自然语言处理 lec4-3 nlm
Language Modelling as Classification
从分类器的角度看语言模型
目标:设计分类器计算:
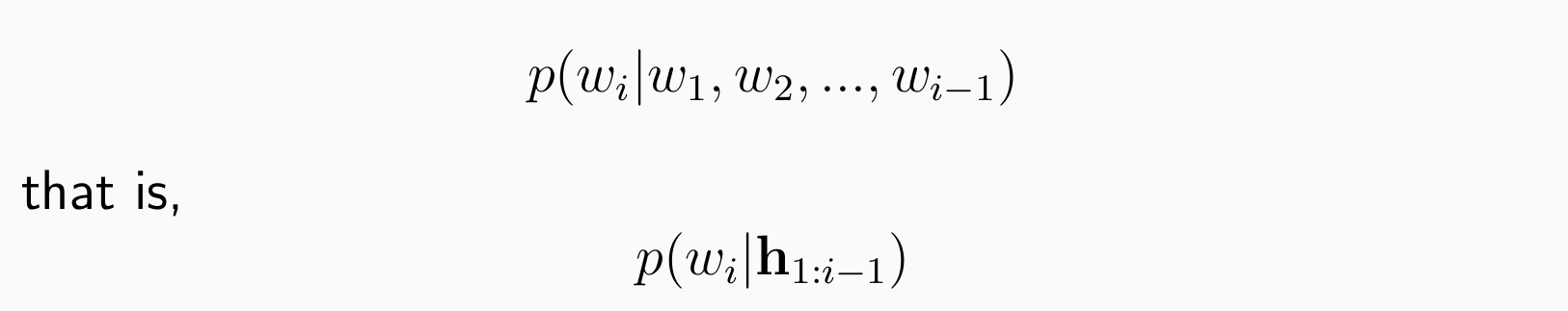
输入:从第一个词到目前预测位置的词
输出:在词汇表中找到下一个词
A Log-linear based Language Model
- Log-Linear Model:使用softmax来概率化/归一化
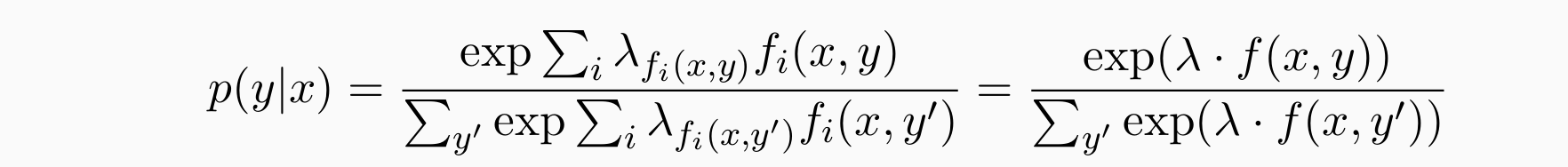
设计许多特征模板/函数 f∗() 来描述一段文本 x
y可以是给定单词的含义、给定书籍的类别或餐厅评论的正面/负面标签等等
An Intuitive Idea: N(ew)LM-0
直观地,构建一个对数线性分类器,将 h1-hi−1 作为输入并输出单词标签 w∗
- 从单词 h1-hi−1 的历史中提取特征
- 尝试任何可能的单词标签 w
- 输出概率最高的 w∗i
问题:
- 特征维度过大,不易应对可变长的位置表达
- 模型不容易优化
- label set过大
特征跟位置有关,而位置难以表达
