自然语言处理 lec5 hmm
Sequence Tagging I- Hidden Markov Models
Generative Models v.s. Discriminative Models
- Generative Models – Naive Bayes:

可能需要多个相关决策并且了解他们的背景,任务可以拆成小的决策,最后聚合成为大的决策:类似于抽取器,抽取特点,进行预测
Discriminative Models –Log-Linear model:
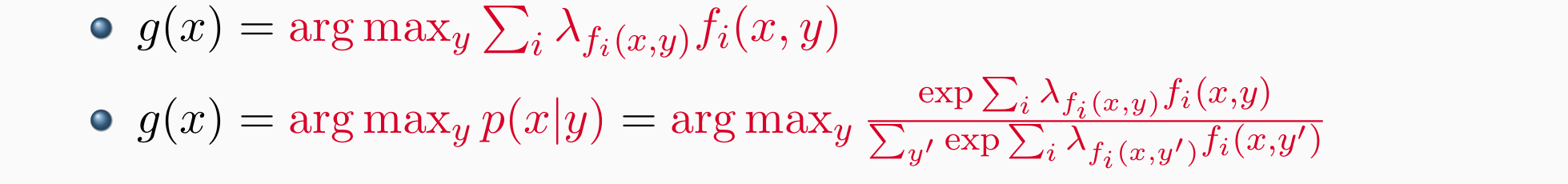
- 更好地适应拥有大量标注数据的目标决策场景,找到可以区分的特征,例如狗带项圈
The Sequence Tagging Problem
给定一个序列的项目,任务是针对序列中的每一个词标注决策对最后的任务有没有帮助,挑选出有帮助的部分
最终小的分类决策可以聚合成复杂结构
常用于语言标注、语音标注、词性标注、分词、切出名词块、大小写分析、口音恢复、信息抽取
NP Chunking and Named Entity Recognition
- 输入:一句话;输出:每个词给出词性标注

- Noun phrase chunking:找到句子中的名词短语

- Named entity recognition:找到命名实体,例如:名字、人物、地点、组织……

- 需要自己定义标签,关键在于如何处理序列的划分
Segmentation as Sequence Tagging
- NP Chunking:3个tags:
- B:beginning of a NP
- I:continuing NP
- O:other words

BIO(BIOE)标记模式:
- Beginning-Inside-Other
- Beginning-Inside-Ending-Other
问题:
- 多个命名实体重叠干扰:e.g.北京市政府
- 实体可以不连续:有一个或多个O
Word Segmentation
- 任务:中文日语的分词问题

- 问题:
- 分词是主观的,不同的场景应该采用不同的策略
- 多义性

- 核心:需要考虑上下文,和序列的性质
Two classes of words : Open vs. Closed
- Closed class words:词的类型比较集中,主要为功能性的词,比较短比较常用的词

