
MetaMorph:Multimodal Understanding and Generation via Instruction Tuning
MetaMorph:Multimodal Understanding and Generation via Instruction Tuning(通过指令微调实现多模态理解和生成)
Abstract
在这项工作中,我们提出了视觉预测指令微调(Visual-Predictive Instruction Tuning, VPiT)——这是对视觉指令微调的一个简单而有效的扩展,它使得预训练的大语言模型(LLM)能够快速转变为一个统一的自回归模型,能够生成文本和视觉token
VPiT 教会LLM从任何以指令跟随格式整理的图像和文本数据输入序列中预测离散的文本token和连续的视觉token
实证研究揭示了VPiT的几个有趣特性:
- 视觉生成能力作为视觉理解能力提升的自然副产品出现,并且可以通过少量的生成数据高效解锁
- 虽然我们发现理解和生成是相互促进的,但理解数据对这两种能力的贡献比生成数据更有效
基于这些发现,我们训练了MetaMorph模型,并在视觉理解和生成方面取得了有竞争力的表现
在视觉生成方面,MetaMorph能够利用从LLM预训练中获得的世界知识和推理能力,并克服其他生成模型常见的失败模式
我们的结果表明,LLM可能具有强大的“先验”视觉能力,这些能力可以通过相对简单的指令微调过程高效地适应视觉理解和生成任务
1 Introduction
多模态大语言模型(Multimodal Large Language Models, MLLMs)在视觉理解方面取得了显著进展,从基本的图像描述发展到复杂的视觉推理。这些模型处理多模态输入——主要是图像和语言——并生成文本token
多模态LLM通常利用预训练的视觉编码器、预训练的语言模型,并通过MLP或交叉注意力模块等连接器对齐这些模态
在MLLM的训练方法中,视觉指令微调已被广泛使用。它将预训练视觉编码器的输出嵌入视为连续的“视觉token”,并直接将其作为输入传递给预训练的LLM
视觉指令微调的一个好处是它在数据和计算上是高效的。通过使用数百万个图像-文本问答对进行指令微调,预训练的LLM可以用适度的计算和数据重新用作多模态LLM
视觉指令微调的有效性表明,LLM已经具备了相当多的内在视觉知识,这使得它们能够在指令微调过程中高效地学习和发展视觉理解能力
受此启发,我们研究了LLM是否也可以通过微调来生成视觉信息,并且具有相当的效率和效果
当前的“统一”模型——即能够同时进行多模态理解和生成的模型——通常将视觉生成视为与视觉理解正交的能力
往往需要对原始MLLM架构进行重大修改,并进行大量的多模态预训练和/或微调
设计这样的方法具有挑战性,过去的研究采取了不同的方法,包括将视觉输入token化为离散token、结合扩散目标,以及将视觉解耦为单独的理解和生成模式
例如,像LWM、Show-o和Chameleon这样的方法需要数十亿的图像-文本对进行广泛的预训练和微调
在这项工作中,我们提出了视觉预测指令微调(VPiT)——这是对视觉指令微调的一个简单扩展,它建立在将连续视觉token作为输入传递给LLM的现有范式之上
VPiT在微调阶段训练LLM输出连续视觉token和离散文本token。模型接受预训练视觉编码器的嵌入以及文本token作为输入,并输出文本token和连续视觉token的组合
为了可视化生成的视觉token,我们微调了一个扩散模型,将嵌入映射回像素空间,如下图所示
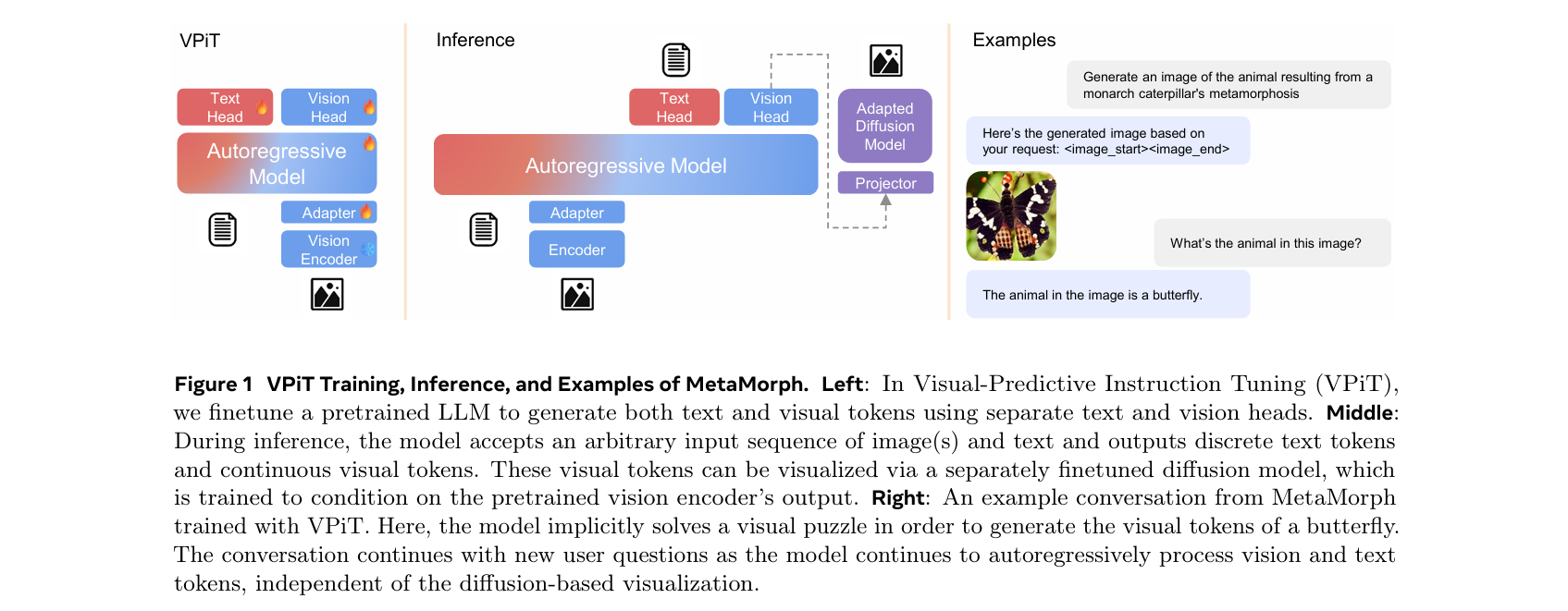
这个框架使我们能够研究视觉理解、视觉生成和预训练LLM之间的协同作用,从而得出以下几个有趣的发现:
- 预测视觉token的能力从理解视觉输入中自然涌现,并且只需要最少的额外训练。与视觉指令微调类似,VPiT高效且有效地将LLM转变为一个“统一”模型,能够理解和生成多模态token
