
Yo'LLaVA:Your Personalized Language and Vision Assistant
Yo’LLaVA: Your Personalized Language and Vision Assistant
Abstract
大型多模态模型(Large Multimodal Models, LMMs)已在多种任务(如图像描述、视觉问答)中展现出卓越能力
尽管知识面广泛,但其知识仍具有通用性(例如识别一只狗),无法处理个性化主体(例如识别用户的爱犬)。相比之下,人类推理通常围绕周围环境中的特定主体展开
本文中,我们提出了个性化LMM的新任务,使其能够围绕特定主体展开对话。我们提出了Yo’LLaVA,它能够根据少量主体示例图像,学习将个性化主体嵌入到一组潜在token中
定性与定量分析表明,与强提示基线(如LLaVA)相比,Yo’LLaVA能以更少的token更高效地学习概念,并更有效地编码视觉属性
1 Introduction
“xx在这张照片里做什么?”或”我想为xx买生日礼物,你有什么推荐?”这些问题看似简单,但现有的大型多模态模型(LMMs)并非为回答此类_个性化_问题而设计
虽然这些模型能利用广泛知识对图像中的物体和人进行分类,但它们无法将这些物体识别为用户已知的特定主体,也无法在缺乏额外上下文的情况下提供任何个性化细节
默认情况下,LMM缺乏个性化能力,主要源于其训练数据的性质,这些数据主要由常见和通用概念(如人、狗、自行车)组成,而缺乏个性化概念(如名为’A’的人)
本文中,我们介绍了Yo’LLaVA,这是一种基于最先进LLaVA框架构建的新型个性化LMM
仅需少量个性化概念(如个人毛绒玩具)的图像,Yo’LLaVA就能学习将该概念嵌入到几个特殊token中(如’aka’),随后在提示时回答相关问题
尽管可以尝试用语言描述个性化视觉概念(例如”我的毛绒玩具’aka’是一个黄白色、狗形状的玩偶”),但文字描述往往模糊,可能无法捕捉所有视觉细节。在这些情况下,学习个性化概念的视觉表示可能更为精确
学习个性化LMM面临两大关键挑战:
- 个性化LMM时,需确保其广泛的预训练知识不受影响(即避免灾难性遗忘
- 使LMM能够捕捉细粒度视觉细节
挑战1:我们冻结了LMM几乎所有预训练权重,并引入一组可学习的输入token:一个特殊token<’aka’>和k个潜在token<token₁><token₂>…<tokenₖ>。特殊token作为个性化概念的标识符,使用户和模型能分别在输入和输出中引用它,而潜在token帮助捕捉<’aka’>的相关视觉细节。我们仅训练特殊token的输出权重

通过这种方式,模型可通过可学习token获取新的个性化知识,同时在其原始权重中保留所有先验知识。这种设计还具有训练快速和存储轻量的额外优势
挑战2:我们采用难负例挖掘(hard negative mining)收集与个性化概念视觉相似但不相同的负例。随后,我们用大量问题(例如”<’A’>在这张照片中吗?”)和正负图像样本(例如”是”和”否”)训练模型。通过这种方式,模型学习将个性化概念的细粒度视觉属性嵌入到可学习token中
总结而言,我们的主要贡献包括:
