
PERSONALIZED VISUAL INSTRUCTION TUNING
PERSONALIZED VISUAL INSTRUCTION TUNING
ABSTRACT
多模态大语言模型(MLLMs)取得了显著进展,但这些模型存在一个明显的局限性,我们称之为“脸盲症”(“face blindness”)
它们能够进行一般性对话,但无法针对特定个体展开个性化对话。这一缺陷限制了MLLMs在个性化场景中的应用
本文提出个性化视觉指令调优(PVIT),这是一种新颖的数据构建和训练框架,旨在使MLLMs能够识别图像中的目标个体并进行个性化和连贯的对话
我们的方法包括开发一个复杂的流水线,自动生成包含个性化对话的训练数据。该流水线利用了多种视觉专家模型、图像生成模型以及(多模态)大语言模型的能力
为了评估MLLMs的个性化潜力,我们提出了一个名为P-Bench的基准测试,涵盖不同难度级别的多种问题类型。使用我们构建的数据集进行微调后,模型的个性化性能得到了显著提升
1 INTRODUCTION
大语言模型(LLMs)的出现显著推动了人工智能的发展,改变了自然语言处理和理解领域。这些模型在大量文本语料库上训练,拥有丰富的世界知识,能够出色地完成各种任务
LLMs进一步促进了多模态大语言模型(MLLMs)的快速发展。MLLMs利用预训练的视觉编码器(如视觉变换器)处理图像,并将其作为标记嵌入与文本标记嵌入结合
这些模型扩展了LLMs的能力,使其能够基于图像输入展开对话,广泛应用于自动驾驶和医疗助手等领域
尽管MLLMs取得了成功,但它们在通用对话中的效果有限,尤其是在针对特定个体的个性化对话中表现不佳。这一缺陷阻碍了MLLMs在个性化用例中的应用
为了赋予MLLMs个性化能力(称为P-MLLM),先前的研究提出通过增加外部模块和词汇表来训练模型,使其能够利用少量个性化训练数据识别场景中的特定个体
尽管这些方法表现良好,但它们存在以下弱点:
- 需要为每个新引入的个体进行额外训练,这在现实生活中缺乏灵活性且不实用,因为目标个体可能频繁变化
- 无法保证总能收集到目标个体的训练数据。因此,如果MLLMs的个性化能力能够泛化,而非局限于少数预定义的个体,无疑更具前景
由于当前最先进的LLMs和MLLMs采用自回归训练范式,它们能够根据给定的前缀生成响应。这种能力也被称为上下文学习能力,使模型在推理时通过调整前缀生成不同的输出,而无需进一步训练
一种直观且实用的方法是在前缀中向MLLM提供个体的信息。这样,MLLM在推理时有望为不同的输入个体生成答案
然而实验结果表明,这种能力具有挑战性,当前的MLLMs难以有效理解此类个性化输入。可能是因为这些MLLMs在有限的多模态数据和缺乏个性化数据的情况下进行了微调,从而阻碍了它们对多模态输入的上下文理解能力的发展
为解决这一挑战,我们提出个性化视觉指令调优(PVIT),这是一种新的训练范式,使MLLMs能够将个性化输入视为上下文前缀
每个个体表示为<个人图像,个人介绍>对,作为多模态前缀提供给MLLM。我们进一步引入个性化包装标记,将每个个体的视觉和文本信息分组,从而消除多个个体参与时的歧义
