
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model(视觉自回归多模态大语言模型中的统一理解与生成)
Abstract
VARGPT是一种新颖的多模态大语言模型(MLLM),它在单一的自回归框架内统一了视觉理解和生成
VARGPT采用下一个token预测范式进行视觉理解,采用下一个尺度预测范式进行视觉自回归生成
VARGPT创新性地扩展了LLaVA架构,在MLLMs中实现了高效的尺度自回归视觉生成,同时无缝地支持单一模型框架内的混合模态输入和输出
VARGPT经过三个阶段的一体化训练过程,包括预训练阶段和两个混合视觉指令微调阶段
统一训练策略旨在实现视觉和文本特征的对齐,增强理解和生成的指令跟随能力,并提高视觉生成质量
VARGPT自然地支持自回归视觉生成和指令到图像合成的能力,展示了其在视觉理解和生成任务中的多功能性
1. Introduction
近年来,多模态人工智能在理解和生成这两个核心领域取得了重大突破。多模态大语言模型(MLLMs)通过利用LLMs的强大泛化能力,展示了在多模态数据理解方面的卓越能力
去噪扩散概率模型(DDPMs)在图像生成领域带来了重大进展,在文本到视觉模态生成方面取得了卓越的性能
受自回归LLMs的有利特性启发,如scaling law,许多工作探索了通过预测下一个token或下一个尺度进行自回归视觉生成
鉴于这些在视觉理解和生成方面的成就,最近的研究一直在探索能够处理理解和生成的统一模型,从而设计了各种统一架构以实现这一目标
- 最近的研究尝试将来自这两个不同领域的模型(例如,LLMs和DDPMs)组合起来,形成一个能够处理多模态理解和生成的统一系统
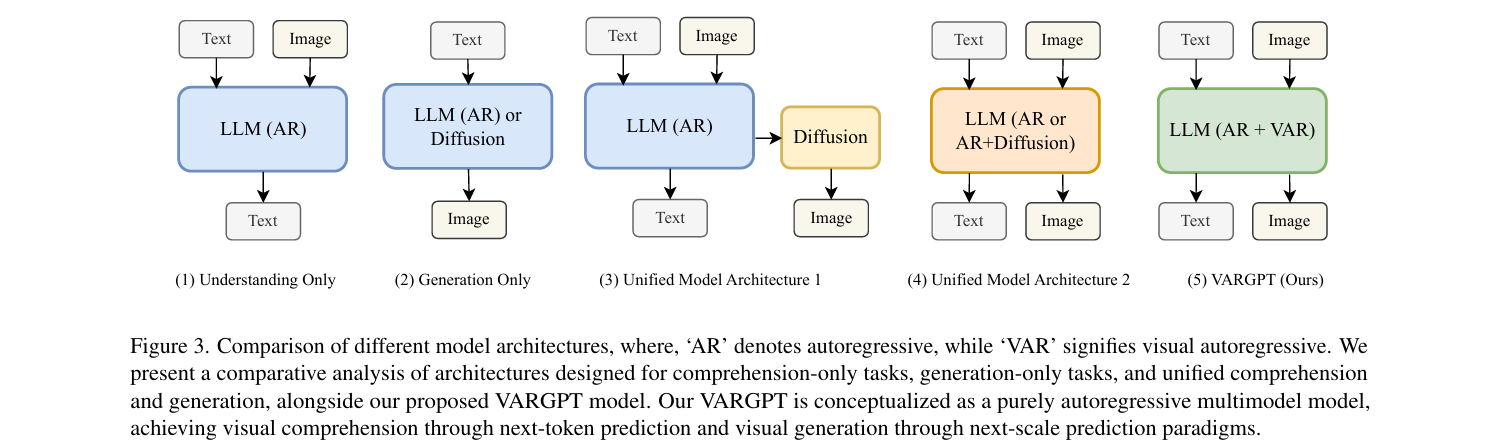
我们致力于在视觉自回归MLLM中统一视觉生成和理解,自然地支持混合模态输入和输出
与所有现有的统一模型不同,我们提出在统一模型中将理解和生成建模为两个不同的范式:分别预测下一个token进行视觉理解,预测下一个尺度进行视觉生成,并训练一个名为VARGPT的新型统一模型:
在模型架构方面,我们的VARGPT的核心结构借鉴了LLaVA-1.5-7B,同时我们还额外加入了一个视觉解码器和两个额外的视觉特征投影器用于视觉生成
VARGPT采用自回归方法来预测下一个文本token以进行视觉理解和问答。当预测到用于视觉生成的特殊token时,模型自回归地预测下一个尺度的token,并通过视觉解码器获得最终的输出图像。所提出的架构使VARGPT能够在视觉自回归MLLM中实现统一的理解和生成。
在训练方法方面,我们采用统一的指令微调来学习视觉理解和视觉生成。通过构建视觉token预测作为指令跟随格式,将指令微调扩展到视觉生成,并将构建的视觉生成指令数据集与来自LLaVA-1.5的多轮对话指令数据集结合进行混合训练
通过提出的统一指令微调,我们同时赋予MLLMs理解和生成能力
训练过程分为三个阶段,包括一个预训练阶段和两个指令微调阶段:
- 在预训练的第一阶段,模型学习文本和视觉空间之间的特征映射
- 在第二和第三阶段的指令微调中,VARGPT分别增强了其在视觉问答和指令到图像生成方面的能力
关于训练数据集,通过统一的指令跟随格式,我们在混合视觉指令微调中统一了理解和生成的训练
