自然语言处理 lec8 dp
Syntactic Analysis II
Dependency Structures
Structures
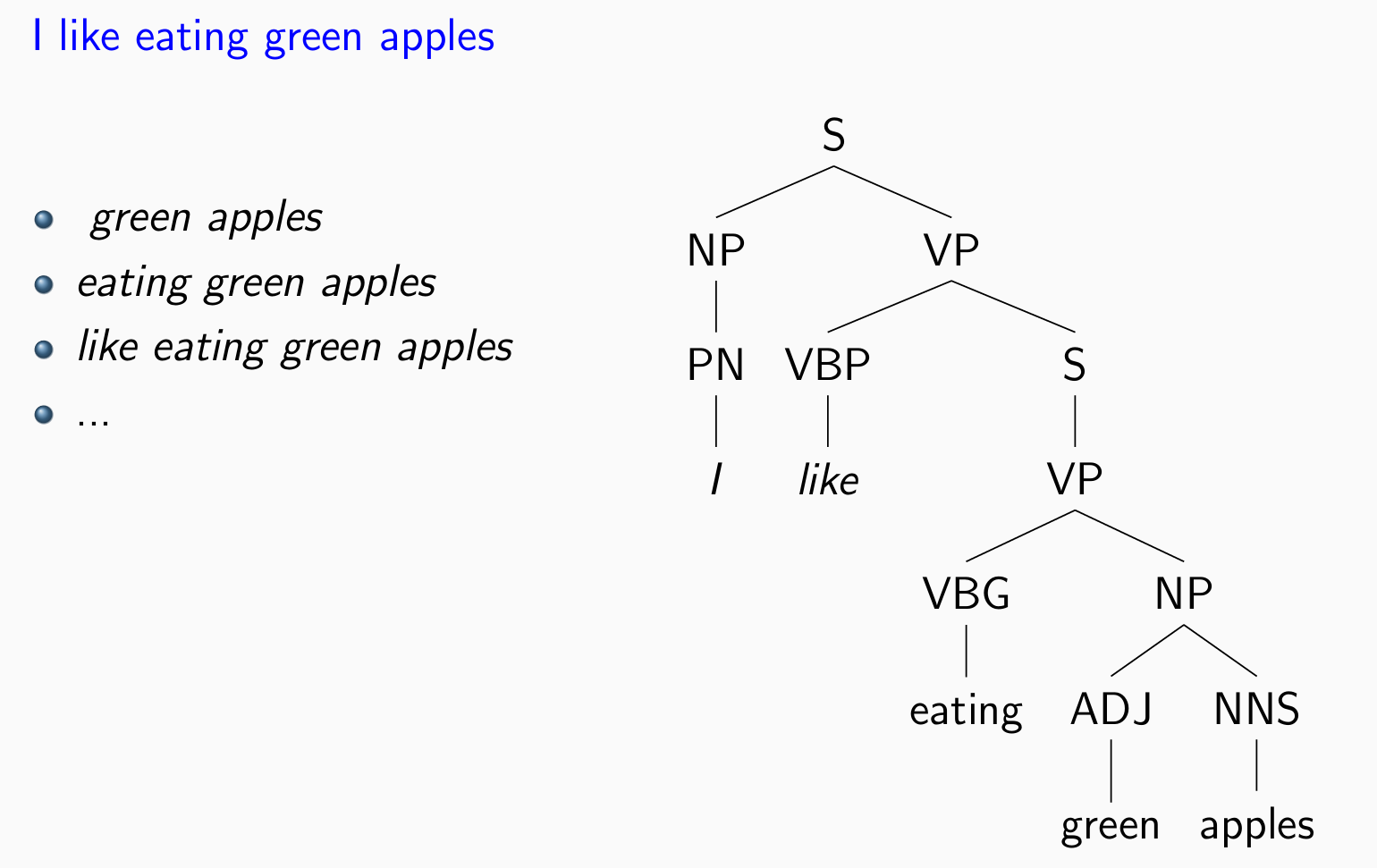
成分树:根据语法,哪个词应该和哪个词合起来
而Dependency则从宏观到微观逐渐观测,什么和什么相关 e.g.我喜欢什么,我喜欢吃什么,我喜欢吃什么样的苹果…
Predicate-Argument Structures(谓词论元):

- 重点考察核心的谓词之间的关系,左边是成分,右边是依存。通过依存关系来刻画意思,角色之间存在重要性的差异
In the words by Lucien Tesni`ere
句子是一个有组织的整体,其构成要素是单词
在单词和它的邻居之间存在联系,这些联系的整体构成了句子的结构
结构连接在单词之间建立依赖关系。原则上,每个连接都结合了一个上级项和一个下级项,单向的,从head -> dependency

- 词法项通过二进制不对称关系链接,称为依赖项