- 个性化大型多模态模型:我们提出了个性化LMM的新任务,使其能够适应用户特定概念并回答问题
- 高效的无遗忘框架:我们提出了Yo’LLaVA——一种个性化LMM,仅需少量每个概念的图像即可高效学习个性化概念,同时保留广泛的预训练知识
- 训练数据集:我们创建了一个专门用于探索个性化LMM任务的新数据集,为训练和评估提供了坚实基础
- 开源:我们将公开释放用于个性化概念建模任务的训练和评估数据,以及我们的代码和模型
2 Related Work
Large Multimodal Models
近年来大型语言模型(LLMs)崛起,其在通用问答和推理能力上取得了显著提升
这些进展进一步扩展,使得系统不仅能理解语言,还能进行视觉感知,即大型多模态模型(LMMs)
这些LMM代表了一个突破性的前沿,使模型能够处理并推理输入的图像和文本,其应用涵盖多个领域,如具身AI和机器人技术
然而,尽管这些模型能以多种方式展示其通用知识(例如识别并描述图像中的名人或犬种),但它们并未设计用于处理个性化查询(例如识别_你_或_你的狗_)
在本研究中,我们提出了一种方法,将此类LMM的通用知识扩展到对用户重要的新个性化知识,从而为用户提供定制化的个性化体验(例如回答与_你的狗_相关的问题)
Parameter-Efficient Fine-Tuning
微调是使训练模型适应新任务或概念的标准方法。然而,在LLMs/LMMs时代,微调这些模型在计算和内存需求上可能极其昂贵
为了克服这一限制,参数高效微调(PEFT)方法被引入,仅需少量可训练参数即可使这些模型适应各种下游任务。主要方向包括:
- 在模型的现有层中引入额外的可训练参数
- 软提示调优:学习提示(例如文本提示)以引导模型适应新任务或数据集。后一概念受提示工程能力的启发,利用任务特定指令(提示)在不修改模型参数的情况下增强模型能力
软提示调优已在多项任务中展现出令人印象深刻的结果(例如智能体工具调用),该概念还被扩展到其他领域(例如从生成图像中恢复提示、学习图像编辑)
在本文中,我们利用软提示调优的思想,在LMM的上下文中学习个性化概念
Personalizing Multimodal Models
在图像生成的背景下,个性化通常指使模型能够重现给定主体的像素级视觉细节的任务。提出的方法通常优化以下一项或两项:
- 针对特定概念的token
- 图像生成模型的部分或全部
相比之下,在NLP领域,个性化通常涉及使LLMs以特定方式表现(例如采用幽默或非正式语气),或使LLMs能够提供个性化响应(例如为特定用户推荐电影)
主要方法包括:
- 提示(例如为特定角色修改系统提示“你是一个幽默的人”)
- 信息检索(例如在交流过程中参考用户保存的元数据)
然而,在LMM的背景下,个性化研究尚不充分
个性化LLM不仅需要从文本中提取信息(例如“<’bo’>是一只柴犬”),还需要从视觉输入中提取信息(例如“这是<’bo’>的照片”)
本文是LMM个性化任务的先驱研究
一项并行研究是MyVLM,但其依赖外部模块识别主体,因此并非完全集成的系统
我们将本研究定位在图像理解和个性化对话之间:个性化后,LMM不仅能识别主体的视觉特征,还能保留关于该主体的推理能力(例如“<’bo’>是一只柴犬,因此它可能非常警觉和忠诚”)