NLM-0(maximum entropy language models):设计了许多优化方法,但最终归结为最大熵梯度下降( stochasitc gradient descent)
Pros:没有zero-events,不依赖counting,是概率模型
Cons:没有更好的方法表示词,难以优化
Neural Language Models
Neural Networks
- A basic neural network unit:

- 加入提供非线性的函数,有点像log-liniear:
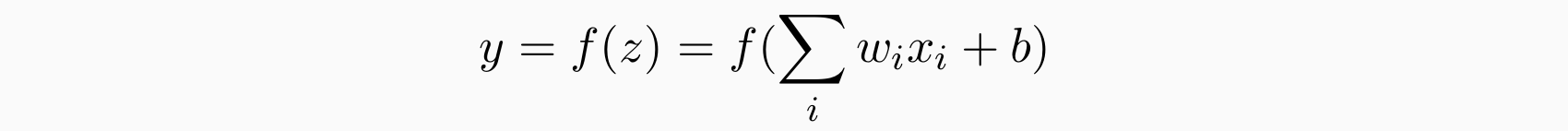
Non-Linear Activation Function
可微分
domain宽一些而输出窄一些
Sigmoid:
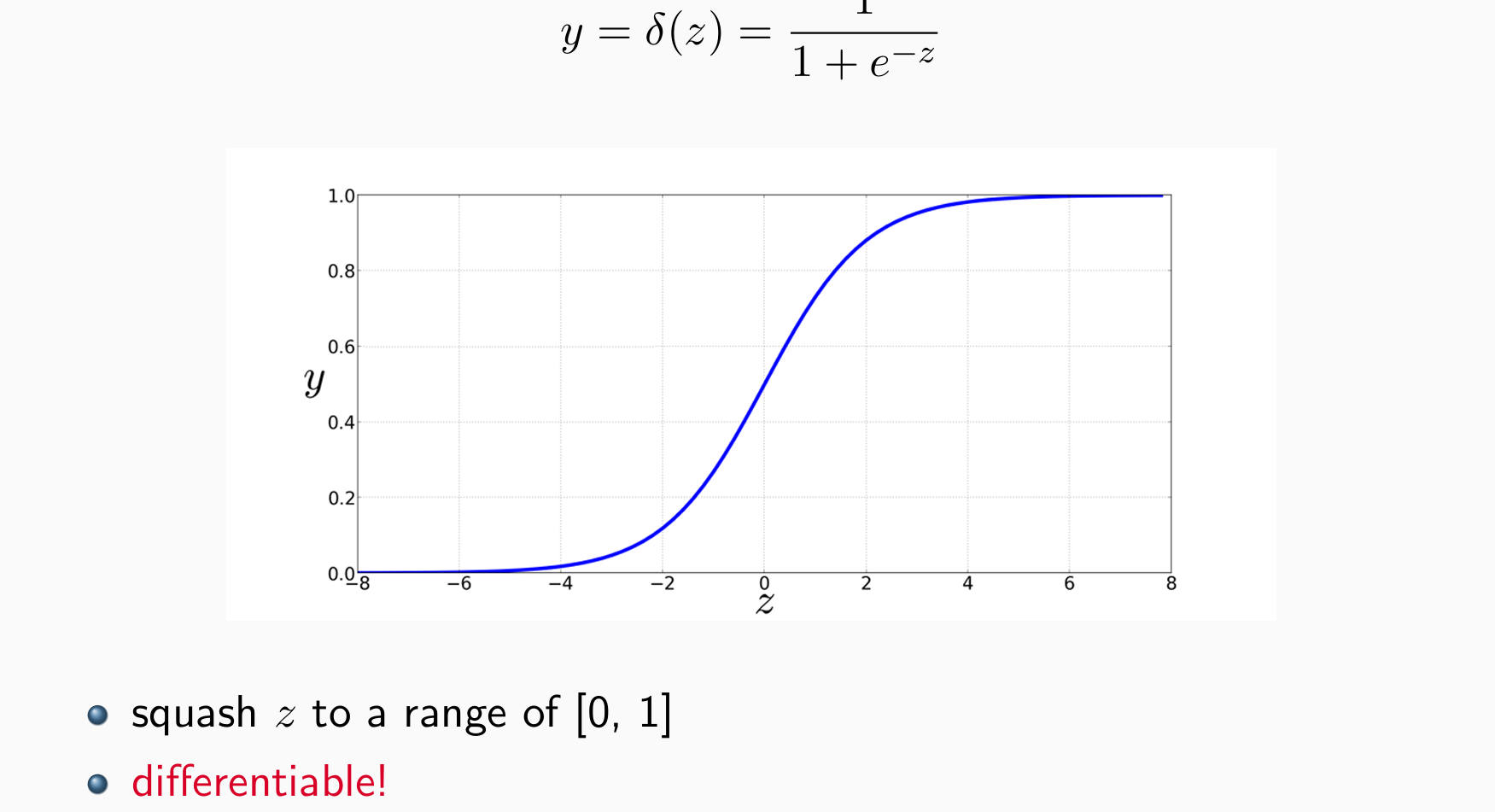
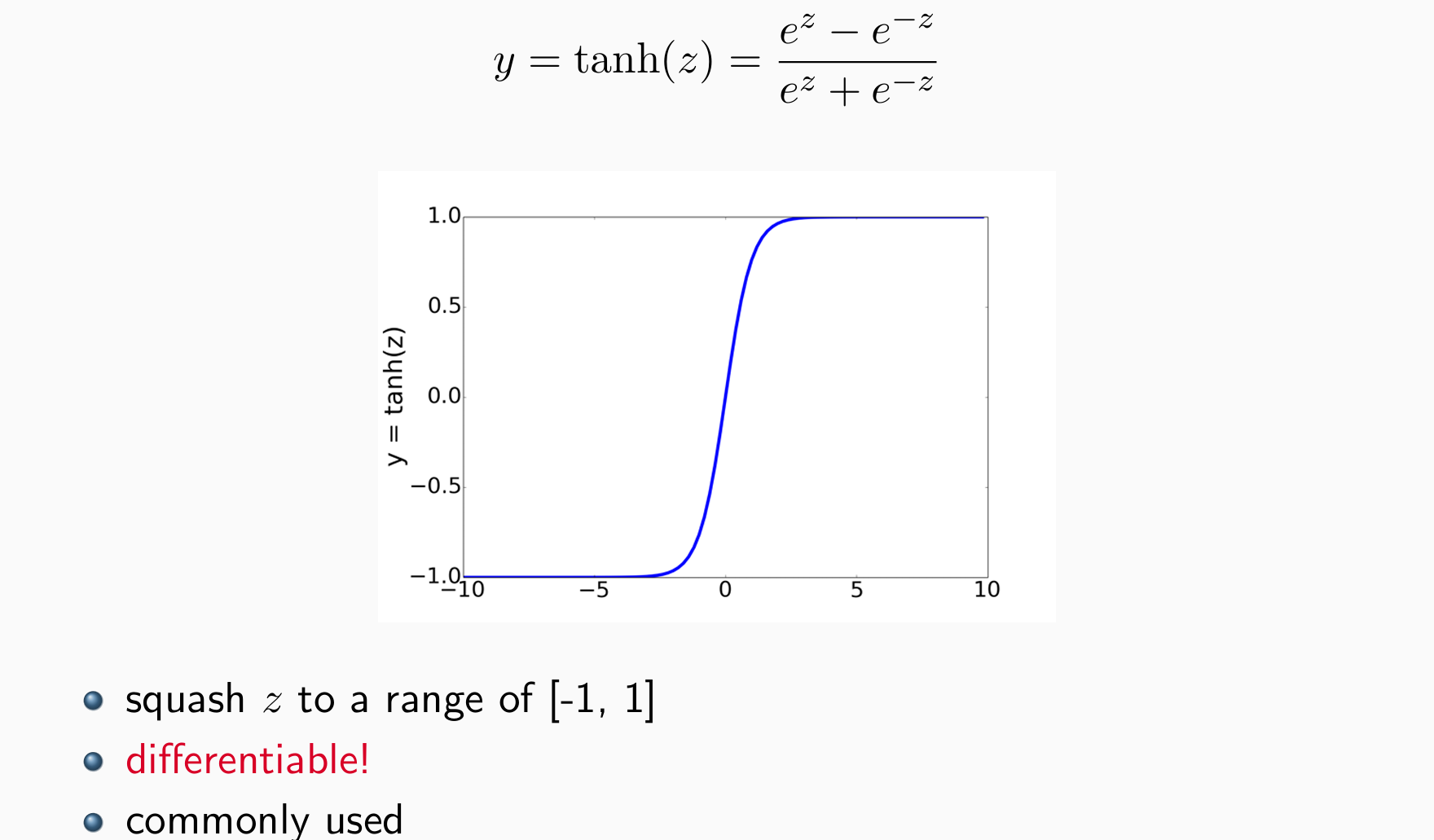
- tanh: elementwise hyperbolic tangent
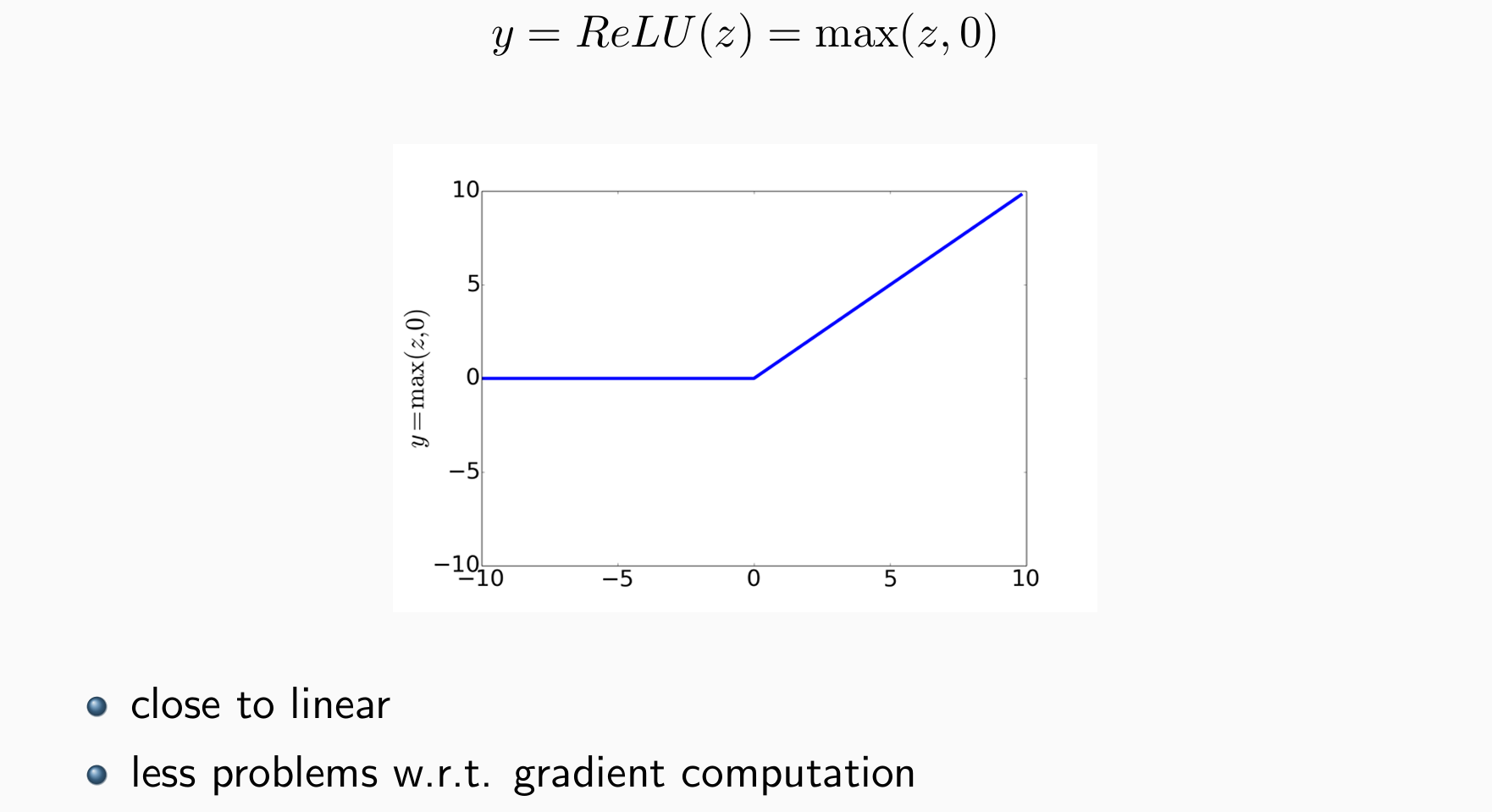
- ReLU: Rectified Linear Unit
- 现在我们可以添加很多layers: linear, non-linear, linear, non-linear, linear, …
