自然语言处理 lec4-1 pre
More About Classification
Generative Models and Discriminative Models
Examples from Dan Jurafsky
任务:区分猫和狗的图片
问题:光线,遮挡,清晰度,动画风格等

- Generative Models(先学p(x,y)):估计描述猫和狗,有什么特征可以归类为猫,有什么特征可以归类为狗。训练两个模型比较得分,分类为猫或狗

- Discriminative Models(直接学习p(y|x)):学习区分性的特征,例如:狗带项圈

- 同分布的数据下,判别式模型性能更强,能够反映一些差别
Generative Models v.s. Discriminative Models
- Generative Models – Naive Bayes:
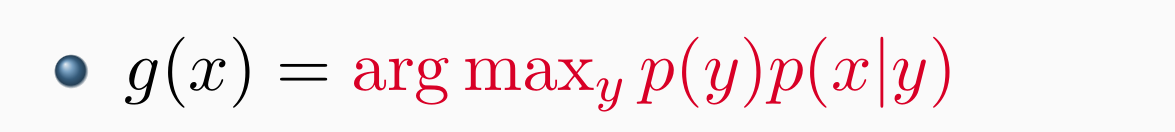
- Discriminative Models – Log-Linear model:
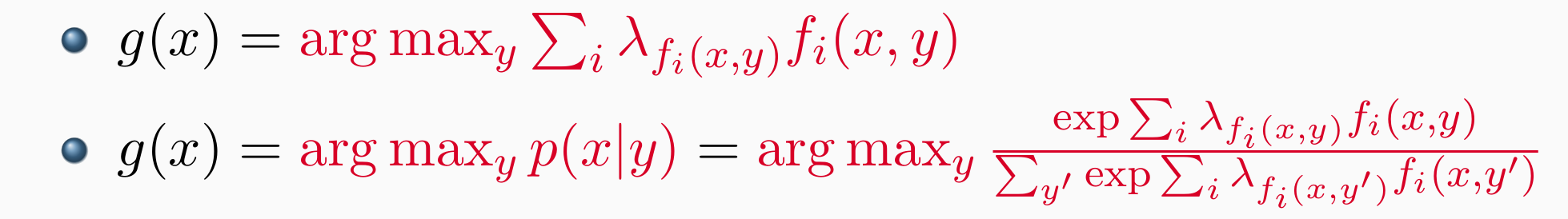
Model Evaluation
- 在大多数情况下,得到一组训练数据,并被要求构建一个分类器,该分类器将被提交到其他地方并在未知的测试集中进行评估性能:
- 设计模型
- 实施系统
- 测试并优化系统
- 到测试集测试性能
Training and Test Sets
Training dataset:估计参数
Test dataset:用于测试模型性能
Held-out Data and Hyper-Parameter Estimations
- 设置validation set(development set)来选择验证超参数: choose CF∗ where the corresponding M∗ obtains the best score on the validation set
Cross Validation
一个好的模型应该:
- 在训练集上表现好
- 应该有泛化能力,在没见过的数据集(测试集)上表现得也好(鲁棒)
如果训练数据充足的话,可以选择切割训练数据中的一小份作为没见过的数据调试超参数。重复这一步骤每次不同划分
K-fold cross-validation:将训练集划分为 K 个不重叠的折叠:X1,X2,…,XK。其中在 X1-K/Xi 上训练模型,使用Xi作为验证集调整超参数
最后再放到test set上进行测试
平均值和标准误差:
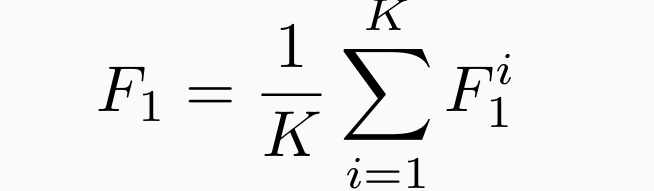

- 在实践中有时采用数据合成加入噪声,或者不均匀划分等等…
What are Language Models?
输入:一个词串,判断是否是“好”的英语,如何判断一个词串是否为该语言下好的表述?
判断依据:
- 语法?
- 词汇分析?
- 语用?前后句是否搭配?
但不可能将设计的判断依据都放入语言模型中,那么如何建模语言模型使得只利用语言数据进行评判?
Formally
给定一定大小的词汇表: V ={a, an, dog, cat, bite, bark, …. zoo, …}
可以产生有限的词串S:the dog barks;dog the bark a laugh smile…
希望对上述词串进行评判好坏:从概率角度,用概率分布P评判S:概率越大,说明词串“好”