- Open class words:具有实际意义的词以及一些新兴词


- Open class words可能具有各种变化,难以界定
Tagset
- 标签集:精细部分词效的标准化代码

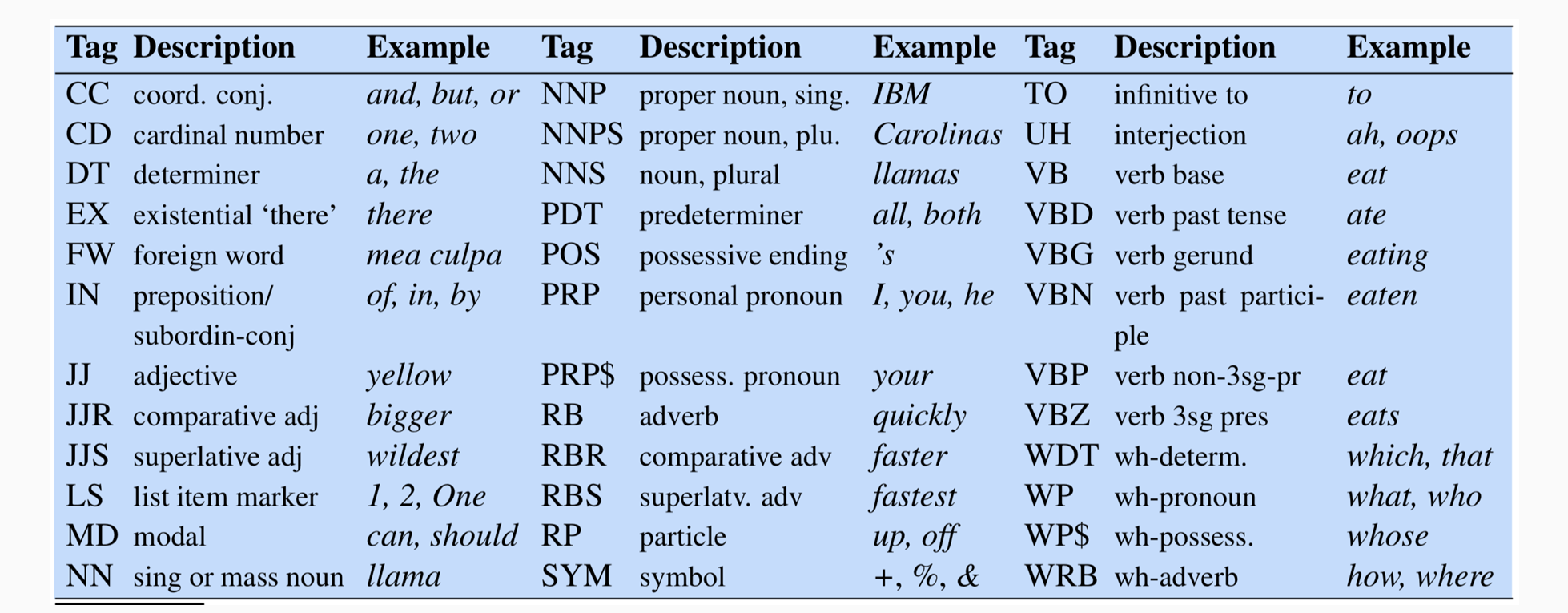
- Penn Tree Bank Tagset