我们还旨在构建一个轻量级、完整的系统,其中不涉及外部模块,完全依赖LMM本身
3 Yo’LLaVA:Personalizing LMMs to Understand User-Specific Concepts
给定少量人或主体的图像 I1,…,In (例如名为<’sks’>的毛绒玩具的5张图像),且没有任何文本标签或描述
我们的目标是将_该主体_嵌入预训练的LMM(在本研究中为LLaVA),以便用户和模型都能使用标识符(例如<’sks’>)进行交流,同时保留广泛的预训练知识
个性化后,我们的方法(Yo’LLaVA)能够:
- 在测试时识别新图像中的_主体_(例如Yo’LLaVA可以判断照片中是否有<’sks’>)
- 支持关于_主体_的视觉问答(例如给定一张新照片,可以询问<’sks’>的位置)
- 支持无需测试时参考图像的纯文本对话(例如询问关于<’sks’>的内在属性,如颜色、形状等)
第3.1节中详细说明如何将_主体_表示为LLaVA的可学习概念。随后,在第3.2节中讨论我们使Yo’LLaVA能够通过难负例挖掘识别_主体_的方法,并在第3.2节中进一步探讨通过难负例增强理解的方法
3.1 Personalizing the Subject as a Learnable Prompt
为了引导多模态模型,例如当呈现一张图像时,若希望询问LMM该图像中是否包含用户的个人玩具(例如名为<’sks’>),通常需要先提供个性化描述(如”<’sks’>是一个黄白色、狗形状的毛绒玩具”)
然而,手动编写此类提示既繁琐又不切实际,因为准确描述主体往往需要过多的词汇(token)。用文字描述主体的所有(微妙)视觉细节极具挑战性,甚至几乎不可能
近期研究表明学习soft prompts可能是更有效、更高效的替代方案[18,14]的启发,我们提出将主体的个性化描述表示为LMM的可学习提示
这种方法轻量级,仅需更新少量参数(新token及对应的输出权重),同时保持核心参数(如图像编码器、语言模型中除输出层外的所有层)不变
具体而言,给定主体(例如名为<’sks’>)的一组图像I1,…,In,我们将其个性化soft-prompt定义为:”<’sks’>是
… 。” 其中,<’sks’>是新增的词汇token,作为主体的标识符,使用户和模型在提问或回答时都能引用该主体。{<’token i’>}(i=1~k)是可学习token,用于嵌入关于主体的视觉细节
由于<’sks’>是token词汇表的新条目,我们将语言模型的最终分类头矩阵W从C×N扩展到C×(N+1),其中C是隐藏特征维度,N是原始词汇表大小。在Yo’LLaVA框架中,可训练参数为:
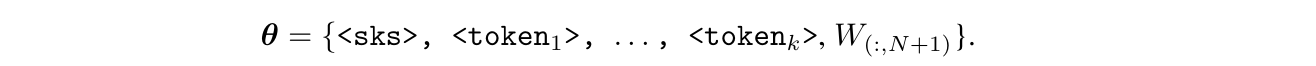
在此,我们仅训练新增的k+1个输入token以及与标识符token<’sks’>关联的最终分类头矩阵W。除此之外,预训练LLaVA的所有其他组件(即视觉编码器、视觉投影器和语言模型)均保持冻结
为帮助模型学习新的视觉概念,我们生成对话训练数据三元组(I(i),Xq(i),Xa(i)),其中I(i)是输入图像,Xq(i)是问题,Xa(i)是相应答案(数据集创建细节见第3.2和3.3节)