训练过程中,MLLM被优化以回答与前缀中目标个体相关的问题。一旦训练完成,MLLM能够充分利用其上下文学习能力,泛化到任意个体,而无需额外的微调或模型架构修改
在我们提出的PVIT范式中,最大的障碍是缺乏大规模、高质量的训练数据。为解决这一问题,我们设计了一个自动框架来合成个性化训练数据,分为三个阶段运行:
- 视觉专家模型从场景图像中提取个体视觉概念(视觉概念构建)
- 利用MLLM将这些视觉概念转换为个体级和场景级的文本描述,并将其融合以创建连贯的表示(双级文本信息提取与融合)
- LLMs利用推理和指令遵循能力生成多样化的个性化问答对(PVIT数据集生成)
为了评估MLLMs的个性化能力,我们进一步创建了一个名为P-Bench的基准测试,从多个角度评估个性化能力
结果表明,当前最先进的MLLMs感知个性化概念的能力有限,而通过我们提出的PVIT训练后,这一能力得到了显著提升
综上所述,本文的主要贡献如下:
- 受LLMs的上下文学习能力启发,我们提出个性化视觉指令调优(PVIT),这是一种新的训练范式,使MLLMs能够在推理时无需额外训练的情况下为任意个体进行个性化对话
- 设计了一个自动数据标注框架,构建高质量的个性化训练数据,并合成了一个大规模数据集,以增强MLLMs进行个性化对话的能力
- 构建了P-Bench,这是一个用于评估MLLMs个性化能力的新基准。我们证明,使用我们构建的数据集训练的MLLM在性能上表现出显著提升
2 RELATED WORK
Multi-Modal Large Language Model
大语言模型(LLMs)在语言理解和生成方面取得了显著进展,在各种任务中达到了接近人类的水平。这一成功激发了人们对视觉语言交互的兴趣,从而催生了多模态大语言模型(MLLMs),这些模型在基于视觉输入的对话中表现出色
然而,它们在个性化对话方面表现不佳。这限制了它们在个性化AI助手、定制推荐或定制治疗中的应用。解决这一局限性对于实现个性化AI交互至关重要
Model Personalization
在模型个性化领域,主要目标是为模型定制新的用户特定概念。在文本到图像(t2i)生成个性化方面已有大量研究。t2i个性化的主流方法是通过少量示例微调词嵌入,以捕捉目标概念的细微差别
一些研究专注于个性化图像描述模型。这些个性化描述方法旨在以特定的写作风格生成描述
相比之下,我们的目标是使模型能够将新的用户特定概念整合到与给定图像对齐的个性化文本描述响应中
Personalized MLLMs
与文本到图像生成和传统图像描述相比,多模态大语言模型(MLLMs)的个性化仍是一个未被充分探索的领域
最近的方法提出为每个新个体引入新的可调参数,并使用少量训练样本进行调优。具体而言:
- MyVLM采用Q-former风格的架构,结合可学习头部提取特定概念并将其附加到视觉特征中
- Yo’LLaVA采用LLaVA风格的架构,提出直接将新概念作为附加标记纳入LLM的词汇表中
