
可视计算与交互概论 notes整理第12-14章
第十二章 光照和着色
什么是着色
- 着色(shading):为几何体的表面加上材质的过程,或者说着色是绘制几何体表面的颜色使得它看起来像我们设定的材质的过程
光照
一个物体除非自己发光,否则都需要反射来自外界的光线进入人眼才能被我们看到
光源:源头的光照
平行光
因为太阳离地球很远,所以来自太阳的光线可以近似当成平行光(directional light)
可以用光照的方向和强度这两个量来描述平行光:
- 方向表示为世界坐标中的归一化三维向量 d
- 强度定义为垂直于光入射方向单位面积上接收到的光照射的功率
光强需要在光的垂直方向测量,接收光的表面与入射光线之间存在夹角 θ,相同的平面面积接收到的光强与 θ 相关。由于平面面积投影到光的垂直方向需要乘以一个因子 cos θ,所以图右边的平面接收到的光强就是左边的 cos θ 倍,也就意味着光强比左边直射时更小。如果平面与光的方向完全平行,cos θ = 0,表示接收到的光强为 0
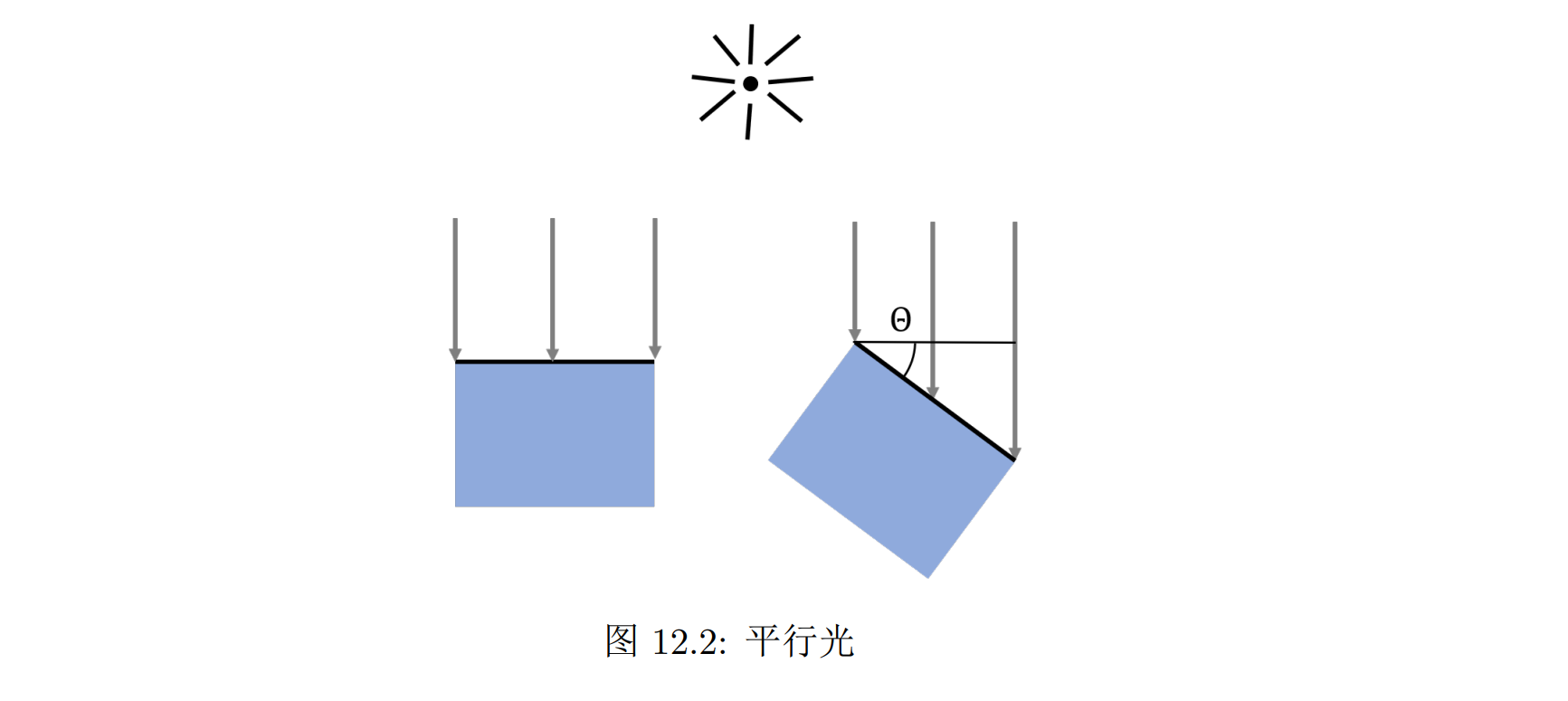
- 用一个颜色 Id 表示平行光的光强,其三个分量表示 RGB 三个频率范围内的光强分量,这样当入射光线与平面法线之间的夹角是 θ 时,平面接收到的光强就是 Idcos θ
环境光
在阴影的暗部也不是完全黑暗的,这一部分区域就是由环境光(ambient light)照亮的
环境光来自四面八方,是太阳光经过云层大气的散射以及其他物体的反射得到的,因此环境光是一种间接光照(indirection illumination)
在最简单的模型中,我们可以认为环境光在各个方向是均匀的,于是只需要一个光强 Ia 就能定义环境光
点光源
蜡烛、灯泡等可以近似描述为点光源(point light)
点光源没有方向性,但是与环境光不同,点光源的强度会随着距离衰减。在远处接收到的光强要远远小于光源中心附近的光强,这个衰减的比率可以计算得到是 1/r²,r 表示观测点与点光源的距离
描述点光源,我们需要记录点光源的位置 p,以及单位长度处的强度 Ip,这样在距离为 r 的地方接收到的光强就能表示为 Ip/r²
反射模型
- 反射模型要研究光线经过物体表面反射之后入射到摄像机中的光强
漫反射
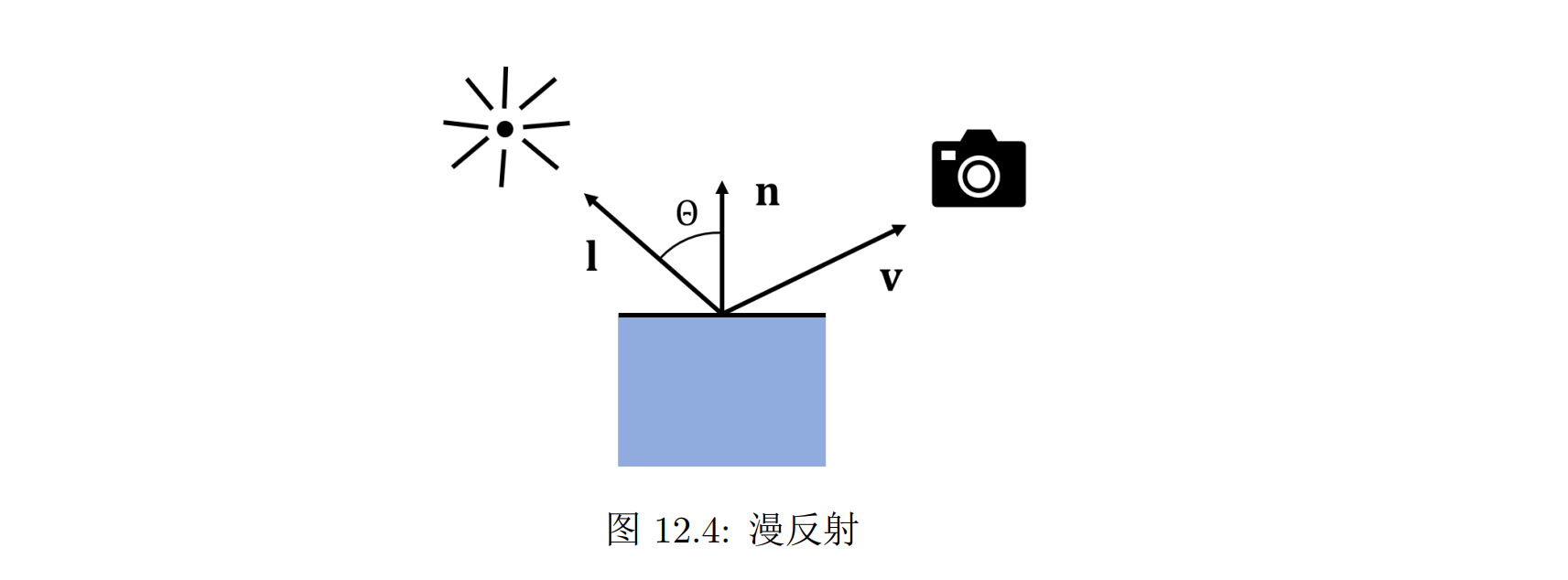
漫反射(diffuse reflection):当物体的表面极度粗糙不平时,入射到表面上的光线会被反射到各个方向
朗伯体(Lambert body):当物体表面只有完全随机的漫反射
朗伯体的特点在于其在各个角度看起来反射的光强都是相同的,这符合我们日常生活中对于粗糙表面的直觉
对于完全的漫反射而言,其反射到摄像机中的光强可以写为:Ld = kd(Ia + Id max(0, n · l))。其中 kd 是表面的漫反射颜色,n 是表面法向,l 是光源的方向:
- kd 是表面漫反射的颜色,尽管表面在空间角度上均匀反射入射光线,但是在频率空间上并不是均匀的,有的频率被表面吸收,有的频率被反射,漫反射的颜色也就表示表面在RGB 三个分量上的反射系数
- Ia 和 Id 分别表示环境光和平行光的强度,存在点光源时只需要把 Id 替换为 Ip/r²即可
- n · l 得到的就是 cos θ,也就是我们在前面平行光部分介绍的表面与入射光线方向不垂直带来的系数,与 0 求 max 表示只有当光源在法向一侧时表面才能被照射到,否则就处在阴影中
镜面反射