- 理解和生成视觉token的能力是内在关联且不对称的。增加理解数据可以提高视觉理解(通过更高的VQA分数衡量)和生成性能(通过更低的FID分数衡量)。相反,增加生成数据可以提高生成质量,同时也有助于增强视觉理解——但程度较小。训练每种能力对模型整体视觉性能的影响的不对称性:以理解为中心的训练在提高视觉理解和生成方面显著优于以生成为中心的训练
基于这些发现,我们训练了一个名为MetaMorph的统一模型,使用VPiT预测多模态token
利用从常见的视觉问答数据集到没有文本注释的纯图像和视频数据的多样化数据源
MetaMorph在视觉理解和视觉生成基准测试中均取得了有竞争力的表现
此外,我们展示了这种统一建模方法使模型能够利用LLM的强大能力。例如,MetaMorph在生成视觉token时可以从预训练的LLM中提取知识
更令人惊讶的是,我们观察到MetaMorph可以在生成视觉token之前隐式执行推理步骤——例如,当提示为“由帝王蝶毛毛虫变态而成的动物”时,MetaMorph成功生成了蝴蝶的图像(上图右)
我们的结果表明:
- 通过指令微调训练统一模型是可行的
- LLM具有强大的先验视觉能力,这些能力可以通过显著少于广泛预训练的样本数量来激活
这些见解为混合模态模型的开发提供了启示
推进基础LLM、指令微调技术和数据来改进多模态LLM中的视觉理解也可能隐式地导致模型在视觉生成方面表现更好
2 Visual-Predictive Instruction Tuning(视觉预测指令微调)
LLaVA引入的视觉指令微调表明,LLM可以通过数百万级数据的微调来理解视觉输入
后期融合指令微调的成功表明,LLM可能已经具备了内在的视觉理解能力,只需通过轻量级微调即可解锁
类似地,我们假设LLM已经具备了一定程度的内在视觉生成能力,只需通过轻量级微调即可解锁
受此启发,我们提出了视觉预测指令微调(VPiT,下图)——这是一个简单的设计,扩展了现有的指令微调方法,使其能够生成视觉token而不仅仅是文本
使用相同的架构和下一个token预测范式来解锁视觉生成能力,无需复杂的修改
采用预训练的LLM并对其进行微调,以预测离散文本token和连续视觉token。视觉token可以通过适配的扩散模型进行可视化
2.1 From Unimodal to Multimodal Next-Token Prediction
标准的指令微调设置由对话轮次的输入序列组成:(Pi,Ri)(i=1~N),其中Pi和Ri分别表示第i轮对话的提示和响应。模型被训练为根据提示生成响应
VPiT在标准指令微调设置中添加了以下机制,以解锁视觉理解和生成能力
Tokenizing multimodal data
我们将Pi和Ri扩展为包含文本和图像
为了将视觉数据集成到预训练的LLM中,我们紧密遵循视觉指令微调处理数据:
- 文本数据:文本通过LLM使用的标准tokenizer进行token化,生成离散token
- 视觉数据:图像通过预训练的视觉编码器(如SigLIP)进行编码。输出是连续的视觉token,然后将其插值为m=64个token。为了将视觉token作为输入传递给LLM,我们应用了一个可训练的投影层,以将其维度与LLM对齐
Model architecture
采用预训练的LLM并对其进行微调,以处理任意序列的文本和视觉token(详见第2.2节)
保留原始的LLM头部用于文本预测,并附加一个单独的视觉头部到LLM,用于预测视觉token,即视觉编码器处理图像时生成的输出token
视觉头部是一个投影层,将LLM的维度投影到视觉编码器的维度
然后,所有响应token都可以自回归地训练和预测,提示token作为上下文
与传统的视觉指令微调不同,在VPiT中,视觉token也是LLM的输出——而不仅仅是输入
为了使LLM意识到视觉token的存在,我们引入了特殊token ⟨image_start⟩和 ⟨image_end⟩ 来指示视觉token序列的边界以及何时使用视觉头部