Dependency Structures
Terminology
Superior: Head/Governor(控制作用)
Inferior: Dependent/Modifier(修饰作用)
Dependency Relations: Grammatical Relations
结构 C 中头部 H 和从属 D 之间的句法关系标准:
- H 确定 C 的语法类别;H 可以代替 C
- H 确定 C 的语义类别;D 指定 H
- H 是强制性的;D 可能是可选的
- H 选择 D 并确定 D 是否为必填项
- D 的形式取决于 H
- D 的线性位置是参照 H 指定的
Dependency Relations
语法关系是二元的非对称的,描述head和dependency之间的功能或类型
从属对象对其头部起的语法作用:
- I is the subject of like
- apple is the direct object of like
有许多不同的依赖关系系统
the Universal Dependencies (UD) project:
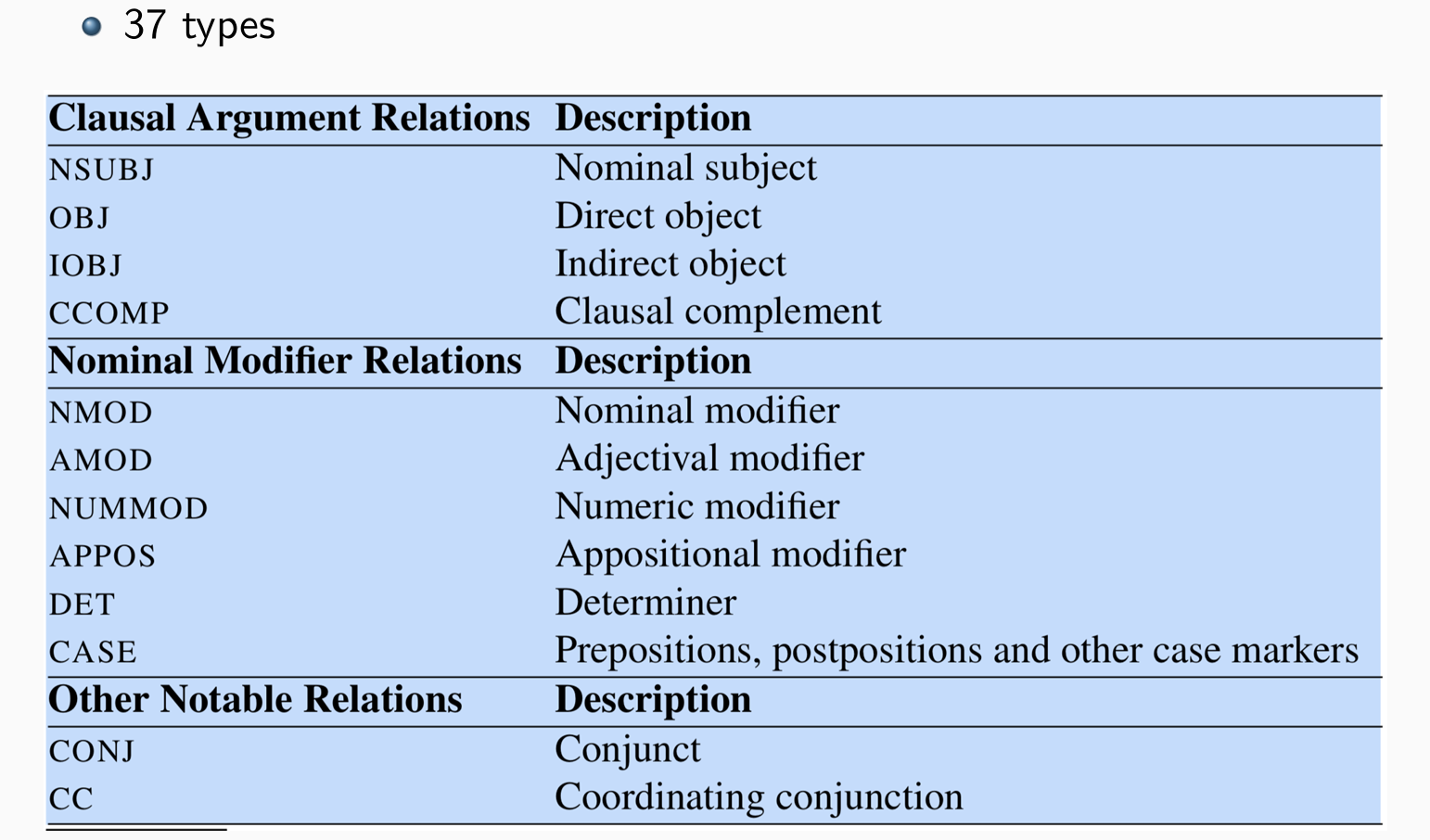
- Notations:
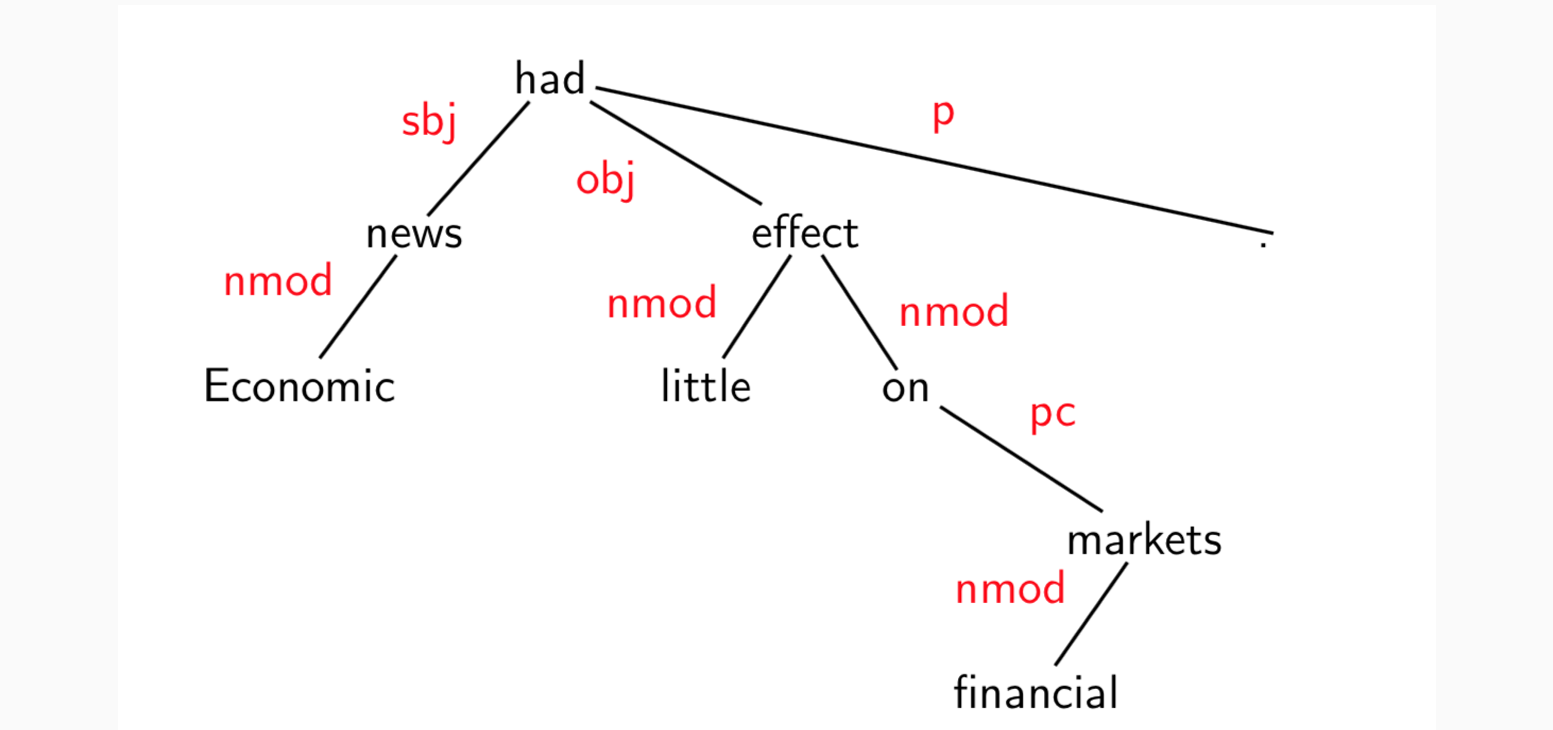
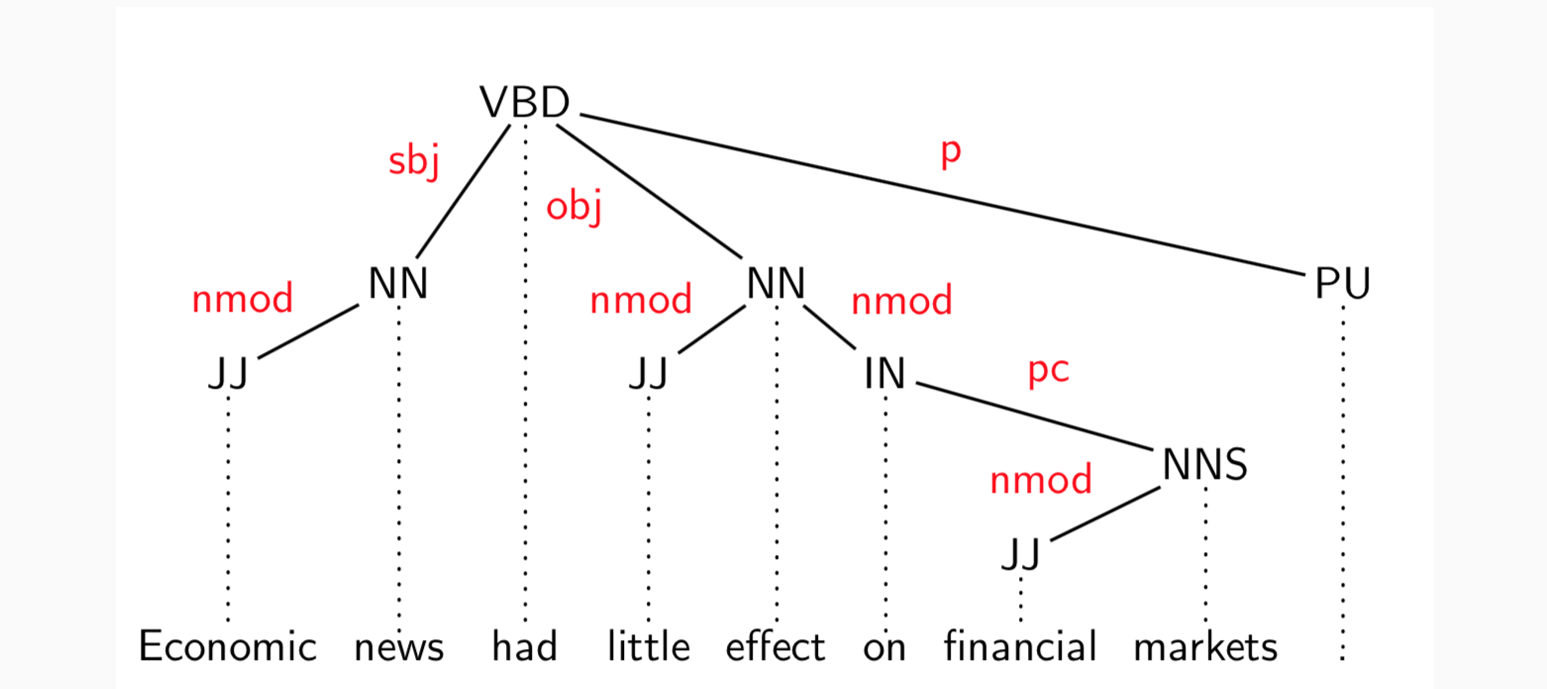
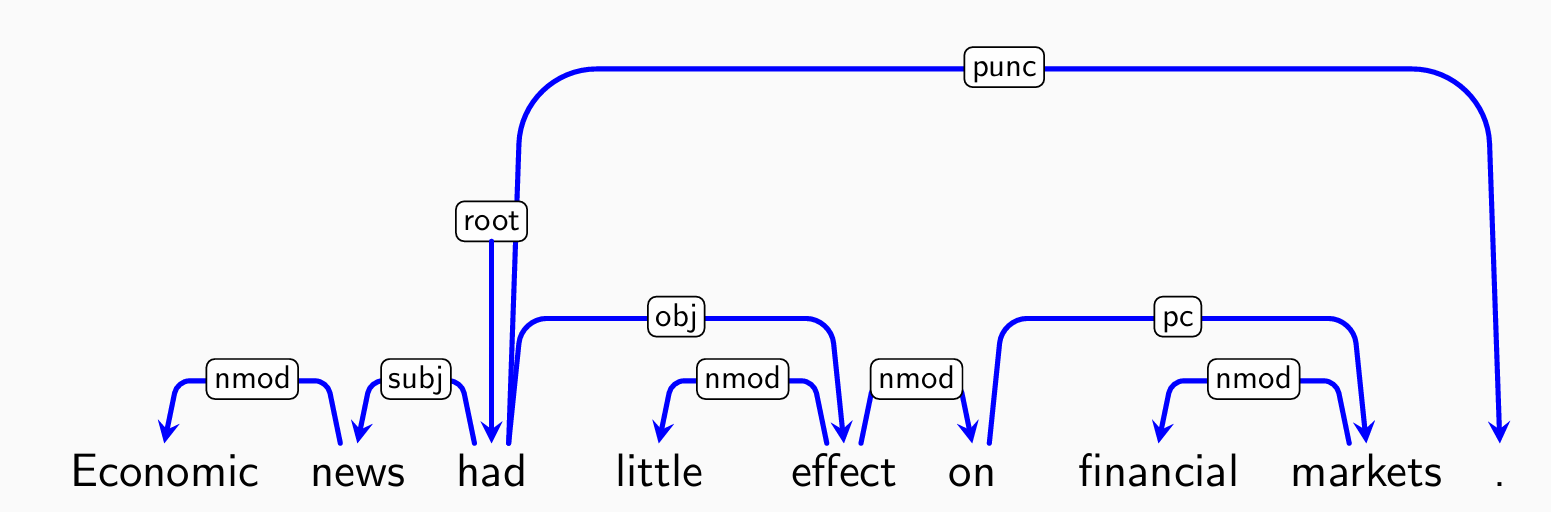
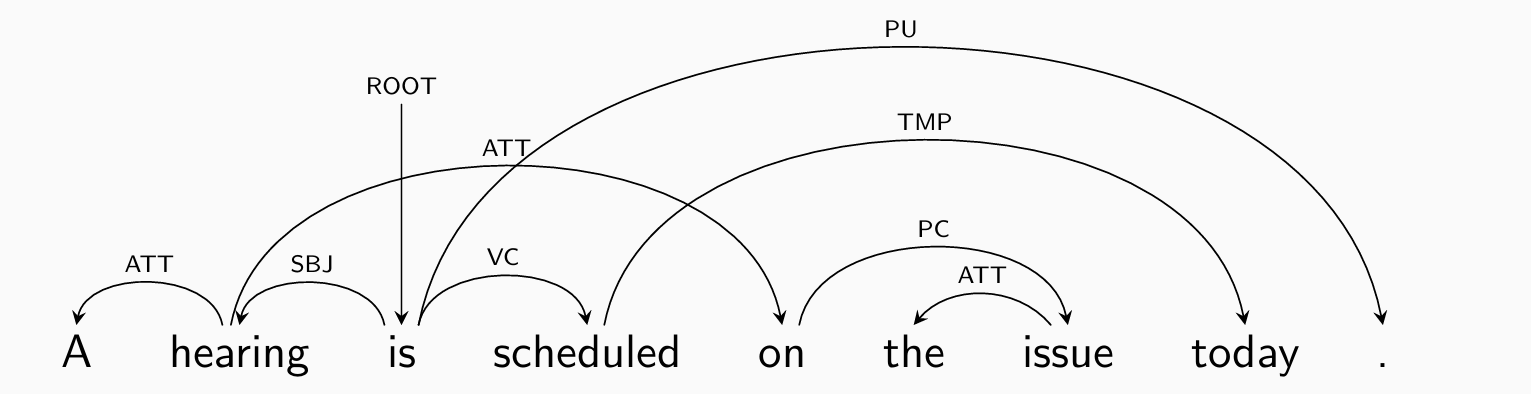
注意:标点符号直接连到根结点,也是句子的一部分
句式结构依赖关系可能并不是树,例如:
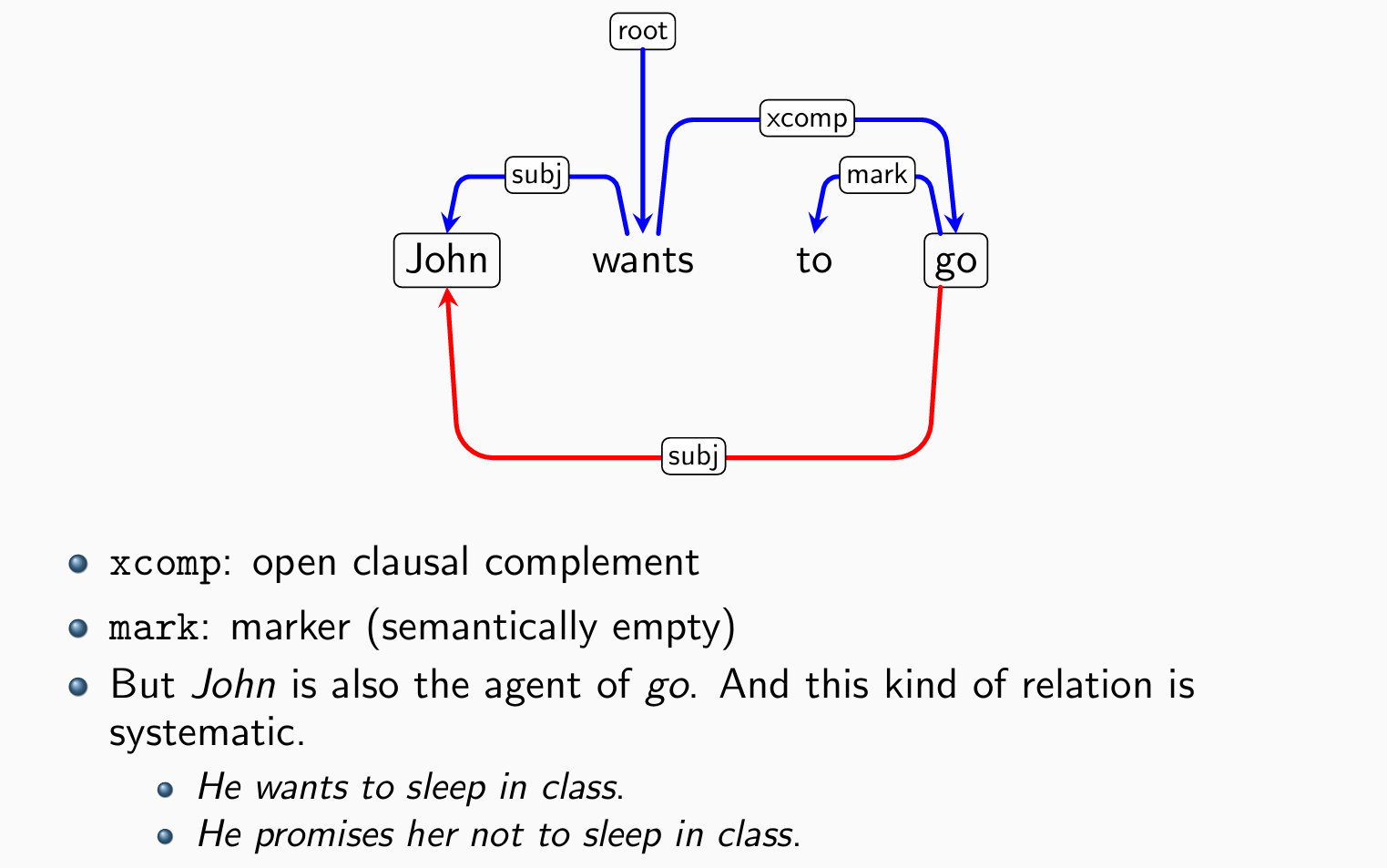
Dependency Graph
依赖关系结构可以定义为有向图,包括
- 点(句子的词和标点符号)
- 边
- 方向(head -> dependence)
Labeled graphs:
- 节点使用单词形式(和注释)进行标记
- 边使用依赖关系类型进行标记
性质:
- 弱连通:对于每个节点 i,都有一个节点 j,使得 i → j 或 j → i,不可能有孤立的结点
- 无环
- single-head只有一个父结点
- 父结点不超出左右范围(projective)
Projectivity
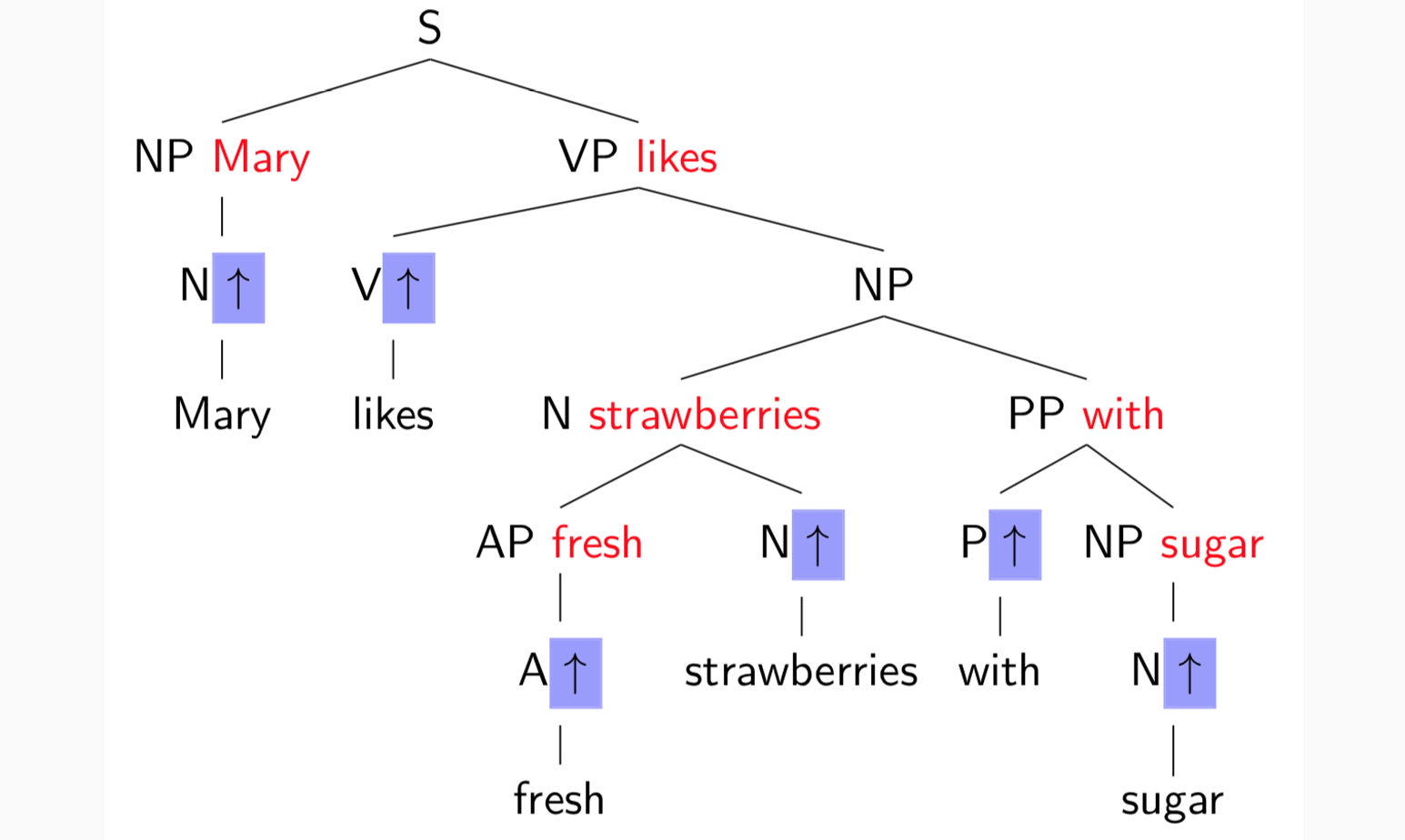
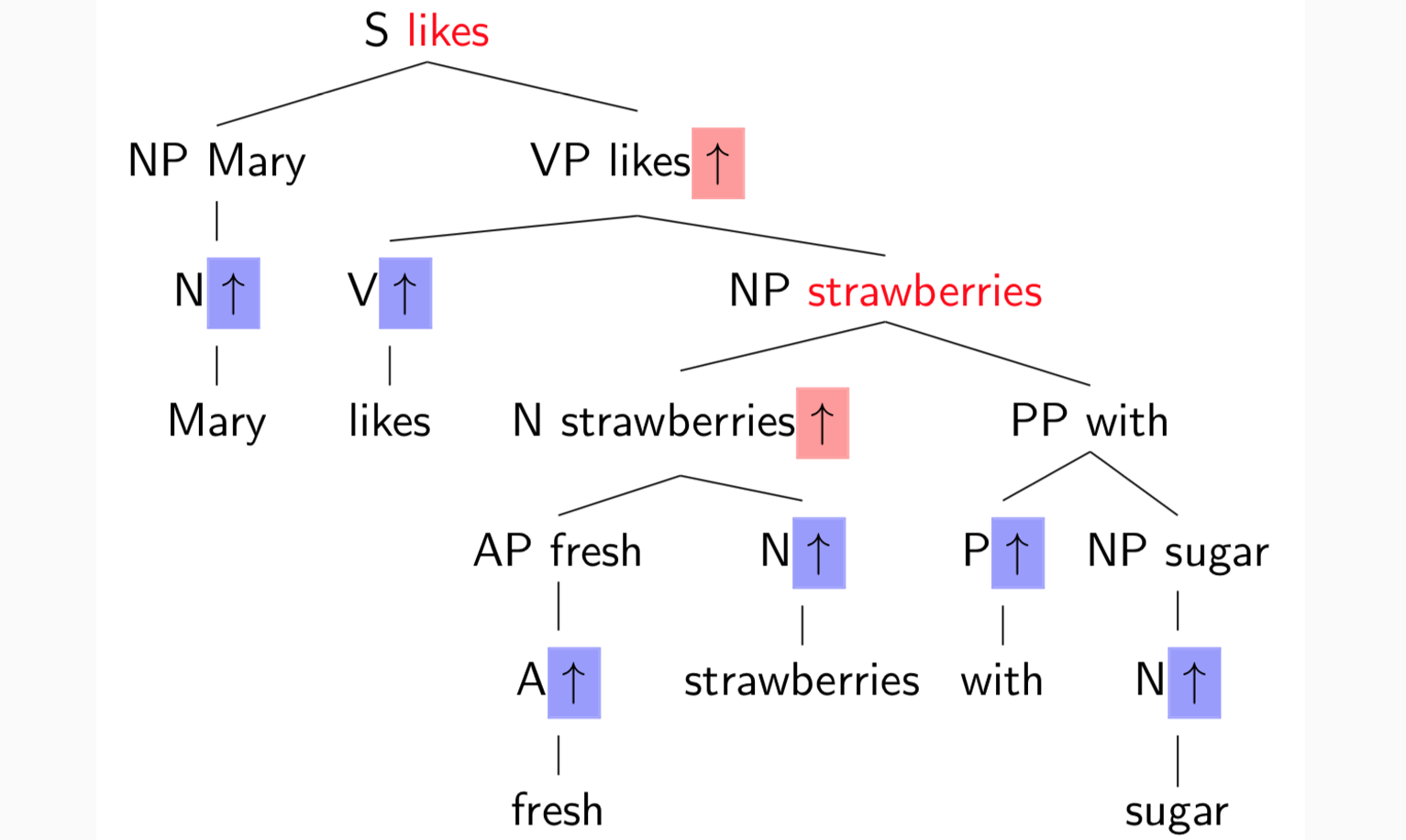
红色为head,核心词
树下面的修饰树上面的,句子理解中可以删去,则为projective
依赖关系树是投影的:如果 wi → wj,则 wi → …→ wk,对于任何 k,使得 wk 位于 wi 和 wj 之间,没有交叉边
这是一个非投影依赖树:(存在交叉边)
projective更容易解析
大多数理论框架不假设投射性
需要考虑非投影结构(灵活的语言):用dependency结构比短语结构好
- 长距离依赖
- 自由语序,修饰词被修饰词的位置关系
Dependency Structures v.s. Phrase Structures
