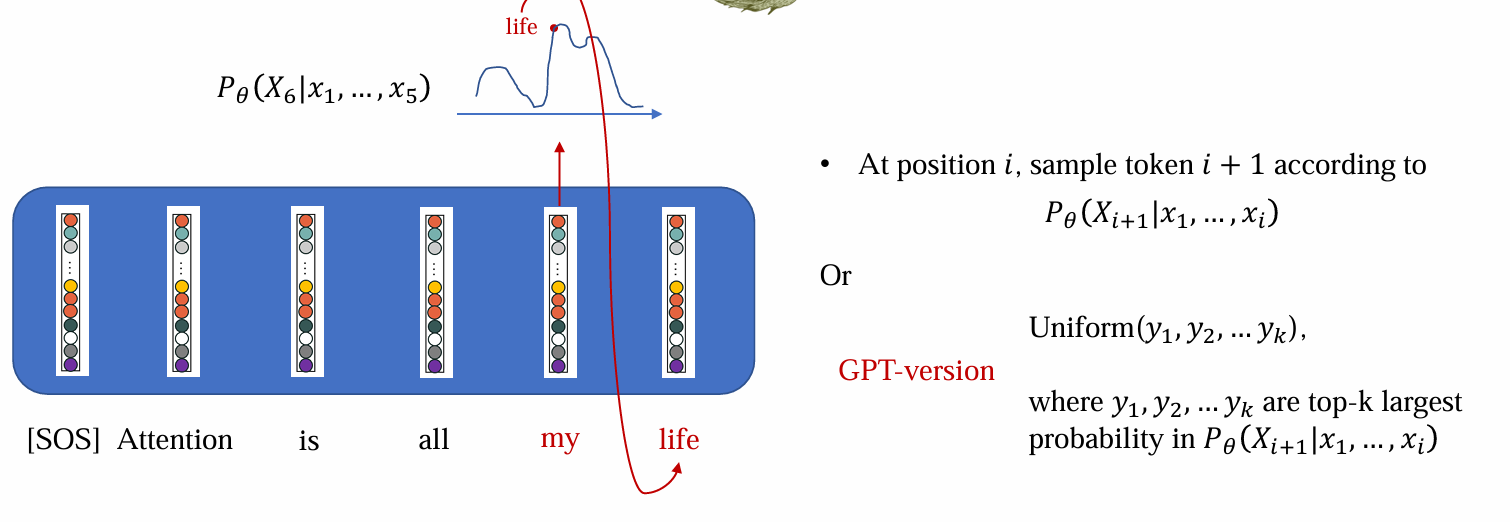
问题:随机性过大,有小概率sample出很不好的结果
解决方法:
- Top-K:先选出K个概率最大的候选,再以一定策略在候选中sample
- Top-P:先选出概率>P的候选,再以一定策略在候选中sample
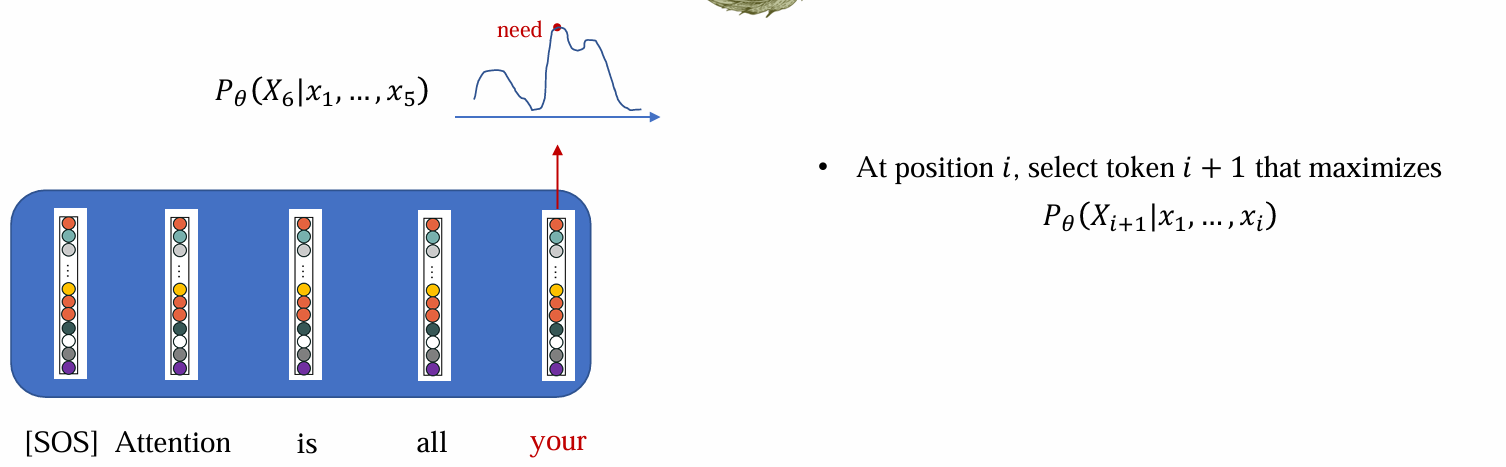