- layers越多,参数越多,计算量越大
- layers越多,可以越好的拟合训练数据
- layers越多,可以提高模型能力
Neural Language Model 1
- Let’s build the first neural language model:linear, non-linear, linear, non-linear
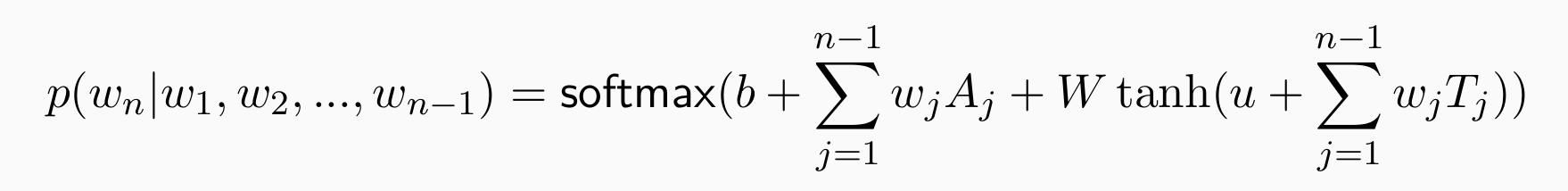
parameters: b, A, W, T, u,M,可学习,但T与历史相关
vocabulary size: V = |V|, hidden size: H
b(V), A(∗,V), W(V,H), T(∗,H), u(H),word embeddings dim. d
Representing Words
bag-of-words和one-hot都并不好,希望对其进行压缩
w∗ 肯定是稀疏的,我们肯定可以将它们压缩/压缩成更短的向量,例如,d 维向量,其中 d 比 V 短得多——word embeddings:
- 找到 (V,d) 的矩阵 M 来存储这些向量
- V 中的第 i 个单词将表示为 (wi.T)M = mi,mi可以跟着模型一起训练