尽管这些方法在个性化对话中表现出色,但它们需要为每个新引入的个体进行额外训练和参数调整。这一要求在现实生活中不太实用,因为新个体可能会频繁加入
此外,通常无法为每个个体收集相关训练样本。这些限制要求模型能够即时泛化到新概念
3 PROBLEM FORMULATION
与先前针对个性化多模态大语言模型(P-MLLMs)的方法不同,我们的方法将个性化视为上下文学习任务,无需为每个新个体进行微调或添加可训练参数
具体而言,我们首先向MLLM提供多模态前缀列表,其中包含<个人图像,个人介绍>对
然后,我们提供场景图像和个性化查询,以针对特定个体展开对话。在多模态前缀和个性化查询的条件下,MLLM应生成与目标个体相关的响应
这种能力并非微不足道,大多数最先进的MLLMs并不具备。如下图所示,即使用户指令针对特定个体,MLLM仍倾向于生成一般性响应;即使在训练中交替使用图像和文本数据的MLLMs中,这一问题仍然存在:

我们推测这一限制是由于缺乏训练,而非视觉编码器的缺陷
因此,我们提出通过个性化视觉指令调优(PVIT)赋予MLLM个性化能力。我们首先收集训练数据集:其中r(i),q(i),Is(i)分别表示第i个目标响应、用户查询和提供给MLLM的场景图像,后者表示包含输入个体图像及其个性化介绍(如姓名)的Ki个多模态前缀
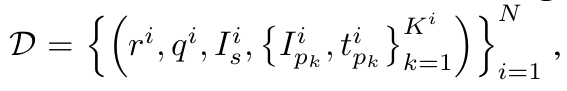
- 优化问题可表述如下:
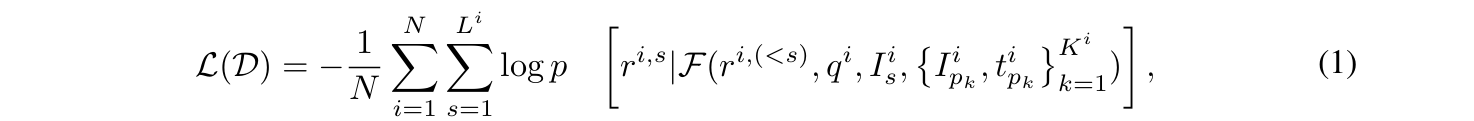
- 在训练过程中,我们最小化自回归损失,以基于查询、场景图像和多模态前缀生成个性化响应。这种方法充分利用了MLLMs的上下文学习能力,使其能够适应新个体而无需额外训练
Personalized Wrapper Tokens
简单地在多模态前缀中交替使用个性化图像和介绍可能会引入歧义,因为个性化介绍(如姓名)可能被错误地关联到前一个或后一个人的图像。这种歧义会使训练复杂化,并在推理时混淆MLLM
为解决这一问题,我们在MLLM的词汇表中引入了两个特殊标记:⟨∣ person_start ∣⟩和⟨∣ person_end ∣⟩,这些标记作为包装器,明确地将每个个体的信息封装为以下结构:⟨∣ person_start ∣⟩ {photo} {text_intro} ⟨∣ person_end ∣⟩
这一设计确保每个个体的信息被正确分组,从而改善模型的学习过程
上下文学习范式的主要挑战在于缺乏个性化训练数据,因为现有的多模态指令调优数据集专注于一般性对话
为解决这一问题,我们提出了一个自动化框架,利用LLMs、MLLMs、图像生成模型和视觉专家,为多模态对话数据标注个性化输入
4 DATA CONSTRUCTION
为了赋予MLLM个性化对话能力,我们开发了一个数据生成框架,能够合成多种类型的个性化训练数据
该框架从一组图像开始,这些图像作为训练数据的场景图像:
- 首先,通过视觉专家模型从这些图像中提取个体的视觉概念
- 接着,利用MLLM将图像中的视觉信息转换为文本描述
