AI中的编程 Parallel Programming
并行编程的介绍 :
CPU vs GPU :
CPU: Complex control circuit
- good:Flexibility + Performance
- bad:Expensive in terms of power
GPU: Simple control circuit
- good:More circuit for parallel computation
- good:More power efficient
- bad:Less flexibility, more restrictive programming models
The CPU is Optimized for Latency,The GPU is Optimized for Throughput
CUDA is Written in C with Extensions :
The CUDA complier complies a CUDA program into two parts, which runs on CPUs and GPUs
- step1:Data:cpu->gpu
- step2:Data:gpu->spu
- step3:cudaMalloc(分配内存空间用于储存和计算)
- step4:Launch kernels on GPUs
CPU称为内存而GPU称为显存
A Typical CUDA Program :
CPU和GPU是异步的
What CPU does
- CPU allocates a block of memory on GPU–cudaMalloc
- CPU copies data from CPU to GPU–cudaMemcpy
- CPU initiates launching kernels on GPU–Launchkernels<<<>>>
- CPU copies results back from GPU to CPU–cudaMemcpy
What GPU does
- GPU efficiently launch a lot of kernels(kernels之间是并行运算的而内部是顺序计算的)
- GPU runs kernels in parallel
- A kernel looks like a serial C program for a thread
- The GPU will run the kernel for many threads in parallel
第一个CUDA程序 :
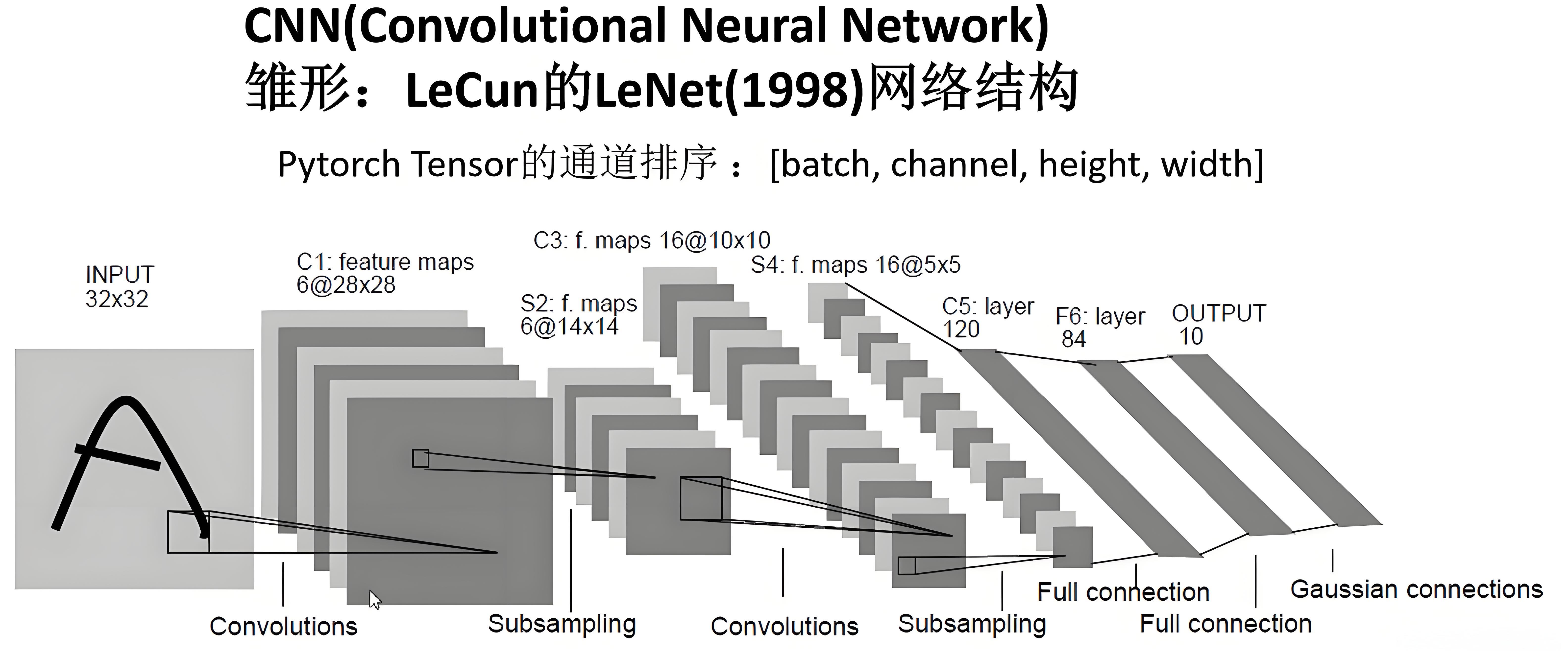
Review: Implement LeNet
1 | class LeNet(torch.nn.Module): |