我们使用标准masked language modeling损失,通过以下公式计算每个长度为L的对话中目标响应Xa的概率:
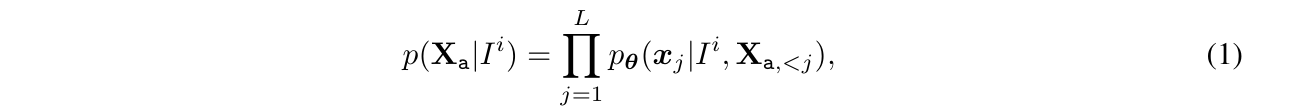
- 其中θ是可训练参数,Xa,< j 分别表示当前预测token xj之前所有轮次的指令和回答token
3.2 Enhancing Recognition with Hard Negative Mining(通过难负例挖掘学习识别主体)
仅用少量图像训练模型时,模型可能无法学习识别主体所需的视觉属性
为解决这一问题,我们从LAION中随机采样100张图像作为负例(不包含<’sks’>的图像)
通过正负例混合训练,模型可以理解主体的视觉属性(例如<’sks’>是一个毛绒玩具),但也可能导致过度泛化:例如,如果<’sks’>是一个黄色狗形毛绒玩具,模型可能会过度泛化,认为所有黄色毛绒玩具都是<’sks’>,这是不希望的
挑战在于如何提升模型区分主体细粒度特征的能力,以帮助其从视觉相似的主体中区分出来(例如其他类似的黄色毛绒玩具)
解决方法:采用难负例挖掘(Hard Negative Mining)
如果主体<’sks’>是一个毛绒玩具,the hard negative examples 将是其他与主体不完全相同的毛绒玩具
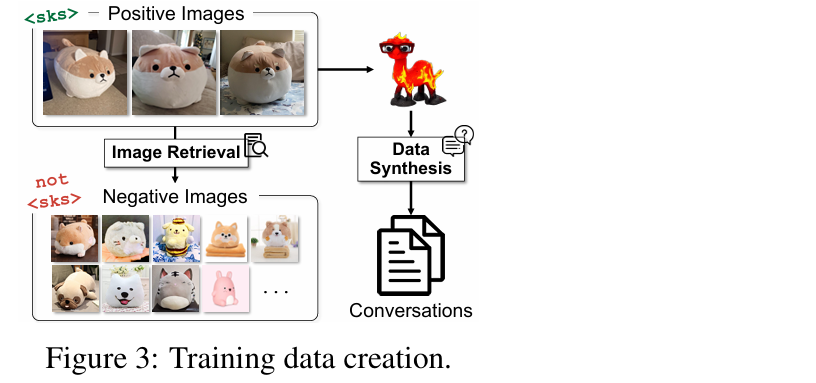
通过让模型接触多样化的视觉相似但不相同的对象,我们鼓励其学习更具区分性的特征,并避免过度泛化
我们从LAION中检索负例:具体来说,对于每个训练图像 Ii(i=1,…,n),我们检索CLIP图像嵌入相似度最高的前m张图像。最终,负例数据包括:100张_简单_负例和n×m 张_难_负例
为了使模型能够识别图像中的主体,我们将训练图像与识别问答模板配对。这一过程涉及询问特定主体(例如<’sks’>)是否出现在照片中
具体而言,在训练期间,每张正负图像(positive and negative image)会随机与一个问答模板配对;答案模板根据输入图像的类型(正例或负例)采样
本质上,所有问答对均以二元分类的形式呈现,通过是/否问题判断主体(例如<’sks’>)是否在照片中可见

3.3 Learning to Engage in Natural Conversations about the Subject(学习围绕主体进行自然对话)
- Yo’LLaVA已具备在新图像中识别主体的能力。然而仅用识别数据训练模型无法使其与用户进行超越识别的交流。尽管模型可能正确回答<’sks’>是否出现在图像中,但它可能在其他问题上表现不佳

因此,我们下一步旨在创建更通用的对话训练数据(例如视觉问答)。这些对话聚焦于主体的视觉特征,而非之前识别对话中使用的识别能力
我们使用一个模板,包含10个手动编写的基本问题,涉及内在属性,分为两大类:
- 与人相关的问题(例如“这个人的头发是什么颜色?”)
- 和与主体相关的问题(例如“这个主体是什么颜色?”)
我们排除了可能不适用于所有主体的复杂或微妙问题(例如“这个玩具的尾巴是什么颜色?”)