- 最后,利用LLM的推理和指令遵循能力创建高质量且多样化的问答对
如下图所示,该框架分为三个主要阶段:
- 视觉概念构建
- 双级文本信息提取与融合
- PVIT数据集生成
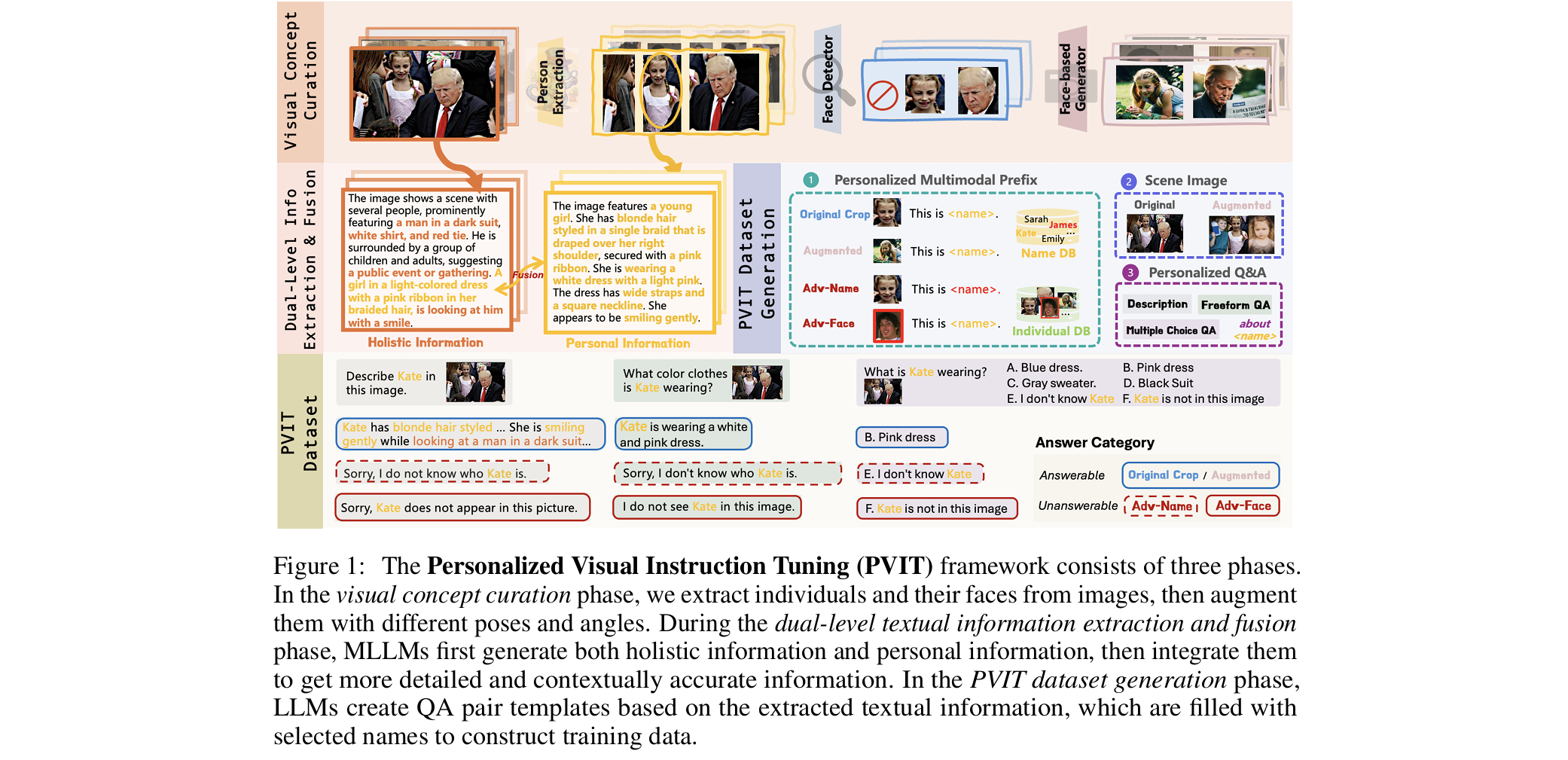
4.1 VISUAL CONCEPT CURATION
- 在这一阶段,基于场景图像,我们设计了收集个体图像的策略:
- 首先,我们应用人物识别准确定位图像中的个体
- 接着,进行人物增强,生成同一个体在不同上下文和视角下的图像。这些图像将作为后续创建个体视觉和文本信息以及个性化问答对的基础
Person Identification
对于每张图像,我们使用开放词汇对象检测器(通过提供图像和文本提示“a person”来定位个体
接着,对于每个检测到的人,我们使用人脸检测器识别并定位对应的面部,因为面部是最具辨识度的特征
个体及其面部的图像将被存储以供后续阶段使用。在此过程中,未检测到面部的个体将被排除
Person Augmentation
在前一步骤之后,我们为每张图像生成一系列<人物,面部>对。场景图像中的每个人可以通过其对应的面部进行引用
然而在实践中,用于引用个体的面部通常与场景图像中的面部不同
为了增加人脸的多样性并增强MLLMs识别个体的能力,采用身份保留图像生成器PhotoMaker对人物进行增强,该生成器基于输入面部生成同一个体在不同视角和上下文中的图像
这些增强后的图像可以作为原始场景图像中个体的参考
4.2 DUAL-LEVEL TEXTUAL INFORMATION EXTRACTION AND FUSION(双级文本信息提取与融合)
为了在后续阶段为特定个体构建个性化对话,不仅需要推导场景图像中每个人的特征,还需要捕捉他们与周围环境的交互方式,这将作为创建准确反映每个个体在场景中角色和行为的对话的基础
为实现这一目标,我们采用了双级信息提取与融合方法
Personal Information Extraction
由于当前的MLLMs无法直接提供包含多个人的场景图像中指定个体的具体特征,我们通过提供从上一阶段裁剪出的个体图像(仅包含一个人)给MLLM来生成个人信息
由于裁剪图像仅包含一个人,MLLM生成的描述将仅
Holistic Information Extraction(整体信息提取)
- 利用MLLMs现有的描述能力提供场景图像的整体信息。具体而言,我们强调描述图像中的主要角色。这种方法旨在提供更多“特征锚点”,便于后续将个人信息与整体信息融合
Dual-Level Information Fusion(双级信息融合)
在获得提供上下文知识的整体信息和捕捉个体特征的个性化信息后,我们尝试将这两部分信息关联起来
通过将个人信息与整体信息中角色的描述进行匹配实现,从而生成描述特定个体如何与上下文交互的融合描述。这种双级融合信息为生成更详细且上下文准确的个性化对话奠定了基础
4.3 PVIT DATASET GENERATION
通过前两个阶段提取的视觉概念和与每个个体相关的文本信息,我们现在可以构建个性化视觉指令调优(PVIT)数据集
