AI中的编程 Parallel Communication
GPU Hardware
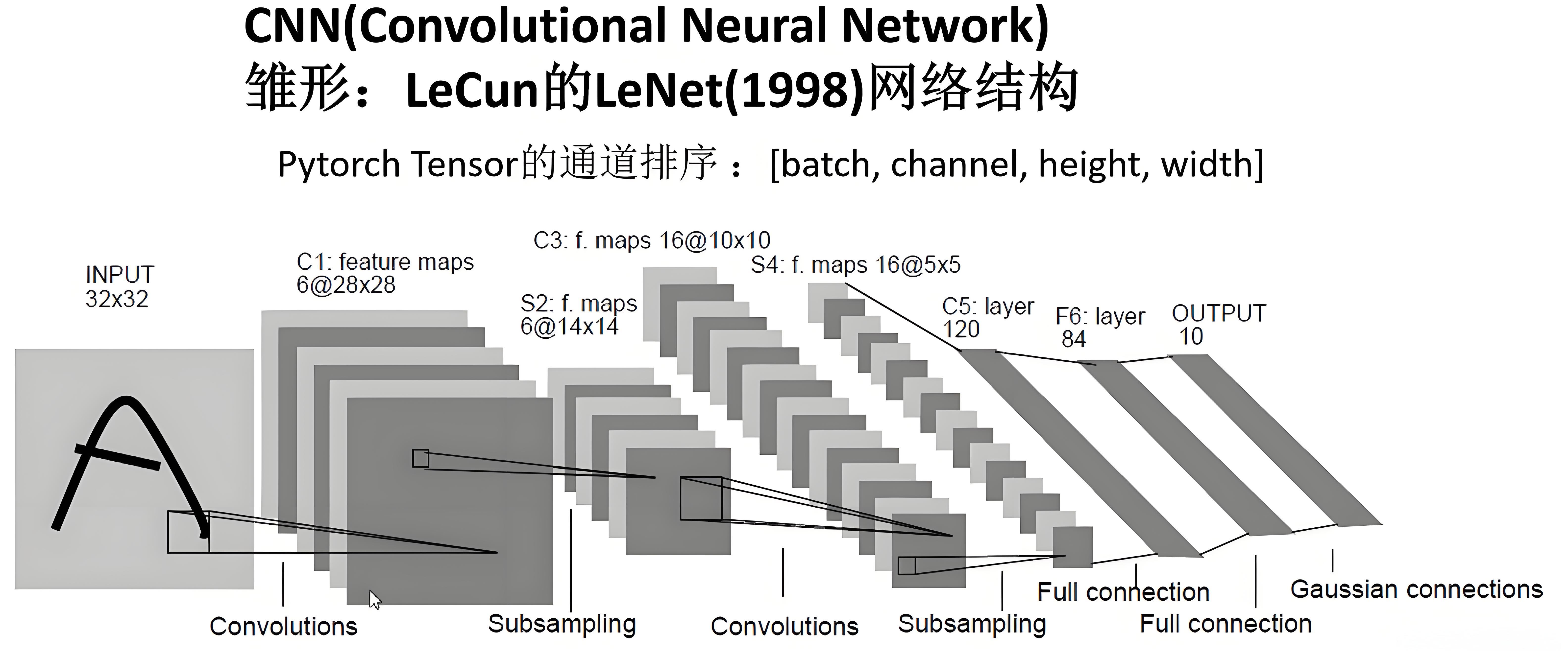
Thread Blocks And GPU Hardware
一个thread对应GPU核,tread block对应SM(Streaming Multiprocessor),而一个grid对应若干个SM
A thread block contains many threads
A thread block must be on one SM; a SM may run more than one block
The programmer is responsible for defining blocks
The GPU is responsible for allocating thread blocks to hardware SMs
The threads run in parallel, and CUDA makes few guarantees about when and where thread blocks will run.thread block间的运行是并行的,无约束的