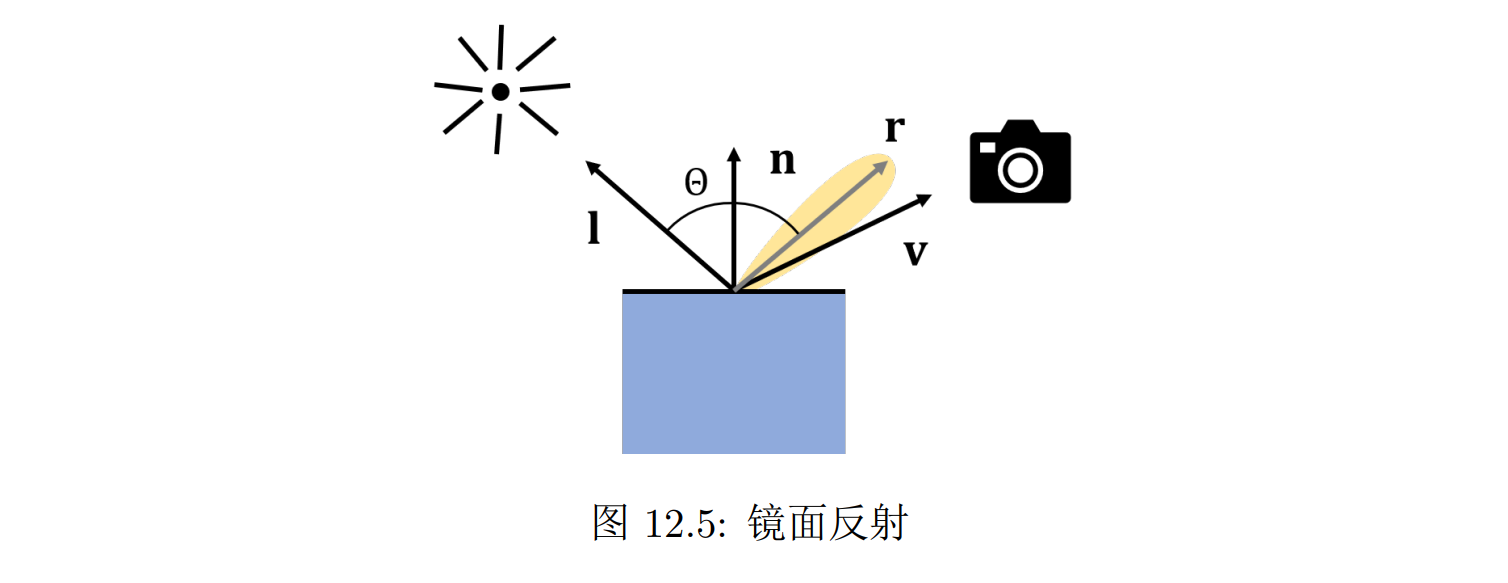
与漫反射相对的就是镜面反射(specular reflection)
理想的镜面反射满足反射定律:光线的出射角等于入射角
理想的镜面反射要求物体表面非常光滑,一般情况下我们可以认为反射光线分布于理想反射光线 r 附近的圆锥内,中心最强,边缘比较弱
用数学表示反射光的分布:衡量 v 和理想镜面反射光线 r 的接近程度,给观察到的光强乘以一个对应的衰减因子,在 v 与 r 重合时为 1,在 v 和 r 距离很远的时候为 0
计算 r:将 l 分解到 n 的方向和垂直于 n 的方向,延 n 的方向不变,垂直于 n 的方向反号,这样就能得到 r
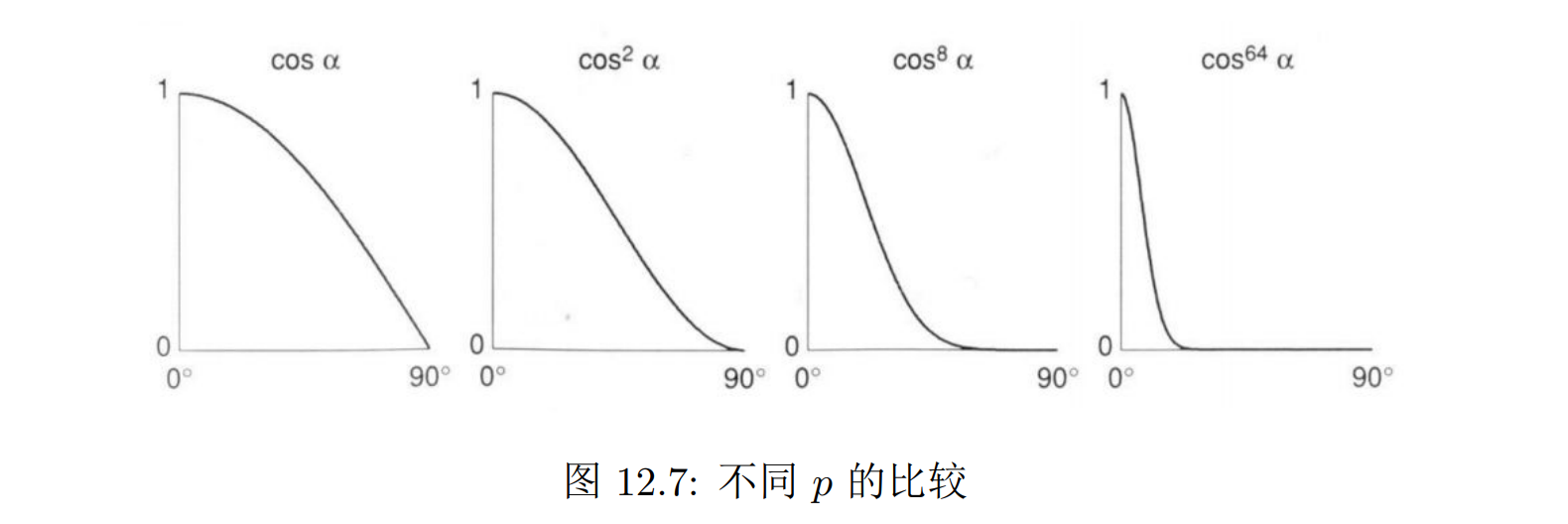
规避掉直接求解 r 从而简化计算:定义半程向量 h = normalized((l+v)/2),并且计算 h 与 n 之间的夹角 α 。当 v 正好沿着 r 的方向时,半程向量 h 应该正好沿着 n 方向,而随着 v 逐渐远离 r,α 也在逐渐增大。于是 α 可以正确度量 v 和 r 之间的差异,同时 h 在计算上要更简单,所以我们可以用 α 来计算光强衰减的因子 cos α (在 α = 0 时取到 1,在 α 增大的时候的逐渐减小)
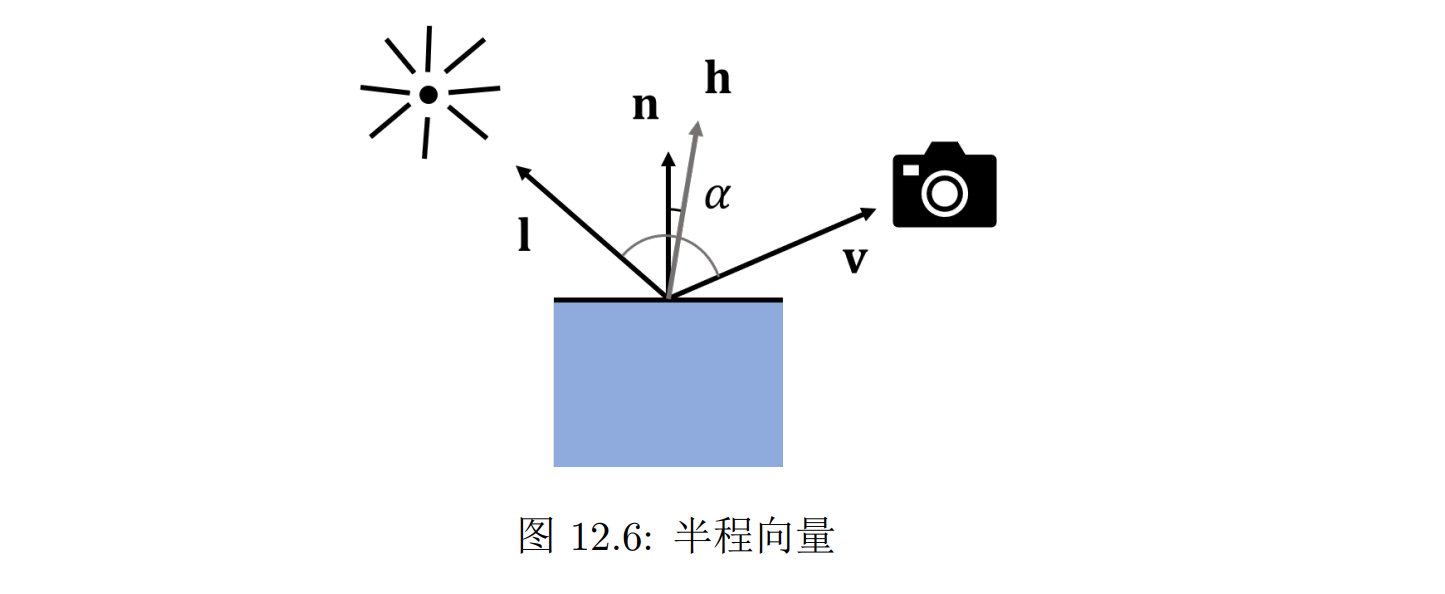
- 镜面反射的公式:Ls = ksId max(0, n · h) ^ p
- 公式里 ks、Id、max 的含义与漫反射公式一致
- 公式的最后多乘了一个p 次方,这个参数 p 是用来控制镜面反射的集中度的。当 p 比较小时 cosα ^ p 衰减比较慢,表示光线比较分散,表面比较粗糙;当 p 比较大时,cosα ^ p 衰减快,表示光线集中,表面比较光滑
Blinn-Phong 反射模型
Blinn-Phong 反射模型:一般的物体我们可以认为同时存在漫反射和镜面反射,结合公式我们就得到了一般物体的反射模型
Blinn-Phong 反射的公式:L = kd(Ia + Id max(0, n · l)) + ksId max(0, n · h) ^ p
至于 Blinn-Phong 之前的 Phong 模型,其实就是前面介绍的在计算镜面反射时计算视线与反射光线之间的夹角,而非半程向量与法线之间的夹角
光栅化
可以通过光栅化来将虚拟的几何和材质转化为屏幕上的像素。那么与之相对应的我们就需要解决两个问题:
- 如何确定每个三角形面片上每个像素的颜色
- 如何处理三角形之间的遮挡关系
深度缓存来处理三角形之间的遮挡:每个像素中除了记录颜色信息,同时还记录了深度信息;每个三角形都需要进行逐像素的深度检测,最终只保留深度最小的颜色
确定像素的深度:利用像素在屏幕空间中的位置和每个顶点经过变换后的平面位置和深度,在屏幕空间中的位置通过插值得到深度,使用我们在之前二维图像绘制中介绍的双线性插值的方法,或者等价的使用重心坐标
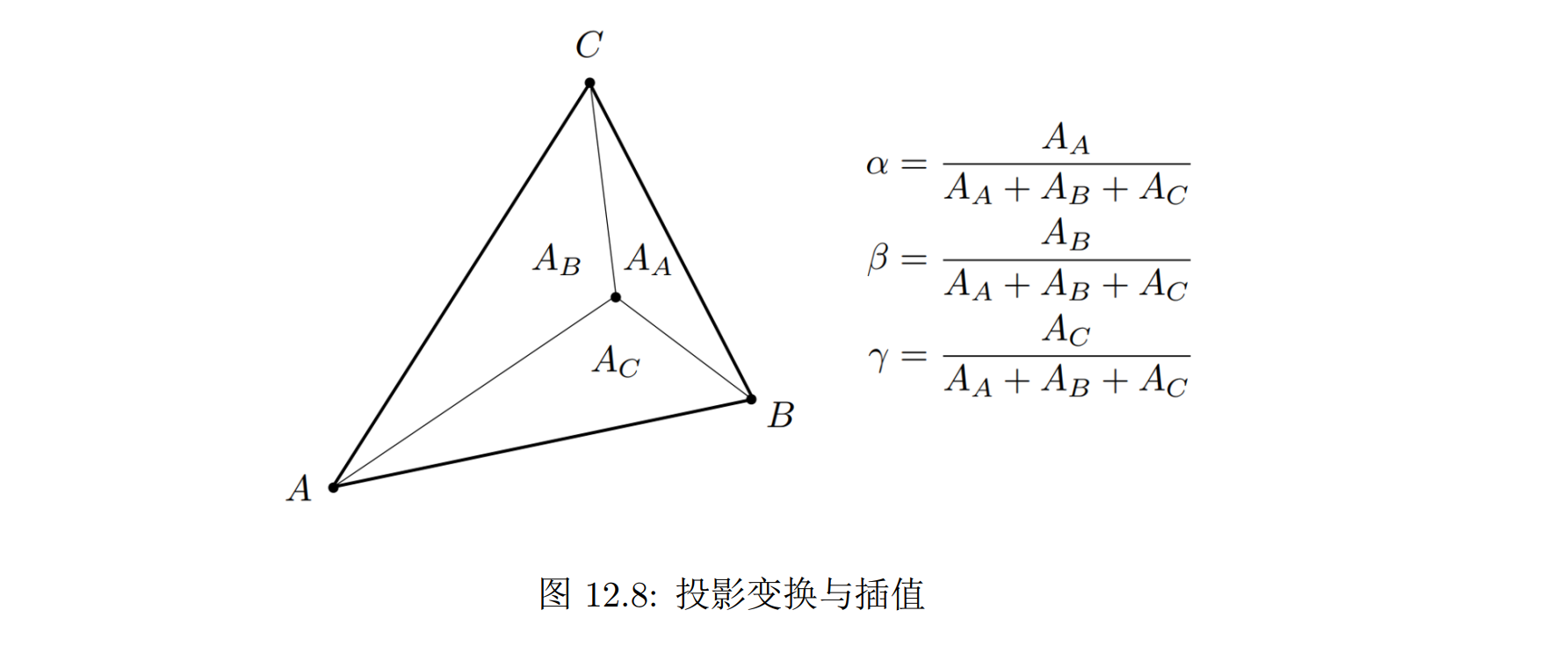
对于三角形中的任意一点,可以使用其分割出的三个小三角形之间的比值计算出其相对于三个顶点的权重:相对于点 A 的权重 α 是与 A 点不相邻的小三角形与大三角形的面积比值。当顶点位于点 A 时,满足α = 1, β = γ = 0,α + β + γ = 1。并且由于面积随着顶点位置线性变化,三个权重也会随着位置线性变化。因此,顶点上的深度、颜色等信息,可以使用 α、β、γ 三个权重加权平均三角形顶点上的值得到