- mi,更短,更浓缩
重要的是,可以将 (V,d) 的矩阵 M 视为参数,和LM一起训练。如果训练集够大,可以学很好的词的表示:
- 无需提前构建
- 无需额外的训练数据
- 可以学习 one-hot 之外的东西
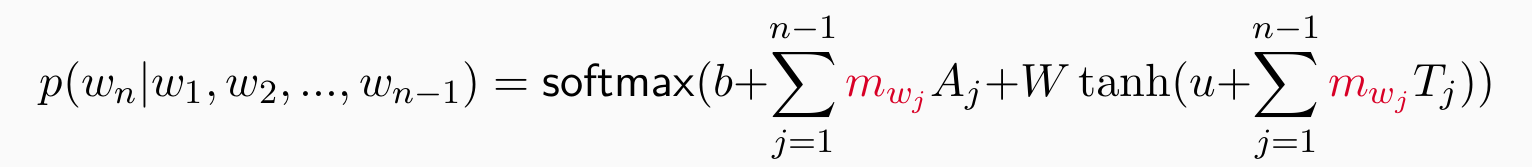
问题:仍然带有n,且Tj,Aj说明仍然存在窗口且A和T和位置相关,A和T的实际大小还要乘n - 1
如果T去掉角标直接乘T,则退化为连续词袋模型。此时1~n-1的词与位置无关,都乘T
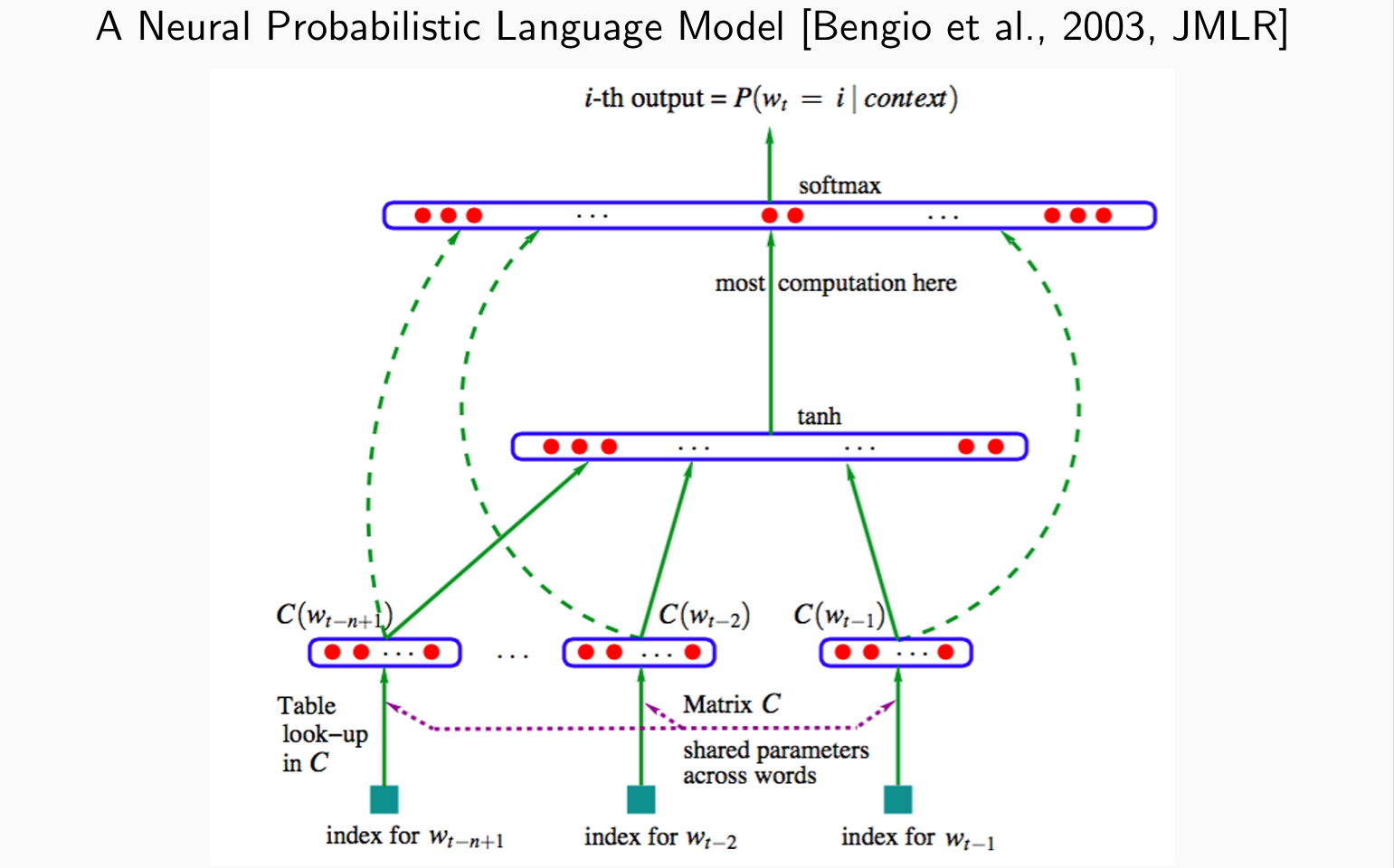
问题:在没有GPU的年代做矩阵乘法计算慢,效率低
单个参数不再具有具体的含义
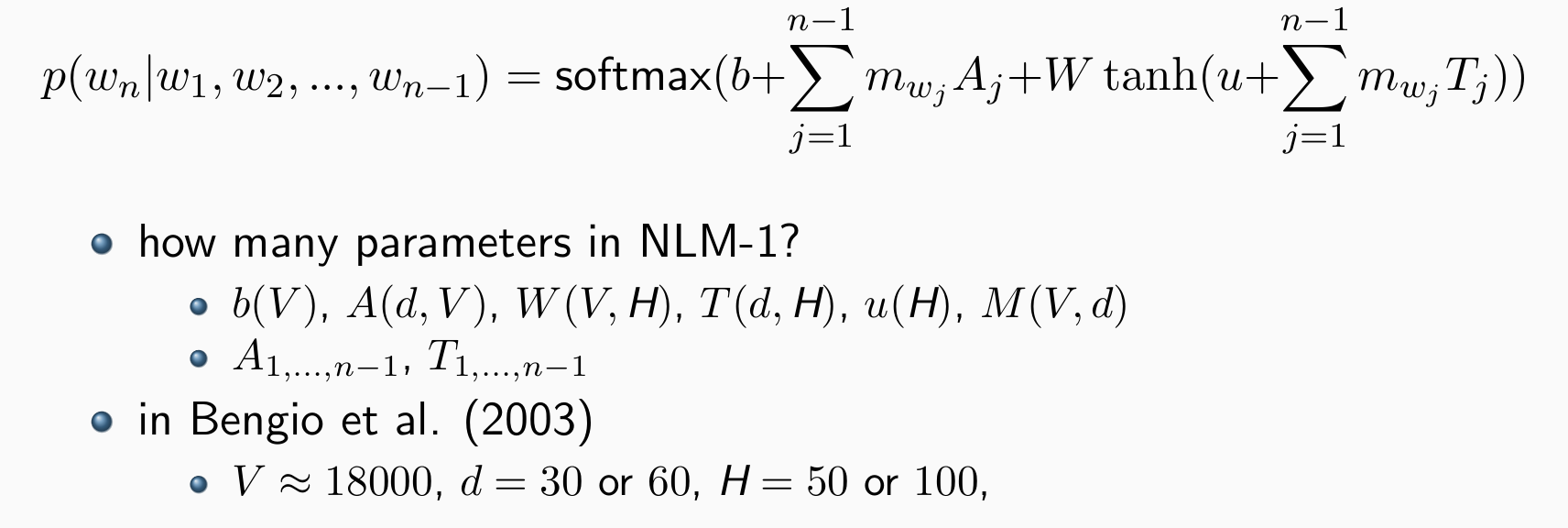
- 压缩参数量的方法:
- 强制A = 0,效果稍好,但是训练速度变慢
- 平均n-1个词,导致连续词袋模型,失去位置信息。但在辨析词义任务表现很好
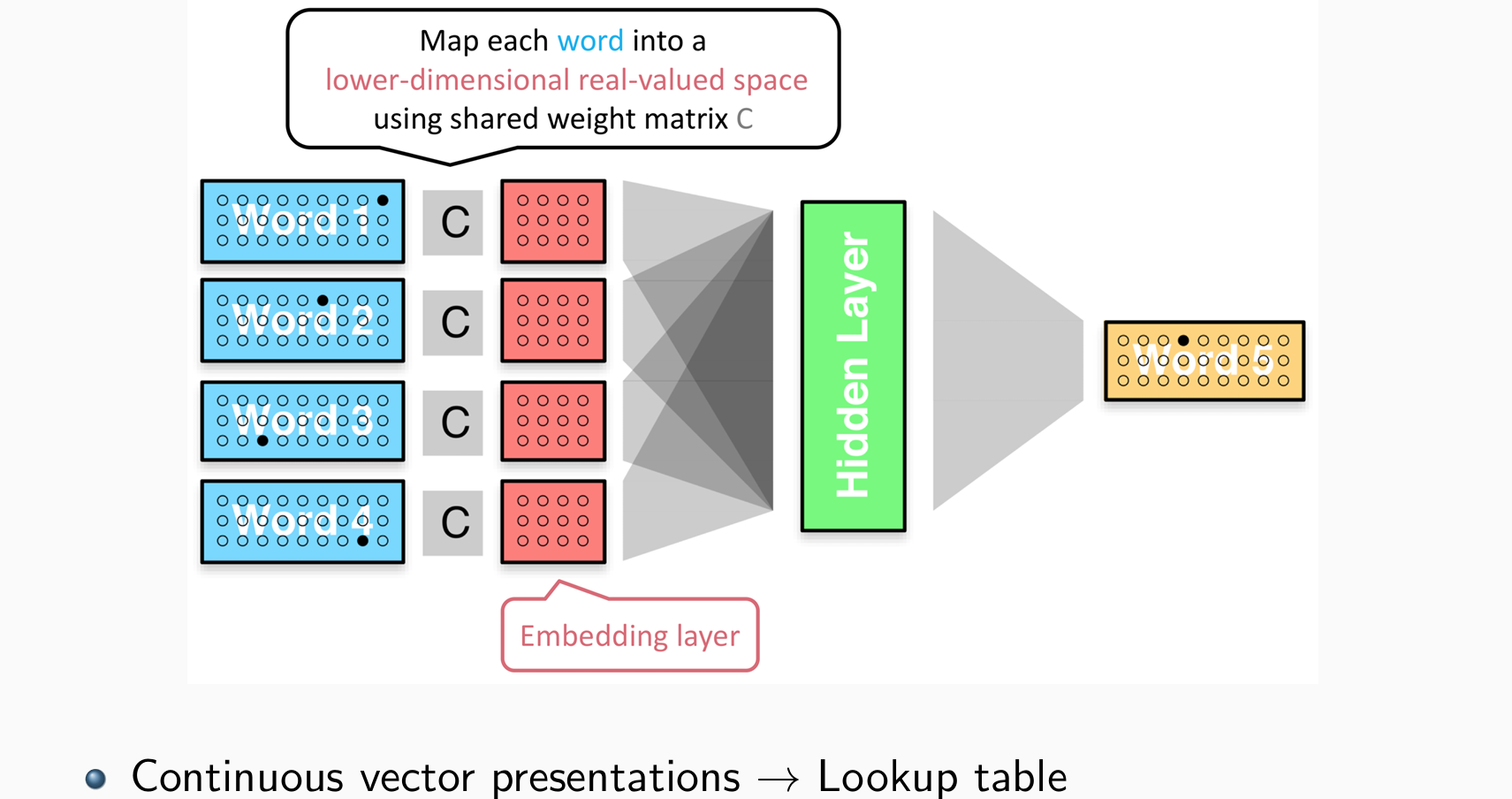
使得lookup table可训练更新,相似的词在词空间上表示相近
但是仍然没有摆脱n-grams的限制
Training