A Thread-Block Programming Example
1 |
|
如果不加cudaDeviceSynchronize();CPU发出指令后,直接向后执行”That’s all”后主程序退出,不会等GPU执行完
执行顺序不一定,先执行完的先输出,所以一共有16!种结果
1 |
|
得到的结果每组(wrap)线程执行顺序不同而组内的每个县城都执行相同的代码,基本同事执行完成
可以认为treads,threads block,warp间是并行的
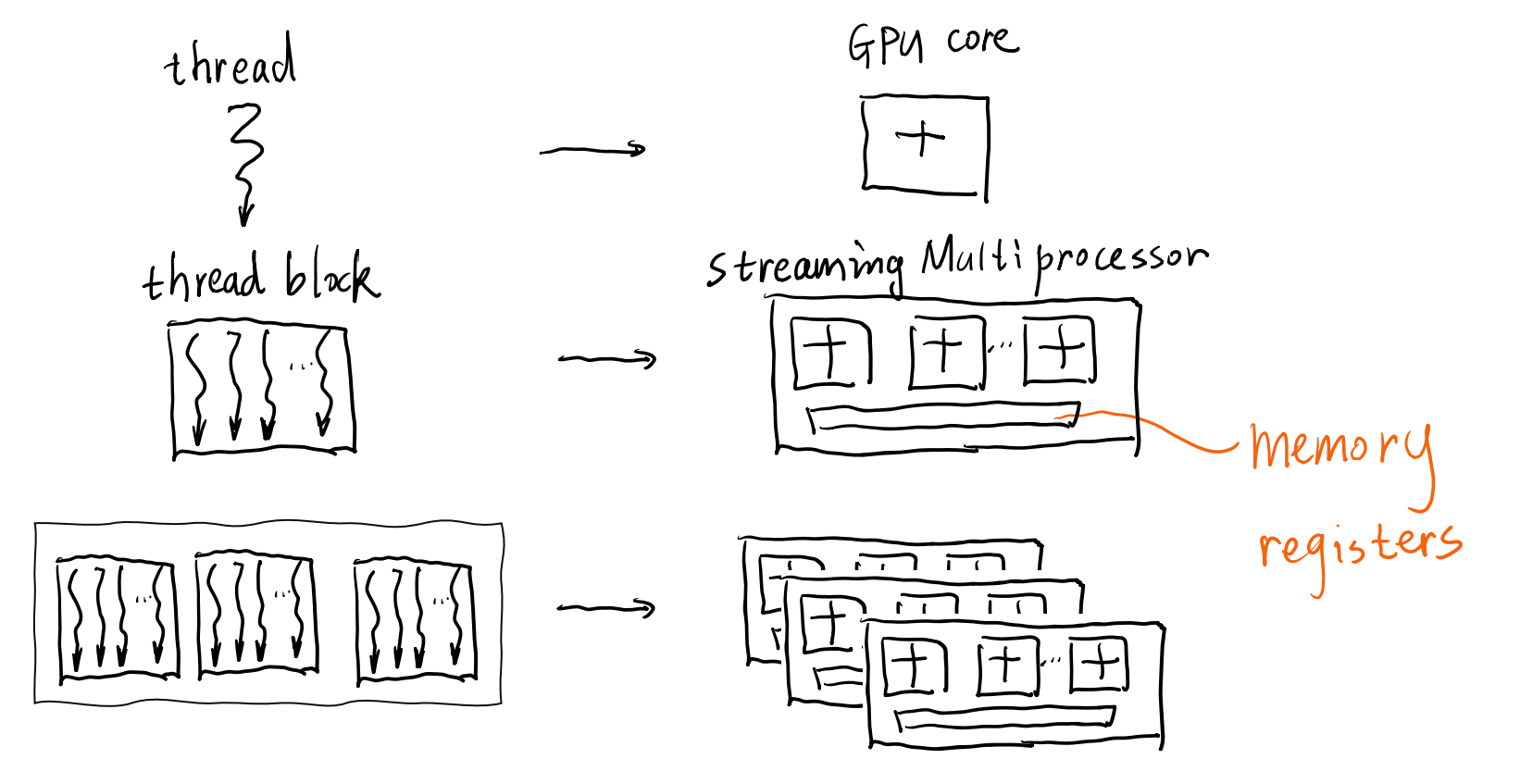
What does CUDA guarantee
CUDA makes few guarantees about when and where thread blocks will run and different blocks / threads run in parallel
All threads in a block run on the same SM at the same time
All blocks in a kernel finish before any blocks from the next kernel run