VARGPT能够实现显著的视觉理解能力,并赋予MLLMs视觉生成能力,自然地支持混合模态输入和输出
VARGPT是第一个支持预测下一个token进行理解任务和预测下一个尺度进行生成任务的统一模型,同时在理解能力方面超越了众多规模相当的MLLMs和统一模型
主要贡献有三点:
- 探索了一种新颖的自回归视觉理解和生成的统一架构,该架构采用下一个token范式进行视觉理解,采用下一个尺度范式进行视觉生成
- 开发了VARGPT,一个支持混合模态输入和输出的统一模型,通过新颖的架构、提出的三阶段训练策略和386万样本的统一指令微调数据集
- VARGPT在众多多模态理解和以视觉为中心的基准测试中表现出色,同时在自回归文本到图像合成方面展示了卓越的能力
2. Related Work
Visual Generation
扩散模型将图像生成视为从噪声到图像的反向扩散过程
扩散模型的进展主要集中在采样方法和架构设计,从而产生了令人印象深刻的模型
在扩散模型取得显著进展的背景下,基于流的生成模型作为一种简化框架出现,推动了先进视觉生成模型的发展
自回归模型采用GPT风格的技术来预测序列中的下一个token,一些工作使用类似于VQGAN的视觉tokenizer将图像转换为离散token,从而实现对视觉数据的token化,并采用类似于GPT风格的预测方法
另一类基于预测下一个尺度的自回归模型,如VAR、HART和Infinity,引起了关注,并已被验证可能具有与scaling law一致的性质
在本工作中,我们的统一自回归框架通过预测下一个尺度的范式完成了图像生成任务
Multimodel Large Language Model
LLMs的进展推动了MLLMs的发展
MLLMs利用预训练的LLMs作为文本解码器,通过连接器将文本和图像与视觉编码器集成
LLaVA使用来自各种任务(如视觉问答和图像描述)的数据以指令格式微调模型,使模型能够理解新指令并泛化到未见过的任务
LLaVA-1.5和LLaVA-NeXT系列通过更多样化和更高质量的数据进一步提升了视觉理解性能
通过架构优化、创新训练范式和引入多样化数据,一系列先进的MLLMs应运而生,如Qwen-VL、mPLUG-Owl2、InternVL、InstructBLIP
Unified Models For Visual Understanding and Generation
近年来,研究人员致力于在模型中统一理解和生成能力
大多数现有方法尝试将预训练的扩散模型与现有系统集成。然而这些系统本质上将扩散模型视为外部工具,而不是将其作为MLLMs的内在生成能力
Show-o通过结合自回归和(离散)扩散建模,能够自适应地处理各种混合模态的输入和输出
Li等人采用跨模态最大似然估计框架,显著改进了现有的基于扩散的多模态模型
LWM和Chameleon利用VQ tokenizer对图像进行编码,从而同时支持多模态理解和生成
Janus通过将视觉编码解耦为单独的路径进一步增强了模型的灵活性和性能
Dual Diffusion研究了使用两个扩散模型进行理解和生成
Liquid在同一空间中学习图像和文本嵌入,并使用预测下一个token的范式实现自回归视觉理解和生成
与所有现有统一模型不同,我们提出在统一模型中将理解和生成建模为两个不同的范式:分别预测下一个token进行视觉理解,预测下一个尺度进行视觉生成
