
数据结构与算法A 第六章树
树的定义和基本术语
树和森林
定义:树 (tree) 是包括 n 个结点的有限集合 T(n ≥ 1):
- 有且仅有一个特定的结点,称为根(root)
- 除根以外的其他结点被分成 m 个 (m ≥ 0) 不相交的有限集合 T1,T2,…,Tm,而每一个集合又都是树,称为 T 的子树 (subtree)
树的逻辑结构:树是一个包含n个结点的有穷集合K,满足二元关系R={r}
- 有且仅有一个结点 k0∈K,它对于关系 r 来说没有前驱。结点 k0 称作树的根
- 除结点 k0 外,K中的每个结点对于关系 r 来说都有且仅有一个前驱
- 除结点k0外的任何结点k,都存在一个结点序列k0,k1,…,ks,使得k0就是树根,ks=k,其中有序对<ki-1,ki>。这样的节点序列称为从根k0到结点k的一条路径
• 例如
– 结点集合 K={ A,B,C,D,E,F,G,H,I,J }
– K 上的关系 r = { <A,B>,<A,C>,<B,D>,<B,E>,<B,F>,<C,G>,<C,H>,<E,I>,<E,J> }
根据次序分类:
- 无序树:子结点的次序没有必要加以区别
- 有序树:往往把子结点从左到右的次序顺序编号
- 度为2的有序树并不是二叉树
定义:森林(forest)是零棵或多棵不相交的树的集合(通常是有序)