The first CUDA program
- Let’s implement torch.nn.functional.relu
1
2
3
4
5
6
7
8
9//ReLU on CPU
float relu_cpu(float x)
{
return x > 0 ? x : 0;
}
for (int i = 0; i < N; ++i)
{
h_out[i] = relu_cpu(h_in[i]);//cpu的指针用h_开头(host)
}
1 | //ReLU on GPU. Define a kernel with "__ global __"; Launch kernels with <<<, >>> |
1 | const int N = 64; |
Configure the Kernel Launch
GPU由一些grid组成,其中grid是根据实际情况由系统自动分配的
grid中有很多block,block中又有很多thread,其中block和thread由代码分配
Kernel <<< number of blocks, number of thread per block >>> (…)
Launch many blocks at once
Maximum number of threads per block(256/512/1024(少))
number of blocks, number of thread per block可以是多维的。relu_gpu<<<1, N>>>(…) → relu_gpu <<< dim3(1, 1, 1), dim3(N, 1, 1) >>> (…)
1
2// How many threads in total ?
relu_gpu<<<dim3(4, 6, 8), dim3(16, 16)>>>(d_in, d_out);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49__global__ void relu_gpu(float* in, float* out)
{
int i = threadIdx.x;
out[i] = in[i] > 0 ? in[i] : 0;
}
int i = threadIdx.x;
int j = threadIdx.y;
int m = blockIdx.x
int n = blockIdx.y
int w = blockDim.x // use w
int k = gridDim.x // use k
// Use 512 or 256 threads per block
const int kCudaThreadsNum = 512;
inline int CudaGetBlocks(const int N)