但不管我们使用什么在屏幕空间的线性插值方法,得到的深度是不准确的
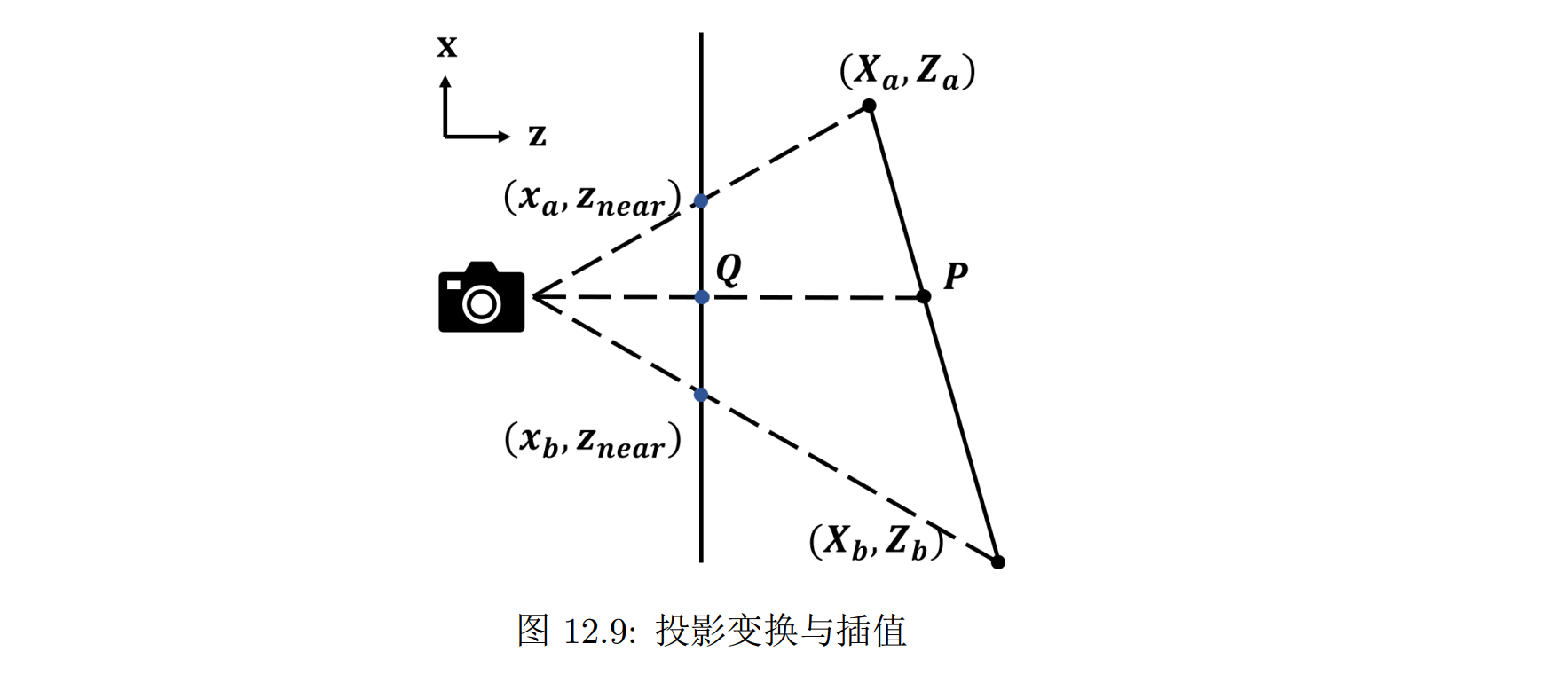
考虑二维情况,这时相机的近平面就是一条直线,(Xa, Za) 到 (Xb, Zb)之间的线段经过投影变换变换到了 (xa, znear) 到 (xb, znear)。假设 xa 和 xb 上下对称,考虑它们中点像素 Q 的深度。如果直接用屏幕空间的 Q 点做插值那么就会得到 Q 点的深度是 (Za + Zb)/2.然而 Q 点的深度应该由其在原线段上的点 P 决定,P 显然并不位于原线段的中点上,因此真实的 Q 点的深度并不是 (Za + Zb)/2
发生这个错误的原因在于透视投影变换是非线性的,重心坐标依赖于三角形的面积(二维中是长度),而透视投影并不能保证所有点面积均匀缩放
正确的做法是在透视投影前做插值,需反求每个像素在投影前的位置,然后在三维空间中线性插值
透视矫正插值(Perspective-CorrectInterpolation):假设我们需要对三角形的三个顶点上的值 fa, fb, fc 进行插值,透视矫正投影的公式表述为:其中 α, β, γ 是使用屏幕坐标求得的重心坐标,wa, wb, wc 是透视投影之后得到的齐次坐标的第四个分量
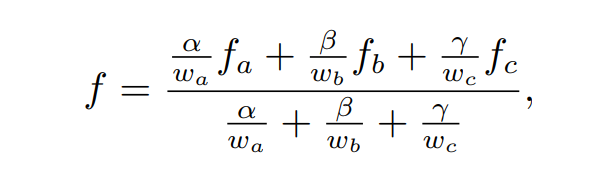
这个公式表明透视投影对于插值的影响只是在重心权重上多乘了一个 1 / w 的因子。参照透视投影的矩阵公式,变换后齐次坐标的第四个分量 w 实际上就是顶点在变换前的深度 z
透视矫正下像素深度的插值公式:
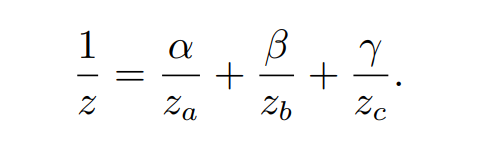
使用透视矫正的方法插值深度,等价于在屏幕空间对 1/z 进行线性插值,这也说明了我们之前对深度 z 直接进行线性插值是错误的
深度缓存技术也不是万能的,最大的问题在于计算的代价
背面剔除(Back Face Culling)可以减少时间代价:如果在场景中我们绘制的都是封闭的几何体,那么显然几何体的背面是永远不会出现在屏幕上的。我们只需要判断三角形的法向与视线方向是否同向,也就是 v · n > 0。如果同向,那么这个三角形就是背面,我们也就不用费力再对它判断深度缓存和着色了
着色模型
- 在给定光照、物体几何和材质之后,决定像素颜色最关键的就是表面的法向
平面着色
- 平面着色(Flat Shading):使用三角形的面法向,逐三角形确定颜色

在平面着色中,每个三角形只有一个法向,每个三角形只有一个颜色,于是我们能在渲染结果里看到很多独立的面片,但是我们还是可以直观看到整个形状上明暗的过渡以及高光
如果我们的三角面片足够多,我们就能得到一个光滑的表面,但是如何在三角形数量不够的时候依然让表面看起来光滑呢?这就引入了第二种着色方法
Gouraud 着色(Gouraud Shading)
Gouraud 着色(Gouraud Shading):计算每个顶点的颜色,然后在三角形中间插值
在 Gouraud 着色中,不再是逐三角形着色,而是逐顶点着色。使用每个顶点的顶点法向计算光照颜色,然后在三角形内部用重心坐标进行插值

在曲面的大部分区域里我们得到了光滑的颜色过渡,但是在高光区域我们能明显看到三角形插值的痕迹。同样,如果我们增加三角形的数量,我们依然能够得到光滑的渲染结果,但是有没有方法能够在当前的精度下进一步减小离散化带来的误差?