Loss functions
语言头部输出词汇表上的概率分布,并通过交叉熵损失进行下一个token预测的训练
视觉预测使用LLM预测的视觉token与视觉编码器生成的视觉token之间的余弦相似度损失
与指令微调实践一致,模型仅在响应token上进行预测并产生损失
2.2 Using Broad Types of Data
由于VPiT使模型能够在其响应中预测文本和视觉token,因此它允许使用更广泛的训练数据
传统的视觉指令微调主要依赖于问答对
我们的大多数数据集是公开可用的,我们将其分为以下三大类:
- 视觉理解数据:这类数据以图像或视频作为输入,并输出文本响应
- ImageQA:Cambrian-7M(Tong et al.)。模型根据输入图像回答问题。Pi∈{视觉token⟩,(文本提示)},Ri∈{(文本响应)}
- VideoQA:VideoStar和ShareVideo。模型根据输入视频回答问题。对于VideoQA中的视频,我们以1 FPS处理帧。Pi∈{视觉token⟩,⋯,(视觉token), (文本提示)},Ri∈{(文本响应)}
- 视觉生成数据:MetaCLIP。模型根据图像描述预测视觉token。我们最多使用500万对数据。将数据整理为问答格式。Pi∈{(文本提示)},Ri∈{(文本响应), (视觉token)} 通过指令提示模型生成视觉token,如“生成一个…的图像”。文本响应为“这是根据您请求生成的图像…”
- 其他视觉数据:这类数据要求模型在给定交错的输入视觉token和文本token的情况下预测视觉token
- 视频数据:SomethingSomethingV2和HowTo100M。模型按顺序预测帧。我们设计了不同的问答对来探究视频,例如询问未来帧、过去帧和重新排序帧。Pi∈{视觉token,⋯, (视觉token), (文本提示)},Ri∈{视觉token,⋯, (视觉token)}
- 视觉思维数据:Visualization-of-Thought和VStar。模型在解决问题之前预测其响应中的多模态token。例如,它在生成文本响应之前预测图像的放大视图。Pi∈{视觉token, (文本提示)},Ri∈{文本响应, (视觉token), (文本响应)} 在响应中,模型将输出“我将从视觉上思考”,然后输出表示图像放大片段的视觉token,接着回答问题
- 图像到图像数据:InstructPix2Pix和Aurora。模型根据文本描述和输入图像生成转换后的图像。Pi∈{视觉token, (文本提示)},Ri∈{视觉token}
- 视觉理解数据:这类数据以图像或视频作为输入,并输出文本响应
2.3 Mapping Tokens to Images through Diffusion(通过扩散模型将token映射到图像)
由于使用VPiT训练的模型学会预测连续视觉token,我们需要将预测的token映射回像素空间
利用了“扩散自编码器”的概念,其中扩散模型可以适应于以图像嵌入而不是文本嵌入为条件
具体来说,我们微调了一个现有的扩散模型,使其以视觉编码器的输出为条件,使用保留的训练数据
在推理时,如果生成了标签token⟨image_start⟩,模型开始输出视觉token,直到⟨image_end⟩
然后,我们将生成的视觉token插入扩散模型,以在像素空间中可视化预测
3 Findings on Unlocking Visual Generation
- 我们研究了以下关于视觉理解和生成效果及其协同作用的问题,基于我们的VPiT框架:
- SS3.1 视觉生成是否可以通过轻量级微调解锁,还是需要大量数据?
- SS3.2 视觉理解和生成是相互促进的还是正交的?
- SS3.3 更多的视觉理解或生成数据对理解和生成质量的贡献有多大?
- SS3.4 哪些视觉理解任务与生成性能最相关?