3. Methodology
3.1. Model Architecture
- VARGPT统一了视觉理解和生成,其架构下图所示
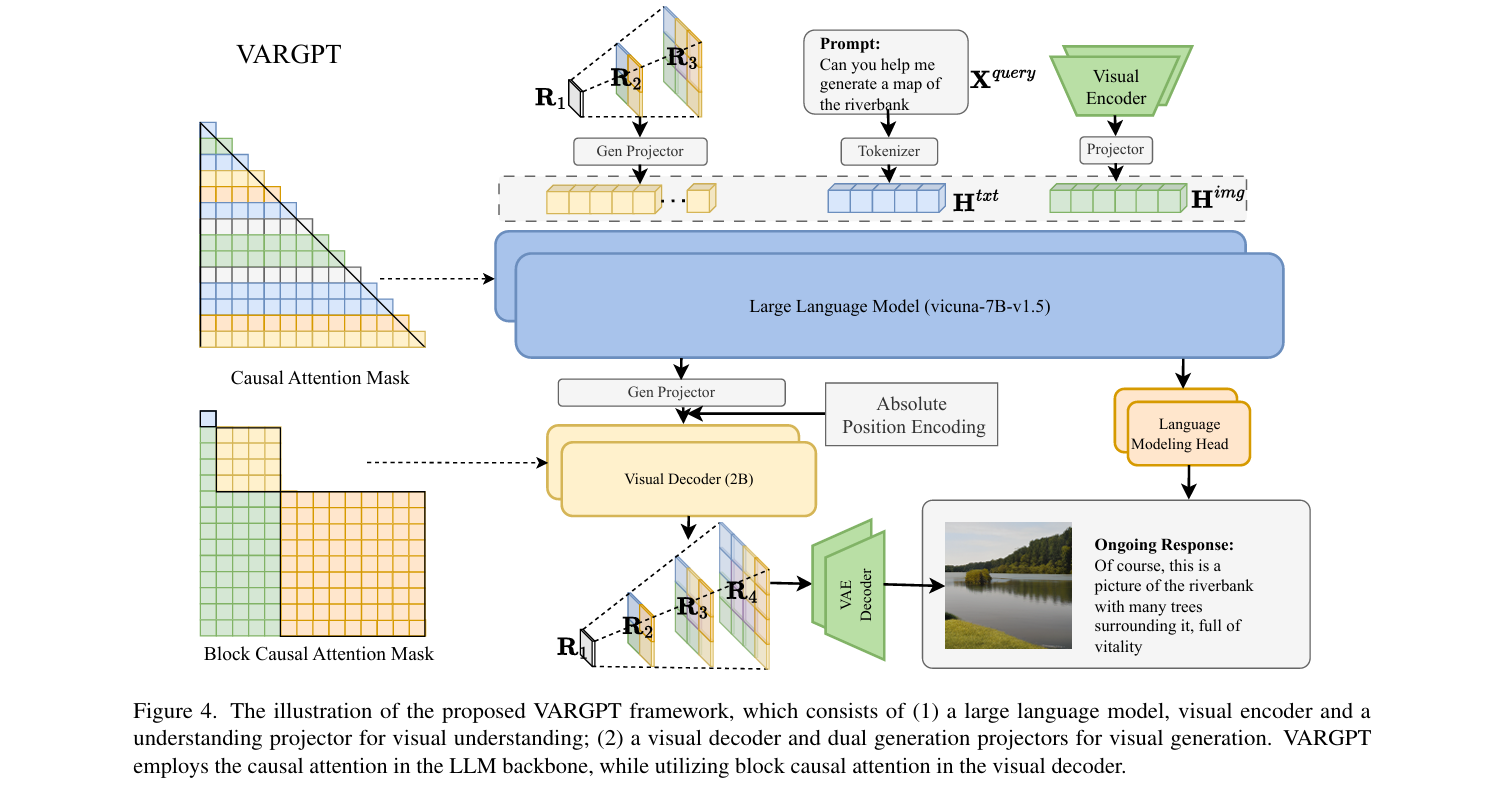
- 架构遵循预测下一个token进行理解和问答的范式,并遵循预测下一个尺度进行图像生成的范式
Visual understanding via next-token prediction
对于视觉理解,我们的模型架构参考了LLaVA-1.5的结构,使用Vicuna-7B-v1.5作为LLM θ,并采用CLIP的视觉编码器(ViT/14)作为视觉编码器,以及一个两层的线性网络作为投影器
最初,用于视觉理解的图像Ximg通过视觉编码器处理以生成嵌入Himg,然后通过接口(例如线性层)进行修改,以与查询Xquery获得的文本嵌入Htxt对齐
组合后的数据作为LLM的输入,LLM自回归生成文本输出Ytxt:其中Y_t^{txt} 表示Ytxt的第t个token,Y_{<t}{txt}表示在第t步之前生成的token序列
- 为了保持LLM的因果注意力特性,我们对所有输入LLM的token应用因果注意力掩码,包括用于生成图像的token
Visual generation via next-scale prediction
对于视觉生成,我们遵循VAR中的大多数设置,并采用多尺度图像tokenizer进行视觉token编码和解码
我们构建了两个图像生成投影器,用于在LLM的输入和输出处转换用于生成的视觉特征
我们构建了一个额外的2B视觉解码器φ,包含30层Transformer,用于解码视觉特征,这在一定程度上可以避免文本解码器中的知识与图像生成知识之间的冲突
通过视觉解码器获得的图像特征将通过多尺度VAE解码器进一步解码,以生成可用的图像
与文本解码器(即LLM)不同,视觉解码器使用遵循VAR中的块因果注意力的注意力机制,以支持预测下一个尺度的token
此外,在将用于视觉生成的特征输入视觉解码器之前,我们添加了绝对位置编码,以进一步区分视觉token的位置信息
形式上,我们将图像的多尺度特征图定义为(R1, R2, …, RK),通过多尺度tokenizer获得。因此,下一个尺度的图像token将以自回归方式生成:
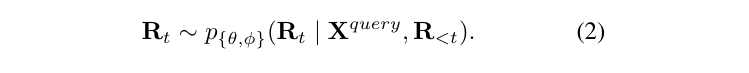
Prompt template for mixed-modal generation
为了区分用于文本生成和图像合成的token,我们设计了一些特殊的token标记
我们使用
来填充图像生成token的位置, 表示图像生成token的开始, 表示生成的结束 当VARGPT生成
token时,与 token相关的特征通过投影器处理,随后输入视觉解码器以生成图像生成所需的特征 在视觉理解任务中,我们使用<’image’> token作为输入图像的表示
Classifier-free guidance (CFG)(无分类器引导)
CFG显著增强了生成扩散模型生成高保真样本的能力
该方法将条件生成模型与同时训练的无条件模型的分布估计相结合,从而提高了生成的整体质量
受DALL-E 2、VAR和VAR-CLIP的启发,使用高斯噪声作为输入来模拟无条件生成。随后通过从条件生成的logits分布中减去无条件生成的概率来获得视觉输出的最终分布