树形结构的各种表示法:
- 树形表示法
- 凹入表示法
- 文氏图表示法
- 嵌套括号表示法
森林和二叉树的等价转换
树与二叉树、森林与二叉树之间可以相互转换,而且这种转换是一一对应的
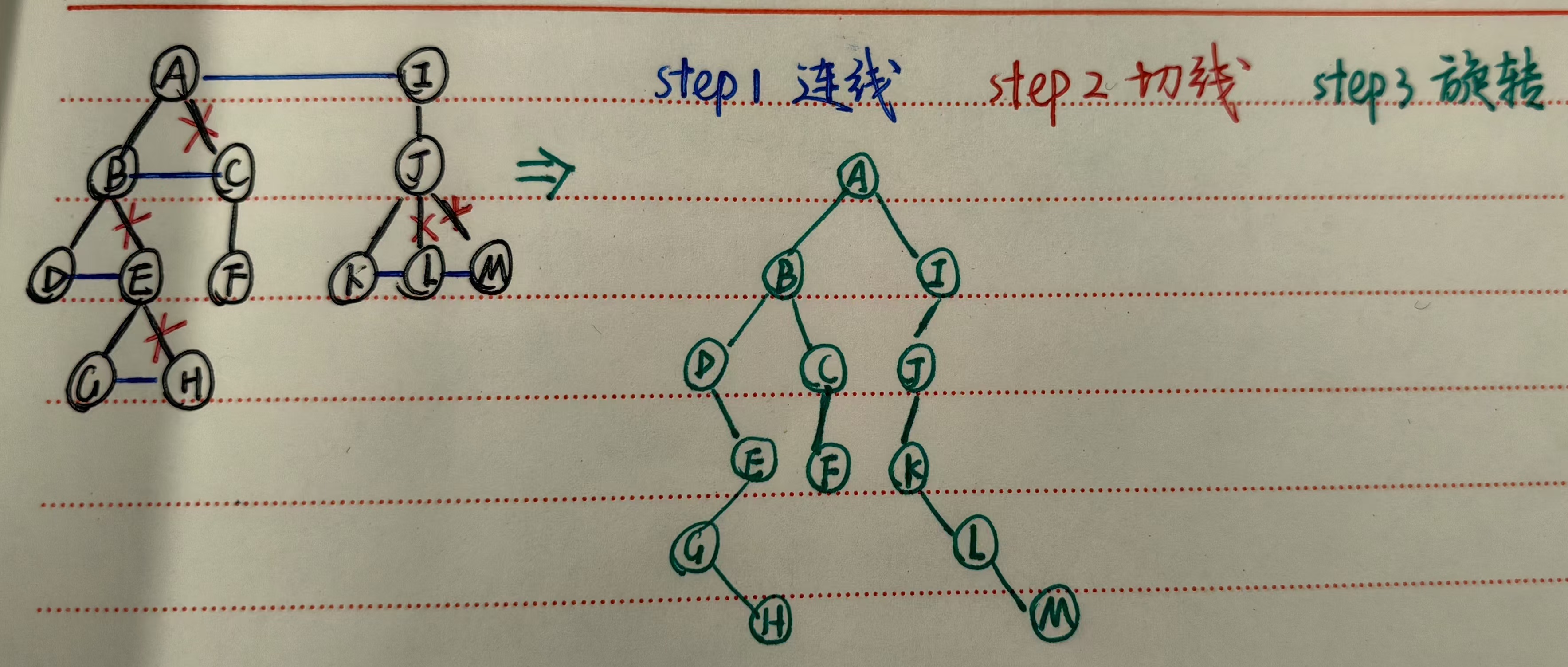
树和森林到二叉树的转换过程:
- 连线:将兄弟结点用线连接起来(同父亲兄弟)
- 切线:保留父结点与其第一个子结点的连线,将父结点到其他子结点的连线切掉
- 旋转:以根为轴,平面向下顺时针方向旋转一定的角度
森林F转换成二叉树B(F)的递归定义:
- 若 F 为空,即 n = 0,则 B(F) 为空
- 若 F 非空,即 n > 0,则 B(F) 的根是森林中第一棵树 T1 的根 W1,B(F) 的左子树是树 T1 中根结点 W1的子树森林 F = {T11,…,T1m} 转换成的二叉树B(T11,…,T1m);B(F)的右子树是从森林 F’ = {T2,…,Tn} 转换而成的二叉树
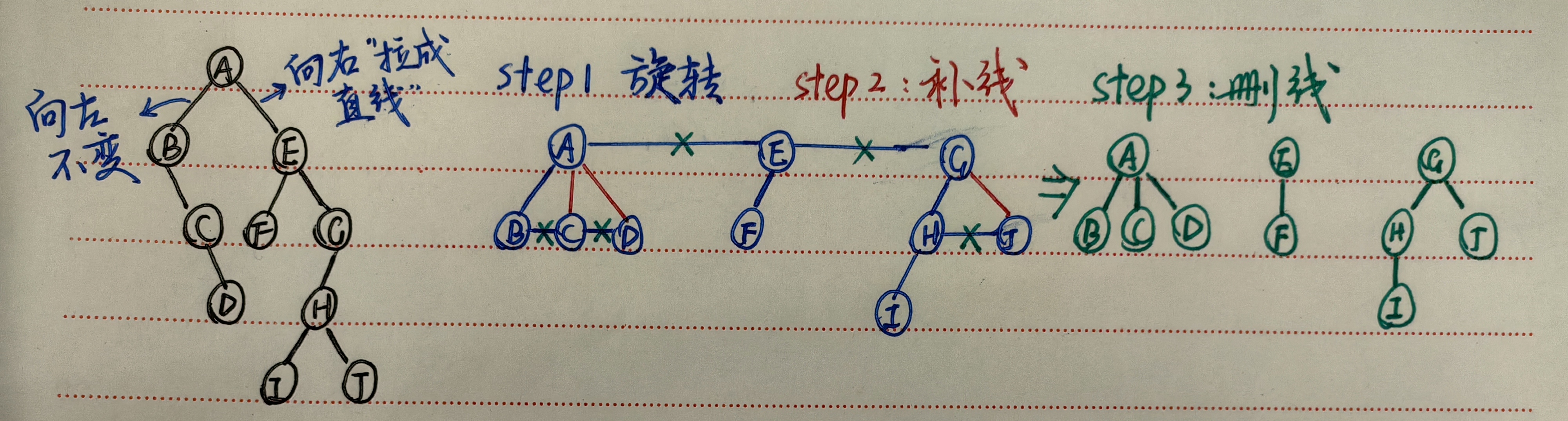
二叉树转换为树或森林过程:
- 旋转:以根为轴,平面逆时针方向旋转
- 补线:若结点x是父结点y的左子结点,则把x的右子结点、右子结点的右子结点以此类推,用连线与y连起来
- 删线:去掉所有父结点到原右子结点的连线