3.1 Visual Generation Can Be Unlocked Efficiently by Joint Training with Visual Understanding(视觉生成可以通过与视觉理解联合训练高效解锁)
我们首先研究了教会语言模型生成高质量视觉token所需的图像-文本样本数量
为此,我们从生成数据中随机抽取{1k, 5k, 10k, 50k, 200k, 1M, 3M, 5M}图像-文本对。我们探索了两种设置:
- 仅使用视觉生成数据微调LLM
- 将视觉生成与视觉理解和其他数据类型(如第2.2节所述)联合训练
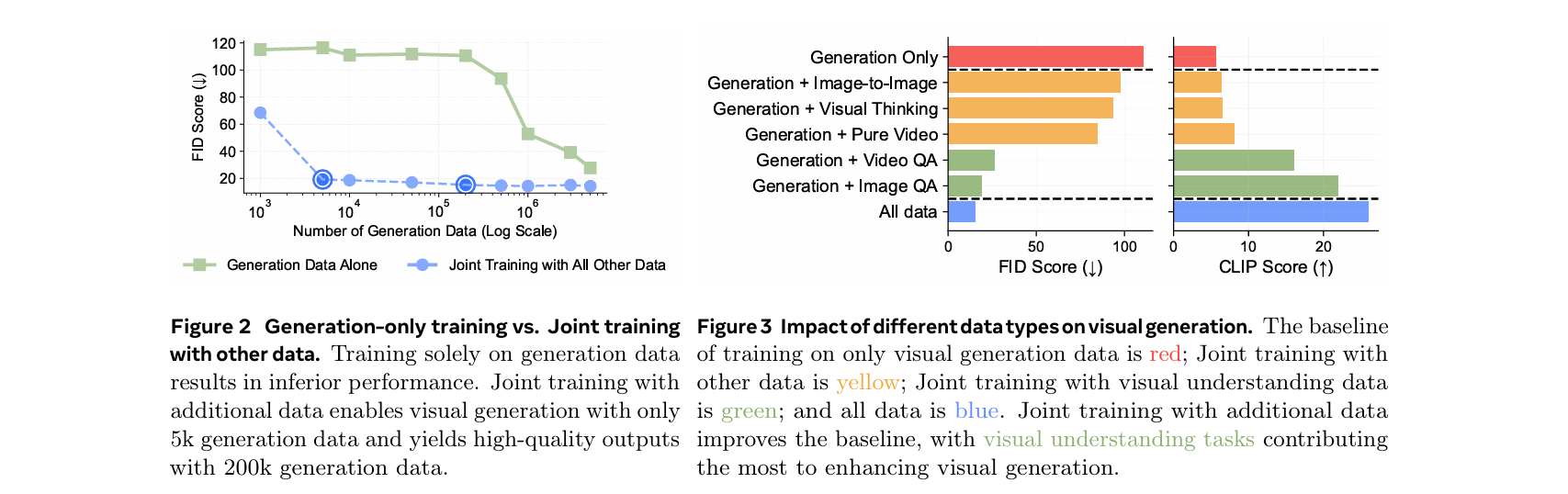
如上图左所示,仅使用视觉生成数据进行训练的效果显著低于与所有其他数据联合训练的效果
即使使用超过300万图像-文本对,模型仍然难以生成高质量的视觉图像(FID分数约为40),并且性能仍然低于使用500万对数据进行联合训练的效果
这表明仅使用视觉生成数据进行训练显著降低了样本效率
该研究也表明,当仅使用生成数据进行训练时,LLM不容易被微调以生成视觉token
相比之下,与其他数据集联合训练显著提高了生成性能
这表明视觉生成并不是一种正交的能力,而是一种受益于其他任务并在联合训练中更有效涌现的能力
为了更好地理解每种数据类型对视觉生成的贡献,我们使用200k视觉生成数据进行了对照实验,分别与第2.2节中定义的每种数据类型进行联合训练
如上图右所示,虽然所有数据类型都增强了模型的视觉生成能力,但改进的程度各不相同:视觉理解数据,如ImageQA和VideoQA,显著提升了模型的视觉生成能力
这表明理解视觉内容的能力与生成视觉token的能力之间存在强烈的联系。此外,将所有数据类型结合在训练中进一步提高了性能,这表明不同数据类型的益处可以叠加
发现1:当模型与视觉理解数据联合训练时,视觉生成能力可以通过显著较少的生成数据解锁,相比之下,仅使用生成数据进行训练则需要更多的数据
3.2 Visual Understanding and Generation are Mutually Beneficial(视觉理解和生成是相互促进的)
More understanding data leads to better understanding and generation
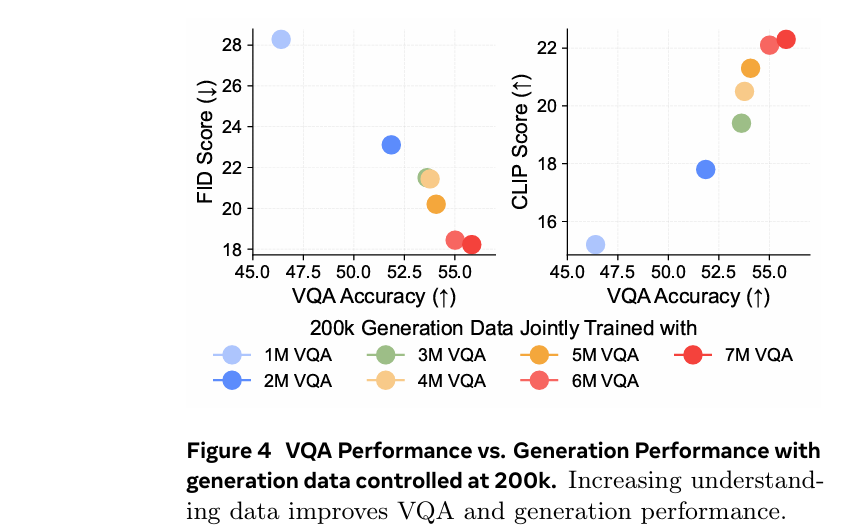
基于上一小节的发现,我们进行了对照实验,研究视觉理解能力与视觉生成能力之间的相关性
如下图,结果表明,更强的VQA能力与更好的生成性能相关
More generation data leads to better understanding and generation
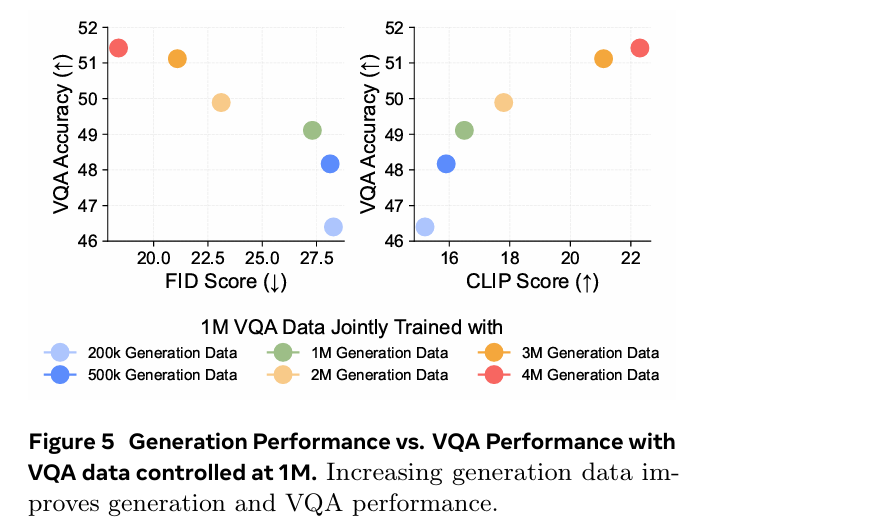
我们研究了相反的方向:增强模型的视觉生成能力是否也与更高的VQA性能相关?