3.2. Training
- 对于VARGPT模型训练,我们提出了一个阶段的预训练过程和两个阶段的指令微调过程,如下图所示
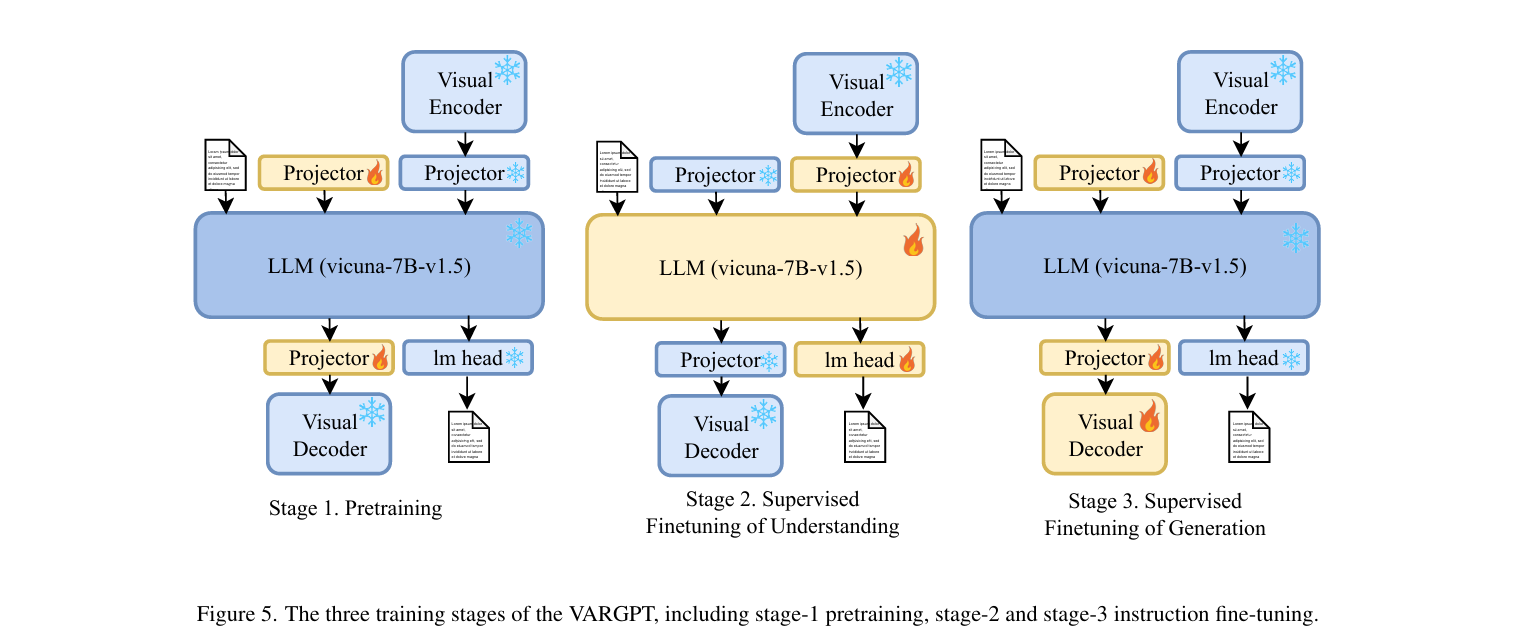
3.2.1. Stage-1: Pretraining
使用来自ImageNet的图像作为图像源,构建用于预训练两个图像生成投影器的训练数据
将预训练数据构建为1.28M的单轮对话数据(具体见第4节)
此预训练阶段的主要目的是训练投影器,初步对齐图像生成特征与文本特征。在预训练期间,冻结了除两个图像生成投影器之外的所有参数
3.2.2. Stage-2: SFT for Visual Understanding
在第二阶段,我们解冻了语言模型和视觉编码器特征输出的投影器,并使用我们策划的多轮对话和理解数据集进行训练
此阶段的主要目的是确保VARGPT保持出色的多轮对话、视觉理解和问答能力
在此阶段,我们引入了5K个来自我们构建的Imagenet-Instruct数据集的样本,使VARGPT能够区分视觉理解和视觉生成任务
当用户输入生成指令时,VARGPT可以通过输出特殊token
来准确响应,以开始自回归视觉生成
3.2.3. Stage-3: SFT for Visual Generation
与第二阶段相比,第三阶段主要旨在通过监督微调提高VARGPT的指令到图像生成能力
在此阶段,我们解冻了视觉解码器和用于视觉生成的两个投影器,同时冻结其他参数以进行SFT
第三阶段的训练数据包括从ImageNet构建的1400K指令对(详见第4节)
4. Unified Instruction-following Data
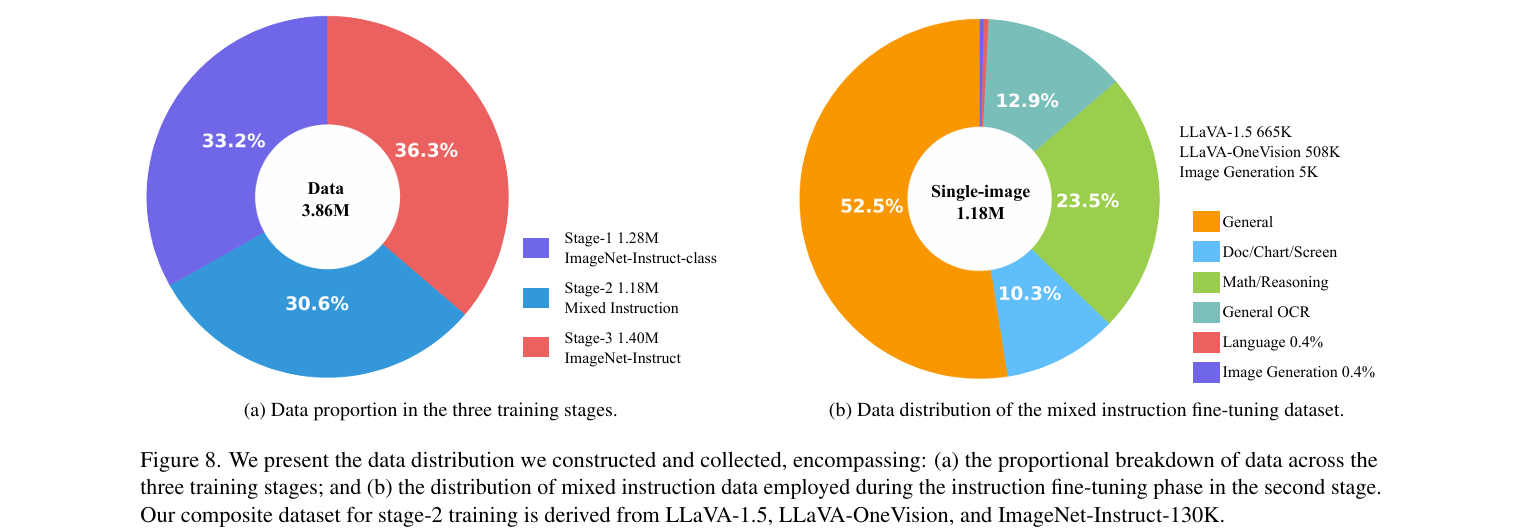
本节描述了三个不同阶段使用的训练数据集的来源以及各种数据类型在其中的比例表示
值得注意的是,我们引入了图像生成指令跟随数据集,如下图所示,详细阐述了其来源以及通过应用LLMs生成的方法。通过这种方法,我们将视觉理解和生成的训练方法统一为视觉指令微调。
4.1. Generation Instruction-following Dataset
- 我们构建了两个图像生成指令跟随数据集:ImageNet-Instruct-130K和ImageNet-Instruct-1270K
ImageNet-1K-VL-Enriched
使用ImageNet-1K-VL-Enriched数据集作为我们的基础数据集
ImageNet-1K-VL-Enriched是ImageNet数据集的增强版本,其中图像描述是使用BLIP2描述模型生成的
Constructing ImageNet-Instruct-130K through Deepseek-LLM
为了构建指令微调数据集的问答格式,我们利用Deepseek-V3 Chat LLM(以下简称LLM)生成提示和答案的种子格式(Prompt_limit_seeds和Answer_limit_seeds)
如下图左所示,Prompt_limit_seeds有效地模拟了用户请求,而Answer_limit_seeds模拟了VLLM与用户之间的对话
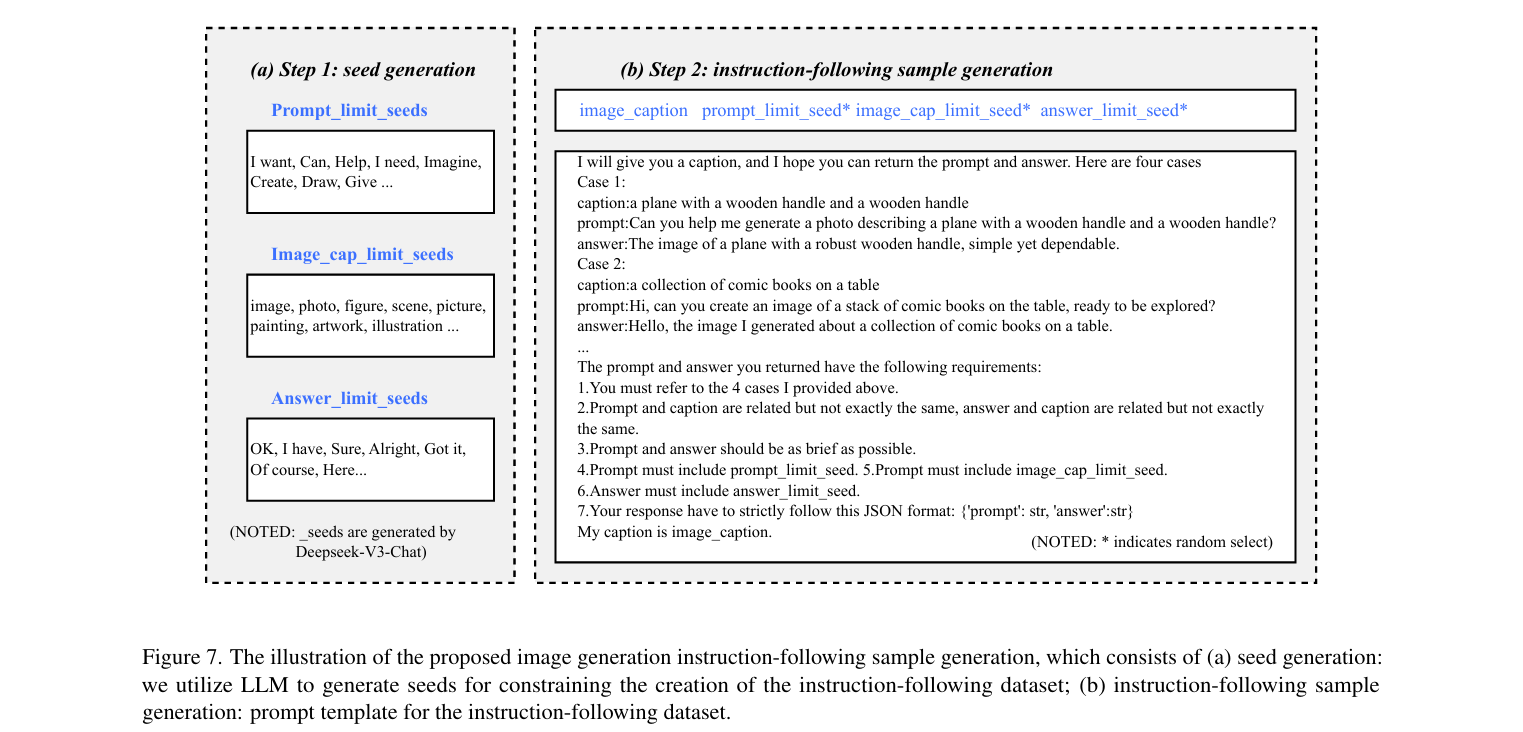