设B是一棵二叉树,root是 B 的根,BL 是 root 的左子树,BR 是 root 的右子树,则对应于二叉树B的森林或树 F(B) 的形式定义是:
- 若 B 为空,则 F(B) 是空的森林
- 若 B 不为空,则 F(B)是一棵树T1加上森林 F(BR),其中树 T1 的根为 root,root 的子树为 F(BL)
树的ADT
- 类似于二叉树,输的抽象数据类型包括结点类和树类
1 | template<class T> |
树的周游
深度优先周游树
由于一个结点可能多于两个字数,因此不能像二叉树的中序周游法那样给出树的中跟次序周游方式。而只存在前序法(先根次序周游森林)和后序法(后根次序周游森林):
- 先根次序周游森林:
- 访问森林中第一棵树的根结点
- 在先根次序下周游第一课树根结点的字数森林
- 在先根次序下周游其他树构成的森林
- 后根次序周游森林:
- 在后根次序下周游第一棵树根结点的子树森林
- 访问森林中的一个棵树的根结点
- 在后根次序下周游其他树构成的森林
- 先根次序周游森林:
先根次序周游森林的序列正好等同于其对应的二叉树的前序序列
后跟次序周游得到的排列正好是对应的二叉树在中序次序周游下的结点序列
先根深度优先遍历森林
1 | template<class T> |
- 后根深度优先遍历森林