Dependency structures:更灵活,有向,有类型,直观上更接近语义,对词序变化更适应
Phrase structures:关心短语,关注nonterminal label,含有语法功能
Dependency Treebanks:许多以前的依赖结构注释是从短语结构自动转换而来的,例如 Penn Treebanks
Dependency Parsing(依赖项解析)
Incrementality in Human Language Comprehension
Self-paced Reading:人类看句子的时候是一个字一个字看,逐步加工的过程,像键盘输入一样
Garden-path Sentences:Garden-path Sentences是语法正确的句子,其开头方式使读者最有可能的解释是错误的;读者被引诱到一个解析中,结果却是一条死胡同,或者产生了明显意想不到的含义

分析过程中要保留分析过程,以及各种可能性,需要考虑历史
Linguistic performance:
- 从左到右,逐字逐句
- 部分解析的结果 (history) 限制后续单词的解析
- 通常执行贪婪搜索以获得良好的解析
Linguistic Structure Predictions
As a structured prediction problem:
- word: single classification
- word sequence: a linear chain of classifications
- trees, graphs, …: searching a structure with many classifications
Two views for structured prediction
- 离散优化:定义评分函数并寻找得分最高的结构体(dependency graph不可行)
- the Viterbit Algorithm
- the CKY Algorithm
- incremental search:搜索的状态是目前构建的 partial structure;每个作都以增量方式扩展结构