如果三角形近似的曲面正对着光源方向,那么三角形中心的高光应该要强于顶点处的高光,这表明三角形中心的颜色并不能写成顶点颜色的线性插值,因为插值出来的亮度不可能强于被插值的顶点的亮度
因此对颜色插值并不是一个好的策略,我们需要考虑三角形内部颜色随位置的非线性变化
Phong 着色(Phong Shading)
- Phong 着色(Phong Shading):既然不能通过插值得到颜色,我们就只有对三角形上的每一个点都计算一个颜色,这样我们的着色方案就不再是逐顶点的,而是逐像素的

在 Phong 着色中我们需要单独计算每个像素的颜色,也就需要每个像素的法向
像素的法向与深度一样,需要在透视投影之前插值才能得到正确结果,因此我们需要使用如下公式进行透视矫正的重心坐标插值,同时在插值之后还需要归一化
- Phong 着色能够正确画出椭圆形的高光区域,不再有 Gouraud 着色的不自然高光了
总结
从平面着色到 Phong shading,我们发现我们需要计算的颜色数量在增加,从逐三角形到逐顶点再到逐像素,换句话说就是着色频率在增加,效果也在逐渐接近真实
最简单的绘制三维物体表面的方法:光栅化 + 深度缓存 +Phong 着色
风格化渲染

风格化渲染,或非真实感渲染(Non-Photorealistic Rendering,NPR):不同艺术风格的渲染结果,这些风格服务于不同的目的,比如游戏、教育、工业等等
风格化渲染的两个非常重要的特征:
- 线,包括物体边缘的轮廓线,表示结构的结构线,表示光影的阴影线等等
- 艺术化的着色,在风格化渲染中,我们往往希望颜色有不同的艺术效果,比如卡通风格、冷暖色调、油画风格等等
首先,我们需要绘制出物体的轮廓线。做法:
通过物体的法线方向来判断物体的边缘位置。法线应该正好与视线方向垂直,也就是 v·n ≈ 0。因此我们可以判断当着色点的法向方向与视线方向点乘在 0 附近时,就绘制边缘线的颜色。这种方法虽然简单,但是得到的边缘性的粗细并不是一致的,如果判断范围过小,就会出现边缘线断裂,如果过大就看起来不再是一条线
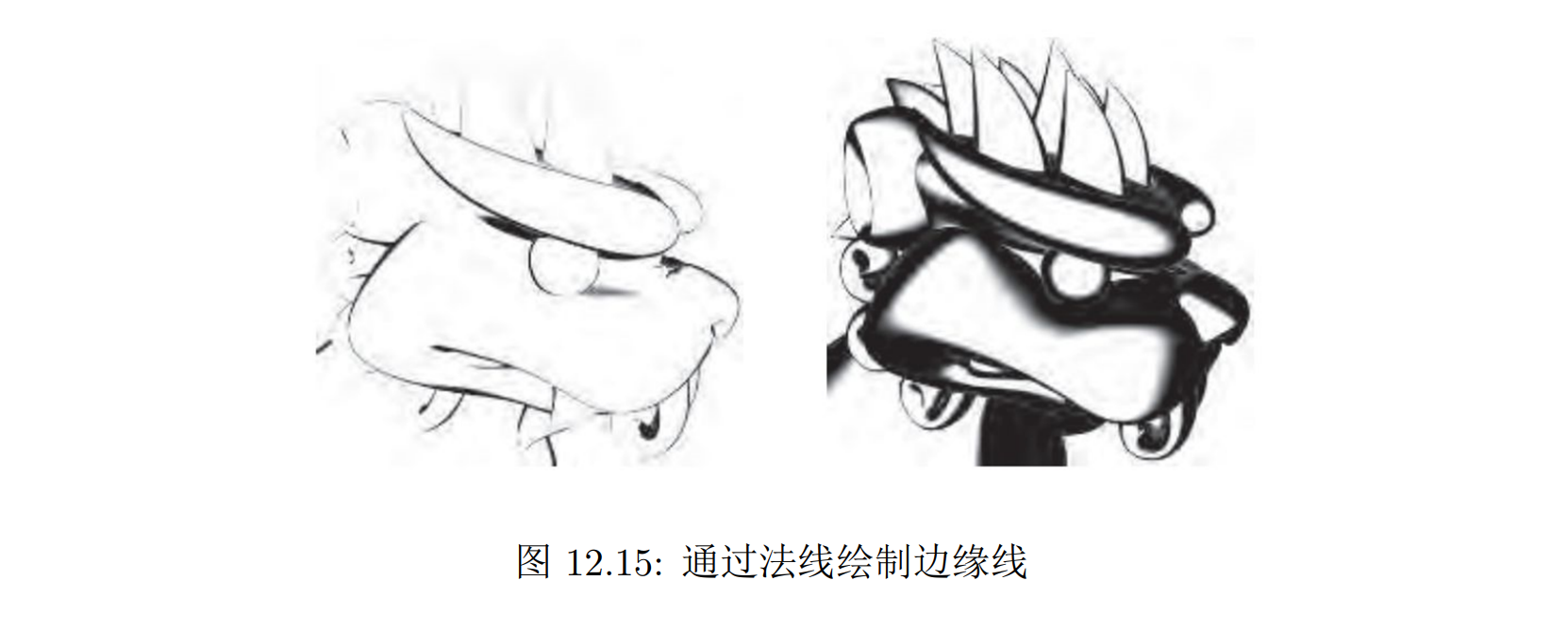
程序化几何法避免了边缘性粗细不一致的问题。们绘制两遍几何体,第一遍只绘制几何体的背面,绘制颜色为边缘线的颜色,并且将几何体稍微向外扩展一点,第二遍再在背面之上绘制正面的几何体,这样没有被遮挡的部分就是边缘线了。需注意两点:
- 在扩展背面的几何体时,需要每个顶点在法向上移动的距离在屏幕上最终是等宽的,不然还是会出现边缘线不等宽的现象.因此在计算移动距离时,我们需要考虑投影变换的影响
- 绘制正面的几何体时,需要使用深度缓存,不然的话我们就可能丢失一些物体上的轮廓线(比如茶壶盖的轮廓线)

还可以在正常绘制结束之后,再从结果的图像中提取出边缘。提取边缘的方法可以使用前面图像章节介绍的卷积方法
为了避免颜色的干扰,我们也可以单独渲染一张法线图,提取出边缘线之后再跟正常图像合成
物体的体积感并不是通过光影来塑造的,而是通过颜色的冷暖塑造的
Gooch 着色(冷暖色着色):由于冷暖色并没有明显的亮度区别,因此我们可以同时观察到物体的各个部分的细节,同时保有立体感,因此这种着色方法经常用于科学插图、工业设计中
在 Gooch 着色中,我们给定了一个冷色 kcool 和暖色 kwarm,物体上的颜色通过在这两个颜色之间插值得到。插值的系数由物体法向与视线之间的夹角决定,具体的插值公式为:其中 l 是指向光源的方向,n 是表面法线方向
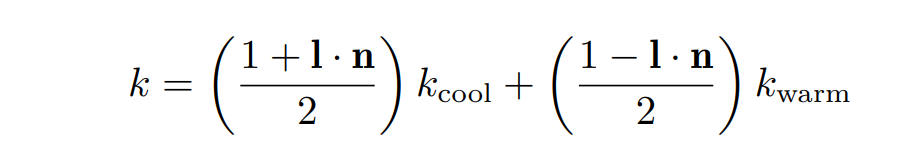
- 在此基础上,我们还可以将连续的颜色变化变成阶梯状的分段颜色,这样就得到了卡通效果
第十三章 图形管线
现代的大型实时游戏场景中包含大量的三角形面片,为了让人眼不感到间断,每秒至少需要渲染 30 帧以上场景.在CPU 上想要串行执行这样规模的计算几乎是一件不可能的事情.为了高效地完成实时图形渲染,人们对渲染的流程进行了很长时间的优化和演进,最终形成了图形管线(GraphicsPipeline)
由于图形管线中很多操作可以进行高度并行化,专用图形硬件——GPU应运而生
光栅化渲染总结
前置知识:
- 如何在屏幕上绘制一个简单的三角形(遍历判断像素点是否位于三角形内)
- 如何在简单光源下给三角形着色(Bling-Phong 着色模型)
- 如何处理三角形的遮挡和走样问题(z-buffer,super-sampling)
结合到一起可以实现一个基本的软件渲染(对应于使用 GPU 的硬件渲染)流程:
- 输入待渲染模型(若干三角形面片及其光照属性)、各光源属性
- 对所有三角形,计算其顶点的投影坐标以及深度,存储其法向量等着色信息
- 取一个三角形,遍历判断所有像素是否在投影后的三角形内部
- 对三角形内的像素点,遍历所有光源,将着色叠加得到像素点颜色
- 计算三角形在此处的深度值,如果相对于 z-buffer 深度更浅,更新 z-buffer,并将此处颜色写入 framebuffer
- 对所有三角形进行 3-5 步操作
- 将 framebuffer 同步到显示器,渲染结果被显示在屏幕上
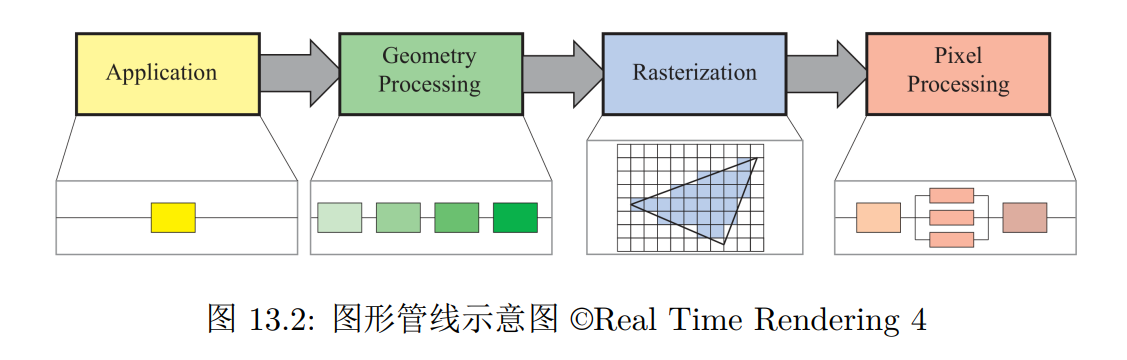
渲染流程中首先对输入进行几何处理。基础的几何处理包括投影、计算顶点颜色等,简称 T&L(Transform and Lighting)
几何处理输出的一系列三角形在接下来的步骤中被光栅化,得到处于三角形投影内部的像素点
这些像素点根据光源属性、光照模型以及后面我们要提到的纹理映射被着色,最后通过 z-buffer、alpha-blending 等算法确定最后的颜色输出,显示到屏幕上
图形管线与硬件 API