SIMT: Single-Instruction, Multiple-Thread
The multiprocessor of GPU creates, manages, schedules, and executes threads in groups of 32 parallel threads, called warps
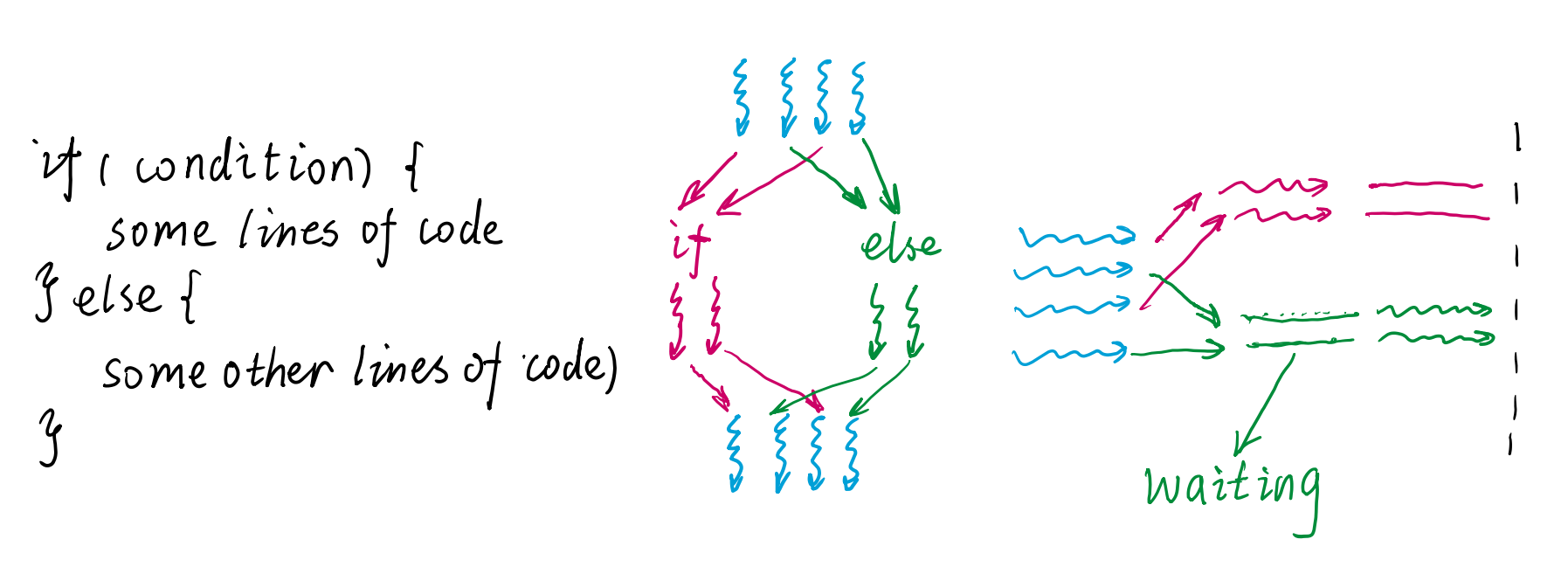
A warp executes one common instruction at a time, so full efficiency is realized when all 32 threads of a warp agree on their execution path
If threads of a warp diverge(分歧) via a data-dependent conditional branch, the warp executes each branch path taken, disabling threads that are not on that path. Branch