- 通常是贪婪搜索,分类器决定在每个状态中采取什么动作
- 通过 Beam Search 进行改进
- 离散优化:定义评分函数并寻找得分最高的结构体(dependency graph不可行)
As a structured prediction problem:
- Search space
- Measurement
- Decoding:查找获得最高分的分析
- Parameter estimation

Transition-Based Dependency Parsing
- 任务:输入为一句话;输出为一个边集,表明结点间的指向
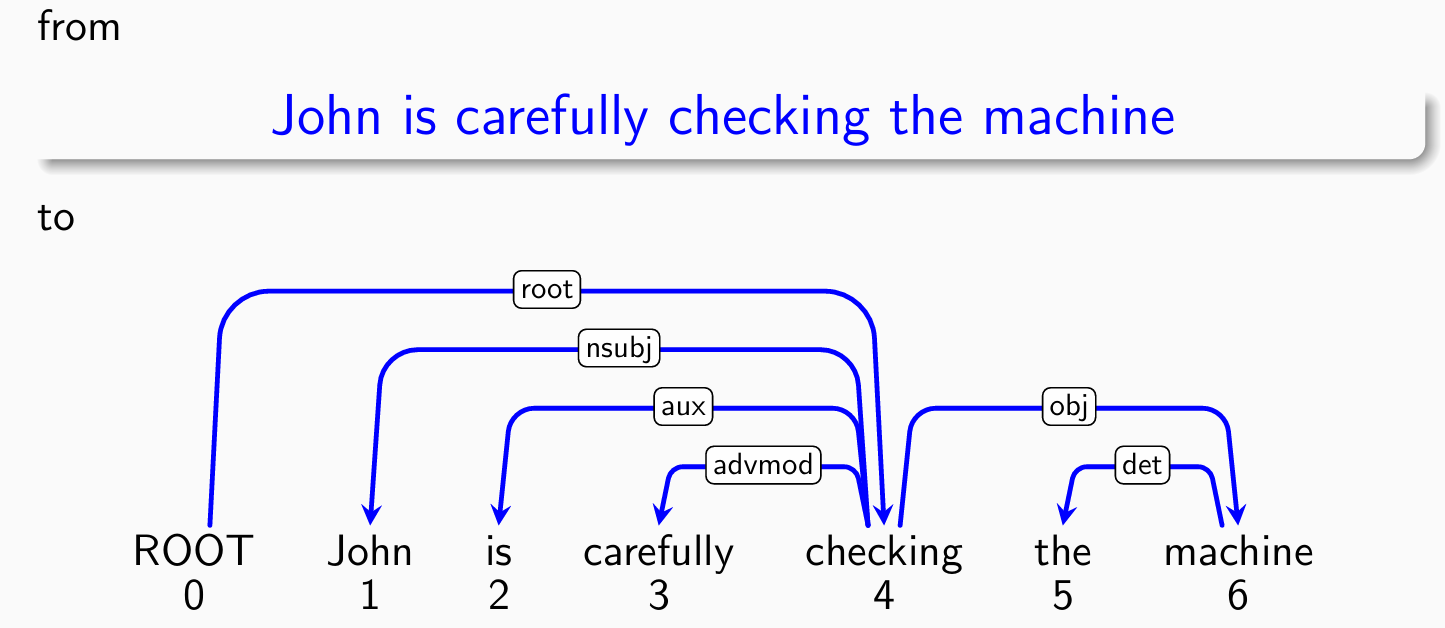
是一种有限状态自动机
用于解析的转换系统是四重 S = (C,T,cs,Ct),其中
- C 是一组状态,每个状态都表示一个解析器状态
- T 是一组过渡,每个过渡代表一个解析动作
- cs 通过将句子 x 映射到特定状态来初始化 S
- Ct ⊆ C 是一组终止状态
问题:
- C包含什么?