为了探索这一点,我们使用1M固定的VQA样本作为理解基线,然后通过改变生成数据的数量({200k, 500k, 1M, 2M, 3M, 4M})来调整生成能力,同时与固定的1M VQA数据进行联合训练
结果如下图所示,在1M VQA设置中,更强的生成能力与改进的VQA性能相关。这意味着增加生成数据的数量不仅增强了生成能力,还对VQA性能产生了积极影响
This synergy scales across different LLMs(这种协同作用在不同LLM之间具有扩展性)
- 下图展示了不同LLM之间的扩展行为
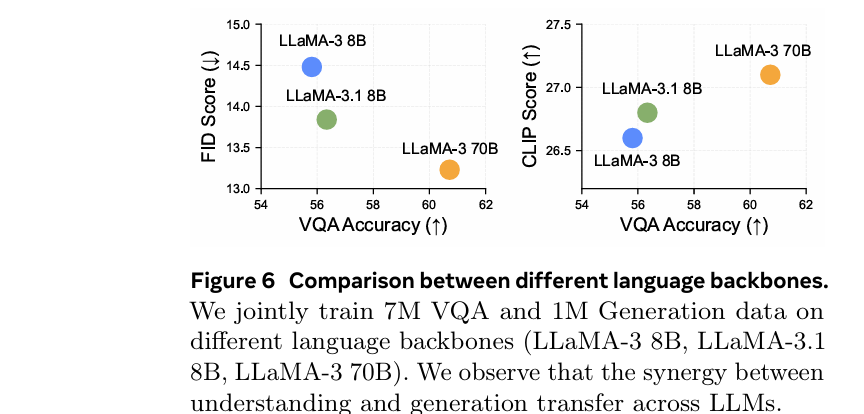
- 发现2:视觉理解和生成是协同的。增加任何一种能力的数据都会同时增强这两种能力
3.3 Understanding Data Contributes More
我们研究了理解和生成数据是否贡献相等。在这里,我们联合训练不同规模的VQA数据{1M, 4M, 7M}和生成数据{200k, 500k, 1M, 2M, 3M, 4M}
下图总结了这些发现,x轴表示VQA数据,y轴表示生成数据。结果通过热图可视化,颜色越深表示性能越好
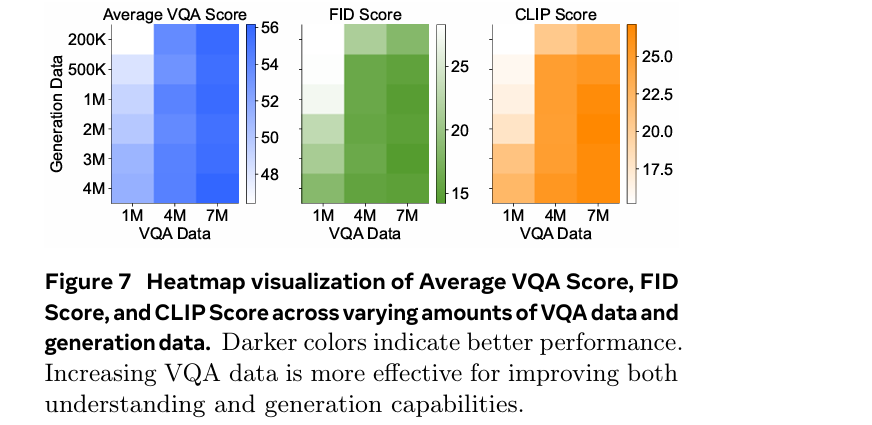
结果表明,增加VQA数据在所有三个指标上都带来了最显著的改进
当VQA数据相对较低(1M)时,增加生成数据会带来明显的改进,如图中颜色逐渐变深所示
然而,随着VQA数据的增加(从1M到4M再到7M),VQA数据的影响变得更加显著,表现为热图中颜色的急剧变化
最终,在7M VQA数据的情况下,增加生成数据的贡献微乎其微
这些结果证明了理解数据在增强理解和生成性能方面的关键作用
发现3:虽然增加数据总体上提高了性能,但视觉理解数据的影响显著大于视觉生成数据的影响
3.4 Certain Understanding Tasks Correlate More with Generation Performance
鉴于理解任务的多样性,如OCR、视觉中心任务和基于知识的任务,我们研究了哪些任务与生成能力最密切相关
受Cambrian-1的启发,我们将VQA任务分为五类:通用、文本和图表、高分辨率、知识和视觉中心VQA
使用我们早期实验的结果,这些实验联合训练了不同规模的VQA数据和不同数量的生成数据,我们在下图中绘制了每个基准的VQA性能与生成性能的关系
我们还计算了VQA分数与FID/CLIP分数之间的Pearson相关性(ρ)
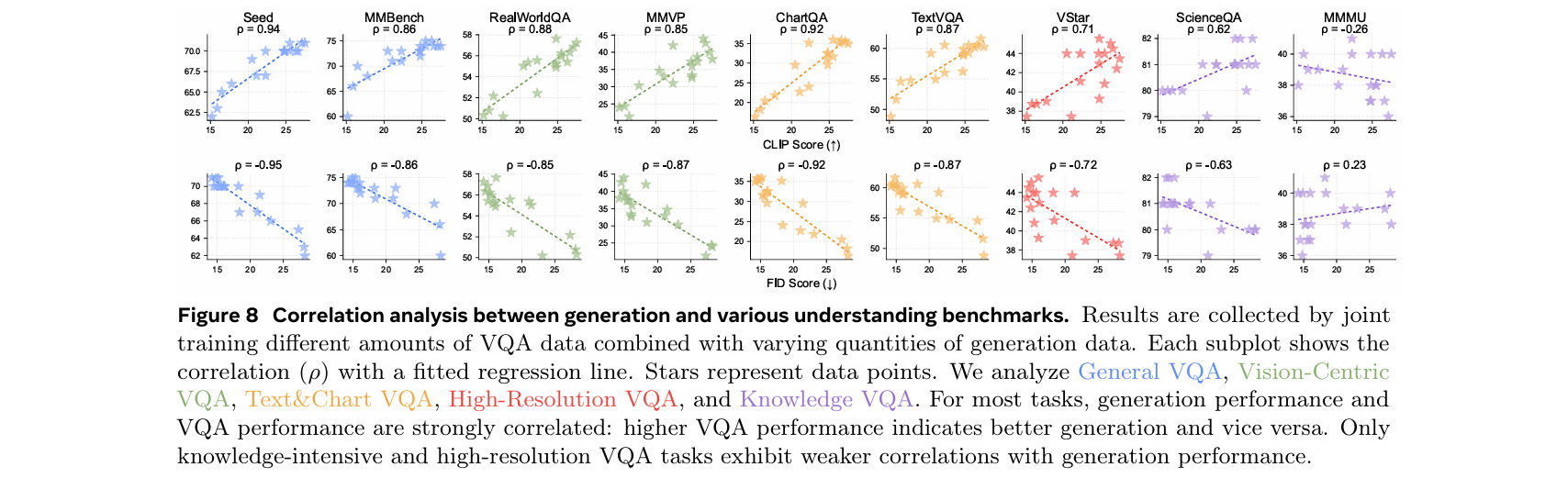
通用、视觉中心和文本与图表VQA任务与生成性能密切相关,每个任务的Pearson相关系数(ρ)均高于0.85
高分辨率VQA表现出中等相关性,ρ约为0.7