使用最大似然估计和随机梯度下降
问题:训练过程非常缓慢
Characterizing Sequences
- 由于embedding矩阵的存在,词的表示和位置强相关,当修饰发生变化,可能导致预测出现偏差

- 因此能否想滤波器一样在词中找到想要的词,去掉不想要的词 -> 引入卷积
Neural Language Models 2
Convolutional Networks
不再做马尔科夫假设
历史可以很短也可以很长
引入卷积和滑动窗口,在词中抽取特征
模型仍然使用linear + non-linear的结构,并且加入更多层来提高性能

- 超参数:layer层数、非线性函数f()、窗口大小、滤波器数量
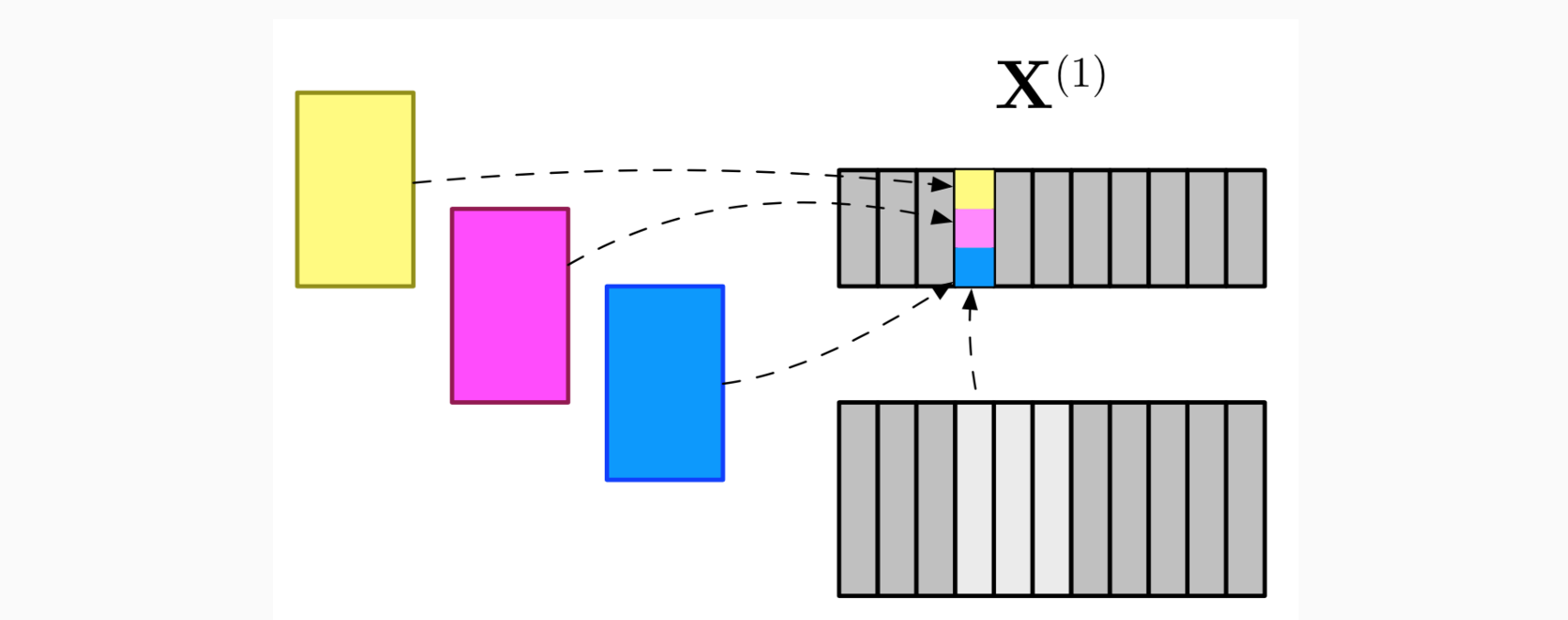
滑动窗口向前滑动,得到的表示成为新的输入X(1),然后再找一组滤波器继续上述过程得到X(2)……从而抽象出不同”分辨率”的特征
滤波器可以作为参数来进行学习
X(l)[∗,m]可以被视为隐藏的状态向量(第m个词,第l层)
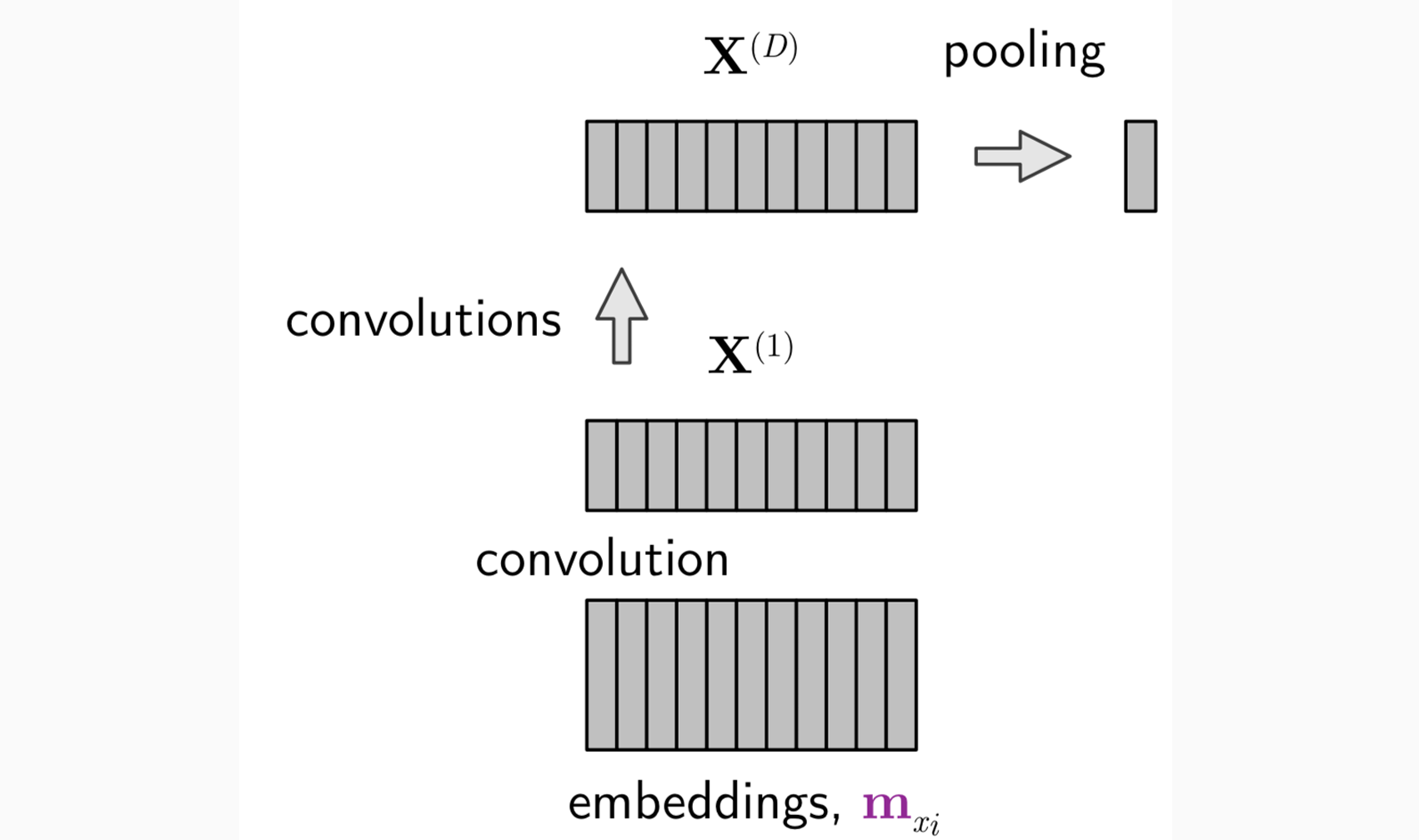
- X(d)是一个变长的矩阵,和句子长度和历史相关(d(dim.) × (t − 1)(th