1 | template<class T> |
广度优先周游
广度优先周游也称“宽度优先周游”或者“层次周游”:从树的第零层(根结点)开始,自上而下逐层周游,在同一层中则按照从左到右的顺序对结点注意访问
森林的层次序列和对应的二叉树的层次序列不同
广度优先遍历森林
1 | template<class T> |
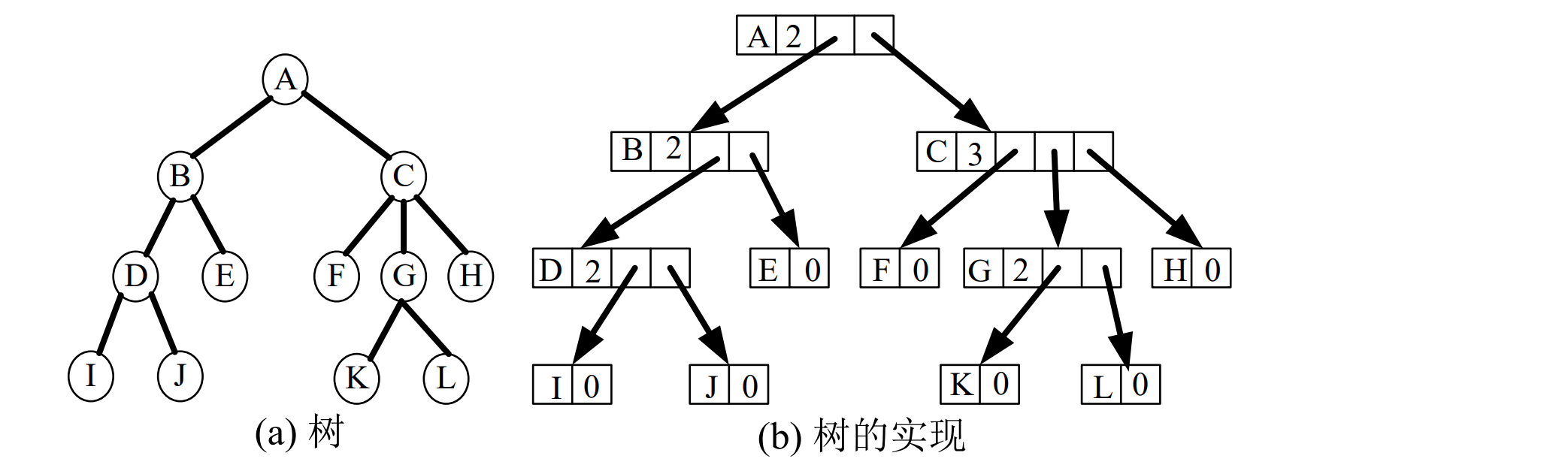
树的链式存储结构
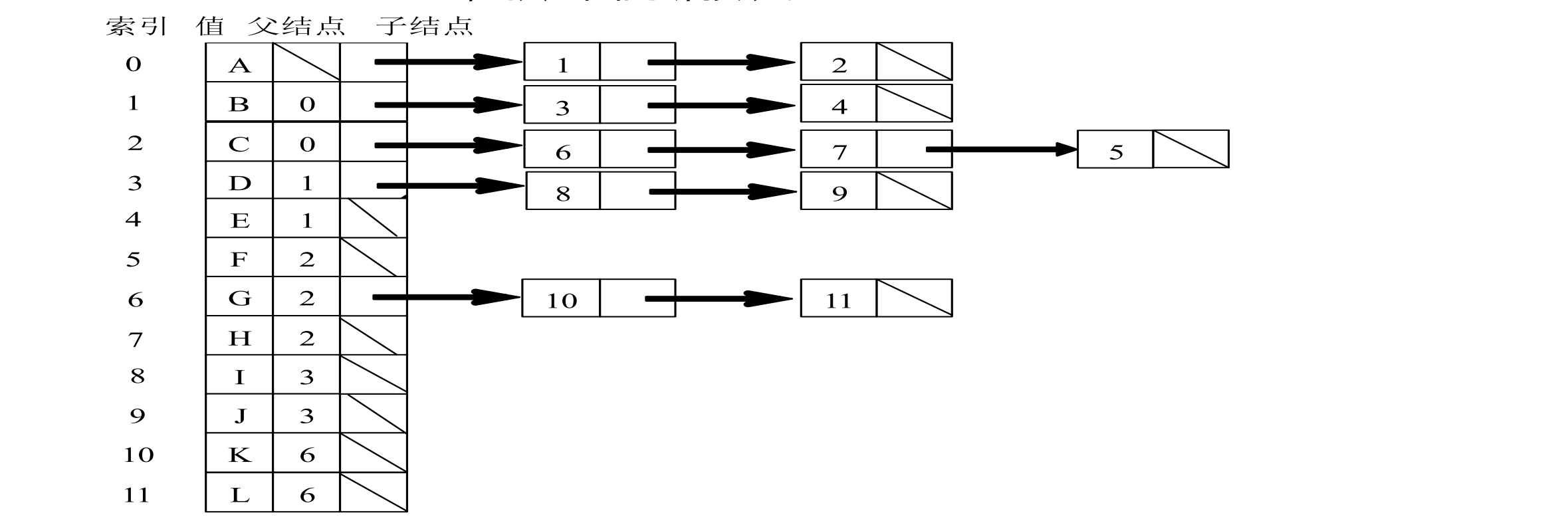
“子结点表”表示方法
“子结点表”表示方法:每个分支结点按照从左至右的顺序形成一个链表存储在改分支结点中,主体是存储了树中各结点信息的数组
3个域:分别用来存放结点信息的值、父结点指针、指向其子结点表的指针
索引从0开始,链表中子结点的顺序由左至右。最左子结点可由子结点链表的第一个表项直接找到,顺链可得所有子结点
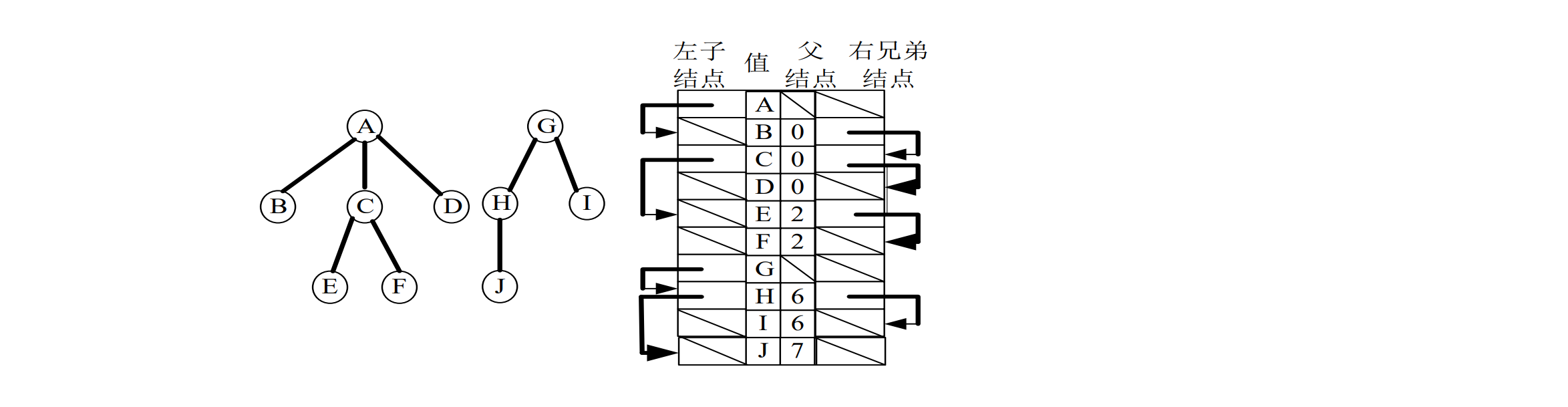
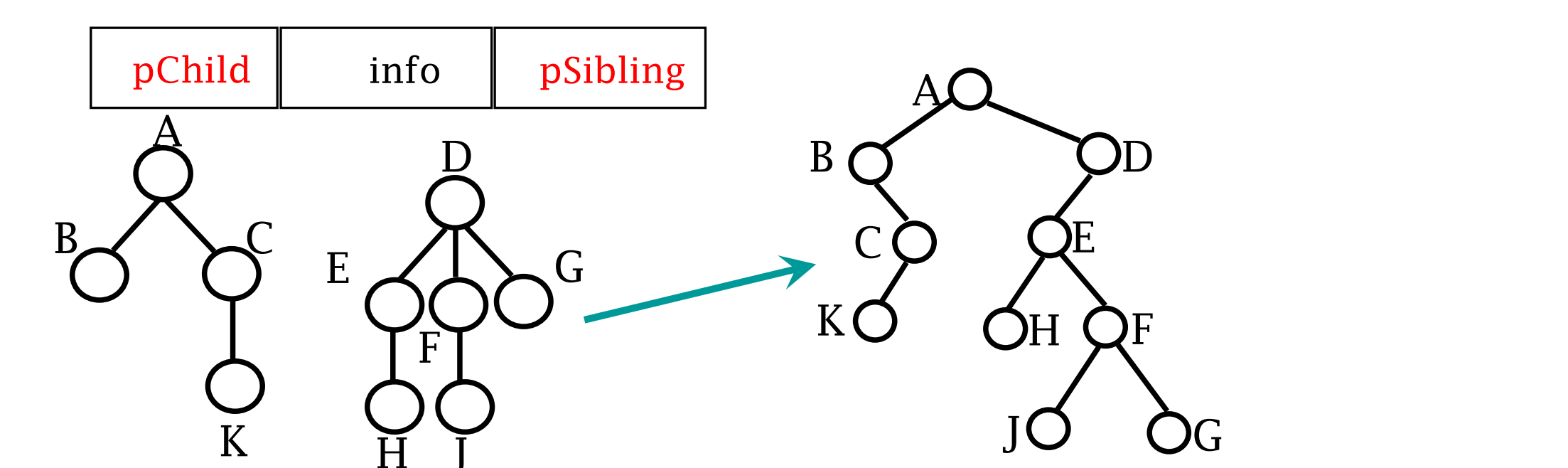
静态“左子/右兄”表示法
4个域:分别用来存储结点的值、指向其父结点指针、指向最左子结点指针、指向右侧兄弟结点的指针
比“子结点表”表示法空间效率更高,而且每个结点的存储空间大小固定