具体事例见下图:对于每张图像 Ii,我们使用LLaVA为每个模板问题生成答案,形成三元组对话(I(i),Xq(i),Xa(i))

传统方法会直接用三元组(I(i),Xq(i),Xa(i))训练Yo’LLaVA。然而这种方法无法有效促进可学习提示的学习(向其嵌入新的视觉知识),因为模型已获得足够回答问题的额外信息
例如,如果提供一张毛绒玩具<’sks’>的照片并询问“它是什么颜色?”,LLaVA 无需知道或理解<’sks’>的视觉属性即可正确回答问题;它可以直接利用输入图像回答问题
因此,为了鼓励模型将主体的视觉属性提炼到可学习的个性化提示中,我们在训练时排除Ii,仅使用(Xq(i),Xa(i))进行训练
通过这种方式,Yo’LLaVA能够正确学习将主体的相关视觉信息嵌入到软提示中,并回答关于主体视觉属性的各种问题,甚至无需任何参考图像
4 Experimental Setup
Training
除非另有说明,我们使用5张图像和k=16个token来学习主体。每个对话都是单轮(一个问题和一个回答)
使用AdamW优化器,学习率为0.001,并以LLaVA-1.5-13B作为基础模型
训练图像包含每个主体约200张负例图像(约100张来自检索的难负例和约100张随机采样的简单负例)
对每个主体训练最多15个epoch,根据训练集上的识别准确率保存最佳检查点。所有实验均在单块A6000 GPU上进行
Dataset
收集了包含40个主体的新数据集:人物(10个)、宠物(5个)、地标(5个)、物体(15个)和虚构角色(5个)
数据集分为训练集和测试集。每个主体的图像数量从10到20张不等
Baselines
选择Vanilla LLaVA作为主要基线
考虑LLaVA的两个主要变体:
- Naive LLaVA(即LLaVA本身,不含任何个性化信息)
- LLaVA+个性化描述(LLaVA辅助以关于主体的个性化描述)
采用两种方法获取个性化描述:
- 人工编写:我们为每个主体手动编写描述(见下表),模拟用户向LMM描述个性化主体的真实场景;

- 自动生成描述:首先提示LLaVA为该主体所有训练图像生成描述。提供两种使用这些描述的方式:这些自动生成的描述对应于下表中”LLaVA+Prompt, Text”(约1.3k token(长)和约16 token(总结)的情况
- 将所有描述拼接成长而丰富的描述
- 提示LLaVA将这些描述总结为简短的个性化描述
- 人工编写:我们为每个主体手动编写描述(见下表),模拟用户向LMM描述个性化主体的真实场景;
为了扩展我们对提示方法的评估,我们将分析扩展到GPT-4V(领先的专有多模态聊天机器人),使用相同的方法生成简短的个性化描述
此外,由于GPT-4V支持多图像对话(LLaVA不支持的功能),我们还尝试了个性化图像提示:提供主体的训练图像及介绍文本(例如”你看到的是名为
的主体的照片”) 这些实验对应于上表中”GPT-4V+Prompt, Image”(约1k token(1张图像)和约5k token(5张图像)的情况。由于图像比文本传递更多信息,我们假设个性化图像提示代表了提示效果的上限
由于GPT-4V的闭源性质,我们的方法无法直接集成,因此该比较仅作为参考
5 Results
我们展示了Yo’LLaVA在两个主要任务上的表现:
- 识别能力
- 问答能力
第一个任务评估Yo’LLaVA在测试图像中识别个性化主体的能力,而第二个评估模型围绕个性化主体进行自然对话(即引用和响应查询)的能力
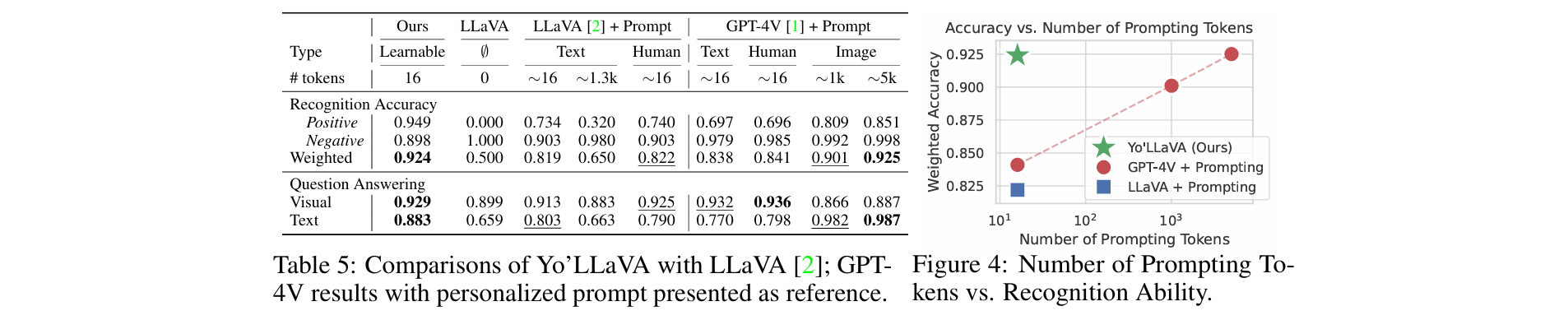
5.1 Recognition Ability
首先评估模型识别个性化主体<’sks’>的能力。40个主体,每个主体有5到10张包含相应主体的测试图像。对于每个主体,其所有测试图像作为正测试图像,其余39个类别的测试图像作为负测试图像
测试时,我们向模型展示一张照片并询问:”你能看到<’sks’>在这张照片里吗?请用单个词或短语回答。”对于包含<’sks’>的照片,真实回答是”是”,其他照片则是”否”
下图展示了正负测试图像的准确率。考虑到测试集的不平衡性,我们计算加权准确率:加权准确率=0.5正例准确率+0.5负例准确率:

正如预期,Vanilla LLaVA基线无法识别个性化主体(这种能力本就不存在于该模型中),我们实际观察到它总是回答”不,这不是<’sks’>”(因此准确率为0.5)
当我们用简短的个性化描述提示它时,LLaVA达到了不错的准确率(即使用约16 token时准确率为0.819-0.822)。另一方面,过长的描述会降低其性能(使用1.3k token时准确率为0.650),可能是因为太多辅助信息反而无益
相比之下,Yo’LLaVA通过可训练token显示出明显优势,在使用大致相同数量token的情况下达到最高准确率(即0.924)
我们还展示了使用GPT-4V进行文本和图像提示的结果,结果表明,Yo’LLaVA优于使用文本提示的GPT-4V(即0.924 vs. 0.838-0.841)
在图像提示方面,GPT-4V的性能随着参考图像数量的增加而提升。Yo’LLaVA仅用16个token就优于GPT-4V使用单张图像提示(约1k token)的表现
Yo’LLaVA即使仅用16个token,也能取得与GPT-4V使用5k token(5张参考图像)几乎相当的结果
我们预计将Yo’LLaVA与GPT-4V集成可以显著减少使用的token数量同时保持性能,但由于GPT-4V是闭源框架,我们无法尝试这一点
5.2 Question and Answering
为了评估模型在问答任务上的表现,我们为视觉和纯文本问答开发了新的基准测试
对于视觉部分,我们展示<’sks’>主体的照片并提出相关问题(例如”<’sks’>在哪里?”)
对于纯文本部分,我们专注于关于<’sks’>内在视觉特征的问题(例如”<’sks’>是狗还是猫?”)
所有问题都以多项选择形式(A或B)呈现。我们总共创建了571个问题;其中171个是视觉问题,400个是纯文本问题,结果如上图所示
Yo’LLaVA在视觉问答中表现最佳(准确率0.929),其次是使用人工编写个性化提示的LLaVA。总体而言,显然如果给定图像,LMM可以利用呈现的信息准确回答问题(例如给定一张狗的照片,即使不知道狗的名字是<’bo’>,它们也能正确识别狗的毛色)
对于纯文本问答(我们没有测试图像,直接询问关于主体的问题),结果表明文本提示(即使是人工编写)可能无法像可训练提示那样捕捉到尽可能多的细节,Yo’LLaVA仍然是领先方法(准确率0.883),优于LLaVA和GPT-4V
