自然语言处理 lec6 sper
HMM POS Tagger
Elements in HMM POS Tagger
Elements:
- a sequence of words
- a sequence of POS tags
- the beginning and end of a sentence
参数:
- Sequences of POS tags → transition probabilities (p(yn|yn−2,yn−1))
- Co-occurrences of words and POS tags → emission probabilities (p(xn|yn))
A Naive Way to Incorporate
- 可以加入先验知识

- 考虑多种特征的方法需要优化多个lamada
Alternative: A Classifier
每一个词进行分类,然后抽取特征,根据特征找到最好的POS标签
log-linear可以用于这个分类任务,但是效果并不好。问题:逐个词抽取特征,没有办法利用前后词特征
individual decisions v.s. a sequence of decisions,需要有一组的决策
Another View: Features
natural language process, e.g., POS tagging:
- 词本身性质:前缀?后缀?大小写…
- 内容:前后文,词义
- 稠密特征
NLP 中的特征:描述观察到的数据 x 相对于预测标签 y 的某些方面的证据,通常目的是提供→判别模型的条件概率 p(y|x)
Feature-based Discriminative Models
- 含有λf(x,y),f(x,y)的线性分类器,其中λf(x,y)是权重。构建一个线性函数从输入x映射到输出y,对于可能的x和y,我们需要计算分数:
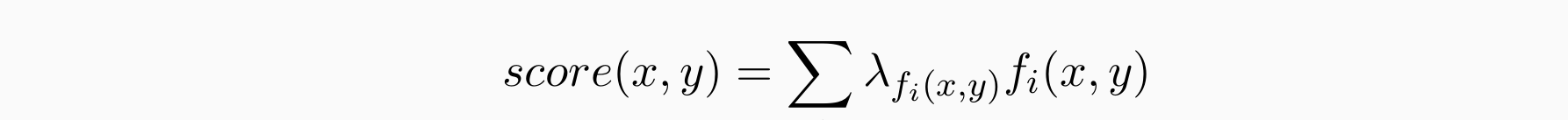
- 线性分类器选择分数最大的:
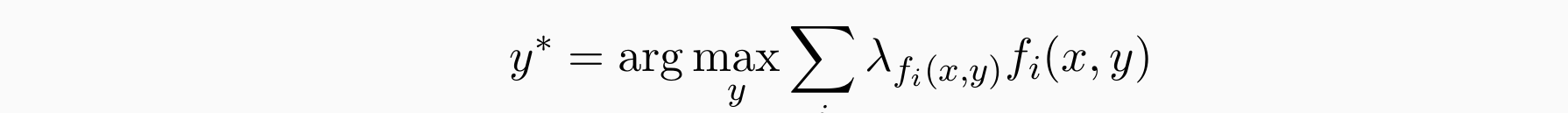
- 问题:如何求lamada?

A Perceptron POS Tagger
输入:训练数据 (xk,yk) for k = 1,2,…,n,其中xk是数据,yk是标签
初始化:λ =[0,0,0…..], T(迭代次数)
follow Collins:GEN对于每一个数据x枚举数据的可能候选标签 ys
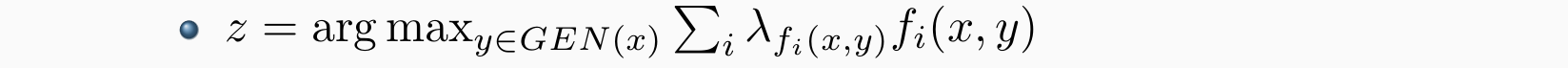
- 循环:如果模型输出的词性和标准一样则不更新,若不一样则更新幅度为1,让模型判断对的特征权重+1,让模型判断错的特征权重-1
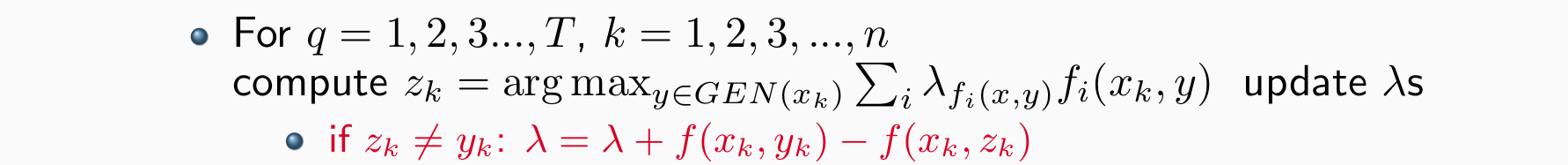
输出:权重λs
batch_size=1每个词更新一次,但是更新范围有限,仅限于让模型判断正确和错误的词,权重的更新只涉及加法
A Simple Perceptron Solution for POS Tagging