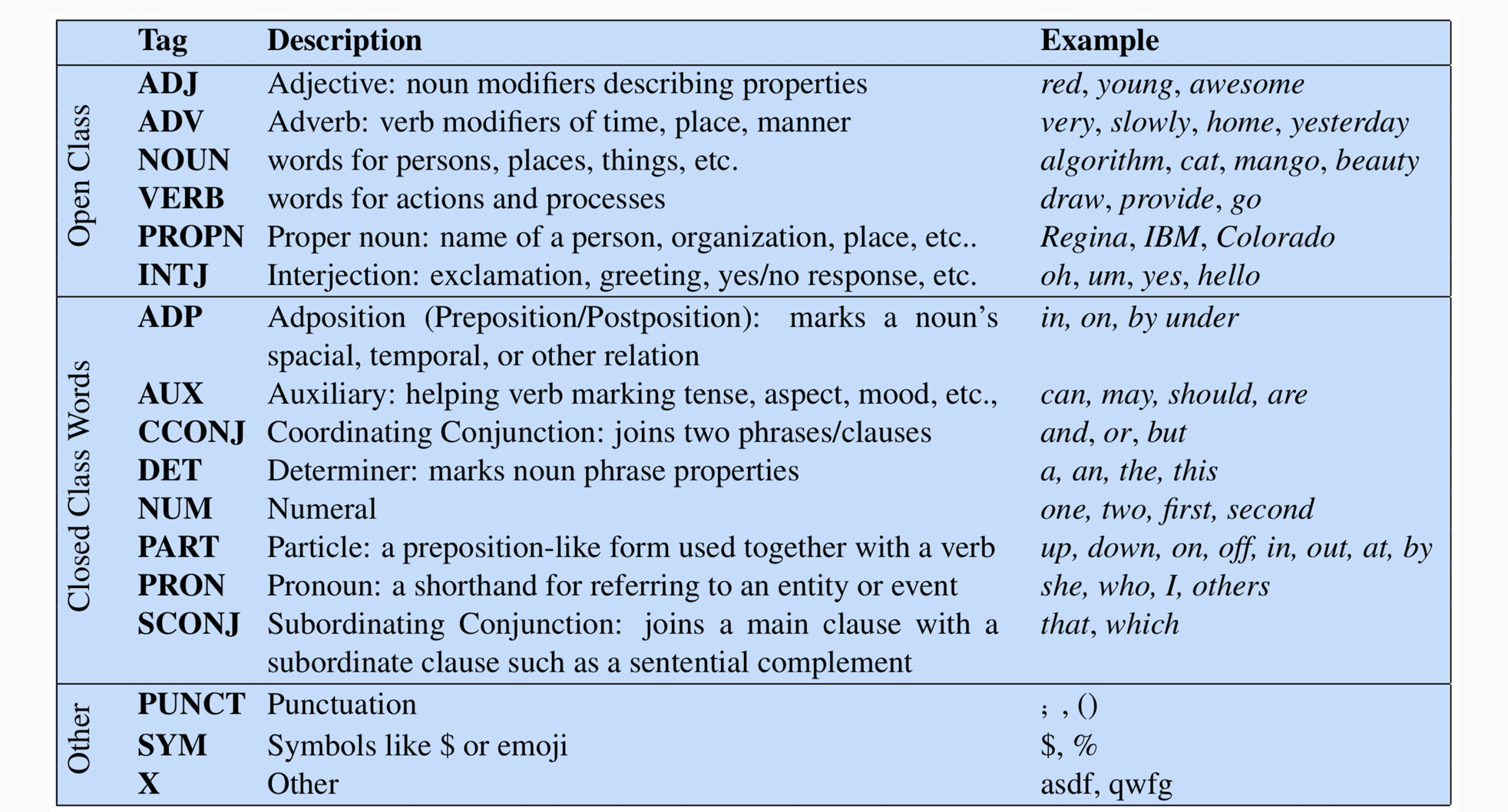
- UD Tagset
The Task of POS Tagging
给定一句话,输出这句话中词性的标记
training data:word sequence paired with its POS tag sequence