word)),因此需要将变长的X(d)编程定长(方便分类任务) -> pooling
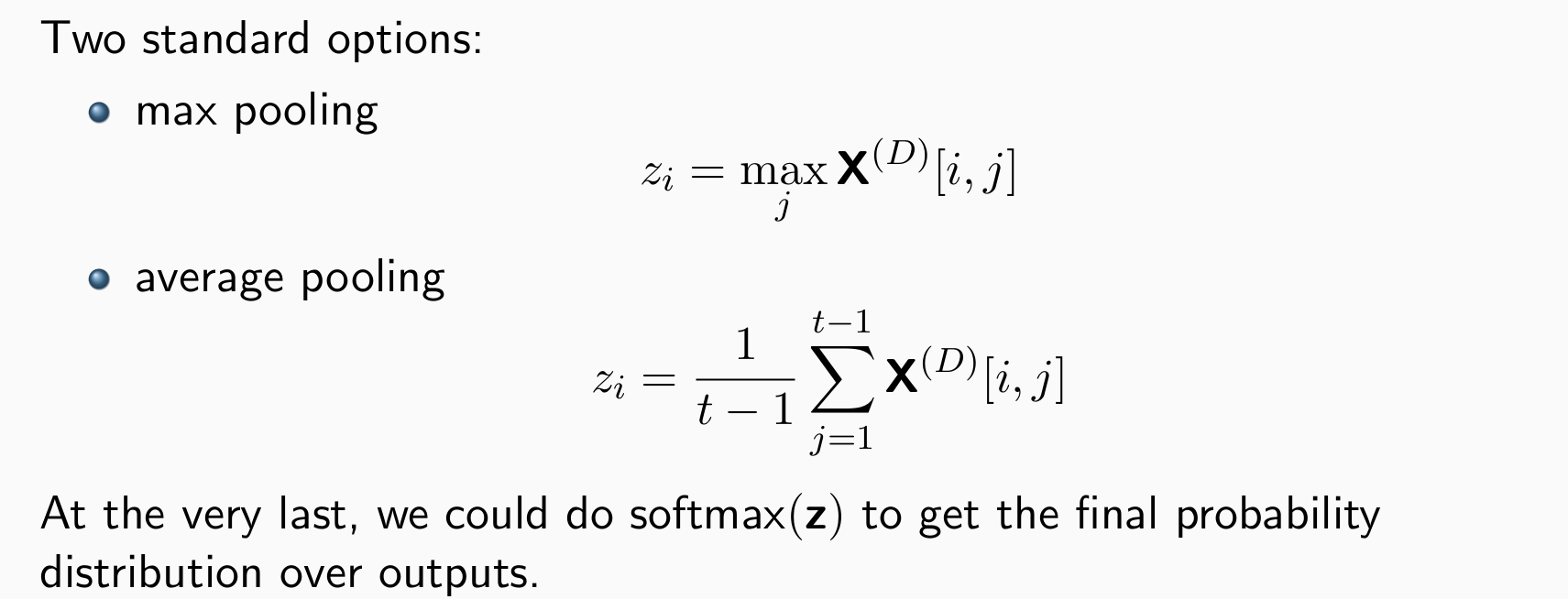
- 使用场景:文章中小的区段,有关键词不需要长距离时,使用CNN效率高且效果好,CNN对局部的文字掌握更好
Neural Language Models 3
Recurrent Neural Network
维护隐藏状态的vector,记忆历史中的关键信息
在每个位置上引入了hidden vector,定长
既考虑了历史信息,同时考虑了当前状态。根据设计忘记一些信息,记忆一些信息,更新一些信息,进行迭代
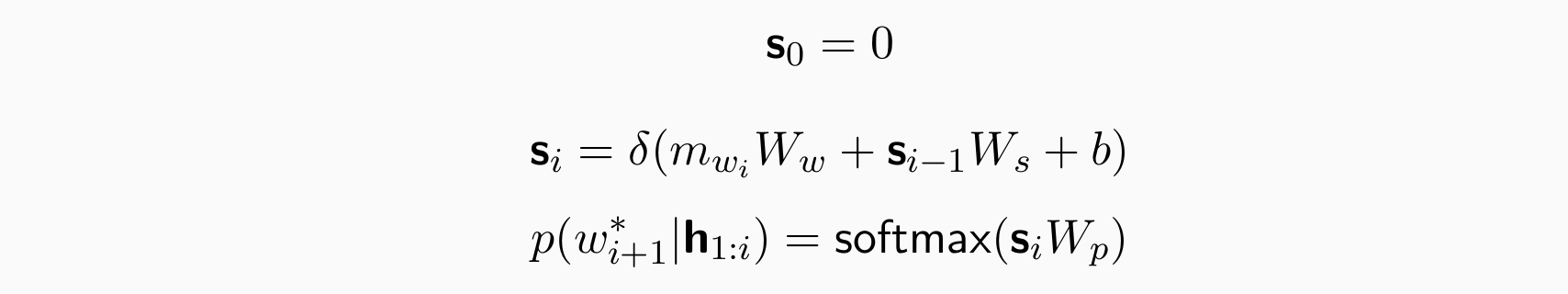
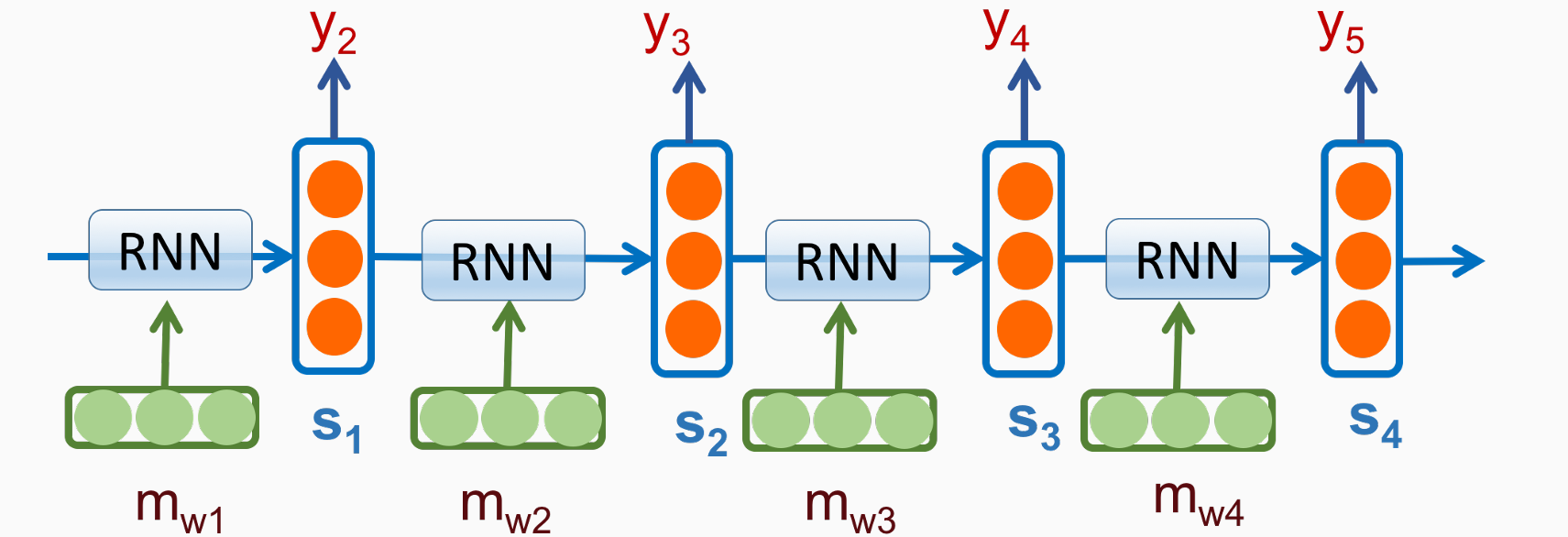
- 训练目标:交叉熵,−logp(wi|h1:i−1)(叠乘,取log后变为叠加),在每个位置上做交叉熵然后相加
Issues with RNN
- 朴素RNN的问题:
- 处理长句子训练速度过慢、
- 梯度传回的时候梯度下降非常快,更新剧烈忘得太多。因而随着序列变长hidden vector只更新附近的参数,长距离的梯度几乎不再更新,有梯度消失的问题
Improvements