Why Language Model ?
语音识别、OCR、手写数字识别、分词、机器翻译、语言生成、对话聊天机器人…
目标:忠实度(特定任务的完成度) + 通顺度(语言模型,和真实语言是否相似),希望找到忠实度和通顺度都比较好的词串
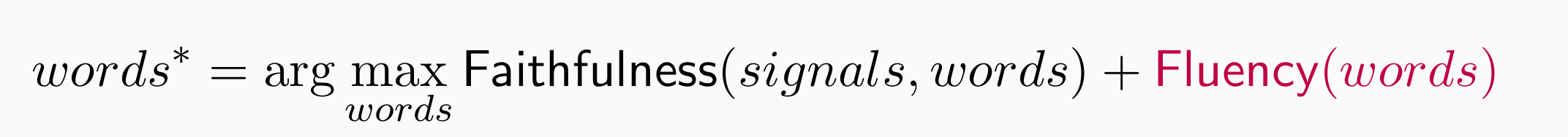
- 例如下面的翻译任务中,满足忠实度的词中选择更为通顺的
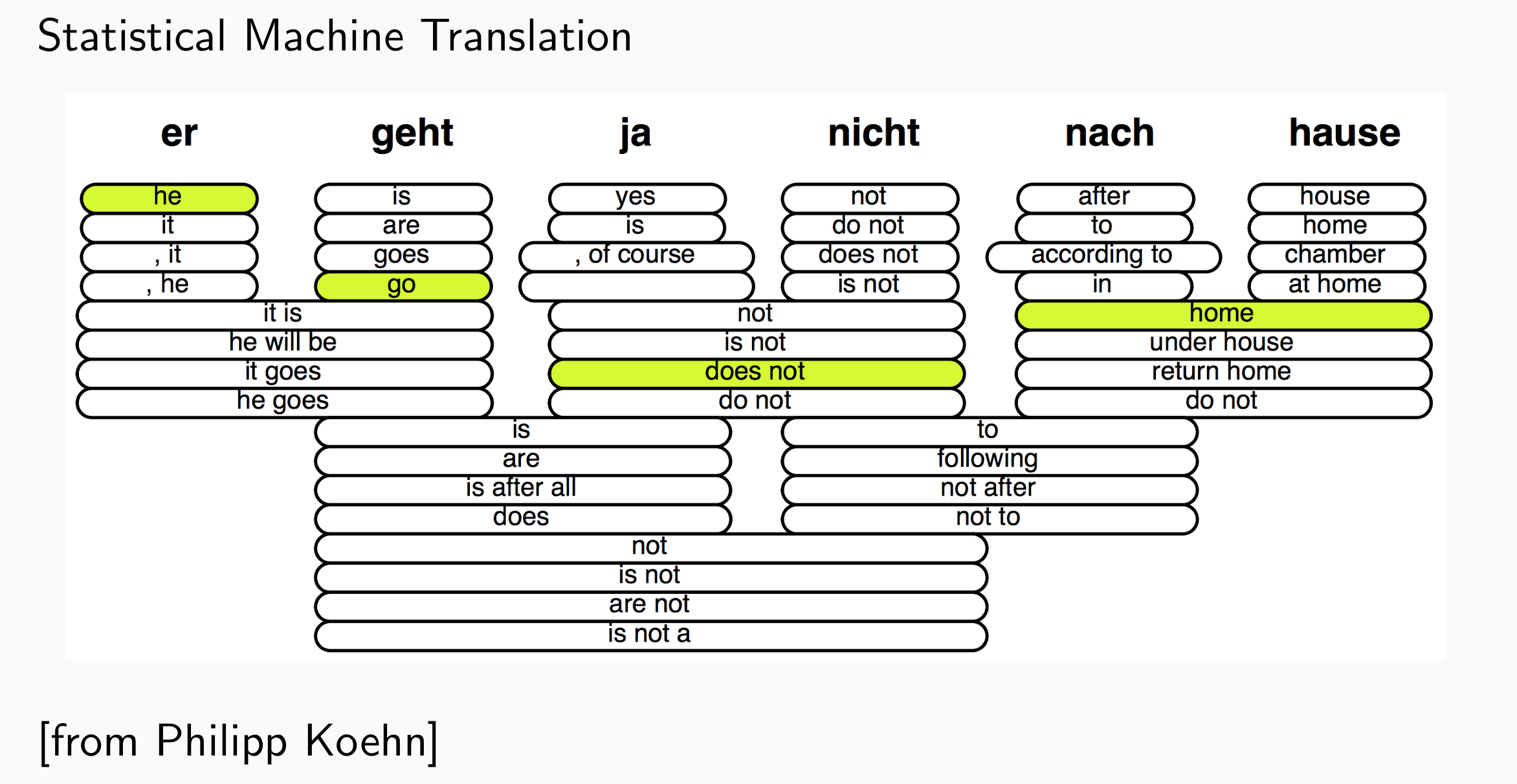
语言模型考察的不仅是词性,而是一种语言习惯
surprisal theory:下一个词有多“出乎意料”(有时是错误的,有时是极好的):可以用预测下一个词的概率来度量,预测率越高,越平淡;预测率越低,越出乎意料