PVIT数据集主要由三个部分组成:个性化多模态前缀、场景图像和个性化问答对
4.3.1 PERSONALIZED MULTIMODAL PREFIX(个性化多模态前缀)
在我们对个性化任务的上下文学习表述中,每个输入个体由一个多模态前缀表示,即个人图像和个性化介绍(如姓名)的组合
个人图像可以从上一阶段获得,可以是原始图像中裁剪的头像,也可以是PhotoMaker生成的图像
个性化介绍包含与个体相关的关键信息,例如姓名。更高级的知识(如性格、爱好和职业)可以轻松扩展,并将在未来工作中考虑
Name Swapping
我们引入
作为占位符,在构建训练数据集时用实际姓名替换。具体而言,我们使用ChatGPT收集了一个姓名列表(约600个姓名),然后随机选择一个姓名替换占位符 需要注意的是,这一过程可以重复多次,从而通过多样化的姓名增强训练数据
这种方法不仅提高了模型对新个体的泛化能力和鲁棒性,还通过避免在训练中将特定个体与固定姓名关联来防止过拟合
Personal Pronoun(人称代词)
为了更好地与用户在日常生活中指代他人的方式对齐,我们不仅通过姓名引入个体,还处理涉及人称代词(如我、你、他)的情况
例如,如果问题包含“我的爸爸”,响应应通过使用“你的爸爸”来调整
为了有效处理此类情况,我们引入了包含人称代词示例的训练数据,确保模型能够根据上下文适当调整其响应
Adversarial Introduction(对抗性介绍)
为了确保模型真正学会准确识别个体,仅考虑可回答问题的情况是不够的。模型还必须学会处理具有挑战性或误导性的场景
即使是最先进的MLLMs也常常完全忽略前缀中提供的输入个体生成响应。例如,即使目标个体(如名为Lisa的女孩)不在图像中,模型仍可能回答关于她的问题,并错误地将其他个体识别为她
为解决这一问题,我们引入了对抗性输入,旨在挑战模型正确处理无法回答问题的能力。具体而言,我们生成以下类型的对抗性输入:
- 对抗性姓名映射:在选择构建查询的目标个体(如Lisa)时,确保该个体未出现在个性化多模态前缀中。对于此类查询,模型应响应“抱歉,我不认识Lisa”,因为该个体从未被介绍过
- 对抗性图像映射:在构建多模态前缀时,随机选择不包含在场景图像中的人物图像。目标个体是前缀中包含的个体之一。在这种情况下,场景图像中不包含该目标个体。模型应响应“抱歉,我在图像中看不到Lisa”,展示其正确识别缺失个体的能力
4.3.2 SCENE IMAGE
在设计包含特定个体的场景图像时,我们的目标是使模型能够准确识别前缀中提供的目标个体
为此我们设计了两种类型的场景图像:
- 原始的完整图像,包含除人物外的完整上下文。这使得后续的问答更加全面,既关注个体的具体特征,也关注其与环境的广泛交互
- 为了增强模型在包含多个个体的图像中识别特定人物的能力,我们还通过拼接裁剪的个体图像创建合成图像,从而提升MLLM在更具挑战性场景中的能力
4.3.3 PERSONALIZED QA
从前一阶段提取的双级信息将视觉信息转化为文本,使我们能够利用LLM的高级推理能力创建个性化对话