动态表示法
为每个结点分配可变的存储空间,每一个结点都存储一个子结点指针表,子结点的数目也存储在结点中
本质上域“子结点表”表示法相同,但是可以动态的分配结点空间,而不是把所有结点都分配在一个数组中
动态“左子/右兄”二叉链表表示法
- 左子结点在树中是结点的最左子结点,右子结点是结点原来的右侧兄弟结点,根的右链就是森林中每棵树的根结点
1 | // 在TreeNode的抽象类中增加以下私有数据成员 |
父指针表示法和在并查集中的应用
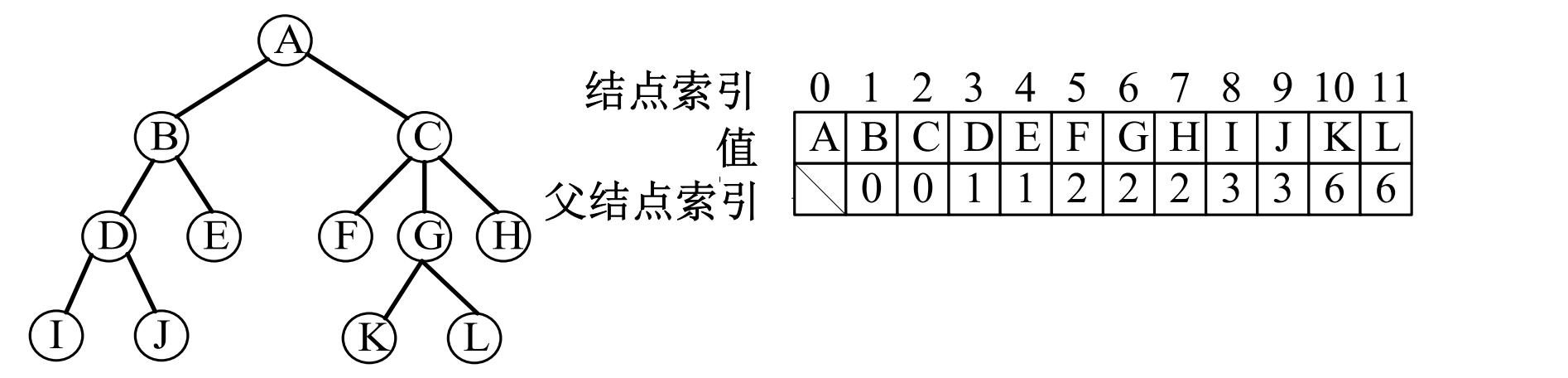
父指针表示法
用数组存储树结点,同时在每个结点中附设一个指针指示其父结点的位置
寻找一个结点的父结点只需要O(1)
父指针表示法适合于无序树的情况而且只适合于查询结点的根和合并树等操作
等价类和并查集
并查集是一种特殊的集合,由一些不相交子集构成。基本操作是:
- find:判断两个结点是否在同一个集合中
- union:归并两个集合
并查集也是一种重要的抽象数据类型,可以用于求解等价类问题。若关系 R 是一个 等价关系,当且仅当如下条件为真时成立:
- 自反:对于所有的x,(x,x)∈R
- 对称:当且仅当(x,y)∈R,(y,x)∈R
- 传递:若(x,y)∈R,(y,z)∈R,则有(x,z)∈R