当以图像作为提示时,GPT-4V可以很好地回答所有内在问题(准确率0.982-0.987)。但这在意料之中,因为所有信息都可以在给定的图像中找到
值得注意的是,使用图像作为个性化提示至少需要1k token,而Yo’LLaVA仅使用16个token
5.3 Comparison wit MyVLM
我们使用MyVLM的数据集将我们的方法与这一并行工作进行比较,该数据集包含29个不同对象,并严格遵循其实验方案
为了评估模型在图像中识别个性化主体的能力,使用与MyVLM相同的准确率指标。如果主体在照片中,将真实值设为”是”;否则为”否”。提示Yo’LLaVA:”你能看到<’sks’>在这张照片里吗?请用单个词或短语回答”
将结果与MyVLM报告的概念头(外部人脸/物体识别器)评估数据进行比较。我们还评估训练后的LMM是否能生成包含主体标识符(如<’sks’>)的描述
按照MyVLM的做法,我们测量”召回率”,即在为其图像生成的描述中至少出现一次<’sks’>的情况。结果如下图所示:

- 我们的方法在两项指标上都显示出明显优势,尽管更简单且不依赖外部识别器(如人脸识别器)
6 Ablation Studies(消融研究)
Number of trainable tokens
将每个主体的训练图像数量设为n=10,并将可训练token数量k从0变化到36
当k=0时,训练仅限于标识符token(如<’sks’>)
下图(第一行)所示,仅训练该token时,识别个性化主体的准确率较低(24%)
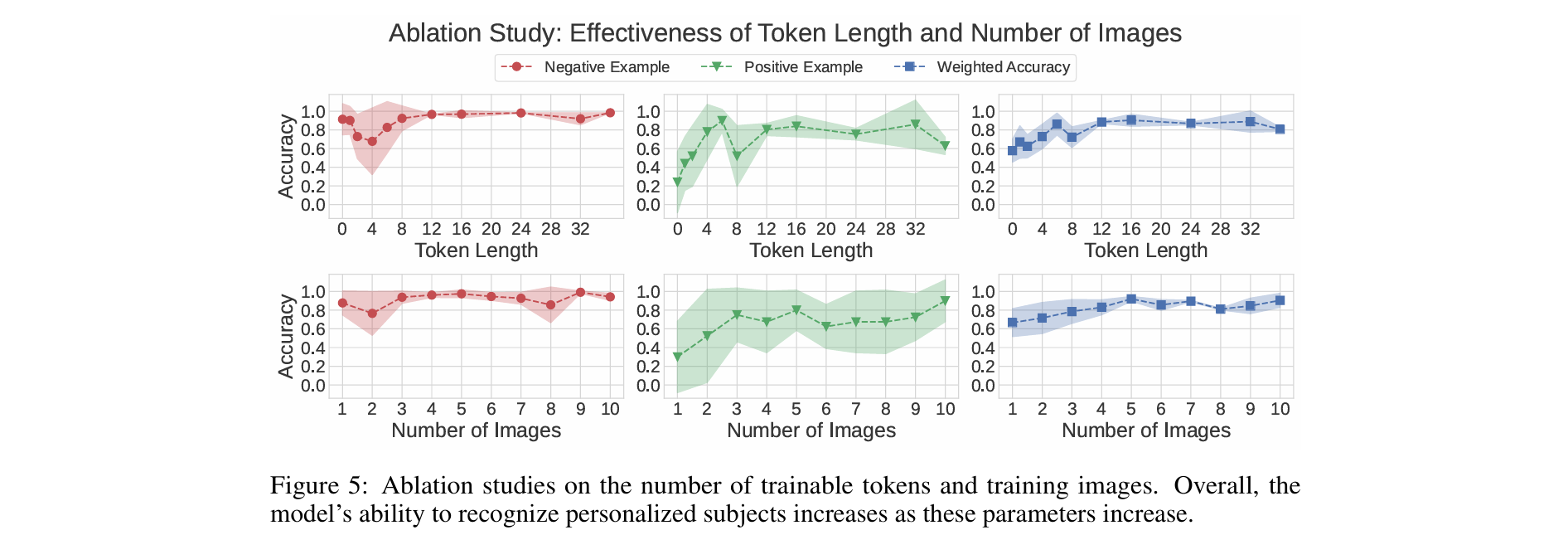
总体而言,当潜在token数量超过k=8时,模型识别个性化对象的能力通常会对正负例都有所提升。为了平衡准确率(越高越好)和token长度(越低越高效)
我们为最终模型选择k=16,在该消融研究中实现了91%的准确率
Number of images
将可训练token数量设为k=16,并将训练图像数量从n=1变化到n=10
下图(第二行)显示,随着照片数量的增加,模型的识别能力逐步提升
- 在Yo’LLaVA最终版本中选择n=5,因为在该消融研究中,这是达到90%以上准确率所需的最少训练图像数量
Dataset creation
- 最后我们对数据集构建进行消融研究。下图展示了识别任务的加权准确率,以及个性化模型<’bo’>的定性示例,以展示模型在支持问答方面的能力

Vanilla LLaVA无法执行文本对话或识别(它对所有测试图像总是回答”不”,准确率50%)
仅在识别任务(即判断给定照片中是否有<’sks’>)上训练后,LLaVA能在一定程度上识别主体(准确率70%),但仍无法执行文本对话任务
在使用合成对话和识别数据训练后,识别准确率和对话能力都有所提升(准确率75%)
最后,在引入检索的难负例(Yo’LLaVA)后,准确率显著提升至91%
7 Conclusion
我们提出了个性化LLMs的新任务,该任务需要从少量图像中学习给定主体(如名为<’bo’>的狗)的视觉属性,然后在新图像中识别该主体,并在提示时回答关于该主体的问题