相比之下,知识VQA任务(如MMMU)与生成性能的相关性较弱
这些发现表明,生成能力与模型的视觉能力更密切相关,而不是与知识特定任务相关
发现4:通用、视觉中心和文本理解的VQA任务与视觉生成表现出强相关性,而基于知识的VQA任务则没有这种相关性
4 MetaMorph Model
基于第3节的见解,我们训练了我们的统一模型MetaMorph,基于LLaMA-3.1 8B,使用VPiT和第2.2节中整理的数据
我们在三个部分中展示了实验结果:定量性能(第4.1节)、MetaMorph在视觉生成中利用LLM知识的证据(第4.2节)以及多模态上下文中的隐式推理技能(第4.3节)
4.1 Competitive Performance in Understanding and Generation
- 将MetaMorph与其他统一模型进行了比较,结果如下图所示
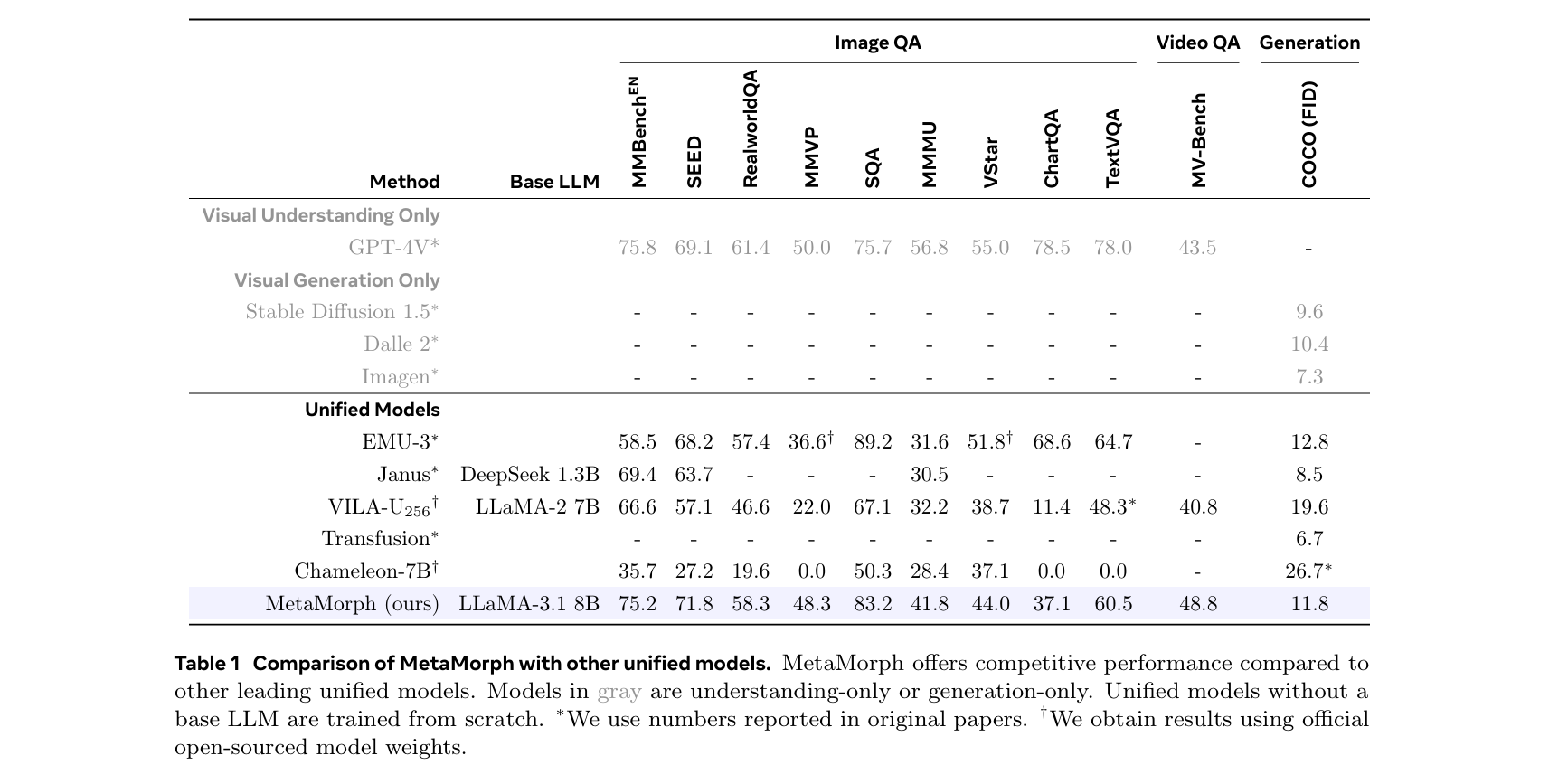
MetaMorph展示了竞争性的表现,并在大多数基准测试中优于其他统一模型——即使之前的模型可能使用了更多的数据进行训练
MetaMorph利用了最新预训练LLM的优势,并在理解和生成方面取得了竞争性的表现。MetaMorph强调了统一模型可以从预训练的LLM中有效开发
4.2 MetaMorph can Leverage LLM Knowledge for Visual Generation(MetaMorph可以利用LLM知识进行视觉生成)
- MetaMorph有效地利用了预训练LLM中嵌入的世界知识,如下图所示

我们提示模型生成需要非平凡和专业知识的概念。示例包括“Chhogori”(世界第二高峰)、“Oncilla”(南美洲的一种小型野猫)和“Chizarira”(津巴布韦的一个孤立荒野地区)
MetaMorph成功地将领域特定知识转化为准确的视觉token,从而展示了利用LLM中的世界知识的能力
MetaMorph比CLIP和T5等文本嵌入模型更有效地处理常见的语义挑战。这些挑战包括否定和主观性,使用提示中包含常见失败模式的提示
4.3 Reasoning in Multimodal Generation
- 下图展示了模型在响应谜题提示时生成图像的示例,例如“黄石国家公园所在国家的国旗”。对于每个谜题,我们直接使用提示“生成{谜题}的图像”,而没有在提示中调用任何思维链(CoT)

当回答“一种乐器,这种乐器通常由提出狭义相对论的科学家演奏”时,模型需要隐式完成三个推理步骤:它识别出提出狭义相对论的科学家是阿尔伯特·爱因斯坦,认识到他偏爱的乐器是小提琴,然后直接生成正确的视觉token——小提琴——而无需在生成过程中显式分离这些步骤