- 问题:如何做decode?由于不涉及到高级特征,因而可以用贪心算法做decode
A Structured Perceptron Tagger
现在逐个词预测,希望能够把前一个词性也作为输入将个体决策变为序列决策
使用历史决策作为新的特征输入
Local models + new/history-based features
Perceptron/Log-linear + history-based features
A Variant: The Structured Perceptron Algorithm

结构感知机更新的尺度变为以句子为单位而不是以词为单位,可以减少更新的次数
问题:前面的标签还没确定时,句子的序列难以确定
解决方案:建立lattice,在栅格中找最好的序列,类似于动态规划
Perceptron v.s. Structured Perceptron

A Bit Complex: Why We Need the Viterbi Algorithm
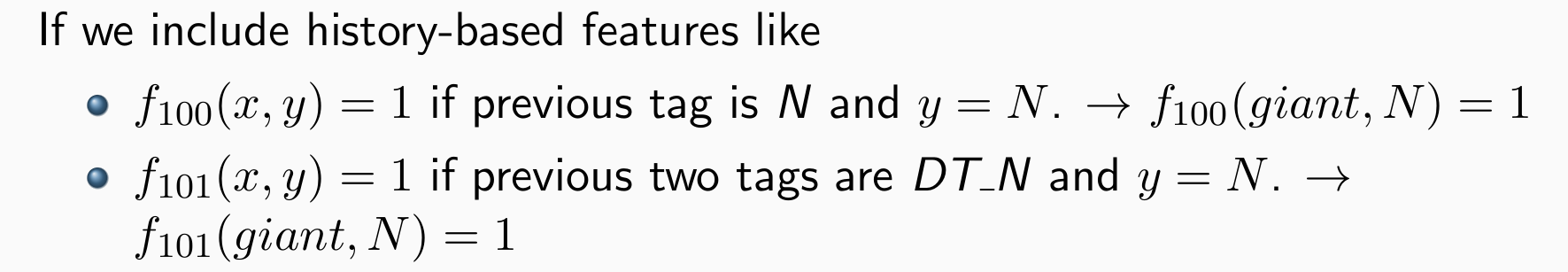
我们没有办法单独的直接的计算score(giant,N), score(giant,ADJ)
我们需要使用动态规划来解码整个句子的当前最佳标签序列
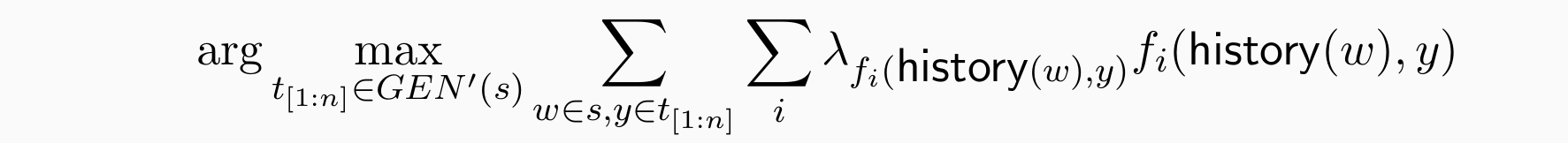
Decoding: the Viterbi Algorithm

- 问题:表太大的情况下,无法完整记录,且Viterbi可能不唯一
An Alternative: Beam Search
核心思想:仅保留最佳的k个
输入:长度为n的句子x,trained model score(∗),和beam_size k

输出:Hi中得分最佳的序列
优点:实现非常简单,较为有效
缺点:不能保证找到全局最优解
Runtime is O(n²k|y|), space is O(n²k)
问题:T难以确定
解决方案:选择某时刻n,拿出第n-2次,n-1次,n次的checkpoint结果,计算平均值或线性加和,或者做投票