如果(x,y)∈R,则元素x和y是等价的。等价类指相互等价的元素所组成的最大集合。即不存在类以外的元素,与类内部的元素等价
划分等价类需要对集合进行3种操作:
- 给每一个元素构造一个独立的集合
- 判定某个元素所在的子集,从而确定两个元素是否在同一个集合中。即搜索包含该元素的等价类,对于同一个集合中的元素返回相同的结果,否则返回不同的结果
- 归并两个集合为一个集合
用树来表示等价类的并查:
- 用一棵树代表一个集合:集合用父结点代替,若两个结点在同一棵树中,则它们处于同一个集合
- 树的实现:存储在静态指针数组中,结点中仅需保存父指针信息
查找所需要的时间由树的高度所决定,合并所需要的时间是O(1)
为了防止树退化为单链,应该让每个结点到其相应根结点的距离尽可能小,改进方式:
- “重量权衡合并原则”:合并操作根据子集中包含的元素的数目,令含有元素少的子集的树根指向含元素多的子集的根。整体深度限制在O(logn),find操作只需要O(logn)
- 路径压缩技术:执行find时,把结点到树根的路径上所有结点的父指针都指向根结点。设X最终到达根R,顺着由X到R的路径把每个结点的父指针域均设置为直接指向R
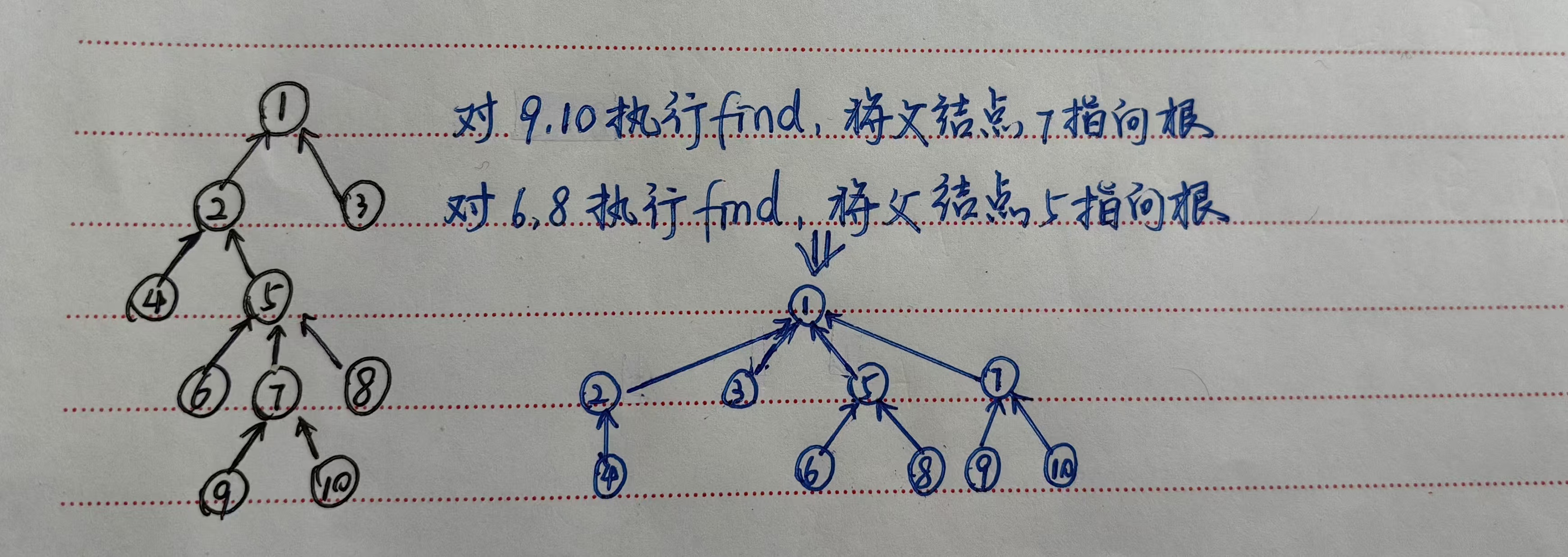
树的父指针表示与Union/Find算法实现