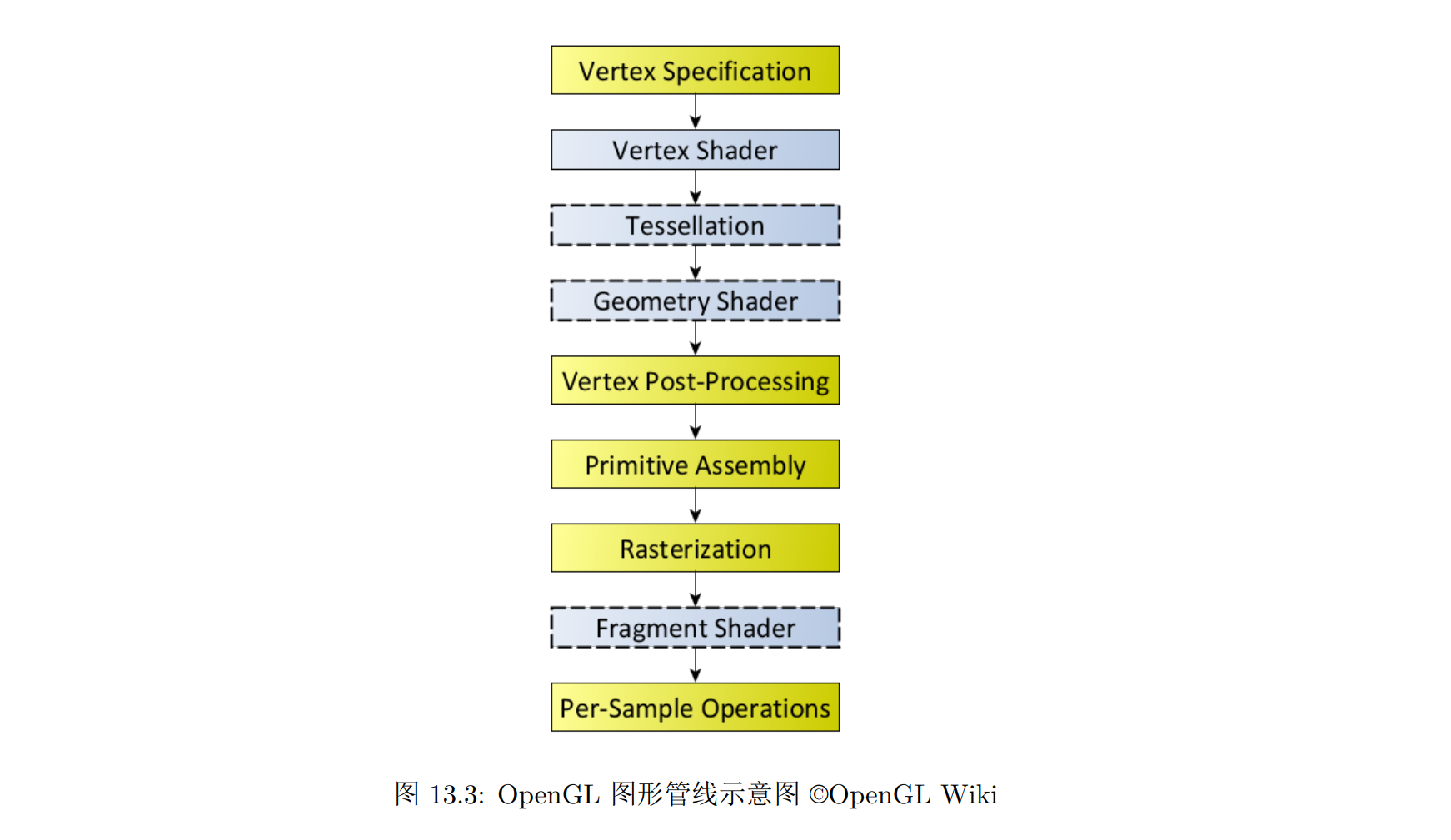
在 OpenGL 中,几何处理阶段被进一步细化为:
- 顶点着色(Vertex Shading)
- 曲面细分(Tessellation)
- 几何着色(Geometry Shading)
- 顶点后处理(Vertex Post-Processing)
- 图元组装(Primitive Assembly)
这些阶段中,顶点着色、曲面细分、几何着色是可编程的(使用 OpenGL 着色器语言 GLSL 编写),而其余部分在硬件驱动中实现,仅能通过一些选项调整其参数
需要手动编写的仅有顶点着色器(Vertex Shader)一项,这一项需要处理顶点到投影空间的坐标变换,并计算光照有关的输入数据
除此之外,顶点着色器还可以修改顶点的位置,利用这一特性可以实现刚体旋转、关节动画、软体拉伸变形、水面波纹、地形起伏等一系列复杂的特效
顶点着色器仅能修改顶点位置而不能增加/删除顶点,为此 OpenGL 的图形管线后续加入了曲面细分和几何着色阶段,大大增加了几何处理阶段的自由发挥空间
1 | // 一个简单顶点着色器的 GLSL 代码 |
#version 450声明这是 OpenGL 4.5 的着色器代码,in、out 分别修饰着色器的输入和输出,uniform 代表全局数据,layout 表示数据在内存中存储的顺序
整个几何处理的运行逻辑位于main函数中,gl_Position则是 OpenGL 定义的全局变量,表示输出的顶点位置,是顶点着色器中唯一必须输出的量
fragColor作为输出,后续将传给下面提到的片段着色器,其内容是可以自由指定的
光栅化过程是光栅化渲染的核心部分,这一部分被硬编码在 GPU 中,并针对性地做了大量优化,仅能通过参数微调
光栅化之后,GPU 并行处理的对象就不再是顶点,而是屏幕中的像素,对每一个像素的着色操作被定义在片段着色(Fragment Shading)阶段
这一阶段是可编程的,所有的光照、着色都在这一阶段完成,所编写的程序成为片段着色器(Fragment Shader)或像素着色器(Pixel Shader)
片段着色结束后,OpenGL 会对着色器的输出颜色根据深度、透明度等进行裁剪与混合,同时根据指定的反走样算法执行反走样操作.在 OpenGL 中,这些操作都是编码在 GPU 中的,无法自定义实现
1 | // 简单片段着色器的 GLSL 代码 |
#version 450声明这是 OpenGL 4.5 的着色器代码,in、out 分别修饰片段着色器的输入和输出,整个着色的运行逻辑位于main函数中
这里fragColor是与上面提到的顶点着色器中输出相对应的量.在 OpenGL 中,如果片段着色器的输入和顶点着色器输出的名称和类型都相同,那么 OpenGL 就会自动将二者关联起来
顶点着色器和像素着色器中都有类型为vec3的fragColor的参数,这就意味着像素着色器得到的输入是由顶点着色器的输出决定的
但与简单的参数传递不同,顶点着色器输出的是逐顶点的值,像素着色器接受的输入是逐像素的输入.这中间进行的转换正是光栅化这一步进行的操作
默认情况下,OpenGL 会把顶点着色器的输出通过我们上一章介绍的透视矫正的线性插值方法插值到每个像素上,喂给像素着色器使用.因此即使我们在像素着色器中没有进行任何的插值操作,直接输出得到的就是光滑插值之后的结果
Gouraud 着色与 Phong 着色之间的差别:
- Gouraud 着色就是在顶点着色器计算 Blinn-Phong 光照模型,输出得到颜色之后通过光栅化插值
- Phong 着色是在顶点着色器输出每个顶点的位置、法向等信息,在像素着色器中计算 Blinn-Phong 光照模型
OpenGL 提供了三种插值选项,由插值限定符(Interpolation Qualifier)决定:
- flat in vec3 fragColor 指这个变量在光栅化阶段不会进行插值,像素着色器会得到三角形第一个顶点上的值
- noperspective in vec3 fragColor指这个变量会在屏幕空间做线性插值
- smooth in vec3 fragColor 指这个变量会通过透视矫正的方法插值,默认情况可以去掉smooth不写
专用图形硬件——GPU

GPU 中包含一个统管任务的 Giga Thread Engine 和几个不同的GPC(Graphics Processing Cluster),每个 GPC 又包含若干 SM(Streaming Multiprocessor)和一个 Raster Engine
每个 SM 中包含很多个核心,这些核心都可以并发执行计算
GPU 堆核心也是有代价的:GPU 上的单个核心通常计算能力不高,并且 GPU 核心的访存延迟明显高于 CPU 核心,这也意味着 GPU 上算法的数据局域性非常重要
GPU 的特点是:高吞吐、高延迟
应用程序首先调用图形 API 的 drawcall,此时 CPU 传递一系列指令和数据给GPU.顶点缓存里的数据被分给各个核心并发执行,这里执行的命令包括顶点着色器、几何着色器、坐标变换等
在 GPU 中,数据加载和命令执行是可以同时进行的,这样数据一旦到达 GPU 就可以参与计算
此后,这些顶点数据通过 Work Distribution Crossbar 被分配给各个包含三角形面片的 GPC.Raster Engine 接到数据后,执行光栅化计算,并完成数据插值等任务,将必要的着色的数据传给片段着色器.所有的片段着色器也是并行执行的
片段着色器给出颜色后,经过 ROP(Render Output Unit)处理一下遮挡、混合,就可以写入帧缓冲(Frame Buffer)等待屏幕显示了