Tagging with Global Features
Plug into a Log-linear Model
- 在线性的基础上加入非线性效果更好
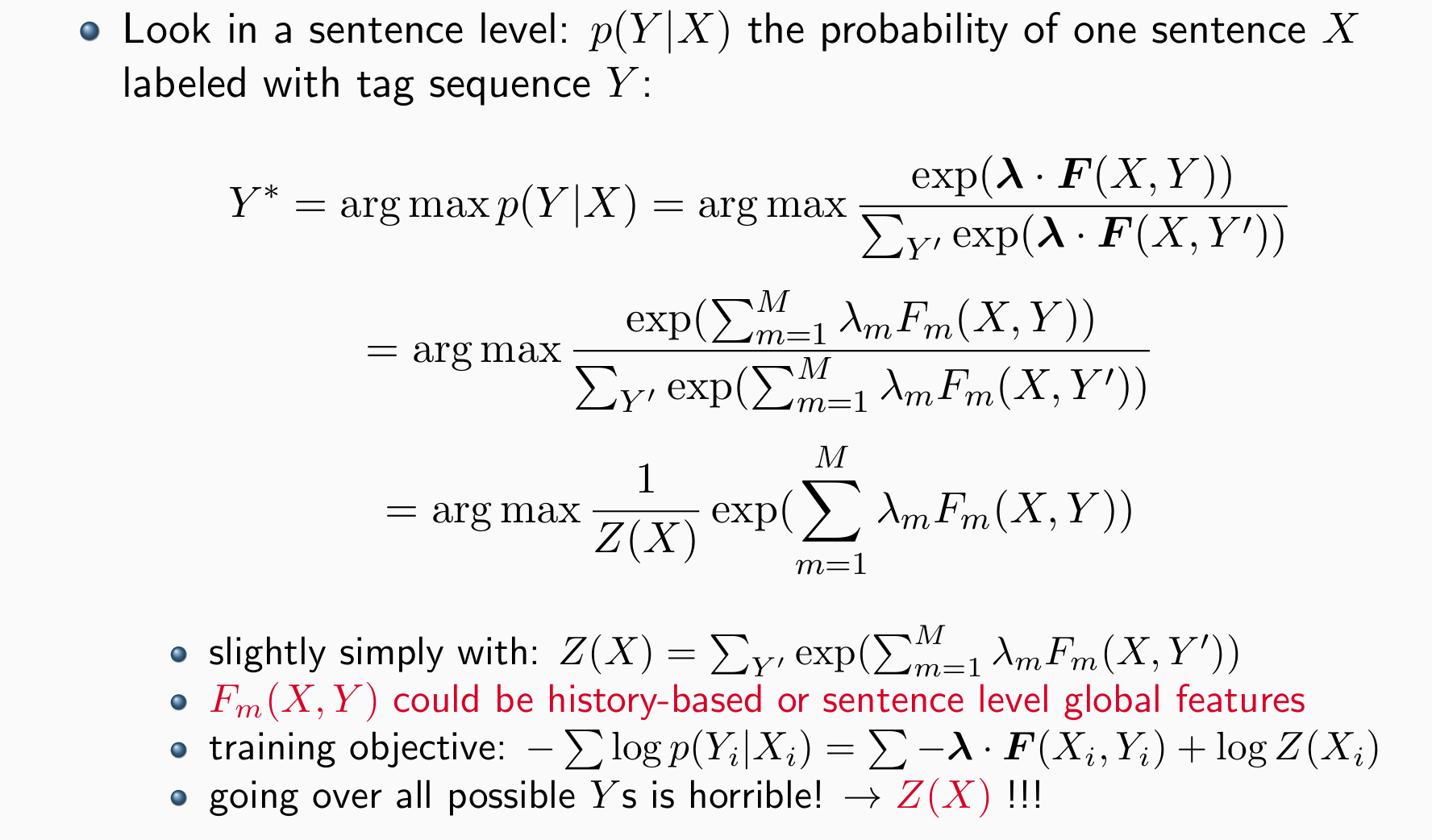
Conditional Random Fields
结构化预测统计学习中最具影响力的模型之一,尤其是序列标记
非线性可以得到更强的版本
通常采用以下形式,以 Y 为各种目标结构:
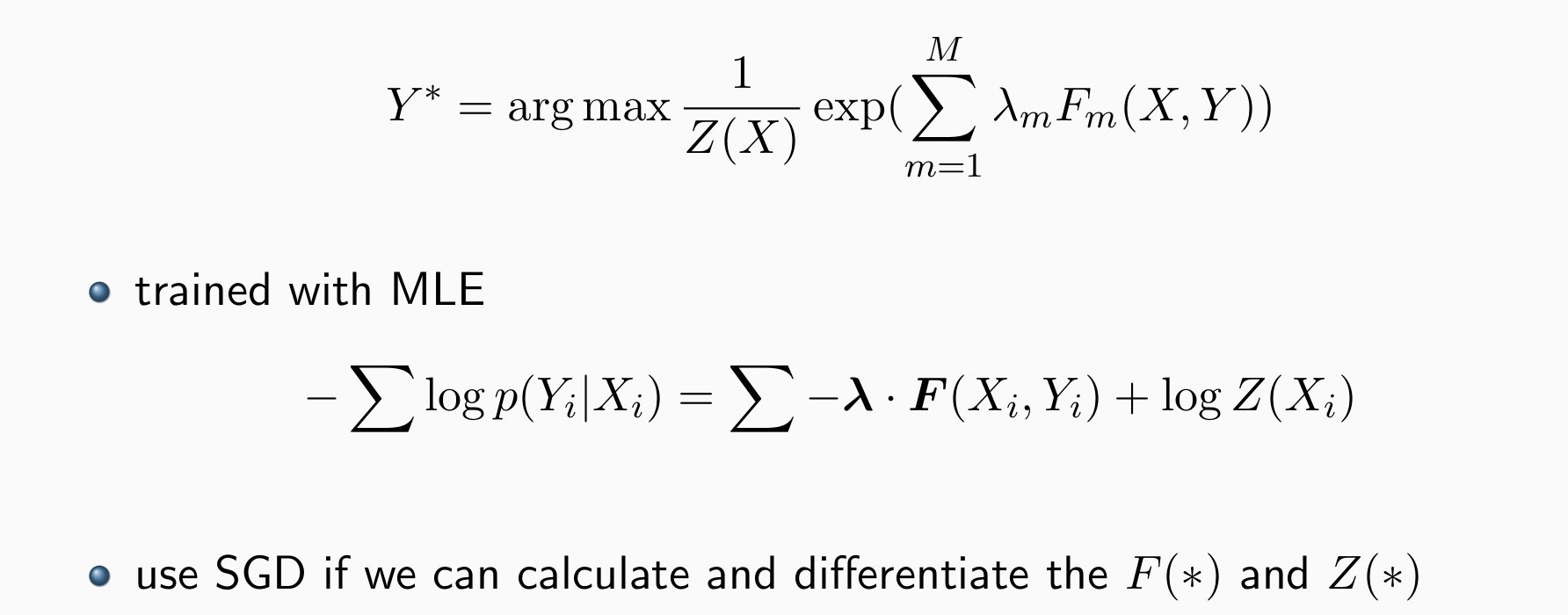
- 可以使用 the Forward Algorithm来进行decode,和Viterbi相似

Neural Sequence Tagger
In Neural Times
Traditionally: → SOTA: Conditional Random Field (CRF)
- 特征工程,可能导致其他语言的问题
- OOA:词没见过会导致问题