divergence occurs only within a warp; different warps execute independently regardless of whether they are executing common or disjoint code paths
Thread Divergence
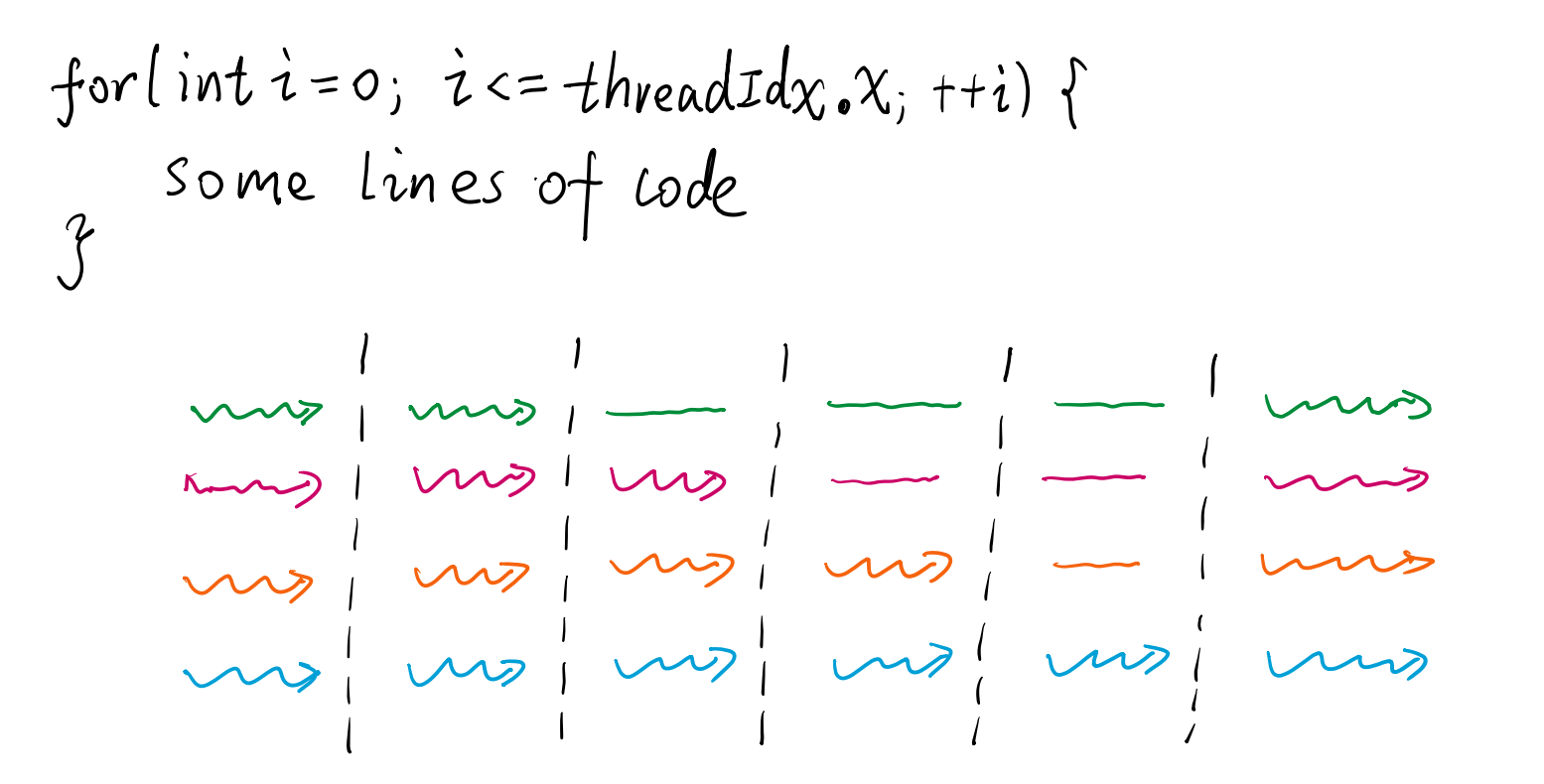
- 并行编程:尽量减少逻辑判断和for循环语句
Synchronization and Parallel Patterns
Synchronization and Parallel Patterns
Threads can access each others’ results through global and shared memory
多个线程一起写(修改)的时候必须加同步
warning:
- A thread reads a result before another thread writes
- Multiple threads writes into the same memory location (e.g., sum)