为了解决这个问题,我们提出了Yo’LLaVA,其中个性化主体由带有标识符(如<’sks’>)的可学习提示和一系列k个潜在token(如<token;>)表示
实验表明,与强提示基线(如GPT-4和LLaVA)相比,Yo’LLaVA能够用更少的token更高效地学习概念,并通过捕捉更多视觉属性更有效地编码
一个有前景的未来方向是将Yo’LLaVA与用户的元数据集成(例如将关于名为<’bo’>的狗的个性化概念与其医疗记录或偏好联系起来),以增强现实应用中的个性化
DeepSeek要点总结
1. 研究背景与问题
- 现有LMM的局限性
- 通用多模态模型(LLaVA、GPT-4V)擅长通用视觉任务(图像描述、VQA)
- 无法识别用户个性化主体(如”我的宠物狗”或”朋友A”)
- 传统文本描述方法难以精确捕捉视觉细节,且提示效率低
2. 核心方法
Yo’LLaVA框架
核心思想
- 将个性化主体表示为可学习的soft prompts
- 仅更新少量参数(新增token及输出层权重),冻结预训练模型其他部分
技术实现
- 个性化标识符与潜在token
- 新增特殊token
<sks>作为主体标识符 - 使用
k个可学习的潜在token<token₁>...<tokenₖ>编码视觉细节
- 参数高效训练
- 仅训练新增token和输出层对应权重
- 冻结视觉编码器、语言模型主体等核心组件
- 训练数据生成
- 结合难负例挖掘(hard negative mining)从LAION检索相似负例
- 构建二元分类问答模板(判断主体是否在图像中)和开放问答数据
3. 关键创新点
- 任务创新
- 首次提出LMM的个性化任务,支持:
- 用户特定主体识别
- 视觉问答
- 文本对话
- 首次提出LMM的个性化任务,支持:
- 方法创新
- 轻量级可学习提示符:仅需5张图像+16个token
- 难负例增强:提升模型区分能力,避免过度泛化
- 资源贡献
- 发布40类主体数据集(人物/宠物/地标等)
- 开源代码与模型
4. 实验结果
| 评估指标 | Yo’LLaVA | 对比基线 (LLaVA+文本提示) | GPT-4V图像提示 |
|---|---|---|---|
| 主体识别准确率 | 92.4% | 81.9% | 90.1% |
| 视觉问答准确率 | 92.9% | - | - |
| 纯文本问答准确率 | 88.3% | - | - |
效率优势:
- 仅需16个token即达到GPT-4V(5张图像+5k token)相近性能
- 显著降低计算成本
5. 局限性
- 细粒度识别不足:主体在图像中占比过小时准确率下降
- 幻觉问题:可能生成无事实依据的描述(如虚构人物生日)
6. 应用与展望
应用场景
- 个性化健康助手(用户体征识别)
- 定制化教育
- 娱乐(虚构角色交互)
未来方向
- 结合用户元数据(如宠物医疗记录)增强语义理解
- 探索跨模态个性化(语音+视觉)
总结
Yo’LLaVA通过:
- 创新的可学习提示符设计
- 参数高效微调方法
实现了:
- LMM对个性化主体的高效识别与对话
- 轻量级设计下的准确率与计算成本平衡
为个性化AI助手提供了新范式