图形管线的新进展
Deferred Rendering
Deferred Rendering:“按需着色”,只着色那些会对最终渲染结果产生影响的三角形部分
与之对应的传统图形管线着色算法称为 Forward Rendering。区别:
- Forward Rendering 中深度测试在着色之后
- Deferred Rendering 中着色被推迟,先计算深度测试和着色所需的属性,再完成着色过程
Deferred Rendering 大大减少了实际执行的着色计算量,而缺点是对透明物体的处理比较麻烦,只能提前裁剪一部分着色,无法产生明显效果;并且 Deferred Rendering 需要存储额外的 G-buffer 数据,这会带来相当高的显存开销
在 Forward Rendering 的流程中,计算着色所需的投影点三维坐标、法向量、漫反射颜色、材质等变量都由顶点着色器直接传给片段着色器进行处理,相当于每个三角形都传了一个二维数组给片段着色器
实际上,这些量只有在着色像素点上的值才有意义,因此对于一个被部分遮挡的三角形,遮挡部分可以无需给出这些变量。如果没有透明物体存在,片段着色器只需要知道自己对应的那个表面点上的着色信息,所有需要的着色信息数量仅构成一个二维的数组(对应二维的屏幕像素分布),这就大大减少了着色需要的数据传输和计算.这个数组通常被称为 G-buffer
Compute Shader
而在渲染过程中,传统的图形管线之外有时也需要用到并行计算.例如,在着色完毕向屏幕输出时,需要对输出图像进行卷积
要么在 CPU 上完成这一过程,要么借助 GPU 另写一份通用计算代码,前者将引入不必要的CPU-GPU 数据传输开销,而后者在数据交互上非常麻烦
为了解决这类问题,ComputeShader 应运而生.可以在 GPU 上执行通用计算任务,但和顶点着色器、片段着色器同属图形 API 范围内,且具有相似的交互逻辑;这使得在渲染过程中调用 GPU进行通用计算变得尤为方便
Compute Shader 最大的意义是它大幅扩展了在图形管线中进行自定义的可能性,想要在图形管线上作出改变,最直接的办法就是引入 Compute Shader
1 | // 简单 Compute Shader 的 GLSL 代码 |
gl_NumWorkGroups表示启动的线程组数量,gl_WorkGroupID表示当前线程组的编号;每个线程组内的线程数由变量in的 layout 指定
有了 Compute Shader 之后,甚至可以绕开传统图形管线在 GPU 上实现渲染
Mesh Shader
要求对顶点的增加/删除,而这仅仅用顶点着色器是无法实现的
在曲面细分和几何着色器加入管线之前,这些操作只能在 CPU 上进行,然后传递到 GPU,这大大影响了渲染程序的渲染效率。现在,借助图形管线中的几何处理部分,这些算法都可以在 GPU 上实现,从而减少了 CPU-GPU 的通信成本,提高了渲染性能
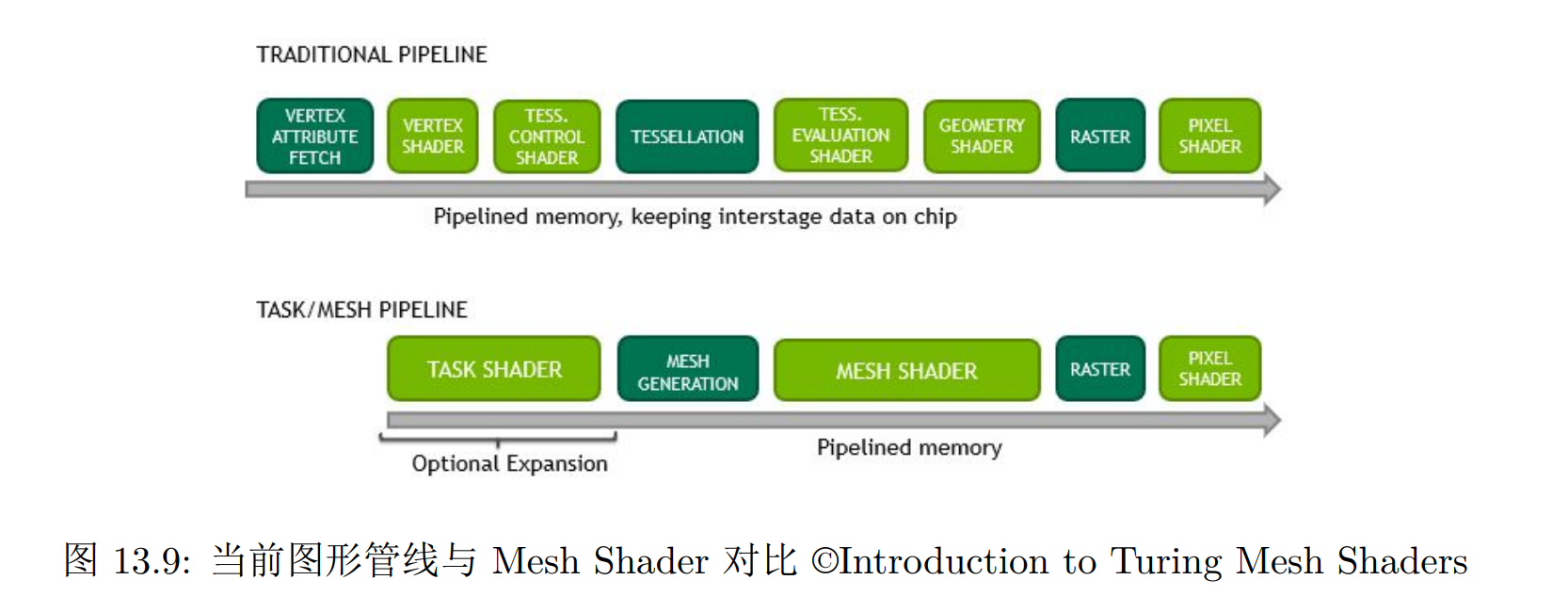
尽管加入了更多的几何处理着色器,现有的图形管线中仍区分了顶点着色器、曲面细分着色器、几何着色器等多种流程,并且其顺序是固定的,这给几何处理带来了不便
Mesh Shader:将几何处理统一为图形管线中一个完全可编程的步骤,几何处理的灵活性和性能都将大幅提高。在 Mesh Shader 中,GPU 线程不再与顶点或者三角形绑定,并且执行的指令也不再要求是相互独立的,一个线程可以同时获得多个顶点或三角形的信息
顶点处理、曲面细分、几何处理的顺序也更加灵活,可以把顶点处理放在最后以降低显存压力
Mesh Shader,复杂几何体的剔除、程序化几何体生成等处理都可以更加自然地放在 GPU 上进行,而不必再借助 Compute Shader 来实现
全局光照
为了在性能与效果之间取得平衡,一种办法是结合使用光栅化管线与光线追踪思想进行渲染
三角形面片的光线求交需要硬件单元支持,但是有一种数据结构可以实现更简单的光线求交:那就是我们之前提到的隐式表面表示 Signed Distance Field
因此,只要对场景中的每个物体都建立一个低精度的 Signed Distance Field 作为近似,就可以通过光线追踪算法,在片段着色阶段以较低成本实现相对准确的全局光照效果
由于 Signed Distance Field存储在网格上而非像素或者表面上,帧与帧之间的表面信息是连续的,因此可以利用上一帧的表面光照信息辅助加速全局光照的计算
低精度的光线追踪有其缺点,那就是容易产生噪点;但借助 Compute Shader,在光追结果上进行滤波降噪,即可消除这一问题的影响
第十四章 纹理映射
像木头、锈铁这样的材质包含了丰富的细节,表面的颜色、粗糙度等属性在表面上都不是均匀的.可以想见,想用高精度的几何表示表面的这些信息是不现实的,更为实际的做法是将这些信息记录在二维的图像中,然后将其附加到几何表面上
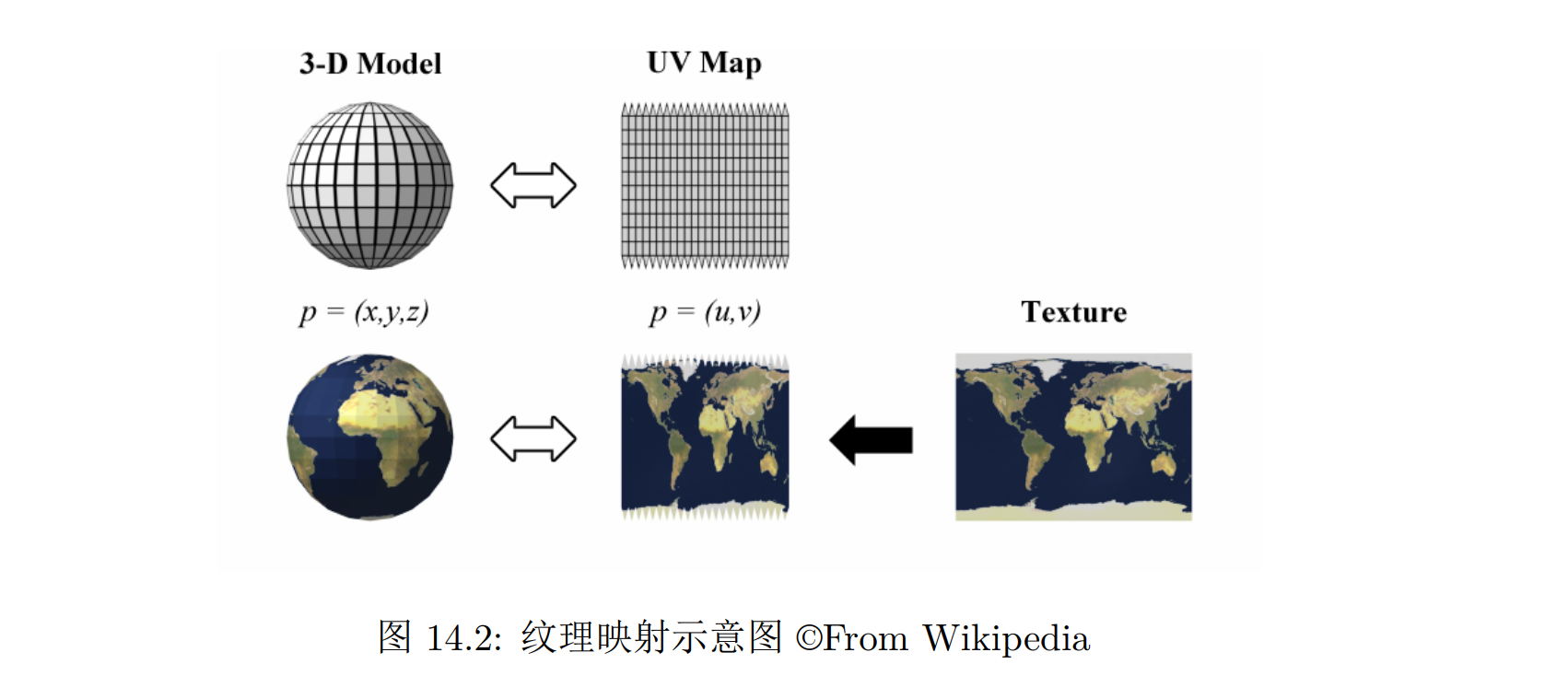
纹理(Texture),或贴图:记录表面颜色、粗糙度等信息的图像
纹理映射(Texture Mapping):将纹理映射到三维几何体上的过程
纹理映射
- 纹理坐标(Texture Coordinate),记为 (u, v),所以也可以称其为 uv 坐标:们可以通过该二维坐标坐标访问到上面的颜色值

要将二维的图像贴到三维几何体上,我们实际上就是要找到几何体表面上的点到纹理坐标的一个映射,这样每个点的颜色就与纹理图像上的一个像素对应起来
对于三角形网格表示的几何体而言,只需要在每个顶点上记录一个 uv 坐标,那么表面上所有的点就都可以通过重心坐标的插值得到对应的 uv 坐标