- 我们从种子池中随机选择prompt_limit_seed、image_cap_limit_seed和answer_limit_seed作为LLM调用模板的元素
LLM invocation template(LLM调用模板)
我们从基础数据集中随机选择了4个图像描述样本作为4-shot示例,以指导大模型生成相应的对话样本,如上图右所示
在生成的提示和答案中添加了相关约束,以确保输出尽可能合规和多样化
随机采样了130K个图像描述数据样本,从而创建了130K个ImageNet图像生成指令微调数据集的样本,将其命名为ImageNet-Instruct-130K
4.2. Data Composition in Three Training Stages
Stage-1
用于阶段1预训练的ImageNet-Instruct-class数据集包含128万个单轮对话样本,这些样本来自ImageNet,专注于学习类别与图像之间的对应关系
假设类别为“鱼”,则格式如下:{‘prompt’: ‘请为我生成一张鱼的图像。’, ‘answer’: ‘生成的鱼的图像如下<’image’>}
Stage-2
- 我们在阶段2中的混合指令微调数据集来自LLaVA-1.5、LLaVA-OneVision和ImageNet-Instruct-130K
Stage-3
在阶段3中,除了构建的ImageNet-Instruct-130K外,我们还创建了一个更大的图像生成指令跟随数据集ImageNet-Instruct-1270K
与ImageNet-Instruct-130K相比,它具有更多样化的提示和答案模板(多达400个)。提示和答案的构建涉及将模板与描述直接连接
5.Experiments
对于用于图像生成任务的图像,我们统一将其调整为256x256像素,并应用与VAR中一致的预处理技术
对于用于视觉理解任务的图像,我们遵循LLaVA-1.5框架中建立的预处理协议
语言模型、视觉编码器和视觉特征映射器使用LLaVA-1.5-7B-hf架构进行初始化
视觉解码器使用VAR-d30参数进行初始化,包含约20亿个模型参数
VARGPT中的视觉生成特征映射器在预训练的第一阶段进行随机初始化并初步更新
采用类似于VAR的多尺度VQ-VAE进行图像token化,以促进下一个尺度预测范式
VARGPT模型的top-k和top-p采样参数分别设置为900和0.95。此外,CFG尺度参数配置为1.5
我们在11个基准测试上评估了VARGPT在视觉理解方面的有效性,包括学术任务导向的基准测试和最近为指令跟随MLLMs提出的基准测试
对于视觉生成评估,我们构建了一个包含50,000个文本指令的评估数据集,以评估模型的生成能力
使用CLIP分数来评估文本指令与生成图像之间的CLIP分数
使用Frechet Inception Distance (FID)度量来评估我们的VARGPT模型生成的图像样本的质量,该模型在ImageNet-1K数据集上进行了训练
5.1.MainResults
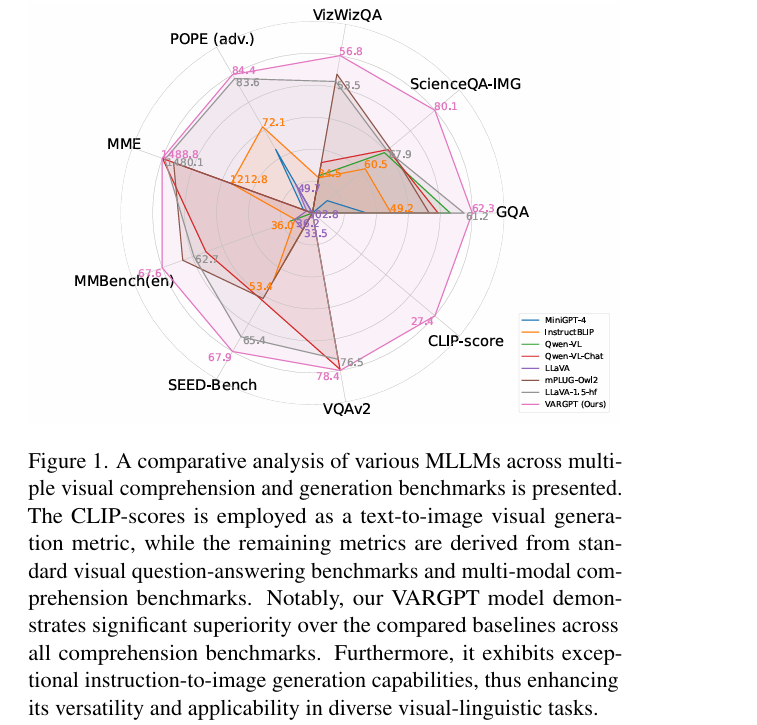
Evaluation on Multi-modal Benchmarks
- 进行了零样本多模态评估,并将我们的VARGPT与各种用于视觉理解的多模态模型进行了比较