这一结果表明,MetaMorph隐式解决了谜题,并在提示后立即生成了正确的视觉token
这些结果与LLM的物理学中的发现一致,作者认为LLM在自回归生成后续token之前预先计算了推理图。我们展示了这种能力即使在解码视觉token时也能转移到统一的多模态模型设置中
5 Related Work
Instruction tuning and visual instruction tuning
指令微调通过微调预训练的LLM来学习交互的格式和风格。这个过程帮助模型有效地传达在预训练中获得的知识和能力
LLaVA将指令微调扩展到多模态领域
From Multimodal LLMs to unified models
最近构建统一模型的努力主要依赖于广泛的预训练或对数十亿级数据集进行大量微调
一些研究还使用连续嵌入来预测视觉token,整合视觉回归损失或利用基于扩散的方法
其他方法将多模态数据token化为离散token,然后使用自回归transformer进行训练
最近的研究还探索了结合自回归和扩散目标的混合策略
与之前的研究不同,我们展示了统一模型可以在指令微调期间在低数据量下有效训练,同时提供了关于视觉理解和视觉生成之间相互关系的见解
6 Discussion
在这项工作中,我们提出了VPiT——这是对视觉指令微调的一个简单而有效的扩展——它使LLM能够预测多模态token
VPiT解锁了比视觉问答更广泛的指令微调数据的使用,例如文本到图像和纯图像和视频数据
通过对照实验,我们发现视觉生成能力作为视觉理解能力提升的自然副产品出现,并且只需要少量的额外生成数据
此外,我们发现虽然视觉理解和生成是相互促进的,但增加更多的视觉理解数据在提高整体性能方面比增加生成数据更为显著
基于这些见解,我们通过使用VPiT微调LLaMA-3.1 8B来训练MetaMorph。通过简单的训练过程,MetaMorph在视觉理解和生成方面都取得了竞争性的表现
MetaMorph可以在视觉生成过程中利用基础LLM的世界知识和推理能力
总体而言,LLM可能具有与统一和多功能模型相似的表示空间。我们希望这项工作的见解能够激发更多关于开发LLM以实现通用智能的探索
DeepSeek 要点总结
论文提纲与核心要点总结
- 标题: MetaMorph: 通过指令微调实现多模态理解和生成
- 作者: Shengbang Tong 等(Meta、纽约大学团队)
1. 研究背景与问题
多模态LLM现状:
- 现有统一模型(理解和生成)需数十亿级数据预训练,计算成本高昂。
核心问题:
能否通过轻量级指令微调解锁LLM的潜在视觉生成能力?
视觉理解与生成是否相互促进?
2. 核心方法:视觉预测指令微调(VPiT)
方法设计:
- 统一自回归框架:将文本和视觉token共同作为输入输出,保留LLM原有架构,仅添加轻量级视觉头部。