与之间介绍深度插值时一样,uv 坐标的插值也必须使用透视矫正插值来保证插值的正确性
纹理图像上 uv 坐标的范围常被设置为 0 到 1,但是表面上记录的 uv 坐标可以超过这个范围,这时可以将表面的 uv 坐标模到 [0, 1) 的范围内再对应纹理图像中的像素,带来的结果就是一张纹理被重复粘贴在表面上,称之为重复纹理(Repeating Texture)
展 uv(UVUnwrapping):几何体上记录的 uv 信息一般在建模完成之后由艺术家给定。简单的几何体我们可以直接给出解析的 uv 坐标:单位球上每个点 r 的 uv 坐标可以写成:
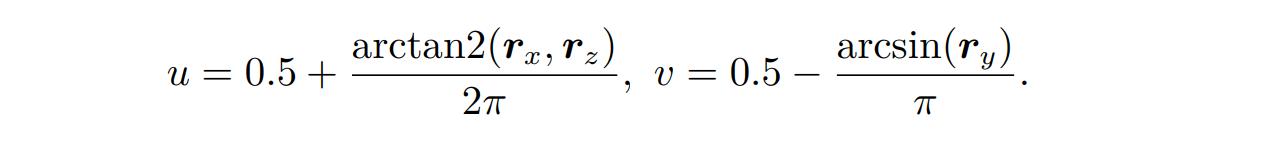
在纹理映射中,拉伸非常常见,并且往往在各个地方并不均匀。如果随意定义 uv 坐标,很容易就会不自然地拉伸问题造成最后渲染上的问题
因此在展 uv的过程中,应该尽量使得 uv 整体上分布均匀。尤其对于复杂的几何体,艺术家往往会将表面分割为不同的块,不同块之间的 uv 并不连续,但是在块内整体比较均匀

如果表面被分割,uv 不连续,这意味着在不同块的边界线上一个顶点有可能需要多个uv 坐标,因此在三角形网格的保存时,我们需要在同一个位置创建多个顶点,具有相同的位置和不同的 uv 值
左边的三角形 012 和右边的三角形 345 公用中间的两个顶点,但是它们在两侧的 uv 坐标不同,因此必须拆分为独立的顶点
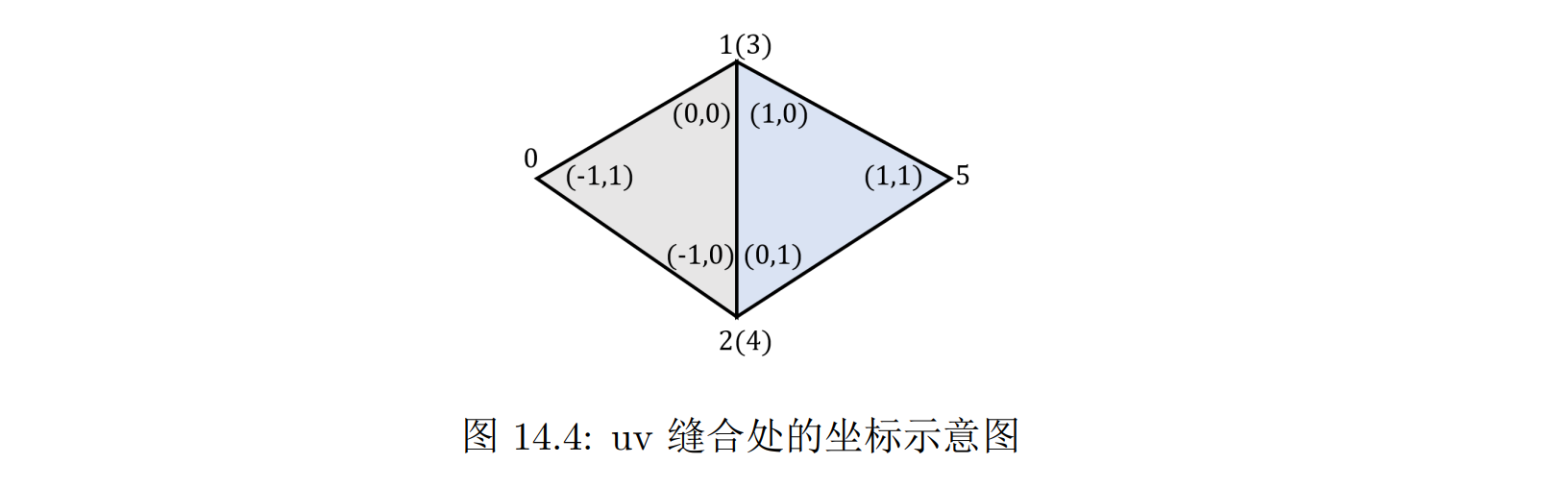
- uv 拆分和 uv 缝合:将几何体表面分块然后粘起来的过程
纹理坐标插值
在 Phong 着色中,我们需要获取每个像素的颜色,也就需要提取每个像素的 uv 坐标然后在纹理图像中查询
由于 uv 坐标在表面连续变换,我们可能遇到图像中被查询的点不在像素中心的情况,这时可以选择将 uv 坐标约化到最邻近的像素,而为了得到更平滑的结果,也可以在纹理图像中进行插值得到 uv 坐标对应的颜色
一般使用的插值方法就是双线性插值(Bilinear Interpolation)
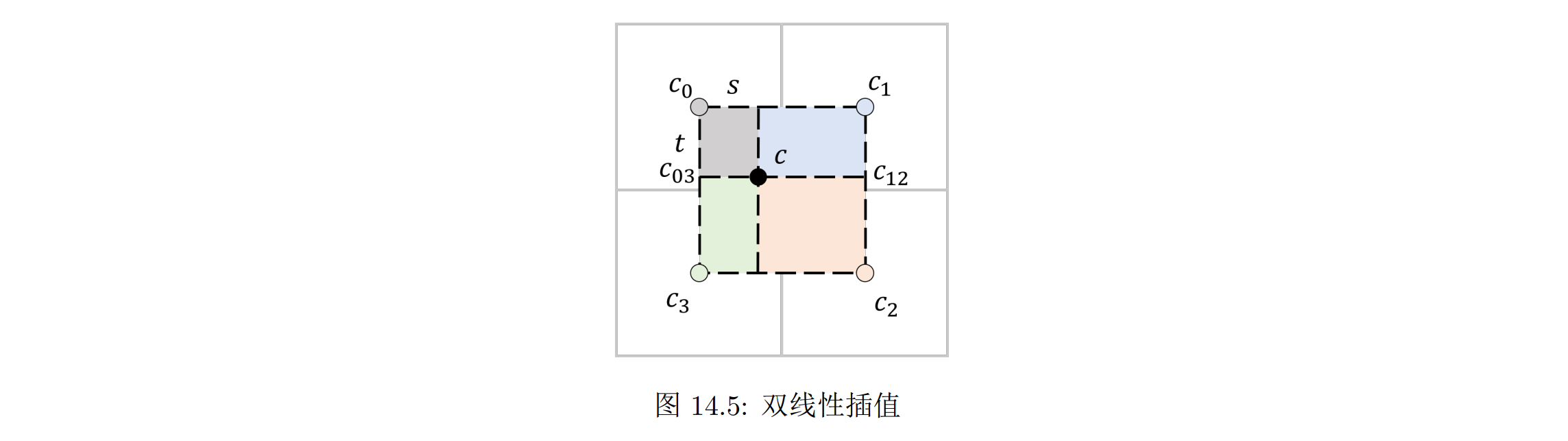
当我们查询的点位于纹理像素 c0, c1, c2, c3 构成的正方形中时,我们可以求其相对左上角的像素在水平和竖直方向占正方形边长的比例 s 和 t,然后在两个方向各做一次线性插值
假设我们先做竖直方向的插值,可以得到两个端点的颜色 c03 = tc0 + (1 − t)c3,c12 = tc1 + (1 − t)c2.然后再做水平方向的插值,就得到了查询点的颜色:c = (1 − t)(1 − s)c0 + (1 − t)sc1 + (1 − s)tc3 + stc2。最终插值得到的颜色可以看成是四个端点颜色的加权平均,权重是对应矩形面积
双线性插值不是唯一的在二维像素中插值的方法,同一维一样,我们也可以选择更高阶的基函数,用更多的采样点插值得到颜色,当然计算成本也会相应提高
最邻近方法有明显的锯齿,双线性插值就能得到比较平滑的效果,双三次插值在头发丝等地方更为平滑,但是在大片区域上跟双线性插值并没有明显差别

纹理反走样
当纹理图像比较小时,我们需要通过插值来实现超采样,那么反之如果纹理过大时。远处的网格出现了摩尔纹,近处的网格上出现了锯齿,这正是我们之前在讲解光栅化时遇到的走样现象
光栅化的走样现象来源于采样不足,纹理的走样也同样可以用采样理论分析:在屏幕空间均匀采样每个像素,但是每个像素对应的纹理空间中的区域并不是均匀的.在距离较远的地方,一个像素实际上对应纹理图像上很大一片区域,其颜色也应该是这一大片区域的平均
如果我们只采样了像素中心对应的纹理颜色,自然就会导致采样不足而出现纹理走样的现象
Mipmap 算法:
想要纹理在近处清晰并在远处没有走样,我们就需要对纹理做不同程度的模糊化
每次采样都重新做模糊化肯定是一个计算复杂度很高的操作,为了降低实时计算的开销,最理想的方法就是预计算
在制作纹理的时候就计算纹理经过不同层次的低通滤波之后的结果,一起保存下来,这样在采样的时候就从重新计算模糊化变成了在不同层次之间的查询
预计算多少层次的结果才能保证不会出现走样?假设我们想要保存尽可能多的模糊层次,每次将相邻的 2 × 2 的像素平均为 1 个像素,这样图像的大小就会变为原来的 1/4
这个过程重复尽可能多次,最终需要的内存大小就是原图像的1 + 1/4 + 1/4² + · · · = 4/3,也就是说最多只会比原来多占用 33.3% 的内存
原始纹理图像的 RGB 三个通道被分成了三个单色图像分别储存在三个色块,空出了左上角的部分储存低通滤波之后的图像,其大小正好是原始图像的大小
第一层低通滤波的图像按相同的内存布局储存在左上角,这样又能空出一块储存下一层的图像.这样递归进行下去,之后只有一个像素,我们可以看到整个 Mipmap 消耗的储存空间正好就是原来图像的 4/3 倍
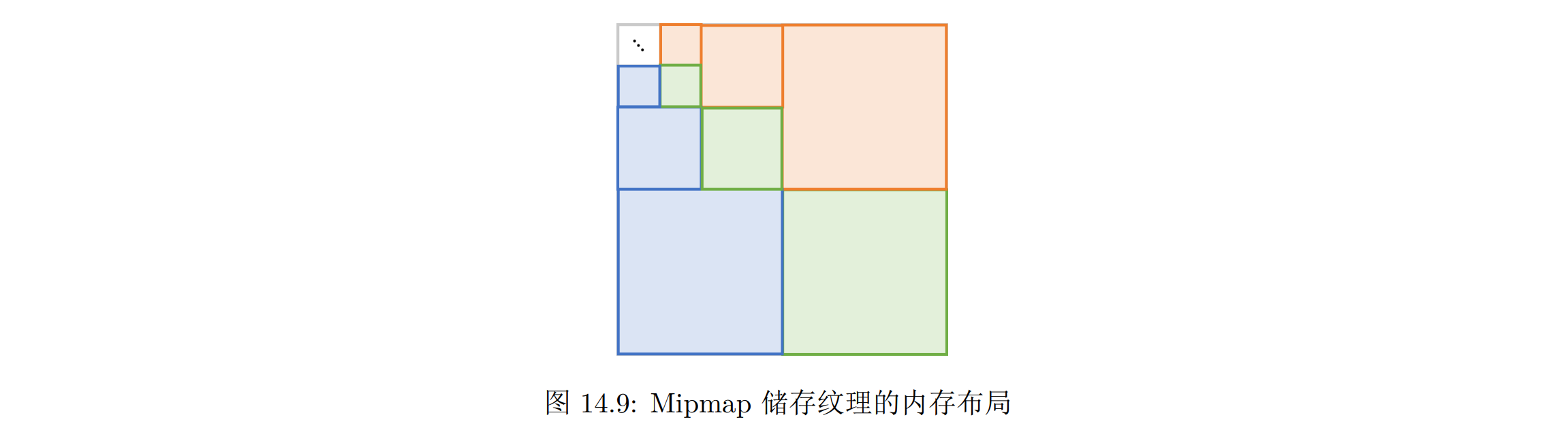
建立了低通滤波的层级结构之后,我们需要在每次着色的时候在层级之间查询,问题就落在了如何确定着色点到屏幕的距离并与层级对应起来。
并不需要着色点相对于屏幕的真实距离,我们实际需要的是屏幕空间到纹理空间的放大倍数。如果一个屏幕像素在纹理图像中边长被放大了 2 倍,我们就在第 1 层查询,如果边长被放大了 4倍,就在第 2 层查询.这个放大倍率我们可以通过有限差分来计算
们计算相邻屏幕像素之间纹理坐标的差作为该点局部映射梯度的估计,那么屏幕空
间 x, y 两个方向的拉伸比例就可以表示为:
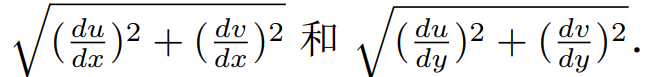