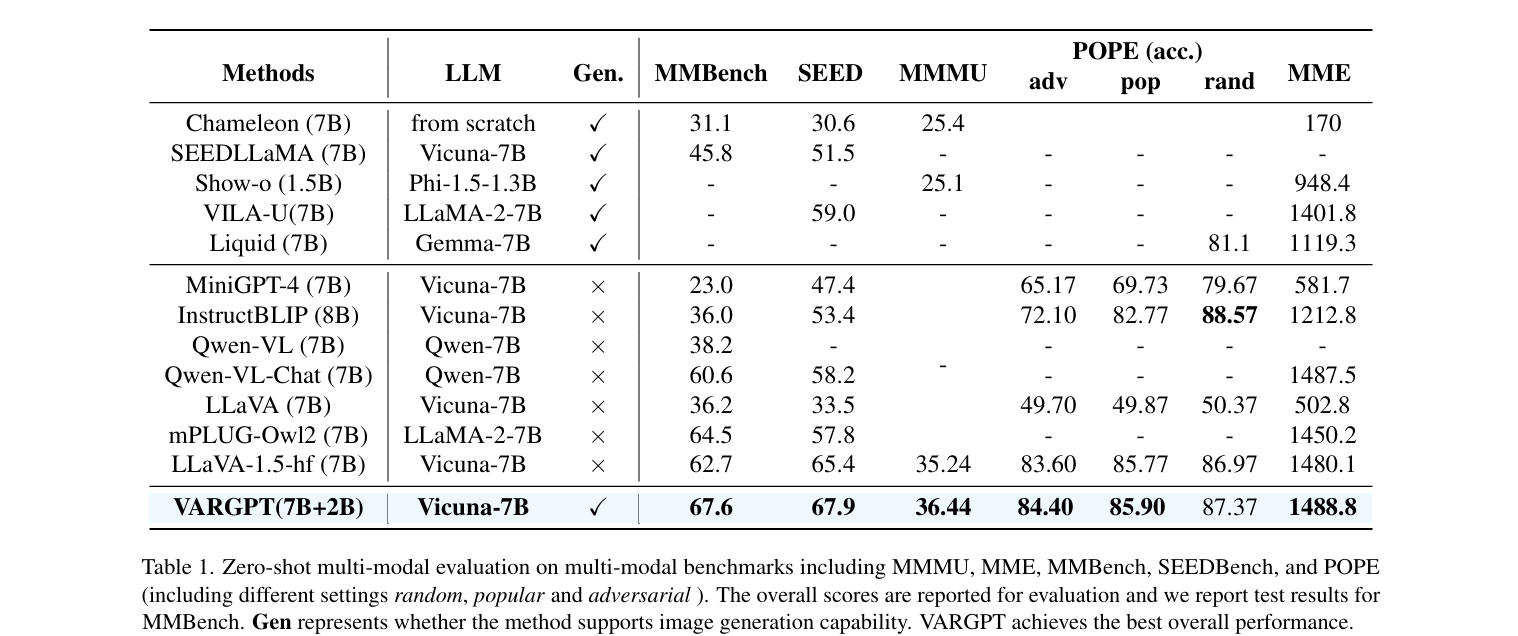
- 据结果有几个详细的观察:
- 我们的方法在大多数现有的用于视觉理解的MLLMs基线(包括LLaVA-1.5 、MiniGPT-4、InstructBLIP和Qwen-VL)上显著优于它们。VARGPT在所有基准测试和一些视觉幻觉评估基准测试(即POPE)上实现了更高的性能,这证明了我们的方法在视觉生成方面的优越性和泛化能力
- 尽管我们的视觉理解核心架构与LLaVA-1.5相似,但我们的方法实现了显著更好的性能,并且还在单一大型模型中支持视觉生成能力
Evaluation on visual question answering tasks
- 将各种视觉问答任务与现有方法进行了比较,结果如下表所示:
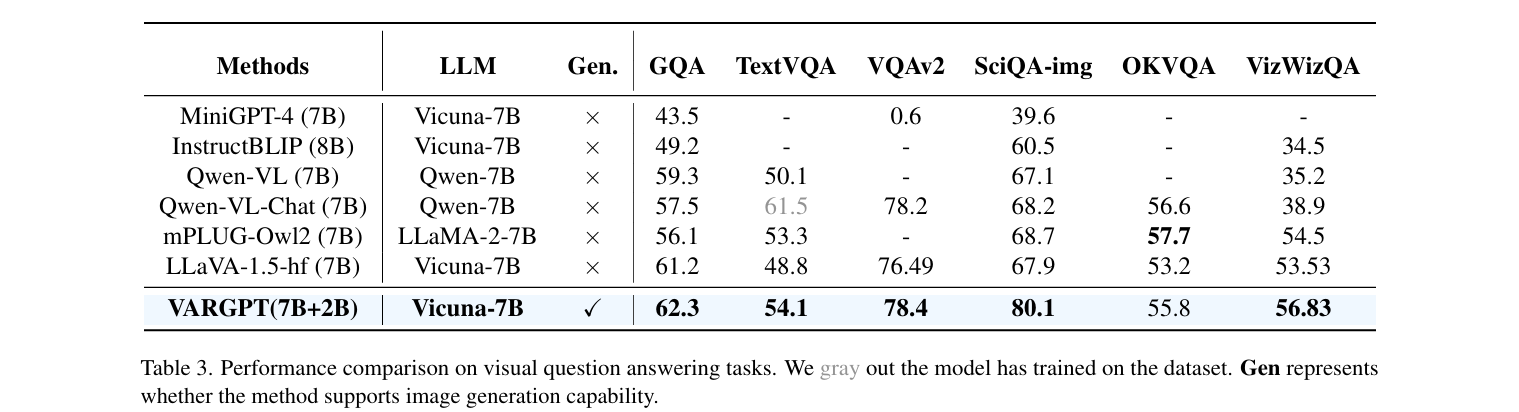
- 观察结果:
- VARGPT在大多数理解基准测试上始终取得最佳结果,超过了具有相同参数规模的用于视觉理解的MLLMs。进一步证明了我们的VARGPT的有效性
- 除了实现显著的理解能力(如在SciQA-img基准测试上比LLaVA-1.5高出12.2%),VARGPT还可以支持视觉生成能力
Evaluation on Instruction-to-image Task
了评估我们的VARGPT的视觉生成能力,我们构建了一个基于指令的问答生成评估数据集,包含50,000个样本
该数据集中的指令描述来自ImageNet-1K图像描述,每个类别限制50个样本以确保类别之间的平衡表示
为了定量评估VARGPT的指令跟随能力,我们评估了两个关键指标:
- 50,000个生成图像与ImageNet-1k数据集之间的FID分数
- 指令与生成图像之间的CLIP分数
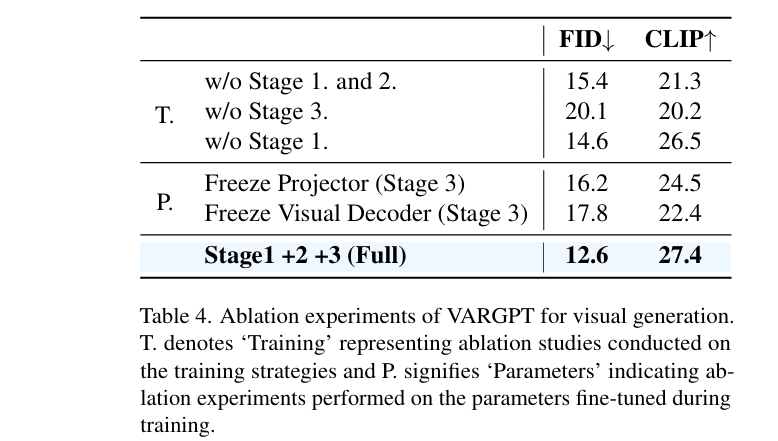
VARGPT能够生成高质量且紧密遵循给定指令的图像
值得注意的是,VARGPT展示了在单一对话中无缝集成文本描述和图像生成的能力,利用单一统一模型进行多模态输入和输出。这一能力进一步强调了VARGPT在统一视觉生成和理解任务中的独特优势
VARGPT使用的图像生成数据集(1.28M ImageNet)与其他统一模型(例如Show-1: 36M, VILA-U: 15M, Liquid: 30M图像)相比,规模较小且质量较低。因此,VARGPT的图像生成性能目前落后于这些方法
然而,通过数据扩展提高质量的潜力为未来的研究和开发提供了一个有前景的方向
5.2. Method Analysis
- 我们在模型参数、训练设置和数据效率方面对VARGPT进行了消融实验,以详细评估各个组件的有效性
Effect of the Training Strategies on Generation
- 在我们的训练协议中省略任何一个阶段或组合阶段都会导致模型视觉生成性能的显著下降
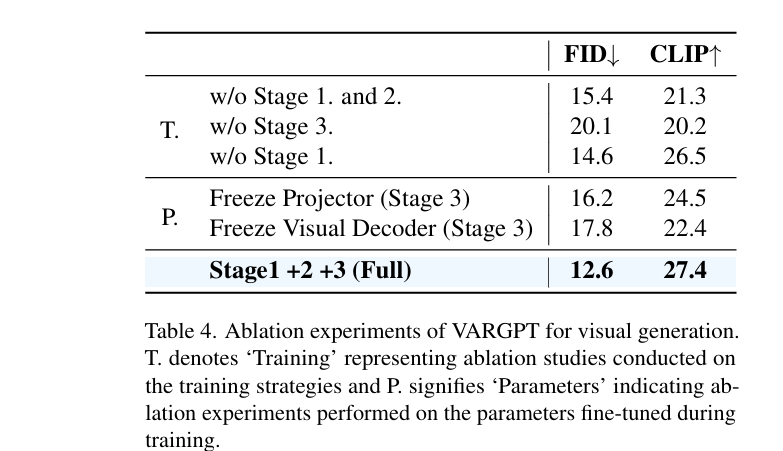
值得注意的是,移除第三阶段(涉及指令微调)会导致生成图像的质量和模型遵循给定指令的能力大幅下降
这些发现强调了每个训练阶段在提高模型视觉生成质量和文本到图像能力方面的关键作用
此外,我们进行了额外的实验,在第三阶段训练期间选择性地冻结映射器和视觉解码器参数。我们的观察表明,在第三阶段缺少这些组件的微调也会导致性能下降