1 | template<class T> |
- 路径压缩
1 | template <class T> |
树的顺序存储结构
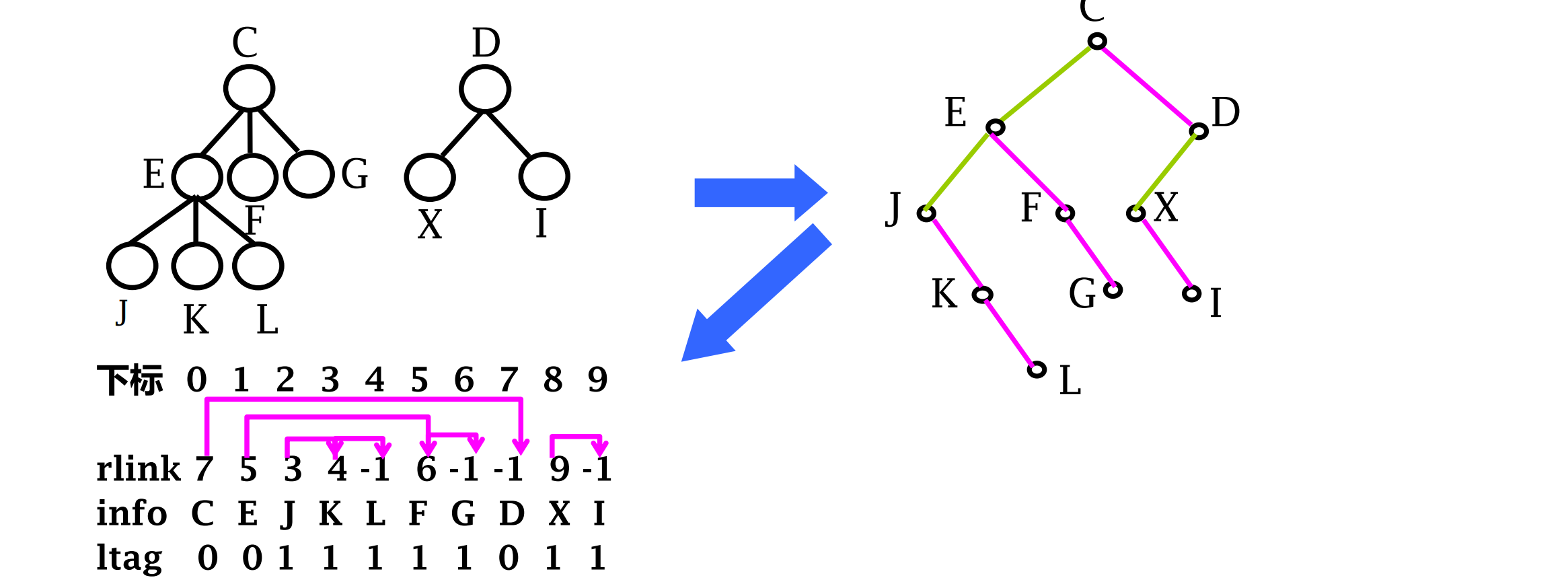
带右链的先根次序表示
3个域:每个结点包括本身数据以及两个表示结构信息的ltag和rlink域
rlink是右指针,指向结点的下一个兄弟,即树或森林所对应的二叉树中结点的右子结点。ltag是一个标记位,结点是叶结点,即对应的二叉树中没有左子结点时,ltag为1,否则为0
带双标记的先根次序表示
3个域:本身数据以及两个标记位ltag和rtag
由先根次序以及ltag、rtag两个标记位就可以确定树“左子/右兄”链表中的结点llink和rlink值
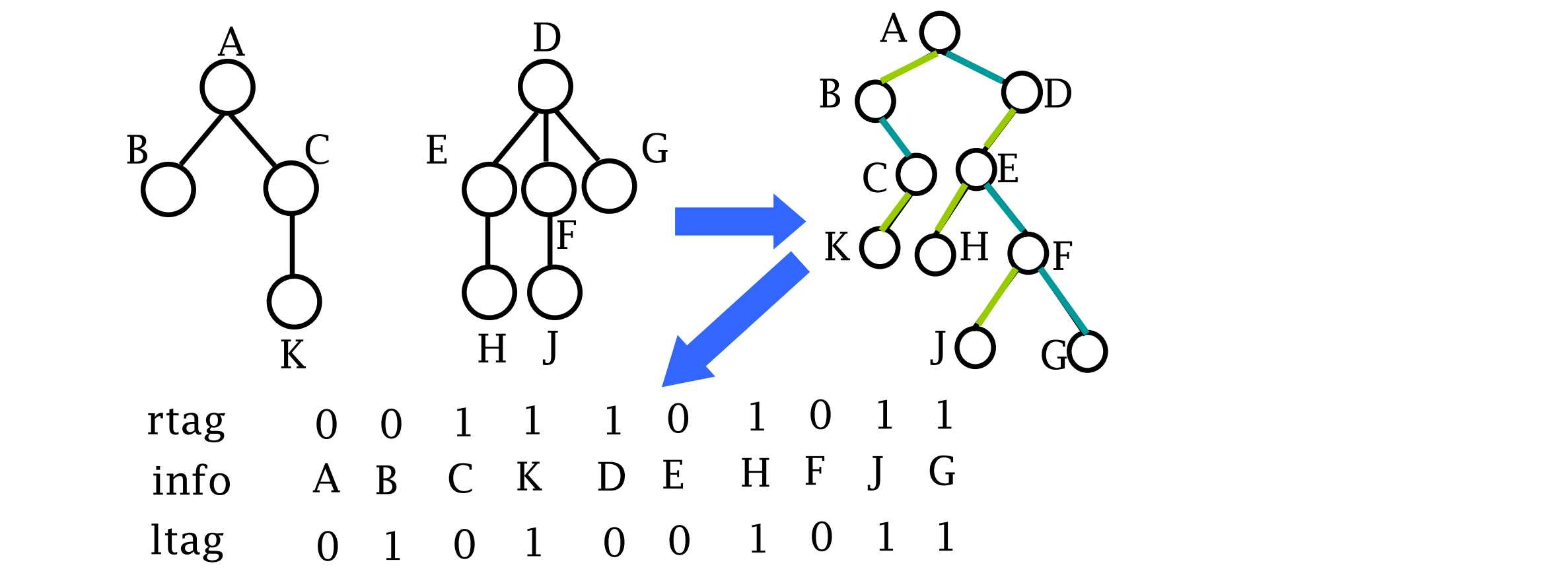
需要用到栈结构:扫描到一个rtag为0的结点就将其进栈;扫描到一个ltag为1的结点就从栈顶弹出一个结点并为其设置rlink
操作步骤:
- rtag=0就入栈,树一直往左走
- 直到碰到ltag=1,从栈顶弹出元素,并给这个元素加上右链链接下一个元素

- 带双标记位先根次序树构造算法
1 | template<class T> |
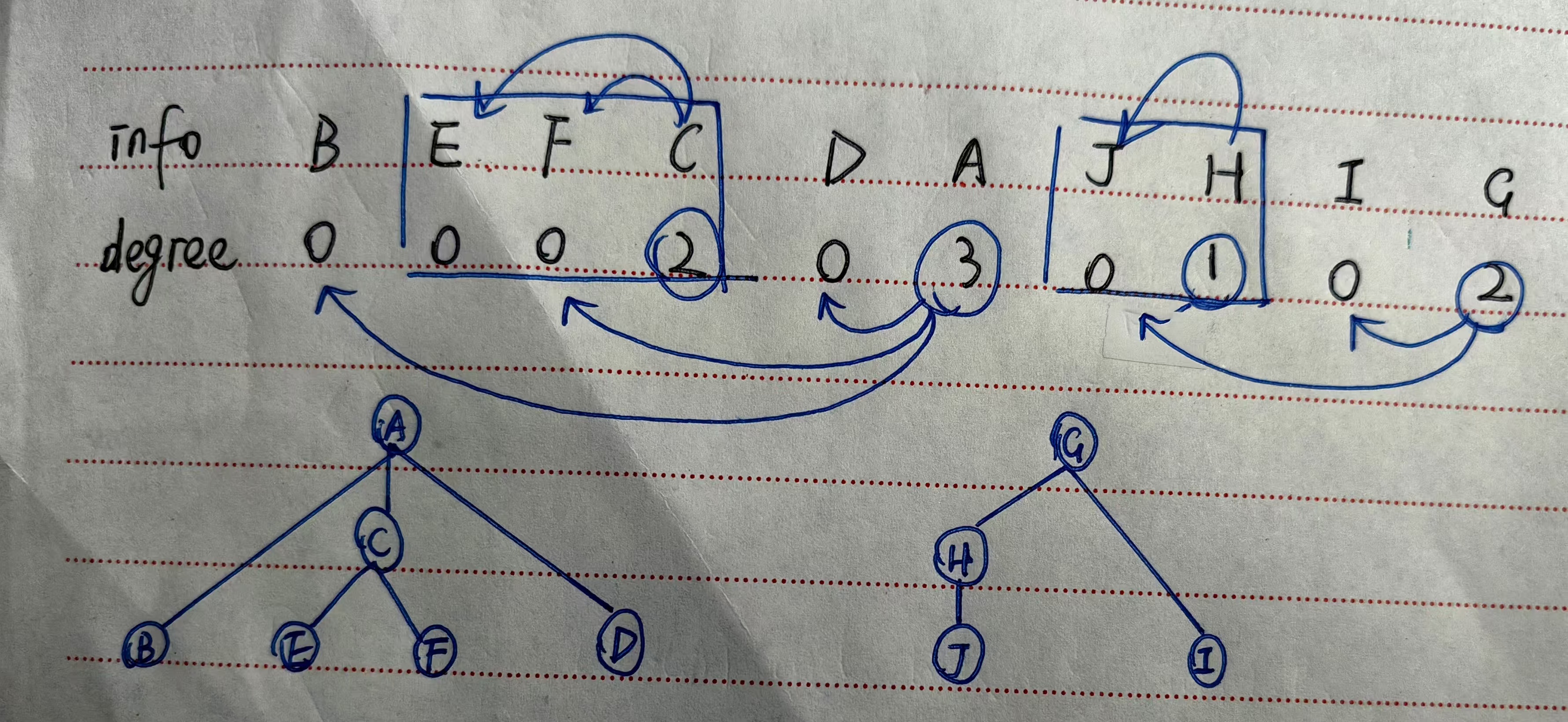
带度数的后根次序表示