- 取这两个比例的最大值我们就能得到一个像素放大比率的估计,再用 log 将其约化到整数就能得到对应的层级:
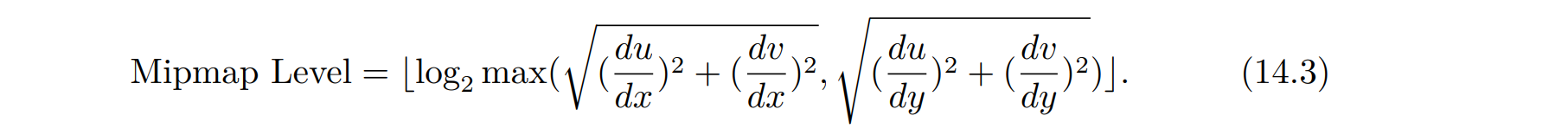
找到对应层级之后,我们就可以使用前面介绍的插值方法在对应层级的图像中找到纹理坐标对应的颜色,返回给着色器进行着色
为了得到更平滑的过渡结果我们也可以选择不约化到一个层级,而是在两层之间插值。也就是在上面公式中不进行取整操作,而是用得到的浮点数在两层之间做线性插值
加上本身在层内就需要做双线性插值,实际进行的采样方法就是三线性插值

从结果可以看到,锯齿和摩尔纹都消失了,说明 Mipmap 确实取到了反走样的作用.但是同时,远处的网格糊成了一片。可以发现网格线在远处变粗了,说明在垂直网格线的方向进行的过度的模糊
屏幕像素并不是在两个方向等比例拉伸的,在远处的像素被拉成了长条形
如果按照正方形的方式进行模糊处理,就会出现在某个方向过度模糊的结果,导致像素糊成一片
这表明我们需要各向异性的低通滤波,需要根据像素拉伸的具体情况在两个方向选择不同的模糊层次
各向异性 Mipmap(Anisotropic Mipmap)
各向异性 Mipmap 中,我们需要预计算除了 2 × 2、4 × 4 这样原来就有的层次外,还需要计算 2 × 4、4 × 2 这样的模糊比率
需要的储存空间就从原来的 4/3 变成(1 + 1/2 + 1/2² + · · ·)² = 4 倍
可以使用和 Mipmap 类似的方法储存预计算后的纹理,将原始图像(包含 RGB 三个通道)放在左上角,然后向两个方向拓展

各向异性的 Mipmap 使用与 Mipmap 类似的方法确定层级,但是我们不再取两个方向放大比率的最大值,而是各确定一个放大倍率然后寻找各向异性的层级
各向异性 Mipmap的局限:各向异性 Mipmap 并没有解决所有的各向异性情况。如果像素是延对角线方向拉伸,我们还是会找到两个方向相同的模糊比率,这时在垂直对角线方向依然是过渡模糊的
想要完全解决各向异性的问题,我们需要更复杂的方法,比如椭圆加权平均滤波(EWA 滤波, Elliptical Weighted Average Filtering, EWA Filtering)
纹理应用
- 在纹理上记录表面的材质信息,比如在着色里介绍的漫反射颜色、镜面反射颜色、粗糙度都可以通过纹理储存在图像中。,最后由着色器合成到一起
记录几何
纹理除了可以记录颜色,还能记录几何信息.如果物体的表面非常凹凸不平,就得用高精度的三角形网格来表示这些凹凸结构
如果这些凹凸结构只影响了最后的渲染成像,而不影响物体的其他效果(比如和其他物体的碰撞),我们就可以尝试用相对粗糙的几何表示物体,然后将这些凹凸不平的效果记录在纹理中
可以记录表面的法向,称之为法向贴图(Normal Mapping),或者也可以称之为凹凸贴图(BumpMapping)
法线是三维空间中向量,可以对应到 RGB 颜色的三个分量,因此可以用储存颜色贴图相同的格式储存
根据分解法向量的坐标基矢不同,可以将法向贴图分为以物体空间为基矢和以表面切向空间为基矢的两种

对比右边使用位移贴图(Displacement Mapping)的结果,可以看到右边球的边界上也是粗糙的
位移贴图是另外一种用纹理记录几何的方式,与法向贴图不同,位移贴图会改变物体的几何,它记录的是顶点位置的偏移
只改变了粗糙几何顶点的位置,我们依然得不到精细的锯齿。因此,位移贴图一般会配合细分曲面技术一起使用,比如在现代图形管线中存在的几何着色器(Geometry Shader),可以在渲染阶段增加几何表面顶点的个数
记录光影
如果我们身处室内,来自窗户、灯光、地板反射等等因素使得环境光有明显的各向异性
可以假象用一个球将渲染场景包围起来,球上每个点都是一个点光源,整个球一起组成了环境光
为了记录各个方向的环境光,我们可以使用一张贴图映射到球上,称为环境光贴图(Environment Mapping)
问题:
- 在环境光贴图的照射下,物体上往往会有丰富的明暗信息,如果我们每一帧都重新计算环境光的光照计算量比较大
- 同时,物体复杂的几何会在物体上投下不规则的阴影.这种阴影不同于平行光照射出来的边界明显的阴影,称为硬阴影,而是平滑过渡的软阴影
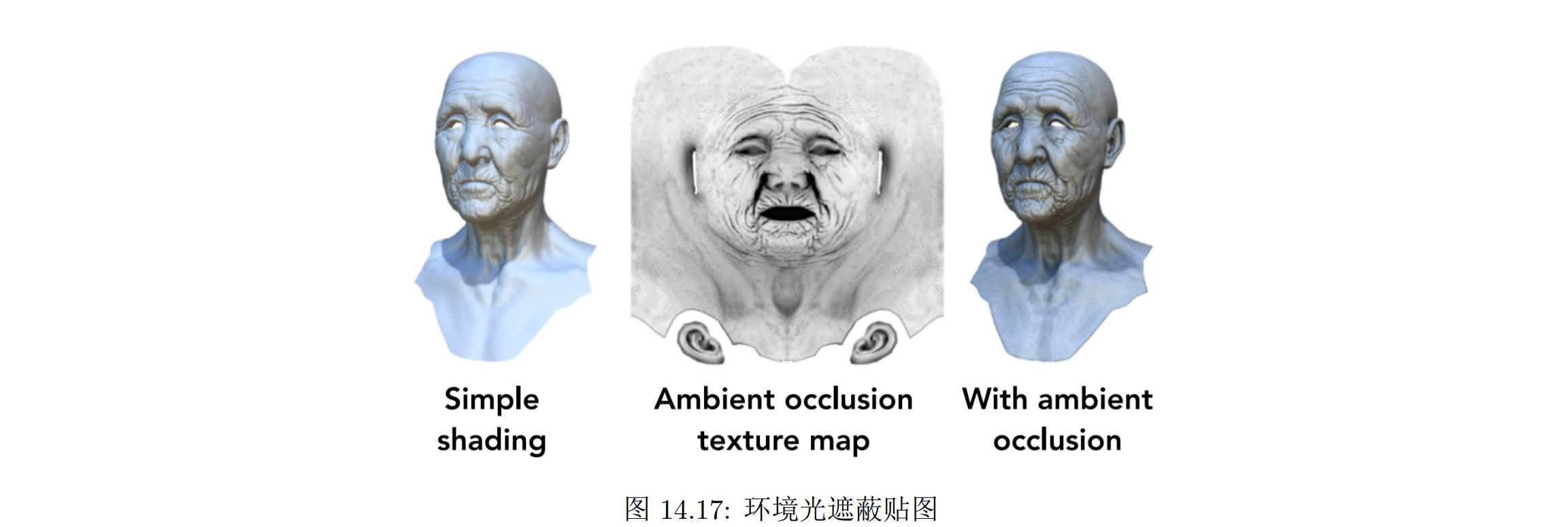
因此,我们可以预计算物体上的光影信息,然后保存到一张贴图中,称为环境光遮蔽贴图(Ambient Occlusion Mapping)
环境光遮蔽贴图能够使几何体上的明暗质感更加突出,同时实时开销低
程序贴图
程序贴图(Procedure Texture)并不是一种纹理的应用,而是一种生成纹理的方法
为了使得有重复性的纹理边界连续,我们需要为纹理指定周期性边界条件,这时使用程序生成的方式会更方便
程序贴图往往利用计算机生成的伪随机数产生的噪声,加上周期性边界条件,生成可重复的贴图
希望贴图有更真实的效果,也可以采用计算机生成 + 手工制作细节的方法生成高质量的重复纹理

阴影贴图
当一束平行光照射下来,如果光线被其他物体阻挡,我们就不能得到平行光的直接照射
阴影贴图(Shadow Mapping)是一种快速计算光线遮挡的方式:对于一个平行光源,我们可以在光源的位置(在所有物体的包围盒之外的任意一个位置)假想存在一个相机,对整个场景拍摄了一张照片,所有被看到的地方也就是光线能够到达的地方,所有看不到的地方都处在光源的阴影里
可以把这张照片的深度图作为纹理图片记录下来,然后在后面的着色中,如果发现着色点到光源的距离大于深度图上对应点的距离,我们就可以认为该点处在阴影中
在实现细节上,每个光源都需要计算一个深度贴图,平行光源应该使用正交投影,点光源应该使用透视投影