基于这些信息,我们精心设计提示和上下文示例,使用LLM生成以下任务的数据:
- 个性化描述:创建用户查询特定个体描述而非整个图像的对话
- 个性化自由形式问答:创建自由形式的问答对,查询与特定个体相关的信息或特征,例如外貌和行为,旨在使MLLM能够进行个性化多轮对话
- 个性化多选问答:创建多选形式的个性化问答对,其中选项包括正确答案和一些混淆选项
与通用图像描述和视觉问答相比,个性化对话对当前MLLMs提出了新的挑战,因为它们不仅需要识别场景图像中的目标个体,还需要将其正确整合到生成的响应中
我们总共创建了300万个个性化对话的训练实例,称为PVIT-3M。构建的数据集涵盖了多样化的数据类型和难度级别
5 EVALUATION USING P-BENCH
尽管已经提出了许多基准测试来评估MLLMs的有效性,但尚未有专门设计用于评估其个性化能力的基准
为了填补这一空白,我们提出了一个经过人工检查的高质量基准测试P-Bench,旨在全面评估MLLMs的个性化潜力
我们设计了多项选择题(MC)和个性化图像描述查询用于评估。在本节中,我们详细介绍P-Bench的问题类型和评估指标
5.1 MULTIPLE-CHOICE (MC) QUESTIONS
- 我们设计了可回答(正例)和对抗性(不可回答)问题,以检验MLLM将目标个体与场景图像中对应人物正确关联的能力
Answerable Questions
- 可回答问题包括以下类型:
- Crop:输入个体由其原始裁剪面部表示
- Aug-In:使用PhotoMaker基于原始裁剪面部生成增强照片
- Aug-Sc-2_和_Aug-Sc-3:将两个或三个不同裁剪的个体图像拼接成一张图像以替换原始场景图像,增加了准确识别个体的难度
Unanswerable Questions
- 不可回答问题包括:
- Adv-name:问题涉及未包含在输入个体列表中的人物,意味着MLLM缺乏关于此人的知识
- Adv-image:问题中提到的个体未出现在场景图像中,意味着MLLM无法从视觉上识别此人
Evaluation Metrics(评估指标)
对于MC问题,我们采用准确率作为评估指标。为了更深入地理解MLLM的能力和局限性,我们分别评估MC问题中的每种类型
此外,为了进一步研究MLLM区分不同个体的能力,我们还分别评估了包含不同数量人物的图像的准确率
5.2 DESCRIPTIVE QUESTIONS(描述性问题)
对于此类问题,我们查询特定个体的描述,而非一般性描述。我们还设计了正例和对抗性描述问题
正例问题涉及场景图像中不同数量的人物。随着场景图像中人物数量的增加,MLLM正确识别目标个体并生成准确描述的挑战性也随之增加
Evaluation Metrics
- 对于描述性问题,我们针对可回答和不可回答问题采用不同的评估策略:
- 对于可回答问题,我们使用LongClip评估目标个体图像与MLLM生成描述之间的相似性
- 对于不可回答问题,我们计算MLLM拒绝回答的百分比
6 EXPERIMENTS