这些结果为我们的三阶段训练策略的有效性提供了有力的证据,在各种消融场景中观察到的性能一致下降,强化了每个提议组件和阶段的重要性
Effect of the Training Strategies on Understanding
为了评估我们的训练策略对视觉理解能力的有效性,我们通过在第二阶段训练期间选择性地冻结组件进行了消融研究
我们分别进行了实验,在第二阶段进行指令微调时冻结映射器或LLM骨干,我们观察到在这两种情况下性能显著下降
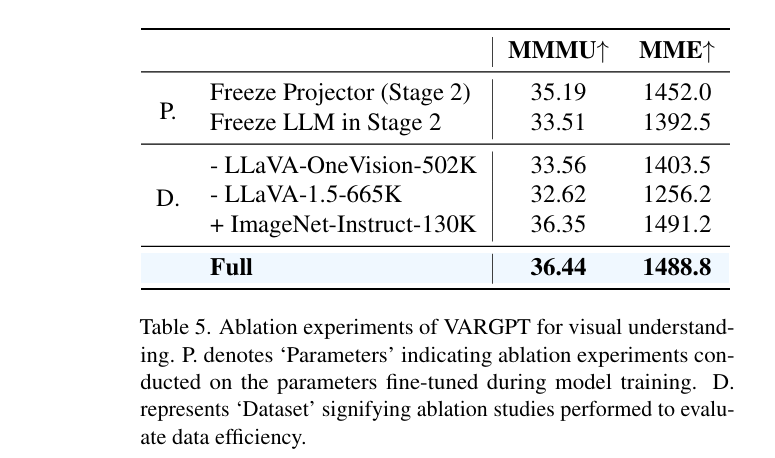
这些结果进一步验证了我们的训练策略在增强视觉理解能力方面的有效性
这一经验证据强调了在指令微调阶段允许映射器和LLM骨干适应的重要性,突出了我们提出的训练方法对模型整体视觉理解能力的协同效应
Effect of the Data Efficiency on Understanding
我们进行了实验来分析我们在第二阶段训练中使用的混合数据集
移除502K或665K理解数据集会对模型的理解性能产生负面影响
相反,当我们进一步纳入我们构建的生成指令数据集时,它增强了模型区分理解和生成指令的能力,并准确提高了VARGPT输出视觉生成特殊token(即
、 和 )的能力,而不会显著影响其理解性能
Visualization of Training Loss Curve
- 在下图中进一步展示了模型训练过程中第二阶段和第三阶段的损失曲线
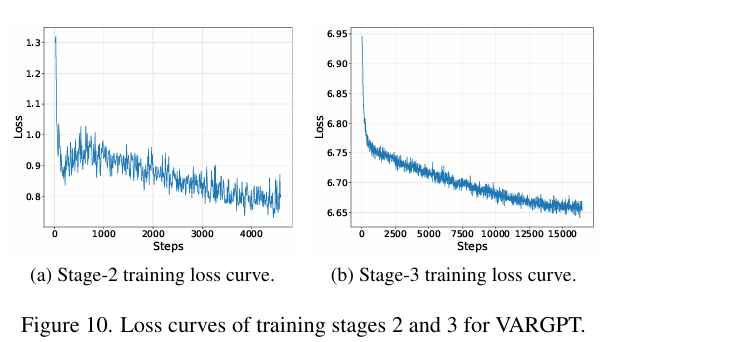
这些损失曲线中观察到的趋势显示出合理且一致的下降,为我们的学习策略的有效性提供了经验支持
对这些曲线的分析表明,训练损失随着时间的推移呈现出原则性的下降,这在很大程度上证实了我们提出的学习方法的有效性
对第三阶段损失曲线的更仔细检查表明,模型的视觉生成能力仍有显著的优化潜力。这一观察表明,延长训练时间和扩展训练数据集可以在第三阶段进一步提高视觉生成性能
6. Conclusion, Limitation and Future Work
Conclusion
VARGPT是一种新颖的MLLMs,成功地将视觉理解和生成集成在一个统一的自回归框架中
通过创新的下一个token和下一个尺度预测范式,VARGPT扩展了传统MLLMs的能力,包括高效的视觉自回归生成
该模型的三阶段训练管道利用特别策划的数据集,实现了视觉和文本特征之间的有效对齐,增强了理解和生成能力
VARGPT在各种以视觉为中心的任务中表现出优于现有模型(如LLaVA-1.5)的性能。此外,它在自回归视觉生成和文本到图像合成方面表现出卓越的熟练度
这些成就突显了VARGPT的多功能性和推动多模态AI领域发展的潜力,为未来统一多模态模型的研究提供了有意义的探索
Limitation
由于我们的视觉生成数据集主要来自ImageNet的图像,VARGPT与某些扩散模型(如SDv2.1和更先进的模型如FLUX)之间仍存在明显的质量差距,这些模型在广泛的高质量图像数据集上进行了预训练。这种差异主要归因于训练数据的不同
在整个训练过程中,生成图像的分辨率始终设置为256x256像素。因此,当前版本的VARGPT仅支持在此分辨率下的自回归图像生成