Inference (greedy search)
贪心搜索可以认为是K=1时的Top-K
argmax选出概率最大的词
Comparison
- 效率、多样性和准确率构成了不可能三角:

Computational cost
Computational cost of attention
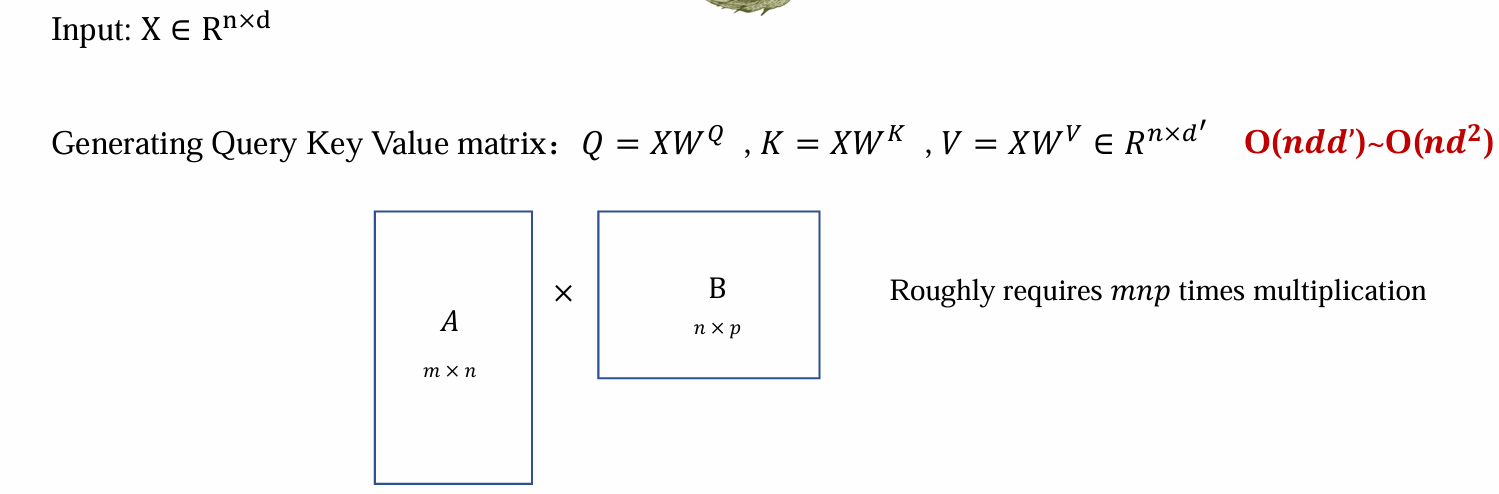

- 可并行,d可以去掉