在本节中,我们在构建的P-Bench上展示了所提出的PVIT的有效性
我们首先展示了经过PVIT调优的LLaVA的结果,其性能显著高于支持多图像输入的最先进MLLMs
接着我们对构建数据的每个组件进行了消融研究,以证明它们对最终性能的贡献
6.1 MAIN RESULTS ON P-BENCH
我们比较了经过PVIT训练的P-LLaVA与其他最先进MLLMs在我们构建的P-Bench上的个性化能力
使用MC问题和个性化描述问题进行评估,结果分别如下表所示:
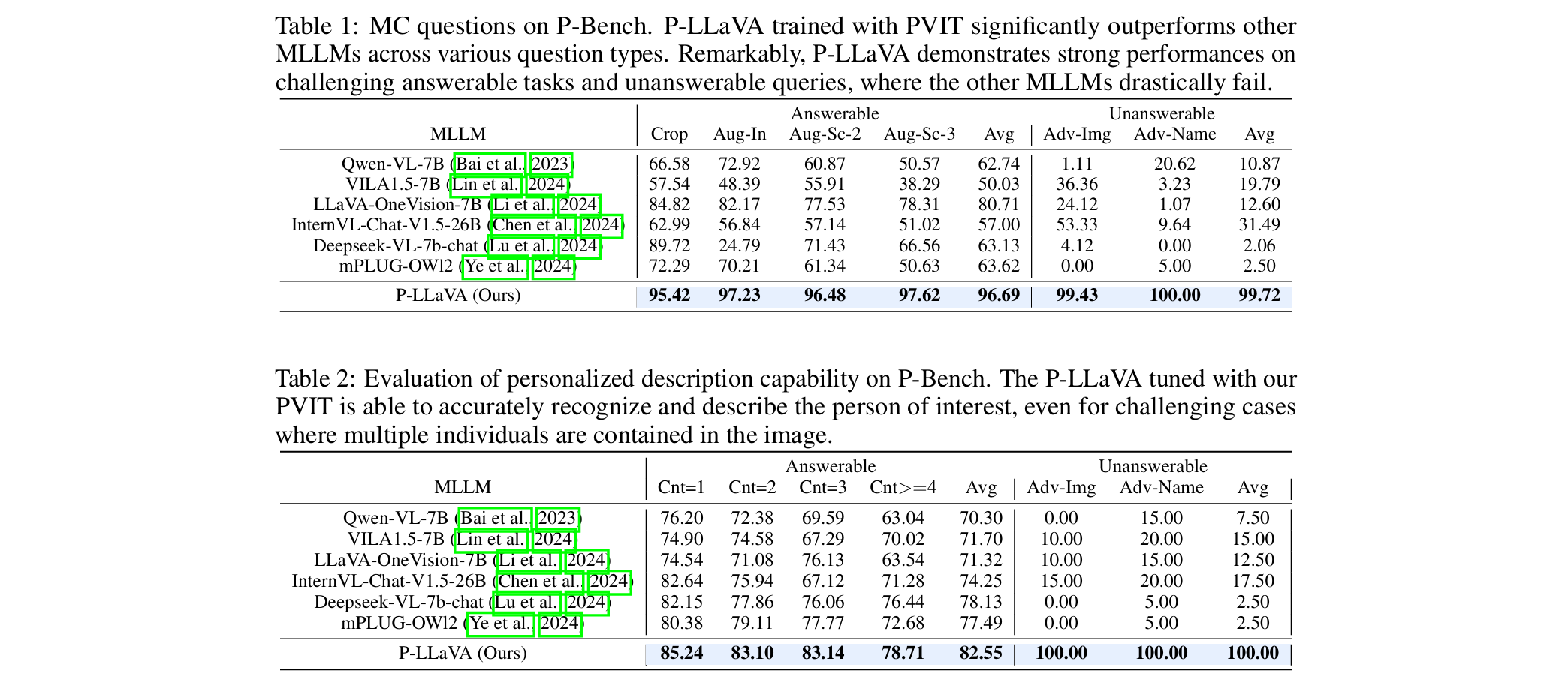
- 观察到当前最先进MLLMs的以下现象:
- 随着输入复杂度增加(即MC问题中的Aug-In、Aug-Sc-2和Aug-Sc-3,以及描述问题中包含更多人数的场景图像),最先进MLLMs的性能显著下降,这表明它们在识别场景图像中输入个体的能力和鲁棒性有限
- 所有MLLMs在不可回答问题上的表现均大幅下降。它们仍倾向于回答无法回答的问题,错误地将图像中的其他人识别为目标个体。这是因为MLLMs从未接受过拒绝回答此类问题的训练
- 使用PVIT对LLaVA进行微调后,观察到P-Bench中所有问题类型的性能均显著提升。正例和不可回答问题的性能均有所提高。在更复杂的场景图像上性能提升更为显著。这些结果验证了我们提出的调优策略在提升模型个性化能力方面的有效性
6.2 ABLATION STUDY
6.2.1 PERFORMANCE FOR VAIROUS NUMBER OF PERSON
- 下表展示了MLLMs在包含不同数量人物的场景图像的MC问题上的个性化性能
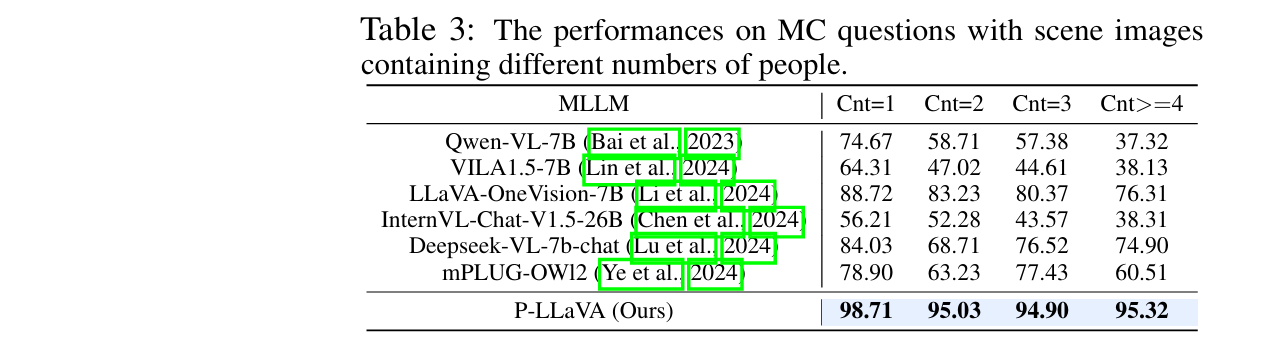
最先进的MLLMs在包含更多人数的场景图像上表现出性能下降,这是由于准确识别特定目标个体的挑战性增加
另一方面,我们训练的P-LLaVA在此类挑战性案例中仍保持高准确率,验证了其准确识别目标个体的能力
6.2.2 DATA ABLATION
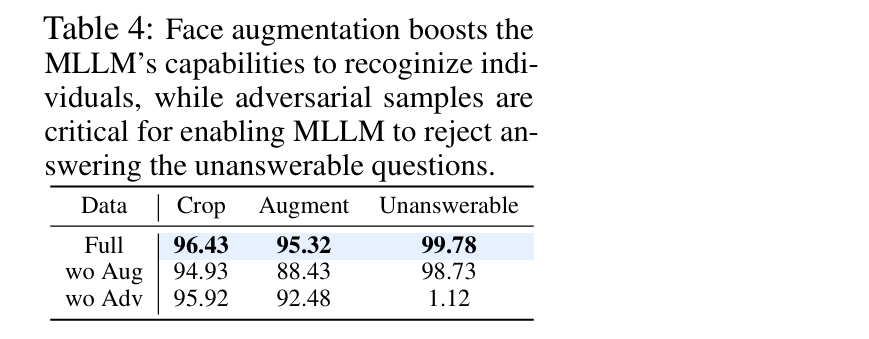
- 下表检验了构建数据集中每个组件的有效性。我们观察到以下现象:
- 使用PhotoMaker进行面部增强增加了输入个体的多样性,有效提升了MLLM识别个体的能力
- 对抗性样本对于使MLLM能够拒绝回答不可回答问题至关重要。如果没有对抗性样本,拒绝回答不可回答问题的准确率会迅速降至接近零
6.2.3 IMPACT OF DATA SCALE AND NAME REPETITION(数据规模和姓名重复的影响)
- 下表展示了使用不同数量数据训练后的评估准确率:横轴表示数据单元的数量,每个单元包含8000个样本
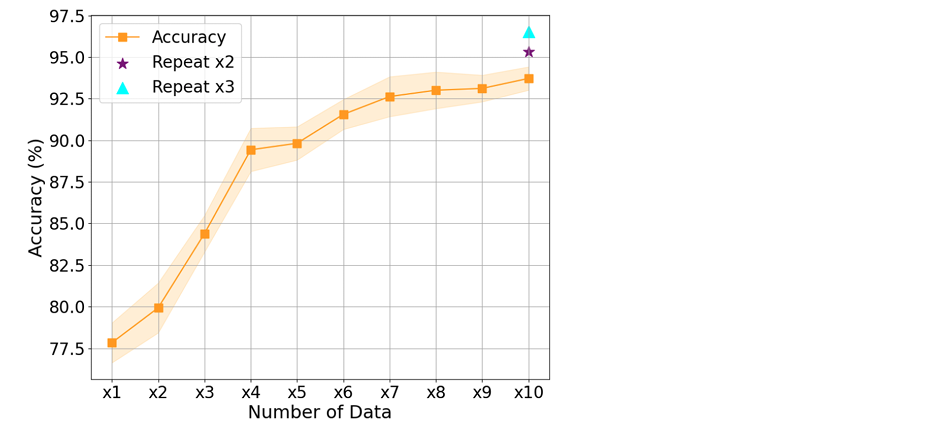
随着训练数据集的规模扩大,性能明显提升
即使使用相同的数据模板,通过使用不同姓名重复构建数据,MLLM的性能仍能进一步提升,这验证了训练中使用姓名的多样性使个性化能力更加鲁棒,并能泛化到新个体