Local:apple is more likely a noun rather than a verb
contextual(上下文): adeterminer is usually followed by a noun rather than a verb,含有说话的习惯,例如两个冠词不太可能相连
输入:a sentence of any length n:x1,x2,x3,…xn
输出:its corresponding POS tag sequence: y1,y2,y3,…yn
考虑POS tag sequence的联合概率:
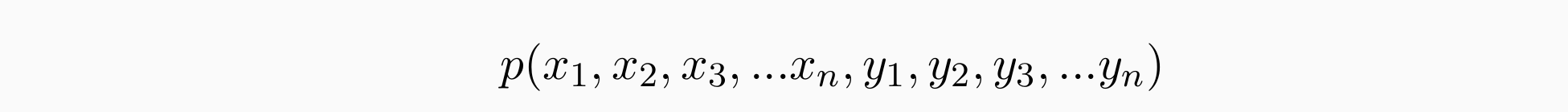
- 使POS tag sequence的联合概率最大:
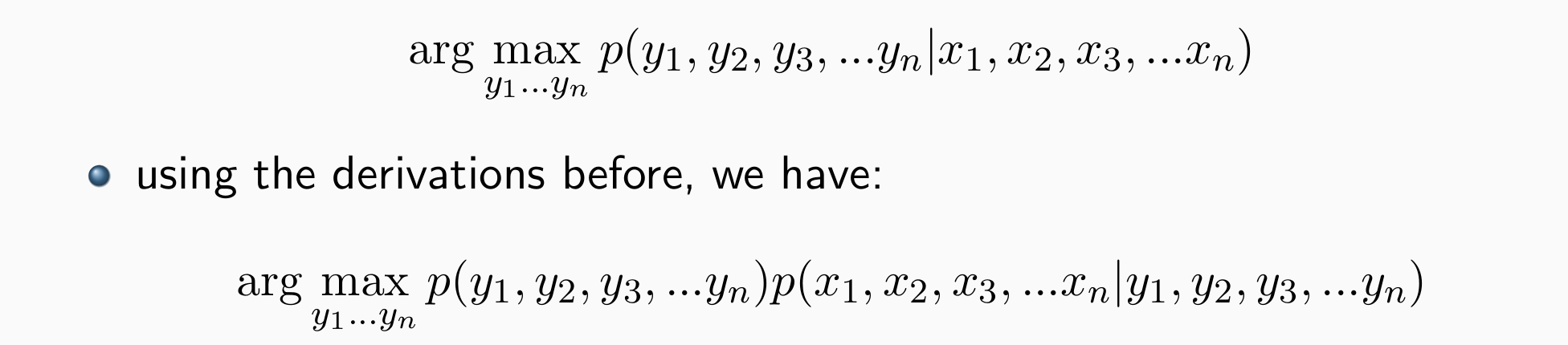
核心:Two key components:
- p(y1,y2,y3,…yn)
- p(x1,x2,x3,…xn|y1,y2,y3,…yn)
p(y1,y2,y3,…yn)看起来像语言模型的公式:描述了什么样的词性更可能是对的p(y1,y2,y3,…yn)=p(y1)p(y2|y1)…p(yn|y1,…yn−1)。语言模型:TrigramLM:p(yn|yn−2,yn−1),BigramLM:p(yn|yn−1), …
如果假定独立性假设简化:
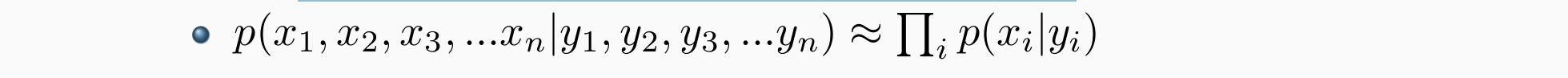
Hidden Markov Models(HMMs)
Hidden Markov Model的核心构成:
- a set of states(POS tags)
- a set of outputs(words)
- initial state(the beginning of a sentence)
参数:
- transition probabilities(转移概率):描述观测过程中词性的转移有多常见
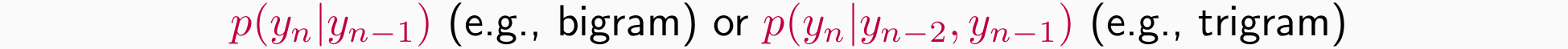
- emission probabilities:如果是动词则选择该词的概率