更新hidden state函数的参数太少,公式和结构过于简单
如果不是语言模型可以进行双向建模(e.g.文本分类):stacking or bi-directional,引入了逆向的hidden state拼接起来
引入新的机制取维持长期的记忆:
- long short-term memories (LSTMs): introduce additive connections, cell state and forget gate, input gate, and output gate
- gated recurrent units (GRUs): introduce additive connections, update gate and reset gate
Long Short-Term Memory
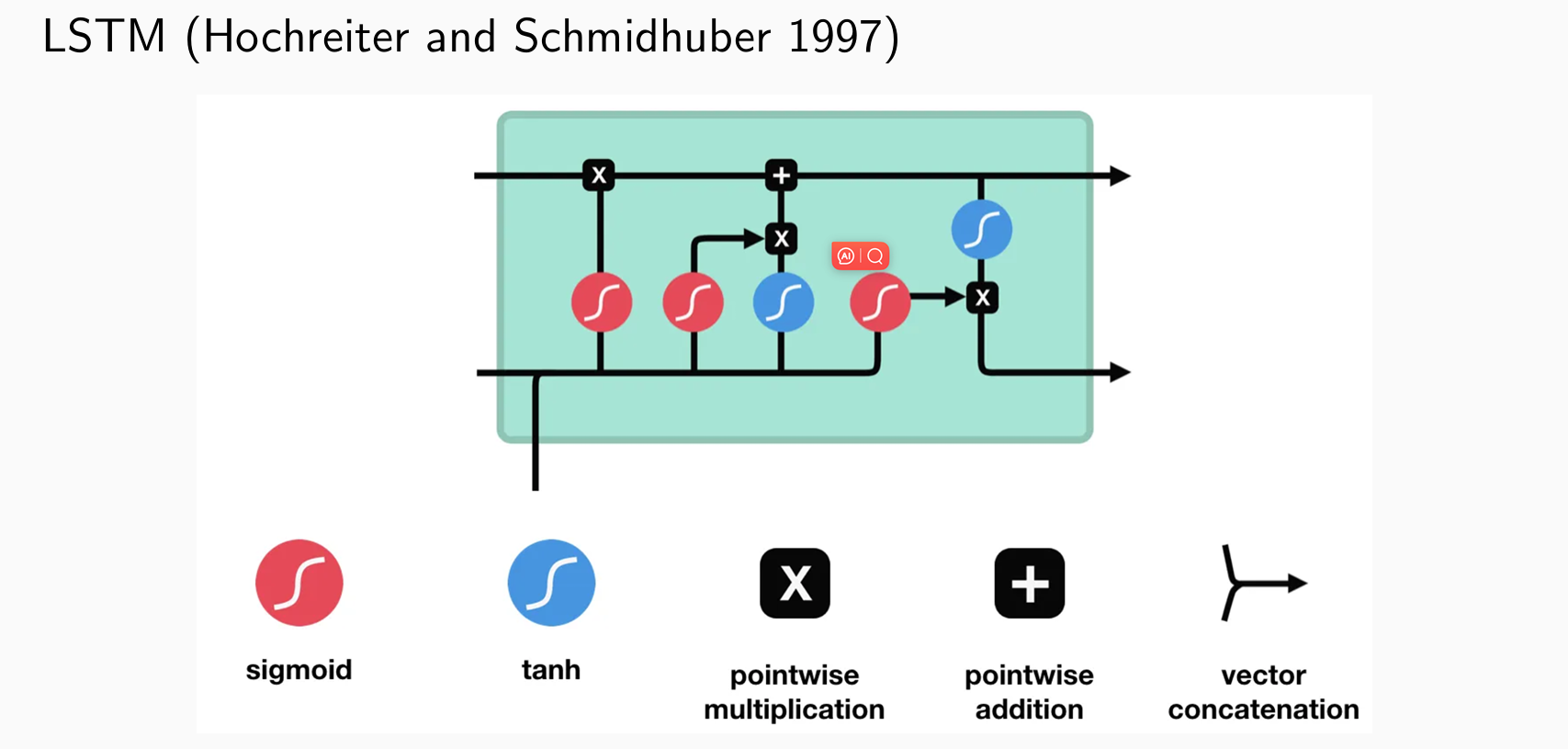
- 引入门控机制:决定是否要遗忘或更新
Gated Recurrent Units
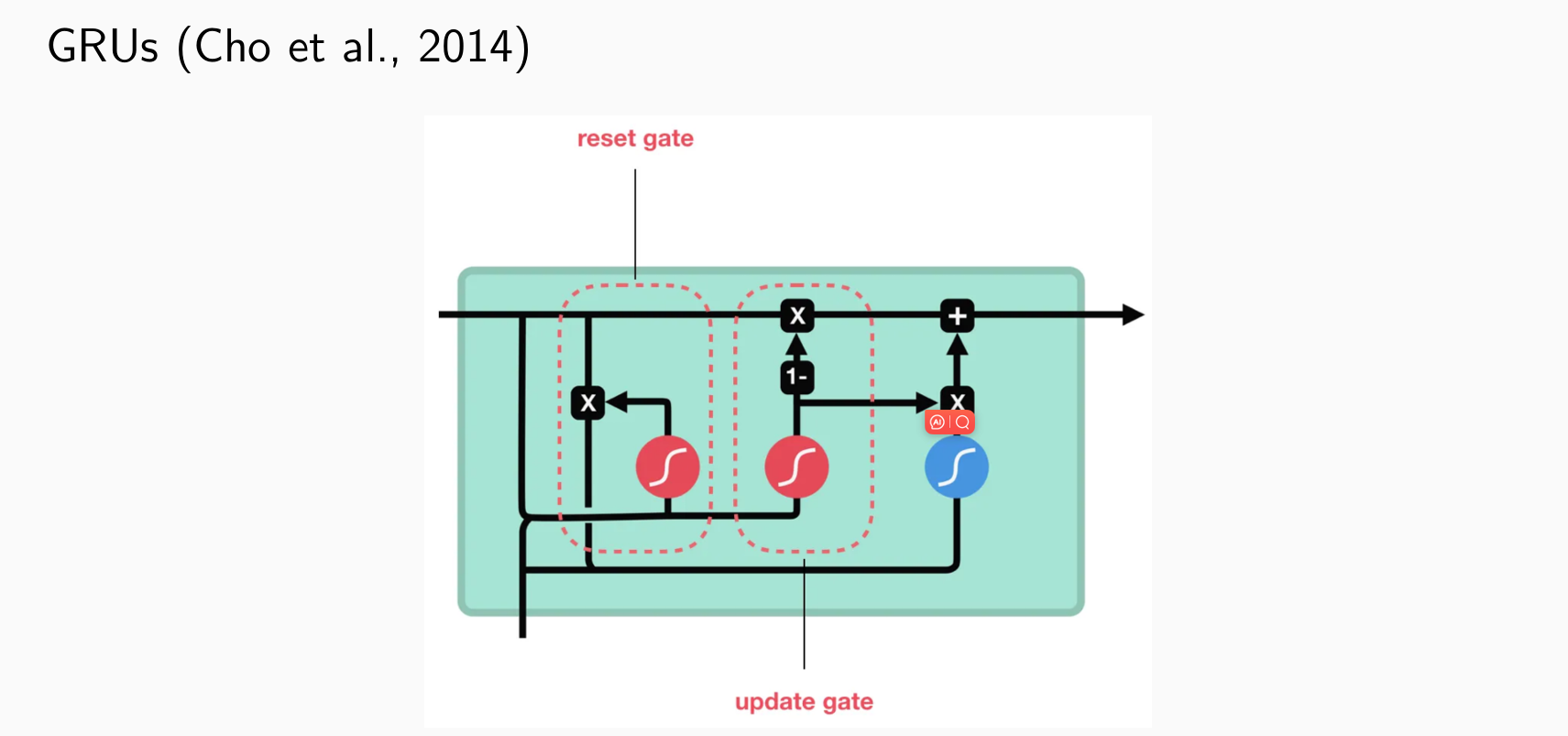
- 两个门控:一个负责如何记忆,一个负责如何遗忘
Contextual Representations
一个词可以有多个不同的含义,说明一个向量表示一个词可能是不够的