Threads need to synchronize to collaborate
Barrier: A point in the program where threads stop and wait until all threads have reached the barrier; then threads proceed
Use Barriers to Avoid Data Races
- 多个线程一起写,可能某一个线程修改完后面的线程才读入
1 | const int N = 128; |
- Barrier解决竞争:
1 | __global__ void shift_sum(float* array) |
- Use shared memory to reduce the visits of global memory
1 | __global__ void shift_sum(float* array) |
Another Example on Thread Collaboration
- Lots of threads reading and writing same memory locations,For example, 10k threads increment 10 array element
1 | const int kNumThreads = 1000000; |
线程多,空间小,反复写,__syncthreads();失效
have to use atomicAdd()
1 | const int kNumThreads = 1000000; |
Atomic Memory Operations
原子操作:一次只能有一个thread对内存进行修改
Atomic memory operations: perform read-modify-write operations on a memory location in a thread-safe manner
atomicCAS: compare and swap,We can construct general atomic operations with atomicCAS
Limitations of Atomic Memory Operations:
- The results are not fully reproducible(结果可能有偏差,代码不可复现,有波动)
- Greatly slow down the program
Measure Speed
Measure Speed On CPU
- 不能用CUDA kernel function来测量CPU时间,因为CPU、GPU执行是异步的
1 | // A naïve method for measure time on CPU |
Measure Speed On GPU
- use cuda event APIs & C++ to implement a class to simplify its usage
1 | // Measure time on GPU |
PyTorch Wrapper around the CUDA Even
1 | import torch |
Communication Patterns
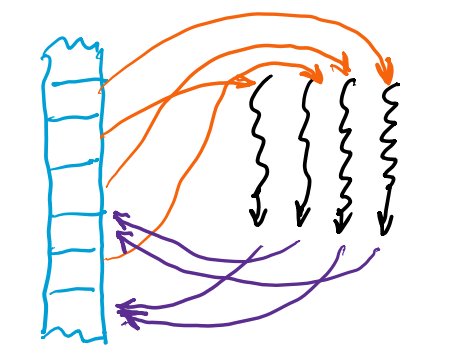
Map: One-to-One
- Read from and write to specific memory locations,读完后一一映射e.g.激活函数
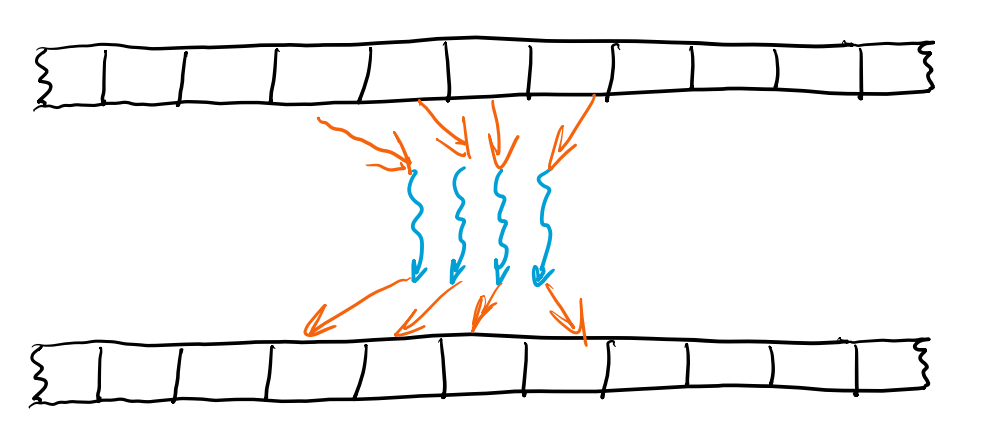