7 CONCLUSION
在本工作中,我们提出了个性化视觉指令调优(PVIT),这是一种新的训练框架,能够针对特定个体进行个性化对话
为实现这一目标,我们首先开发了一个自动流水线,生成包含多样化视觉和对话上下文的个体训练数据
然后,我们利用这些数据对MLLM进行微调,显著提升了其个性化对话能力,这通过P-Bench基准测试得到了验证
DeepSeek论文要点总结
一、研究背景与问题
核心问题
- 当前多模态大语言模型(MLLMs)存在**”脸盲症”**,无法针对特定个体进行个性化对话(如无法识别图像中的Lisa并回答相关问题)。
- 现有方法需为每个新个体单独训练(如MyVLM/Yo’LLaVA),缺乏泛化性和实用性。
研究动机
- 推动MLLMs在个性化场景(如家庭机器人、智能助手)中的应用。
二、核心方法:PVIT框架
1. 核心创新
- 多模态前缀:将个体表示为
<个人图像, 个人介绍>对,作为模型输入的前缀。 - 个性化包装标记:引入
<person_start>和<person_end>标记,消除多个体输入的歧义。 - 无需微调新个体:通过上下文学习(in-context learning)实现泛化。
2. 数据生成流程(PVIT-3M)
- 阶段1:视觉概念构建
- 使用开放检测器(GroundingDino)定位人物,PhotoMaker生成多视角增强图像。
- 阶段2:双级信息提取与融合
- 个人级描述(裁剪图像生成细节特征) + 场景级描述(整体上下文) → 融合为连贯文本。
- 阶段3:数据集生成
- 利用LLM生成多样化QA对,覆盖个性化描述、自由问答、多选问答三类任务。
- 引入对抗性样本(如未出现的人物)提升模型鲁棒性。
三、评估与实验
1. P-Bench基准
- 评估维度
- MC问题:包含可回答(Crop/Aug-In/Aug-Sc)和不可回答(Adv-Name/Adv-Image)类型。
- 描述性问题:基于LongClip评估生成描述与图像的相似性。
- 核心发现
- 现有MLLMs在复杂场景(多人图像)和对抗性问题上表现显著不足。
2. 实验结果
- PVIT调优的P-LLaVA:
- 在MC问题中平均准确率达96.69%(SOTA模型为63.13%)。
- 在不可回答问题中拒绝回答准确率接近100%(SOTA模型低于20%)。
- 关键消融结论:
- 数据增强(PhotoMaker)提升个体识别能力,对抗性样本对拒绝回答至关重要。
四、贡献与意义
方法论贡献
- 提出首个基于上下文学习的MLLM个性化框架PVIT,无需为每个新个体微调。
- 构建首个大规模个性化多模态数据集PVIT-3M(3M样本)和评估基准P-Bench。
应用价值
- 推动用户中心的多模态交互(如家庭机器人、个性化医疗助手)的发展。
五、附录补充
- PVIT-3M数据细节:包含Crop/Aug-Sc/Adv-Name等多样化类型(详见附录A)。
- 训练配置:基于LLaVA-7B微调,使用8×A100 GPU训练30小时(超参见附录D)。