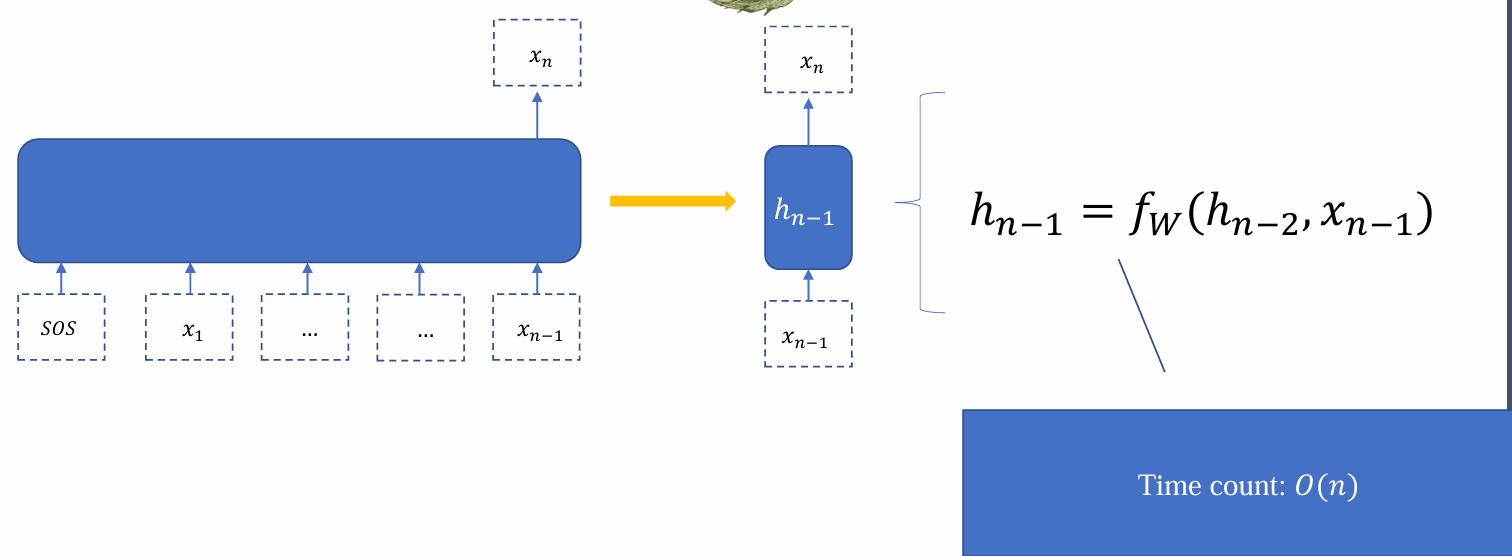
Inference cost
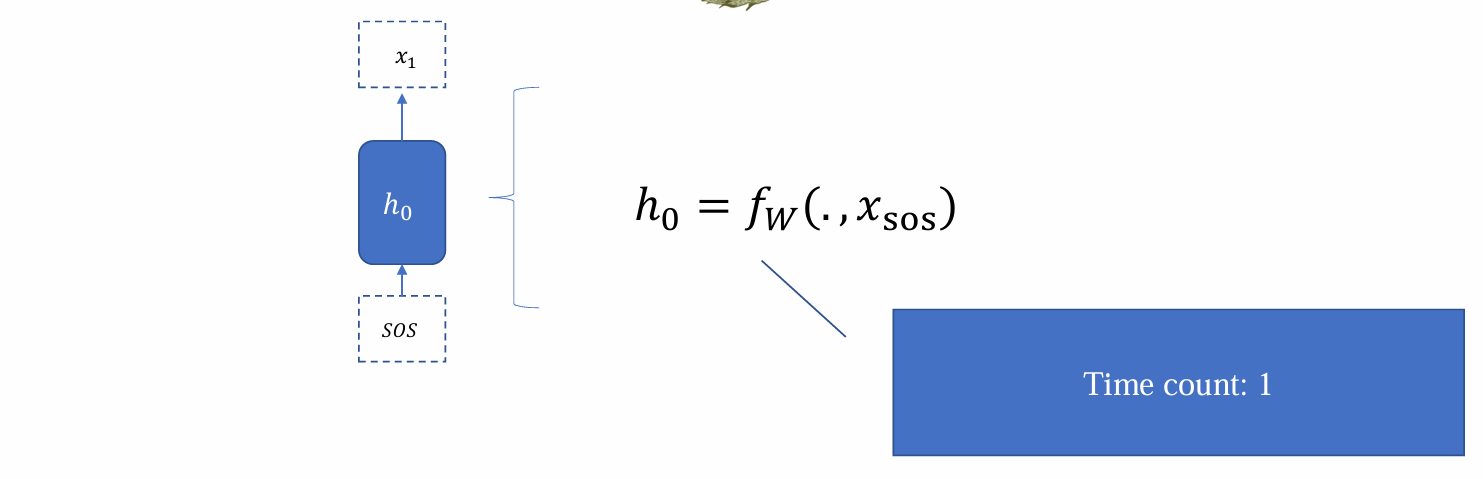
- 若将更新计算一次hidden state的时间步记为1,则RNN的inference time count和序列长度呈线性关系:
- 而transformer在每个位置还需要和前面的每个位置作用,因此时间复杂度更高