- Label bias:过强的关联——依赖一两条特征来判断(可以用正则化缓解)
Neural Times:
- 没有特征工程
- 语言迁移容易
- 可以在不同层次上建模
- 各种 NN 架构,用于捕获local/长上下文,包括前向和后向:CNN, RNN, LSTM, BLSTM, BLSTM-CNN
BSLTM for NER
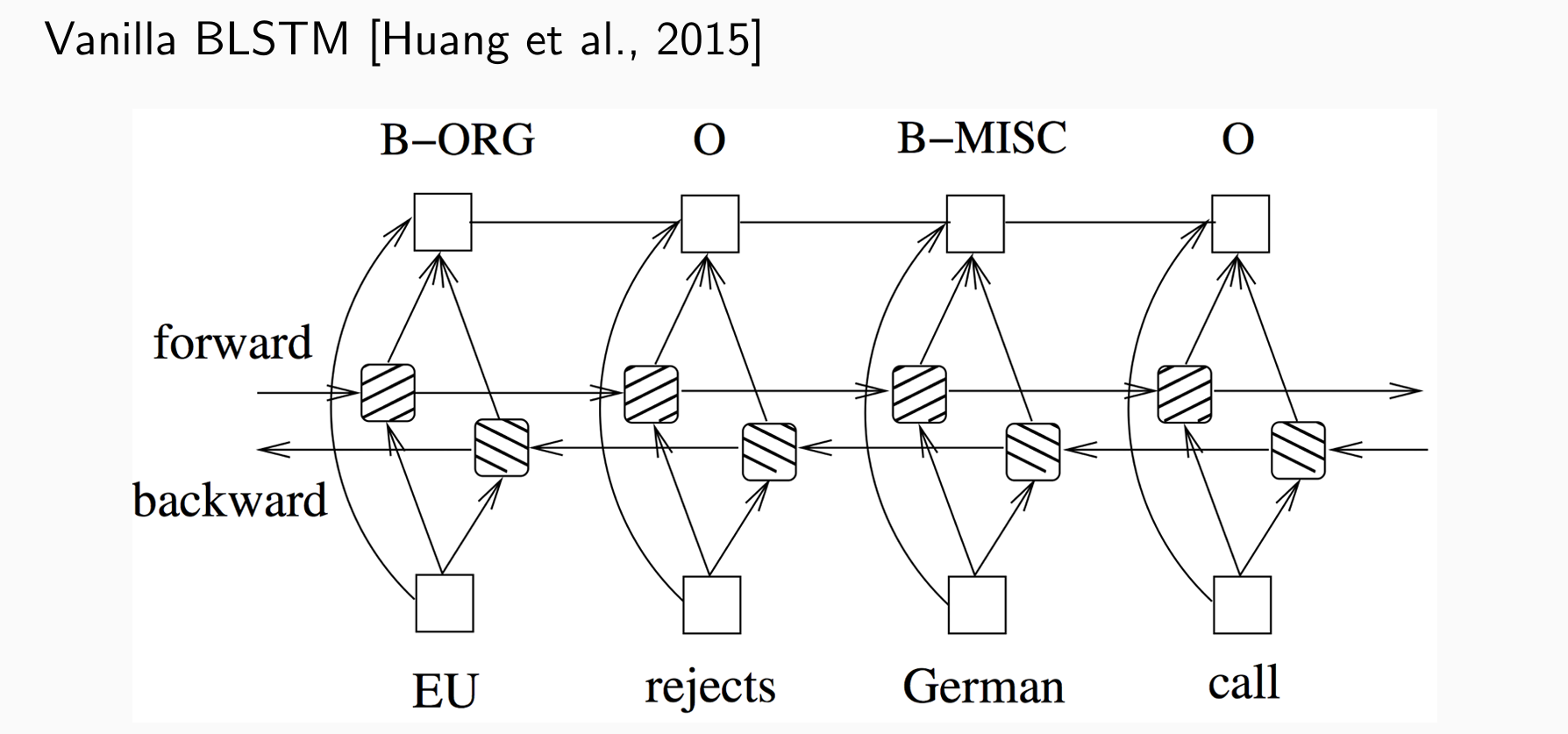
两个方向的LSTM,能看到未来与历史,然后进行拼接用于任务
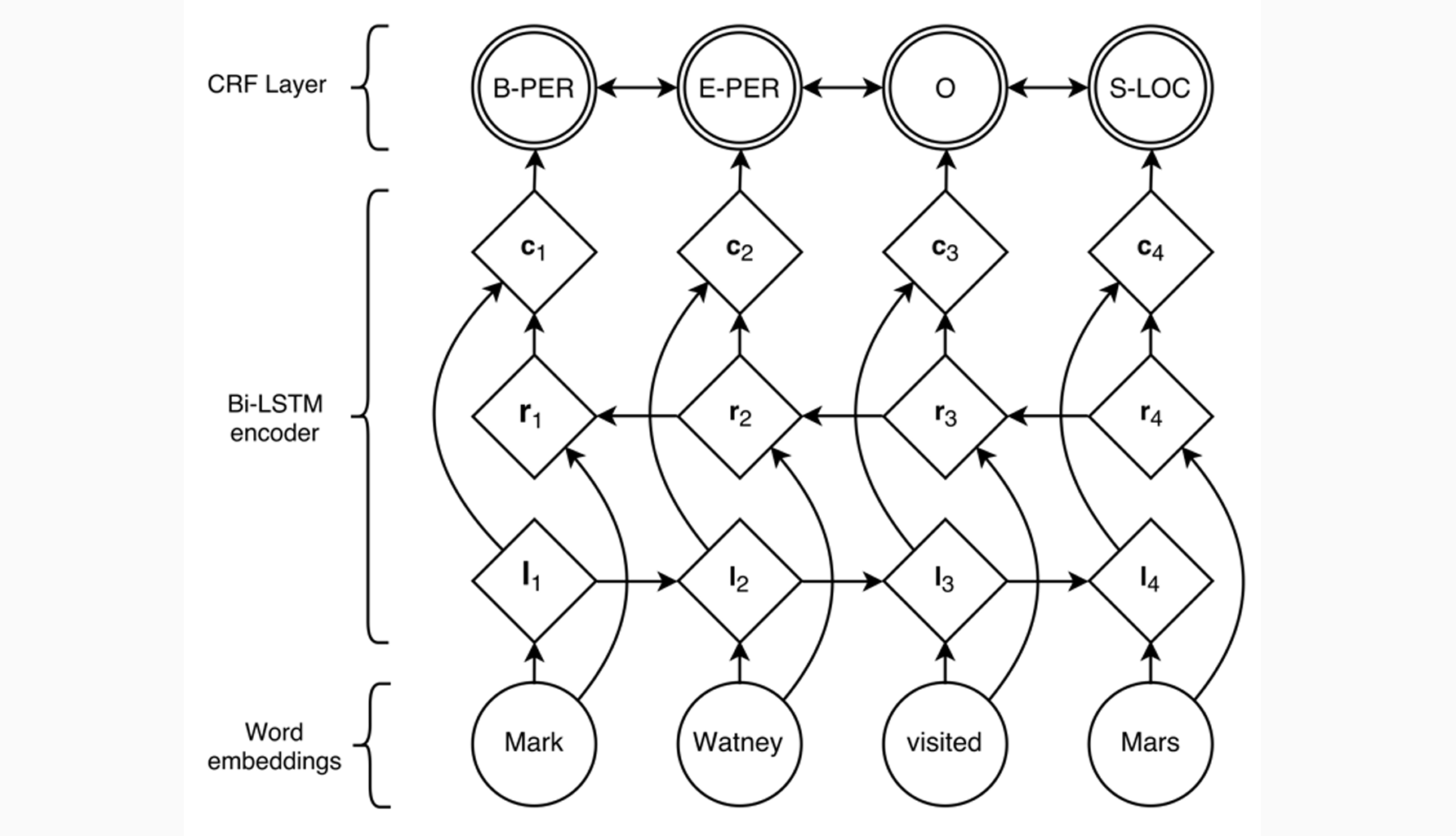
BLSTM with CNN:

- BLSTM with CRF (conditional random field) :可以记住什么标签间的转移是更重要的
Contextualized (String) Embedding
- Flair:上下文字符串嵌入,看成字母构成的序列
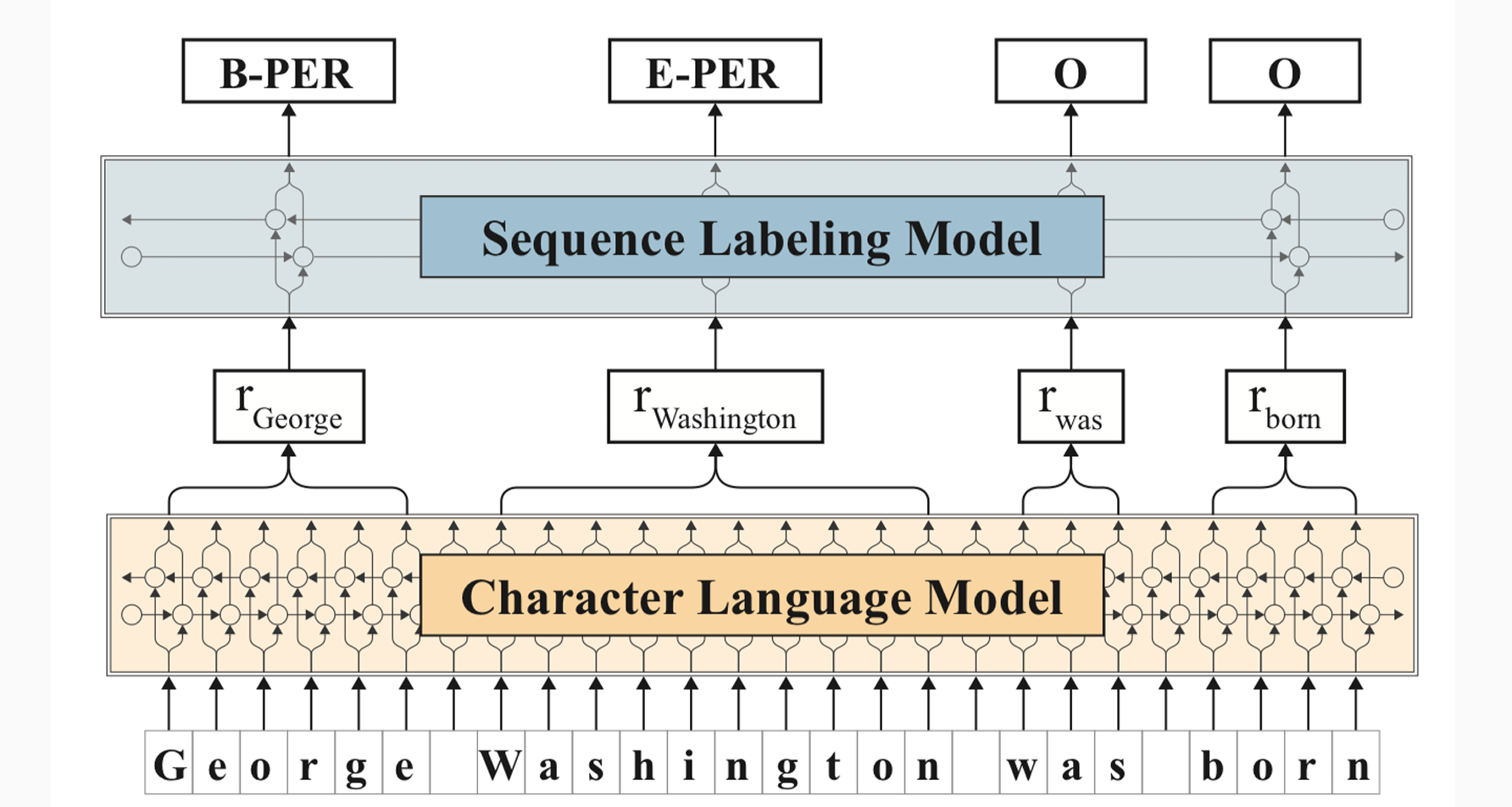