Gather: Many-to-One
- 读-写:多对一,e.g.卷积是二维Gather(图二)
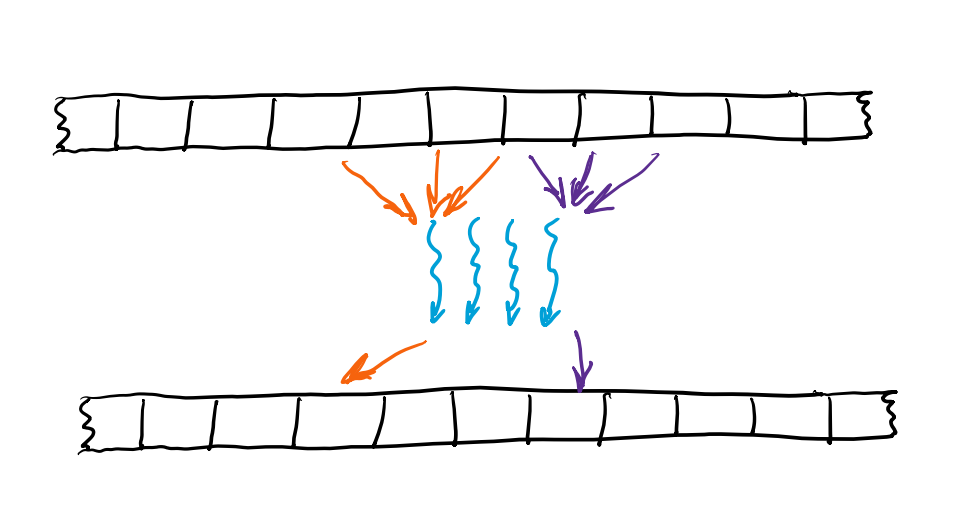

Scatter: One-to-Many
- Scatter is the reverse of Gather,与Gather常常配对出现
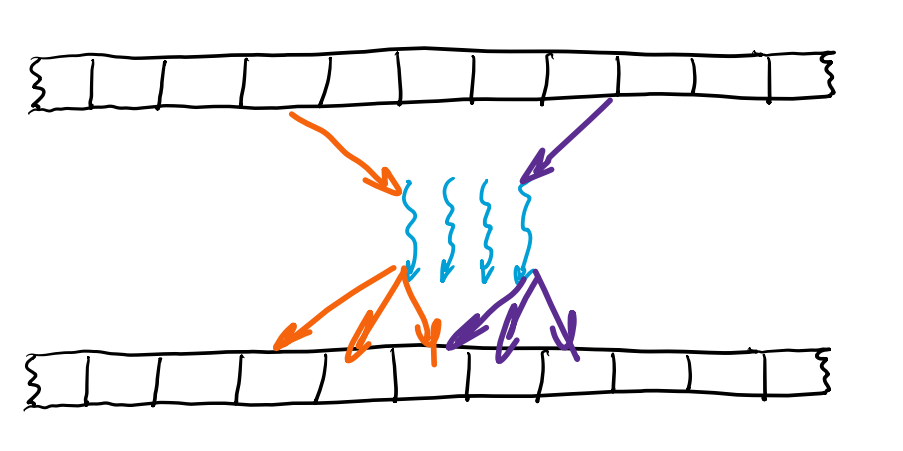
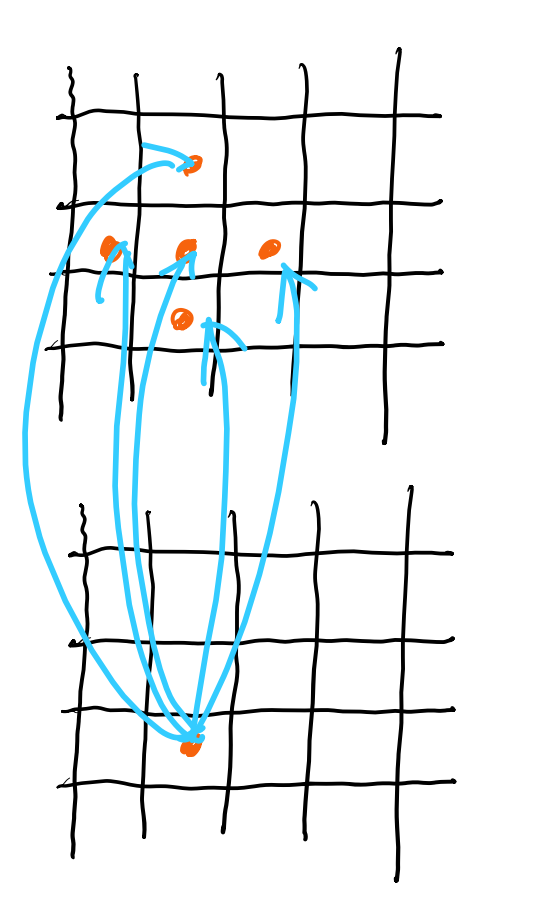
Stencil
Read input from a fixed neighborhood in an array
Stencil is a special kind of gather
The backward pass of stencil is a special kind of scatter
Transpose
- 转置:一种特殊的map,也是一一映射
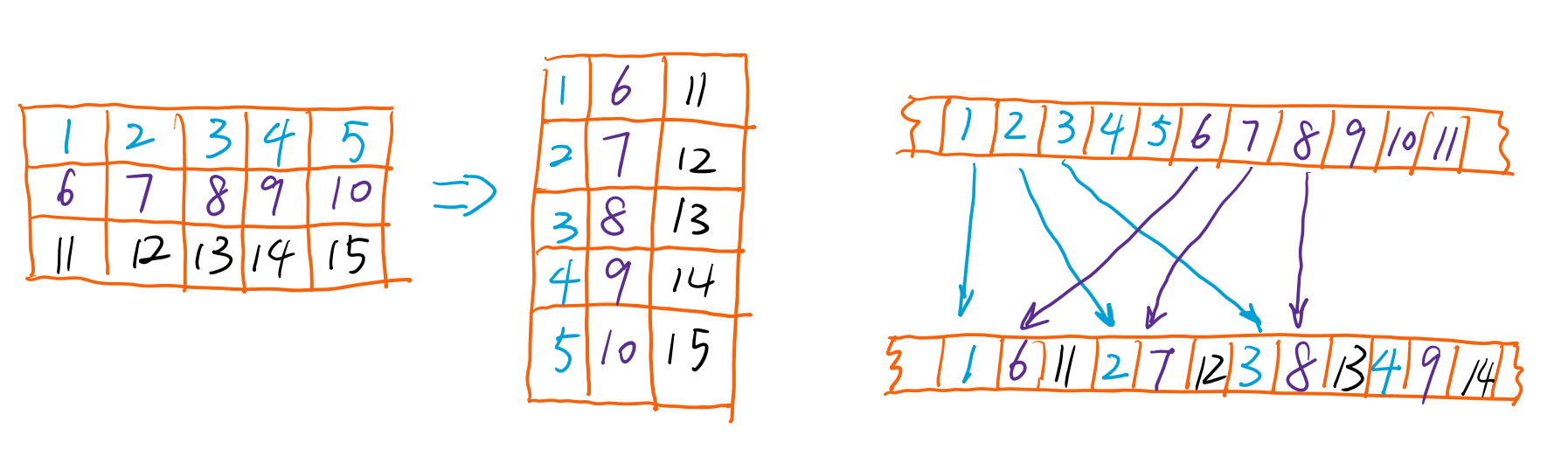
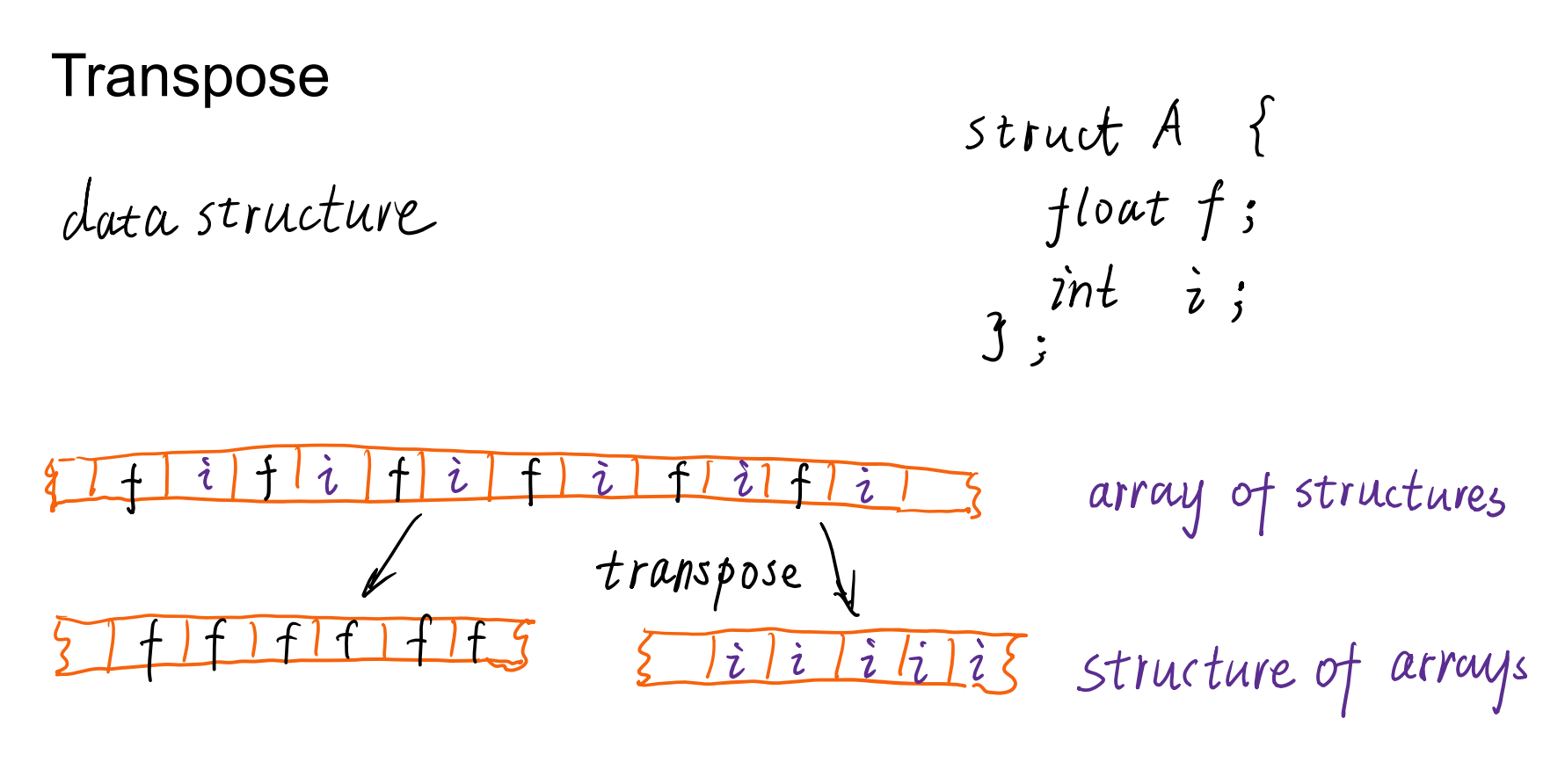
- 可以将四维tensor:N*(HWC)变成N*(CHW)