数据格式:
文本通过标准tokenizer处理,图像通过预训练视觉编码器(如SigLIP)编码为连续视觉token。
引入特殊标记(
和 )标识视觉内容边界。
训练目标:
- 文本生成:交叉熵损失;视觉生成:预测视觉token与编码器输出的余弦相似度损失。
可视化
- 通过微调扩散模型将生成的视觉token映射为像素图像(如Stable Diffusion)。
创新点:
无需复杂架构改动:直接扩展现有视觉指令微调框架,实现多模态生成。
数据高效:联合训练理解与生成任务,显著降低生成数据需求(仅需200k样本)。
3. 关键实验发现
视觉生成的涌现性:
生成能力是视觉理解的副产品:联合训练理解任务(如VQA)时,仅需少量生成数据即可解锁高质量生成能力(5k样本即可生成合理图像)。
仅生成数据训练效果差:单独训练生成任务需数百万样本,且性能显著低于联合训练(FID分数差距达50+)。
理解与生成的协同性与不对称性:
协同性:增加理解数据(VQA)可提升生成质量(FID↓),增加生成数据亦可提升理解能力(VQA分数↑)。
不对称性:理解数据对生成能力的贡献远大于生成数据对理解的贡献(7M VQA数据+200k生成数据 > 1M VQA数据+4M生成数据)。
任务相关性:
- 通用视觉任务(如物体识别)与生成能力高度相关(Pearson ρ>0.85),知识型任务(如MMMU)相关性较弱。
模型扩展性:
- VPiT在不同规模LLM(如LLaMA-3 8B/70B)上均有效,更大模型性能更优。
4. MetaMorph模型表现
多任务性能:
视觉理解:在9个ImageQA基准(如MMBench、ScienceQA)中优于多数统一模型(如EMU-3、Chameleon)。
视觉生成:FID分数(11.8)接近Stable Diffusion(9.6),但能生成更复杂的语义内容。
LLM知识迁移:
生成专业术语图像(如“Chhogori”山峰、“Oncilla”野猫),优于传统T2I模型(如Stable Diffusion)。
解决需多步推理的生成任务(如“黄石国家公园所在国家的国旗→美国国旗”)。
隐式推理能力:
- 无需显式思维链(CoT),直接生成符合逻辑的视觉内容(如“爱因斯坦演奏的乐器→小提琴”)。
5. 贡献与意义
方法论贡献:
提出VPiT框架,证明LLM可通过轻量级指令微调实现高效多模态统一建模。
揭示LLM具备潜在视觉先验能力,仅需少量数据激活。
实践意义:
降低多模态模型训练成本,推动开源模型发展。
为结合LLM知识与生成任务(如教育、设计)提供新思路。
6. 未来方向
探索更复杂的多模态任务(如视频生成与推理)。
研究LLM视觉先验的边界(如3D生成、物理规律理解)。
优化扩散模型与LLM的协同训练策略。