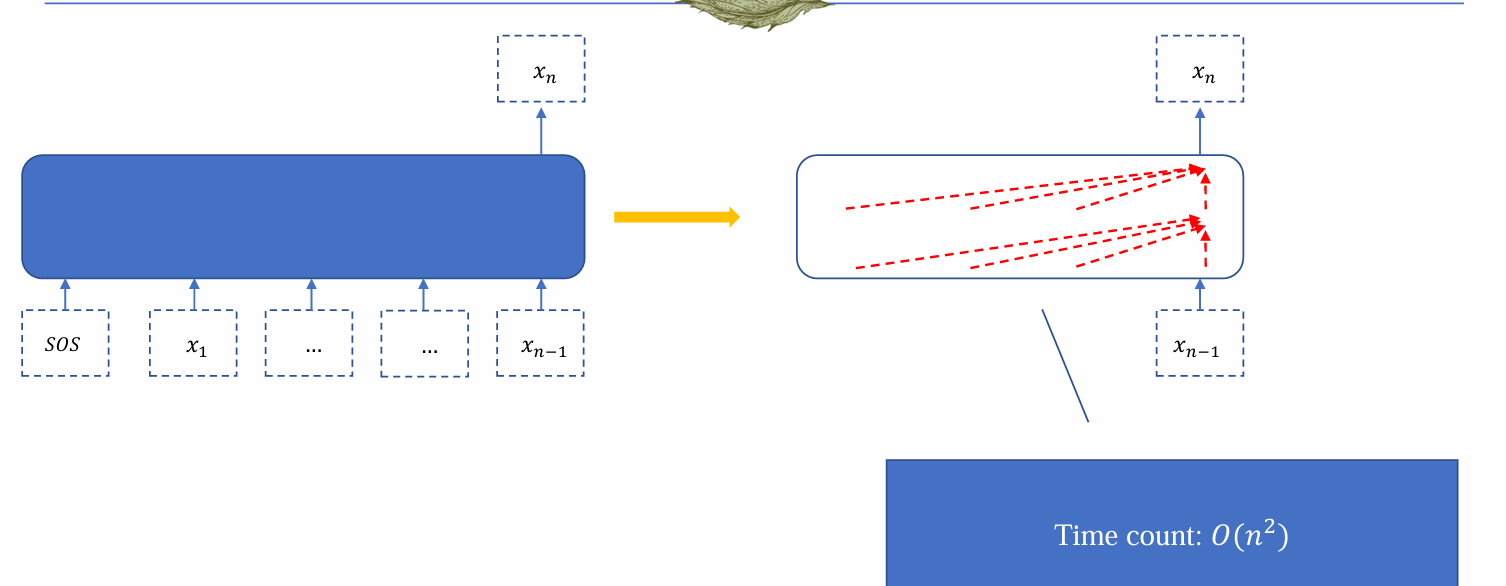
- 因此在inference输出序列时,RNN的速度要快于Transformer
Training cost
- Transformer的training cost是O(n²),但是可以并行,因此训练速度很快:
- RNN的training cost是O(n),但是不可并行,因此训练速度很慢