Go Deeper:
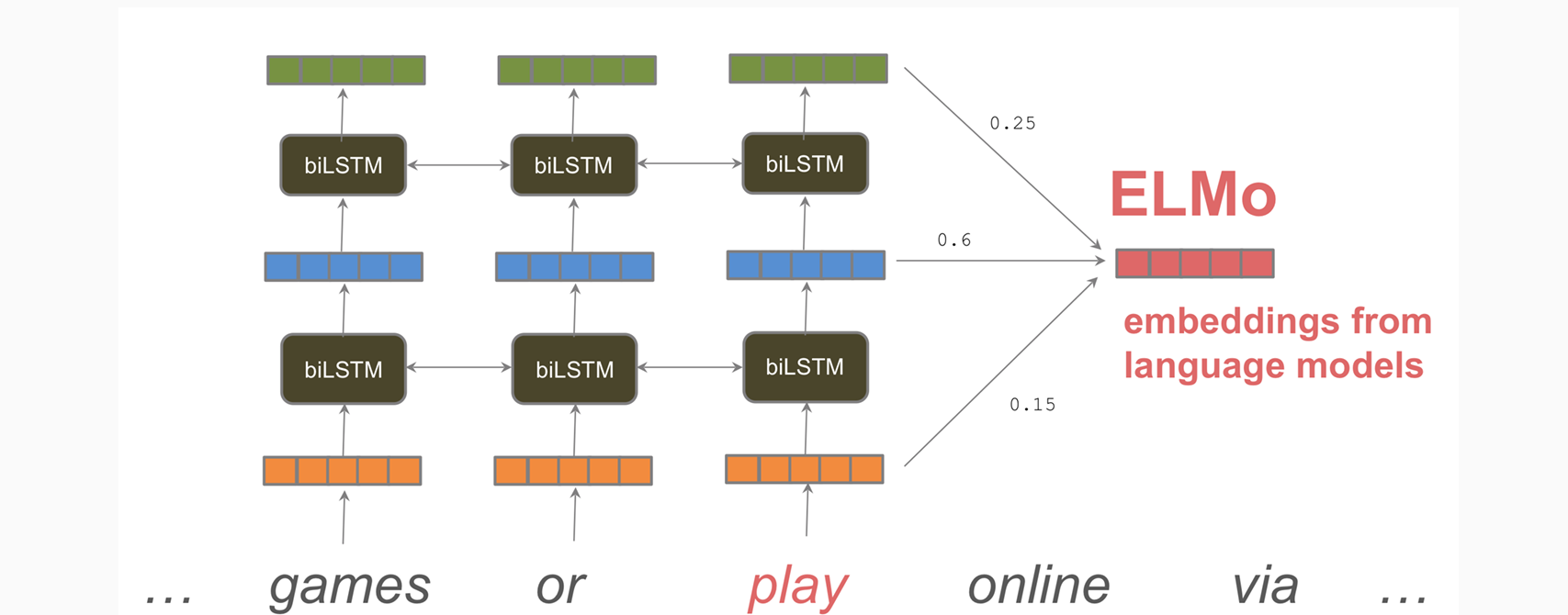
- To train a neural LM: Left-to-Right and Right-to-Left:
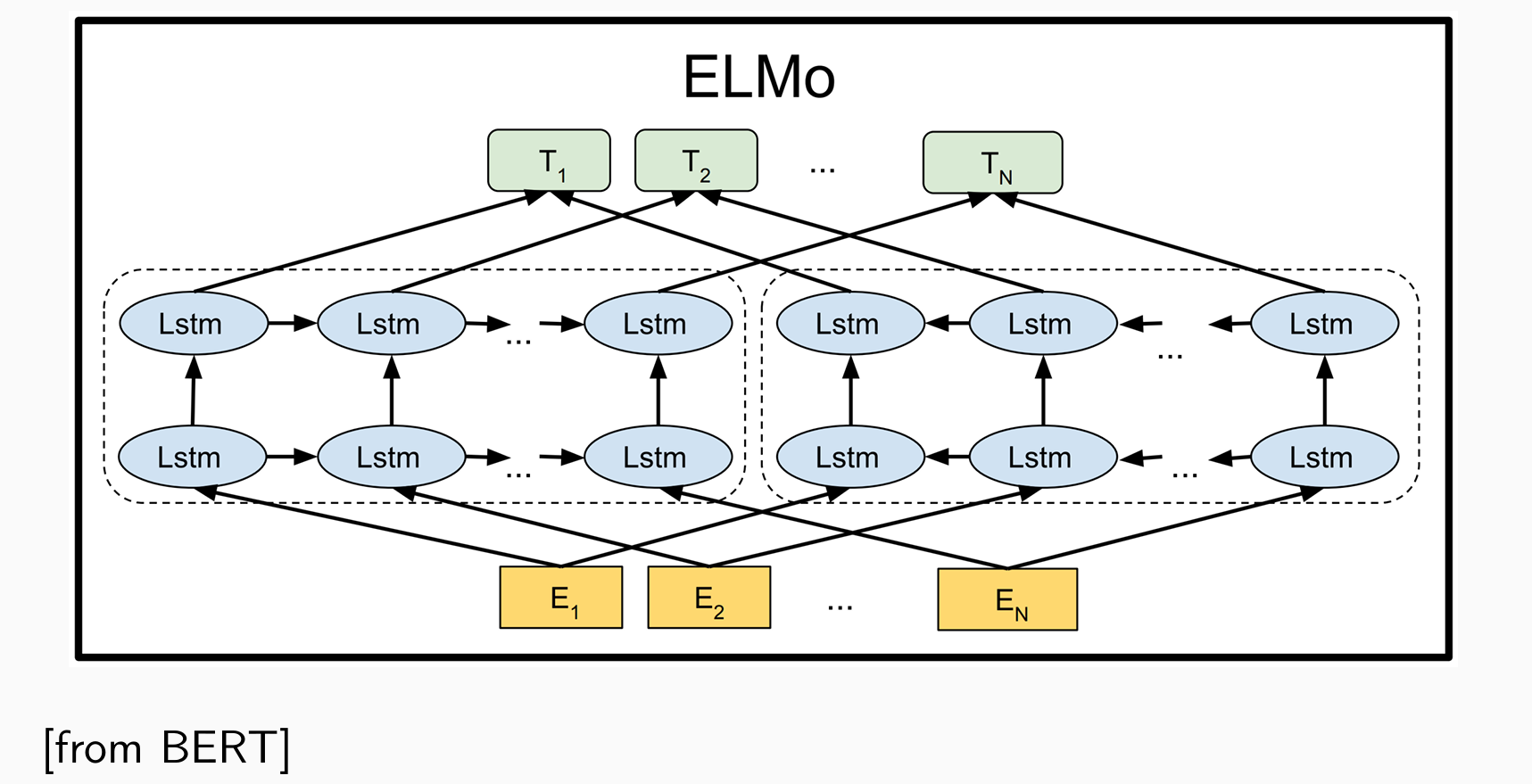
BERT适合做完形填空,给定前后猜中间词
To train a neural LM: Left-to-Right:
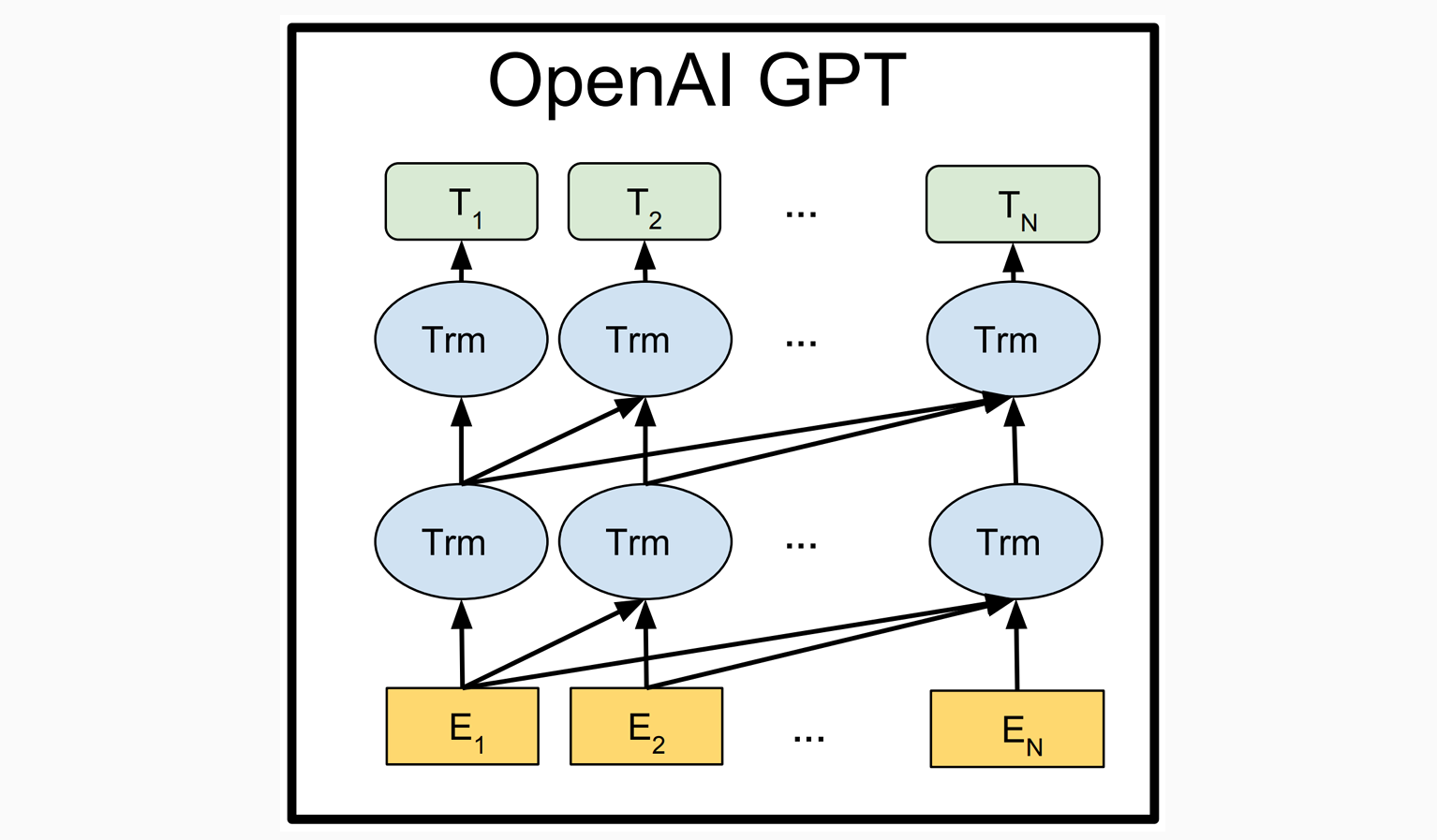
- To train a neural LM: Transfer to other tasks
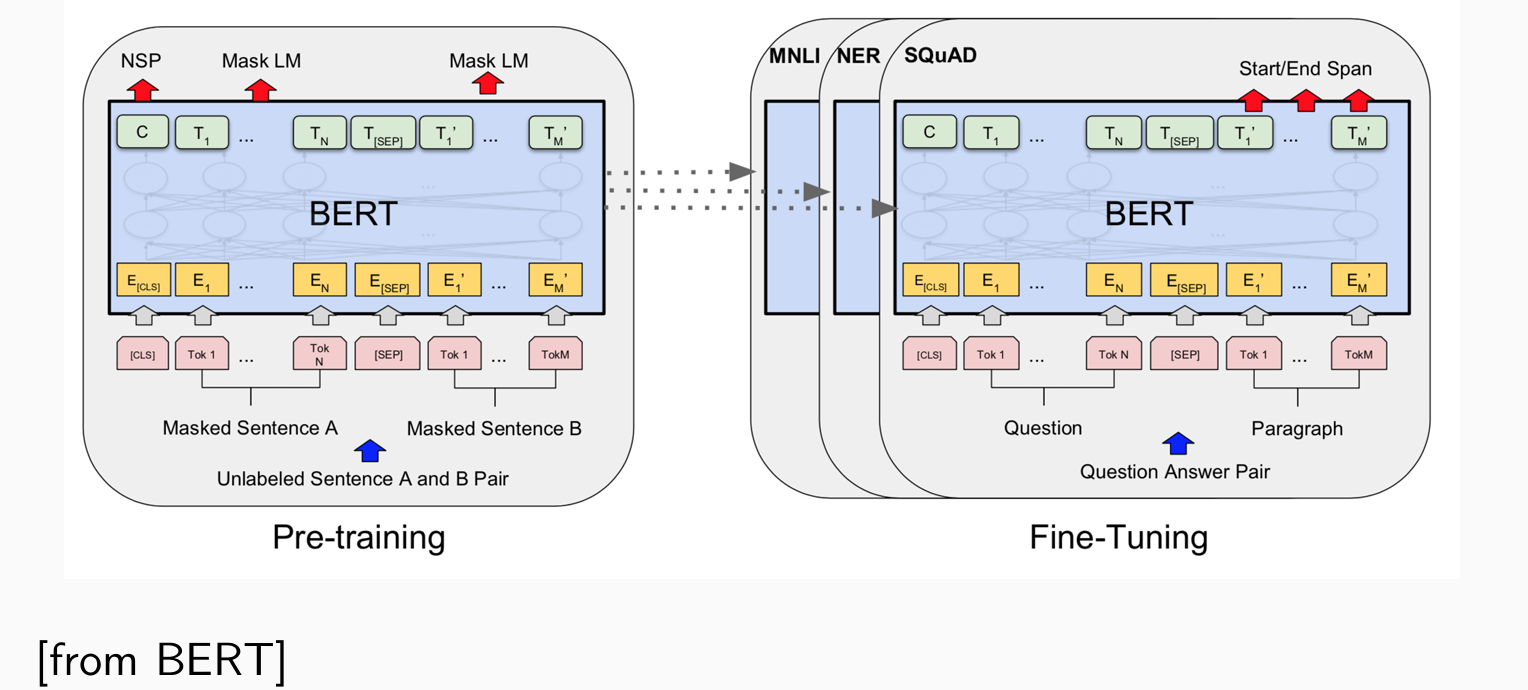
Pre-training:
- Task 1: Masked LM:删除一些词,e.g.30%,让语言模型预测删去的词,说明可以理解语义
- Task 2: Next Sentence Prediction:给定两句话,预测哪句话在前哪句话在后,说明可以理解句子的逻辑以及篇章结构
当参数很大,表示句子能力很强的时候,Task2意义不大
可以习得一些常识性的知识
微调Fine-Tuning需要标注数据