{
return (N + kCudaThreadsNum - 1) / kCudaThreadsNum;
}
//上述代码一般直接用于程序
// Define the grid stride looping
// 宏定义,用于在CUDA的内核中进行并行循环
// i 是循环变量,n 表示输入数组的长度,或者说需要处理的元素总数。
// 该循环的结构将确保线程正确地分配计算任务
// blockIdx.x 表示当前block的索引
//blockDim.x 表示每个block中线程的数量,threadIdx.x 表示当前线程在block中的索引
// 通过这些索引和数量信息计算出线程全局唯一的ID
// 定义CUDA核函数,用于在GPU上执行ReLU操作
// __global__ 关键字表示这是一个GPU核函数,可以在GPU上并行执行
// 参数 in 是输入数组,out 是输出数组,n 是数组的长度
// 每个线程将会处理数组中的一部分数据
__global__ void relu_gpu(float* in, float* out, int n)
{
// CUDA_KERNEL_LOOP 使用上面定义的宏进行并行循环。
// 每个线程将通过 CUDA_KERNEL_LOOP 负责处理数组中的不同元素。
CUDA_KERNEL_LOOP(i, n)
{
out[i] = in[i] > 0 ? in[i] : 0;
}
}
// 启动 relu_gpu 核函数
// <<<CudaGetBlocks(N), kCudaThreadsNum>>>用来指定核函数的执行配置
// CudaGetBlocks(N) 返回启动的block数目,kCudaThreadsNum 是每个block中线程的数量
// d_in 是设备上的输入数组,d_out 是设备上的输出数组,N 是数组长度
// 通过这个启动配置,每个线程将负责处理 d_in 和 d_out 中的一部分数据,实现并行化
relu_gpu <<<CudaGetBlocks(N), kCudaThreadsNum>>> (d_in, d_out, N);
GPU Memory and Hardware :
implement a class Tensorto circumvent this issue
1 | // allocate memory in the constructor |
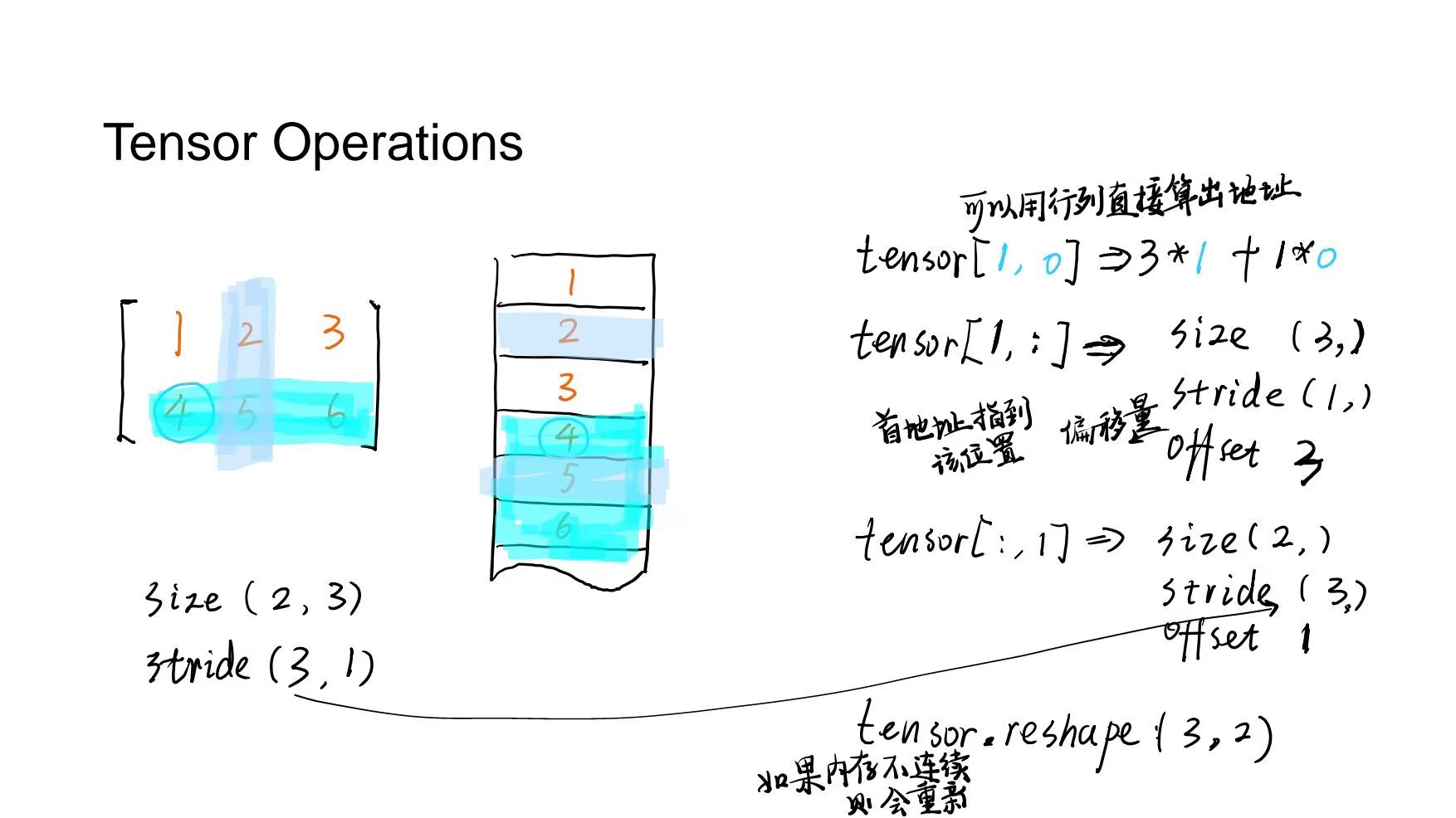
Tensor Operations
-Tensor常见的参数包括:
1. size:(C,H,W)
2. strides(每一个维度的步长,内存+1要走多少步):(H*W,W,1)
3. dtype:float
4. device:cuda:0?cpu?