尽管VARGPT在指令理解和指令到图像生成方面表现出初步的熟练度,在大多数情况下能够有效遵循用户输入指令,但在某些情况下,指令中的某些细微细节可能无法充分反映在生成的图像中
这一局限性在某些情况下表现出来,表明模型在全面捕捉和渲染复杂指令细节方面仍有改进空间
Future Work
为了实现更高质量的图像生成并支持更高分辨率的输出,我们计划改进下一个尺度预测模型架构,扩展图像数据集,提高图像质量,并实现动态分辨率能力
在VARGPT的后续版本中,我们打算探索支持统一的自回归视频理解和生成
deepseek要点总结
论文提纲与核心要点总结
标题: VARGPT: 视觉自回归多模态大语言模型中的统一理解与生成
- 研究背景与动机
• 现有问题:
- 现有MLLMs(如LLaVA)专注于视觉理解但缺乏生成能力,扩散模型(如DDPMs)擅长生成但无法理解。
- 现有统一模型多依赖外部工具(如扩散模型),未实现端到端混合模态输入输出。
• 目标:
构建单一模型,支持视觉理解(文本生成)与视觉生成(图像合成)的统一框架,突破模态割裂。
- 核心创新点
- 双范式架构设计:
- 视觉理解: 基于LLaVA-1.5,采用next-token预测生成文本(问答/描述)。
- 视觉生成: 新增视觉解码器与投影器,采用next-scale预测自回归生成多尺度图像。
- 混合模态支持: 通过特殊标记(如
)实现文本与图像输出的无缝切换。
- 三阶段训练策略:
- 阶段1(预训练): 对齐视觉-文本特征(ImageNet数据)。
- 阶段2(指令微调): 优化多轮对话与视觉理解能力(LLaVA-1.5数据)。
- 阶段3(生成微调): 提升指令到图像生成质量(ImageNet-Instruct数据)。
- 数据构建:
- 构建ImageNet-Instruct指令数据集(130K~1.4M样本),通过LLM生成多样化指令模板。
- 实验与性能验证
- 视觉理解任务:
- 在MMBench、SEED-Bench、MMMU等基准中超越LLaVA-1.5、Qwen-VL等模型(如MMBench得分67.6 vs. LLaVA-1.5的62.7)。
- 减少视觉幻觉(POPE准确率84.4%),推理能力更强。
- 视觉生成任务:
- 支持混合模态输出(文本+图像),生成分辨率256×256。
- CLIP分数(27.4)与FID(12.6)优于基线,但受限于训练数据(ImageNet)规模,暂落后于大规模扩散模型。
- 消融实验:
- 三阶段训练缺一不可,冻结视觉解码器或投影器显著降低性能。
- 局限性与未来方向
• 当前局限:
- 生成质量受限于ImageNet数据规模与分辨率(仅256×256)。
- 复杂指令细节生成能力待提升。
• 未来计划: - 扩展高质量数据集,支持动态分辨率生成。
- 探索视频理解与生成统一框架。
- 核心贡献总结
- 首创双范式统一模型: 通过next-token(理解)与next-scale(生成)预测,实现端到端多模态统一。
- 高效训练框架: 三阶段分步优化,兼顾特征对齐与任务性能。
- 开源数据与代码: 构建大规模指令数据集,模型与代码开源(项目页: vargpt-1.github.io)。
阅读价值:
• 技术突破: 首次在单一自回归模型中融合视觉理解与生成,为多模态统一模型提供新思路。
• 应用潜力: 可拓展至教育、设计、交互式AI等领域,支持复杂多模态任务。