2个域:info用于存放结点的数据,degree用于存放结点的度数
不包括指针,但仍能反映树的结构。带度数的后根次序表示转化成森林:
- 从从左至右扫描,度数为0的结点是叶子结点
- 遇到度数非0(k)的结点时,则排在结点之前且离他最近的k个子树的根就是该结点的k个子结点,并将其视为一个整体
带双标记的层次次序表示
3个域:info是结点的数据域;当结点没有左子结点时标记位ltag为1,否则为0;当结点没有下一个兄弟时标记位rtag为1,否则为0
需要用到队列结构:当一个结点的ltag值为0,应该将其加入队列中。遇到rtag为1的结点后,取出队列中第一个元素,将其llink指向下一个元素

K叉树
K叉树T是具有下列性质的有线结点集:
- 集合可以为空
- 非空集合是由一个根结点 root 及 K 棵互不相交的 K 叉树构成。其余结点被划分成 T0,T1,…,TK - 1(K ≥ 1)个子集,每个子集都是 K 叉树,使得T = {R, T0,T1 ,…,TK - 1}
K 叉树的各分支结点都有 K 个子结点
满K叉树和完全K叉树与满二叉树和完全二叉树是类似的
也可以把完全K叉树存储在一个数组中
第六章 树 OJ作业
1:宗教信仰
1 | /*描述 |
2:发现它,抓住它
1 | /*描述 |
3:树的转换
1 | /*描述 |