5. offset(偏移量,首地址指到该位置要走多少步)
GPU Memory Model
访问速度:local>shared>>global>>cpumemory
包含线程的大小:cpumemory>global>shared>local
Define the shared memory by the keyword __ shared __
Highlight: We can fetch data into the shared memory for data reuse to reduce the visit of global memory.
1
2
3
4
5
6
7
8
9
10
11
12__global__ foo(float* x, float* y)
{
int i = threadIdx.x; // local memory
float s, t; // local memory
__shared__ float s[128]; // shared memory
__shared__ float a, b, c; // shared memory
// which of the following is the fastest?
t = *x;
b = a;
s[i] = t; //local复制shared,最快
*y = *x;
}
Highlight: Coalesced Global Memory Access
- The CUDA program is efficient when threads read /write contiguous memory locations
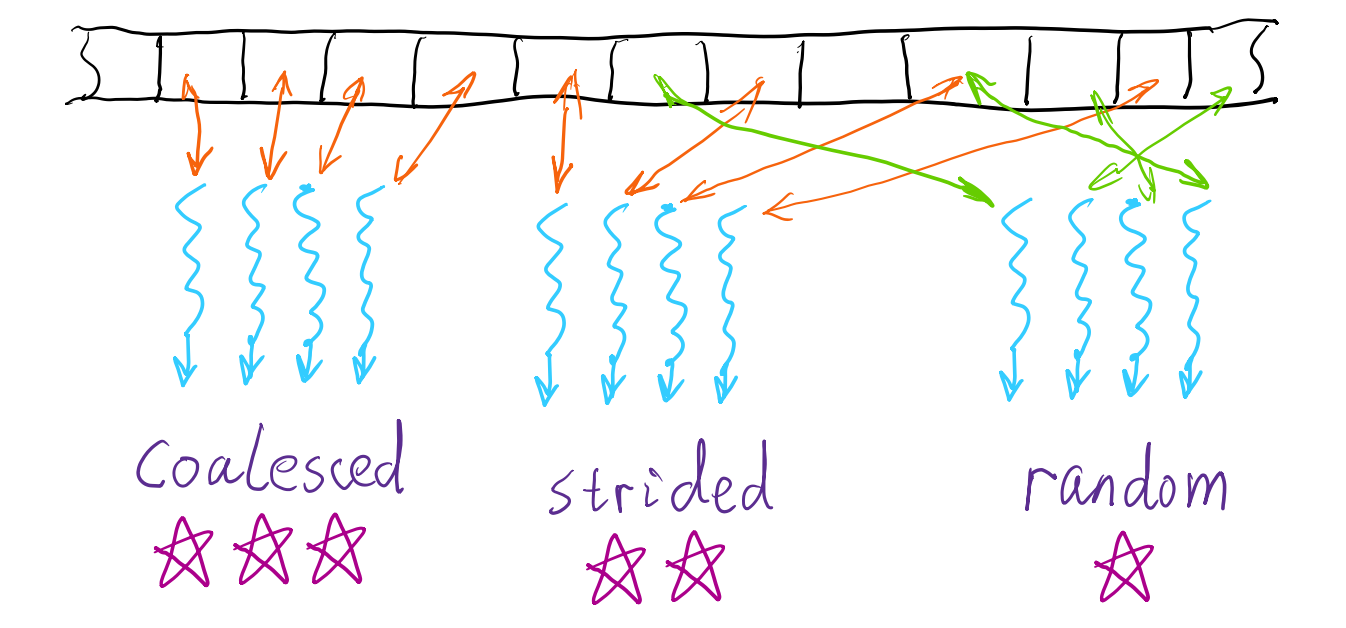
Highlight: Coalesced Global Memory Access
- The CUDA program is efficient when threads read / write contiguous memory locations
1
2
3
4
5
6
7
8__global__ foo(float* x) {
int i = threadIdx.x; // local memory
float s, t; // local memory
// which of the following is coalesced?
t = x[i]; //是coalesced
x[i*2] = t; //是strides
x[i+1] = s; //是coalesced
}