- transition probabilities(转移概率):描述观测过程中词性的转移有多常见
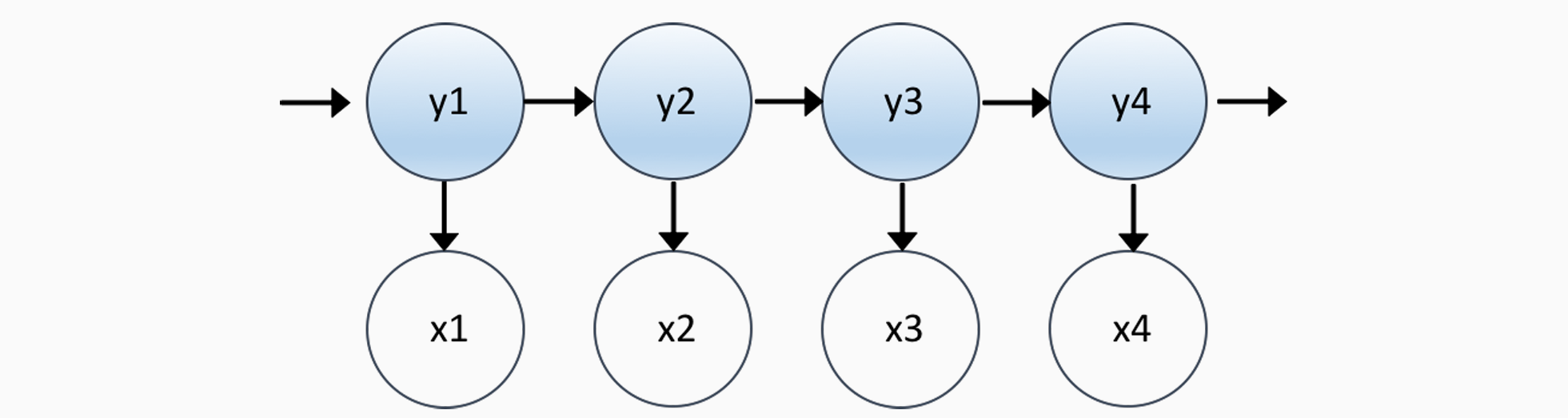
The Generative Story for HMMs
- 生成过程如下:

Parameter Estimation
transition probabilities:P(ADJ|VERB)=?
emission probabilities:P(apple|NOUN)=?
可以用频率计数来估计,count/count
方法:MLE估计+smooth
得到两张非常大的表,第一张表:tag_size x tag_size;第二张表tag_size x vocabulary
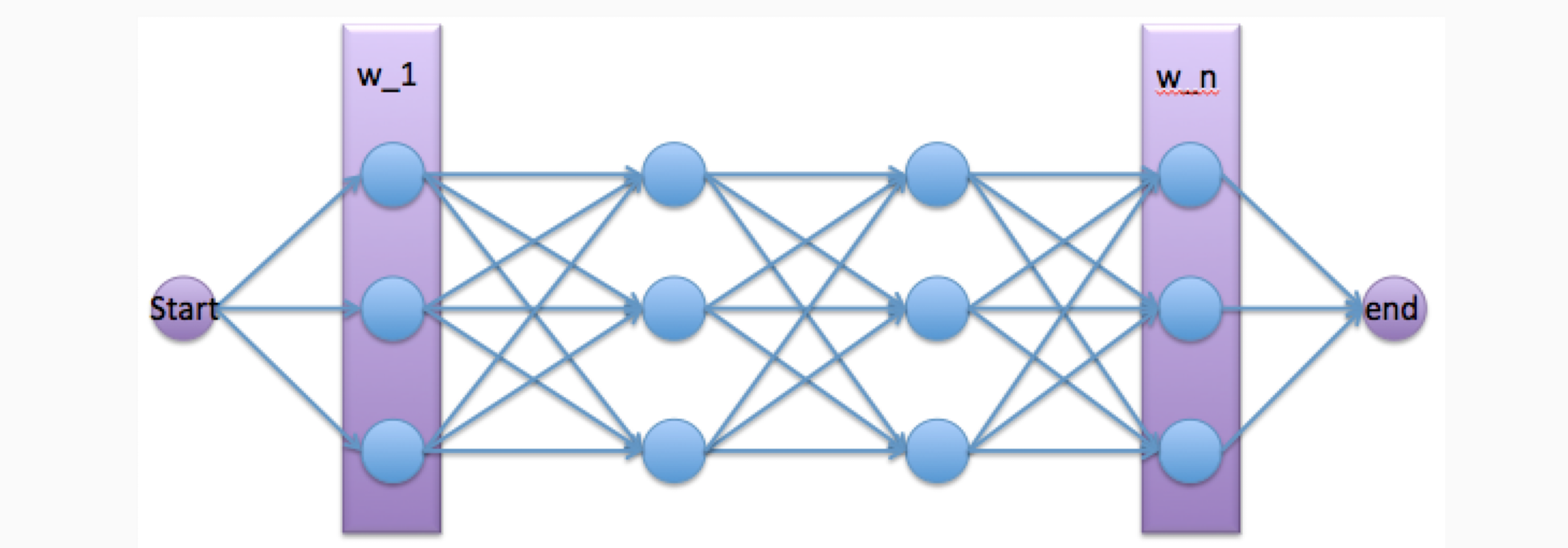
Decoding
如何根据这两张表找到最好的POS tag sequence:暴力搜索?不适用于非常大的表格
解决方法:使用动态规划的方法
Dynamic Programming Scoring Table
- 给定任何长度的句子:n:x1,x2,x3,…xn;对应的POS tag序列:y1,y2,y3,…yn
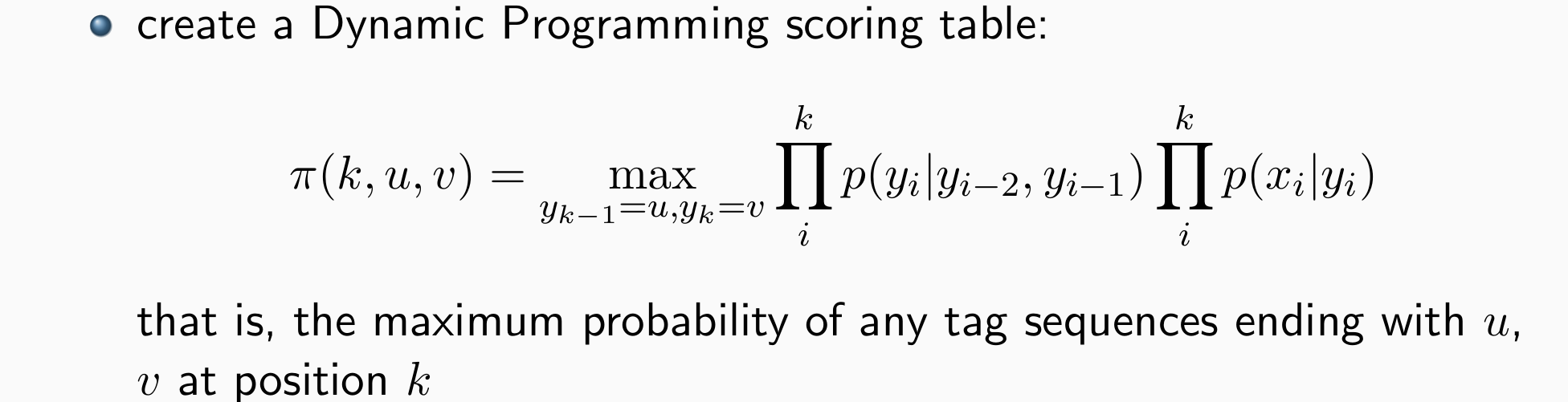
The Viterbi Algorithm
初始化:π(0,START,START)=1
对于i=1,2,3,…,n,u∈Si−1,v∈Si,计算:
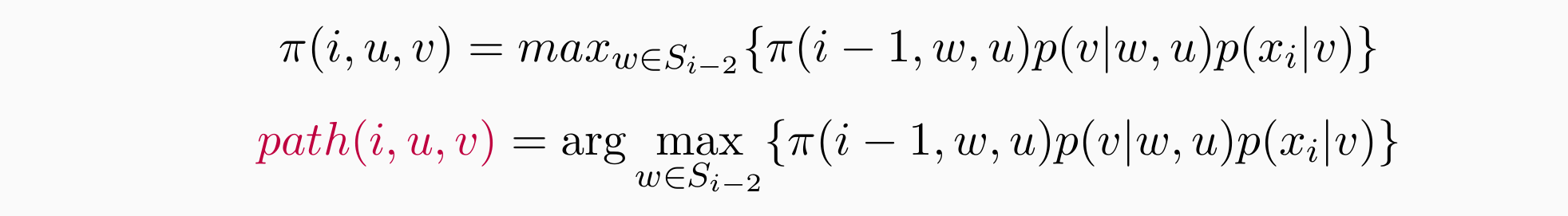
- 输出:

- 覆盖best sequence:
- build path(∗,∗,∗)
- derive yn−1,yn
- recover yn−2 = path(n,yn−1,yn),…
Sequence Tagging
become more powerful combined with other skills
plays an important role in NLP
可以应用于NLP中的多个任务
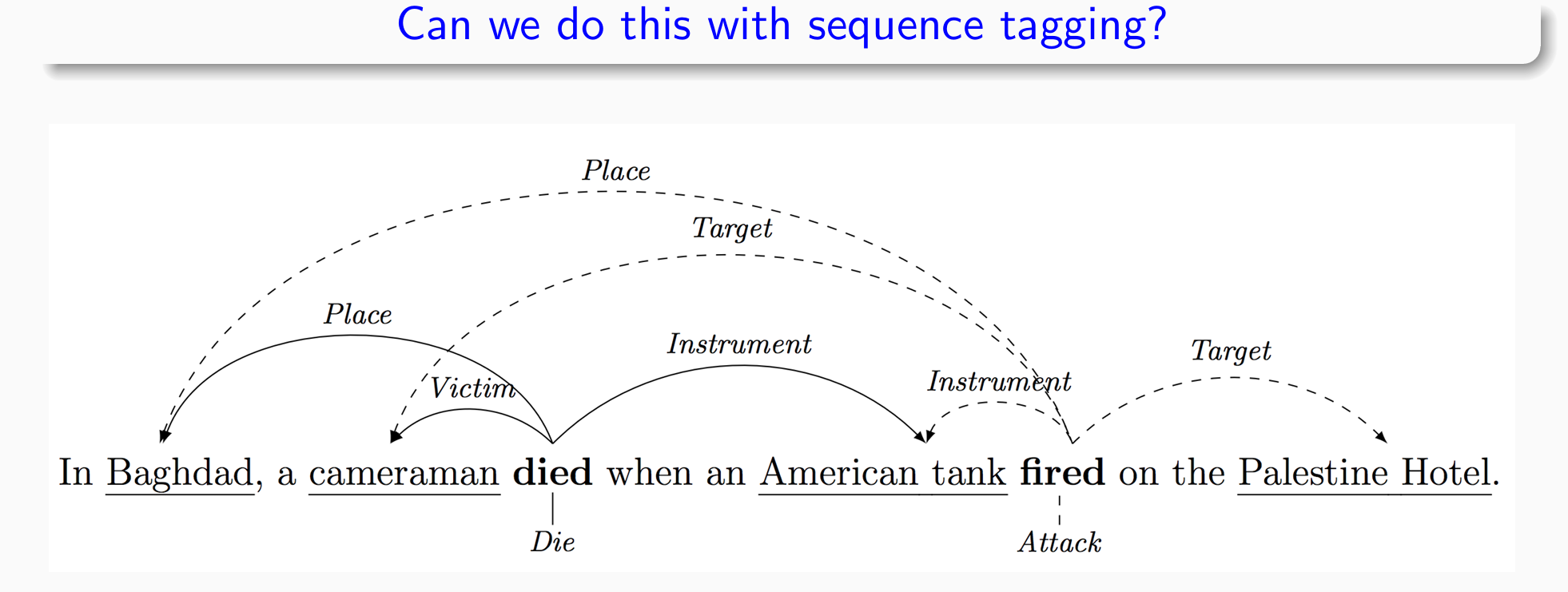
- 上面的案例中,died和fired被称为触发词,虚线实线对应argument,argument有不同的类别