仍然是双向LSTM,可以得到字符级别的上下文表示
可以得到词的性质。e.g. ~ing、大写
问题:如何通过字符的表示得到单词的表示?直接拼接会导致词的维度不一样。双向的LSTM从左到右和从右到左拼接
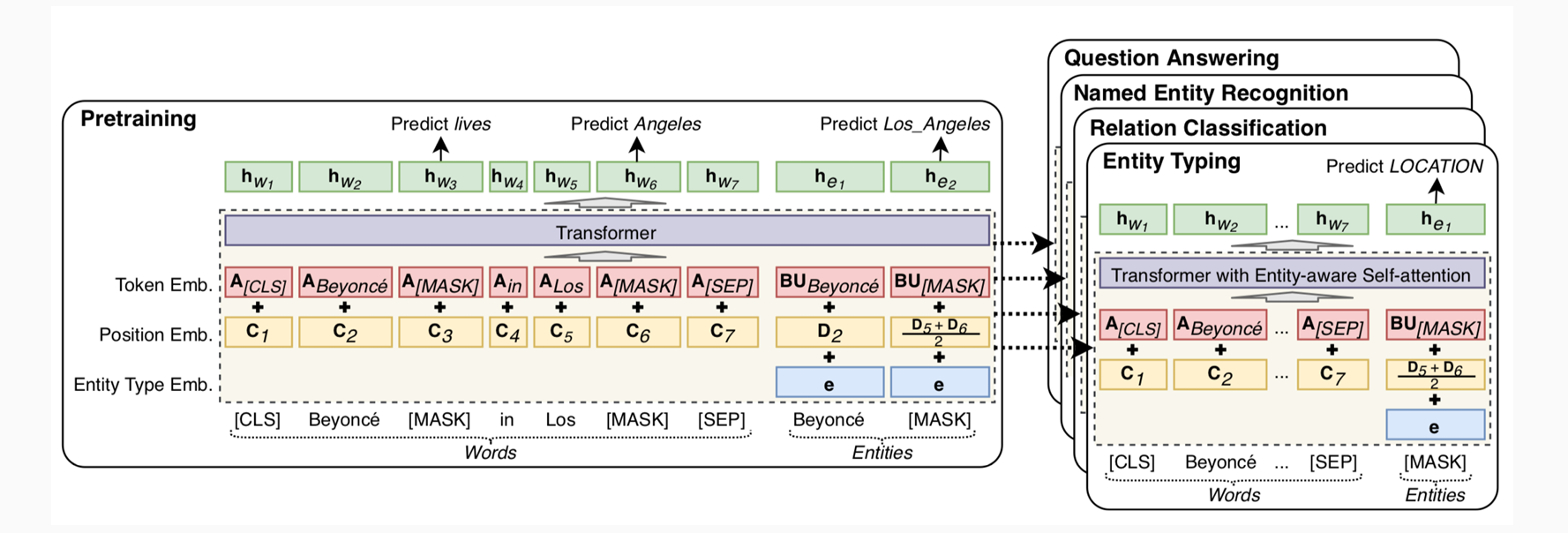
LUKE: transformer (BERT), masked entity predition, entity-aware self-attention, …
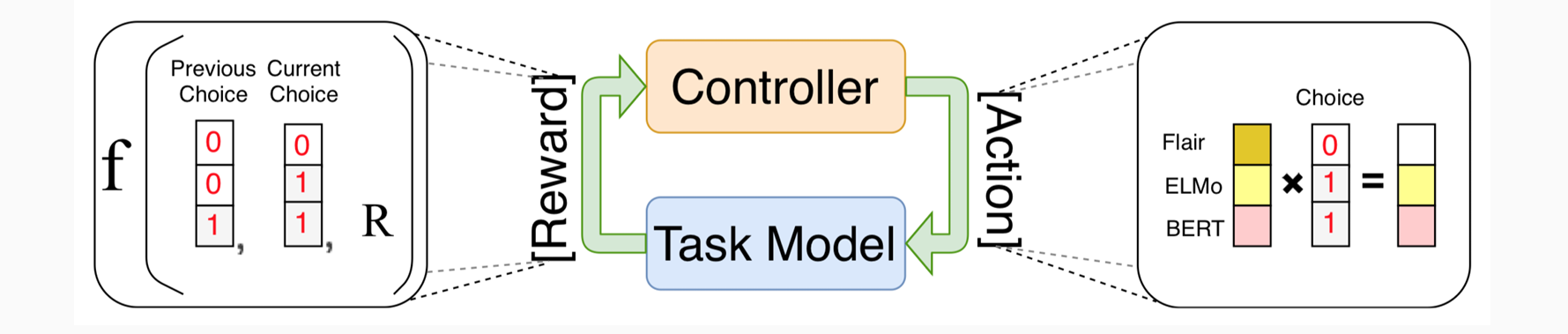
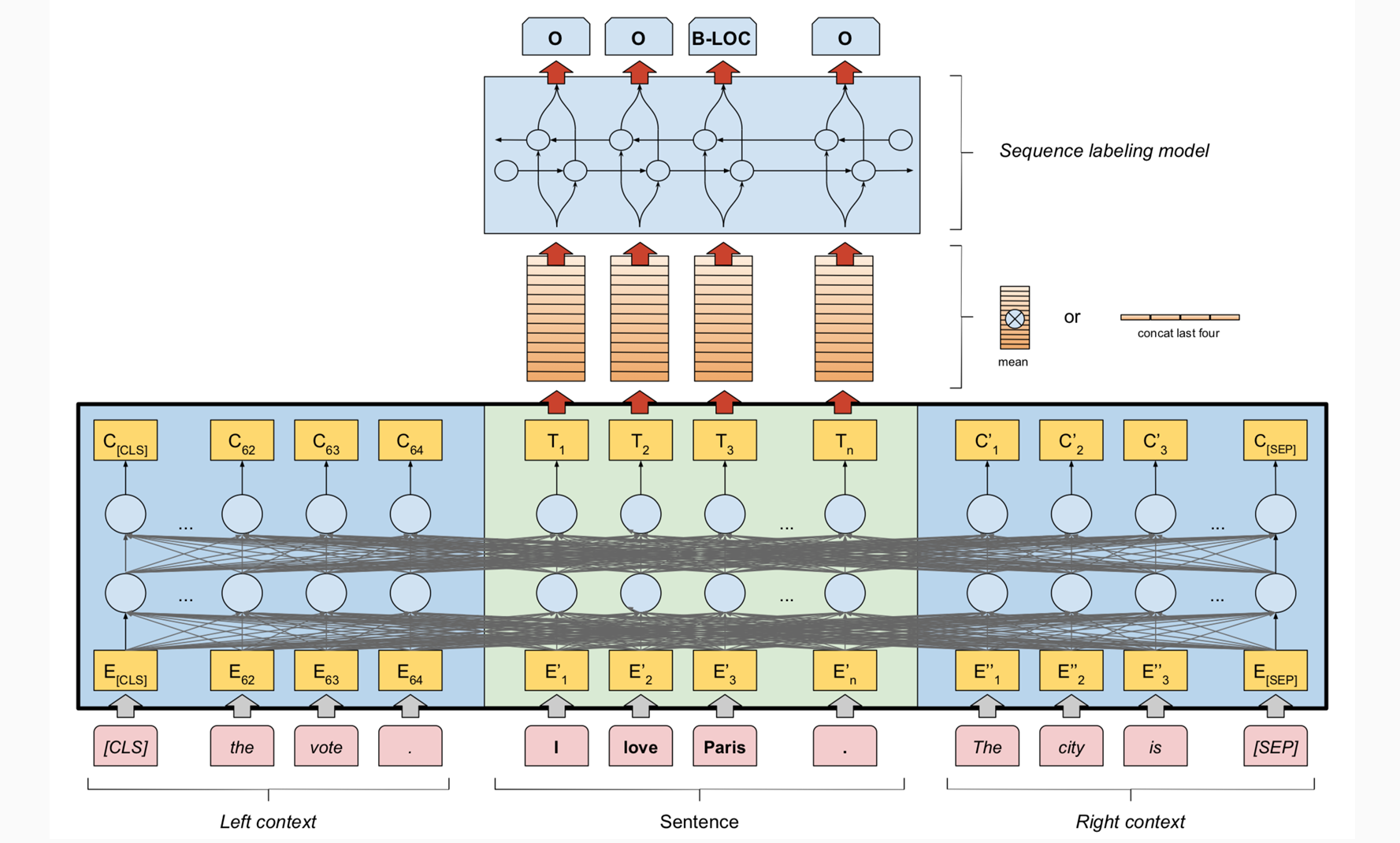
Using Document Level Features
- FLERT: Document level features for NER
Beyond Contextual Embeddings
也许我们需要更多的机器学习/深度学习……
嵌入的自动串联⇒神经架构搜索