- T做什么动作才能朝结束状态运转?怎么定义动作?
Deterministic parsing:
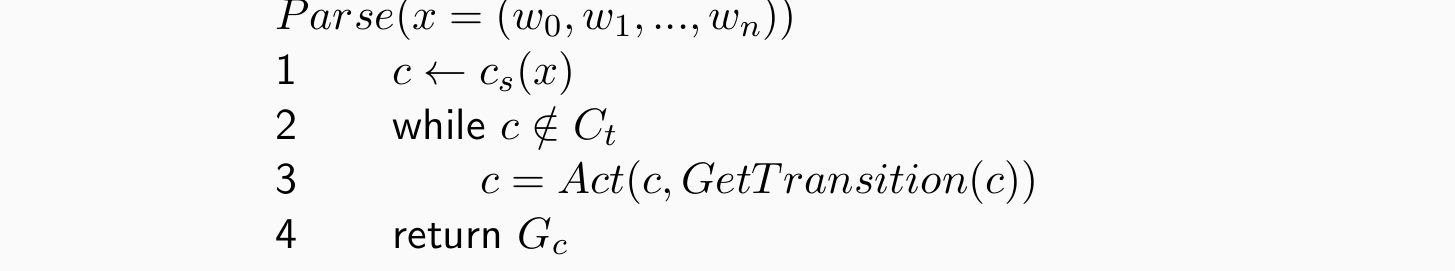
核心:GetTransition(获取该做什么动作的分类器),动作分类器
An oracle for a transition system S = (C,T,cs,Ct)。o : C → T,得到的结果定义为oracle
给定 S 和 o,确定性解析动作为:
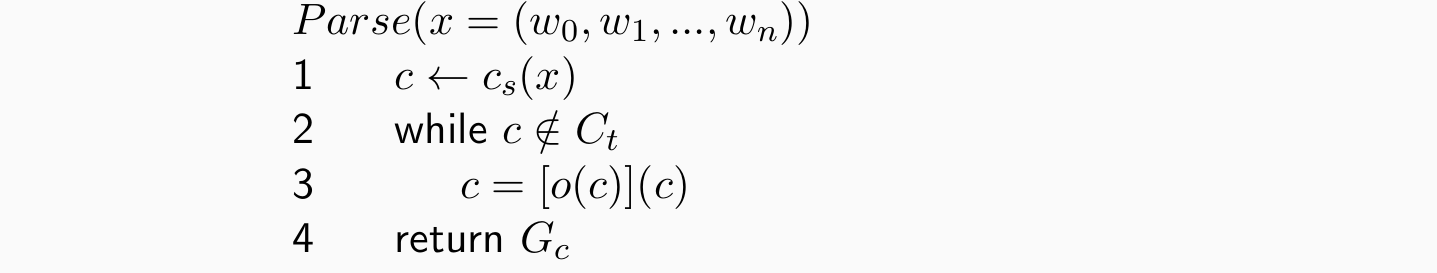
- Oracles可以被分类器估计:
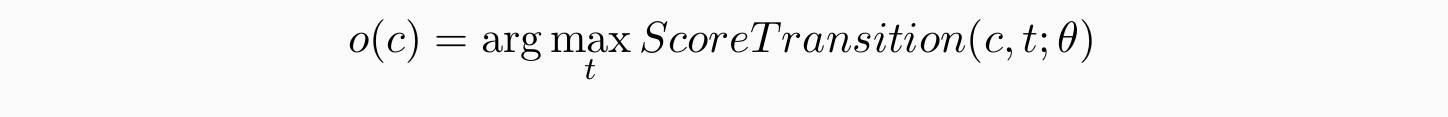
- GetTransition(c)的 Basic idea:
- 定义一个转移系统(状态机),用于将句子映射到其解析动作
- 学习:在给定当前状态的情况下,诱导一个模型来预测下一个动作(状态转换)
- Parsing:给定诱导模型,构建最佳转换动作序列
Stack-based Transition Systems
句子 x = w0,w1,…,wn 的基于堆栈的状态是四元组 c = (x,σ,β,A),其中:
- σ 是一个stack存放 i ≤ m 的标记(m ≤ n)(已经看过的tokens但是还没做决定是什么意思,考察栈顶元素和当前词的关系来决定是否出栈)
- β 是tokens j > m 的buffer(队列,先进先出)
- A 是一组依赖关系边,因此 G = (0,1,…,n,A) 是 x 的依赖关系图。存储已经处理过的集合
基于堆栈的转换系统是四重 S = (C,T,cs,Ct),其中
- 是所有基于堆栈的状态的集合
- cs(x = w0,w1,…wn) = ([0],[1,…,n],∅)
- T 是一组动作转移,每个转移都是一个状态转移函数 t : C → C
- Ct =c∈C|c =(σ,[],A).
The Arc-standard Transition Algorithm
Transitions:
- Shift(把buffer中的i拿到栈顶中):(σ,i|β, A) ⇒ (σ|i,β,A)
- Left-Arck(连线j到i加入边集A,j是buffer中正在考虑的词,i是栈顶,连线后弹出栈顶,i是j的child):(σ|i, j|β, A) ⇒ (σ,j|β,A ∪ {(j,i,k)})
- Right-Arck(连线i到j加入边集A,j是buffer中正在考虑的词,i是栈顶,连线后buffer移除,j是i的child):(σ|i, j|β, A) ⇒ (σ,i|β,A ∪ {(i,j,k)})
σ|i = stack with top i
i|β = buffer with next token i
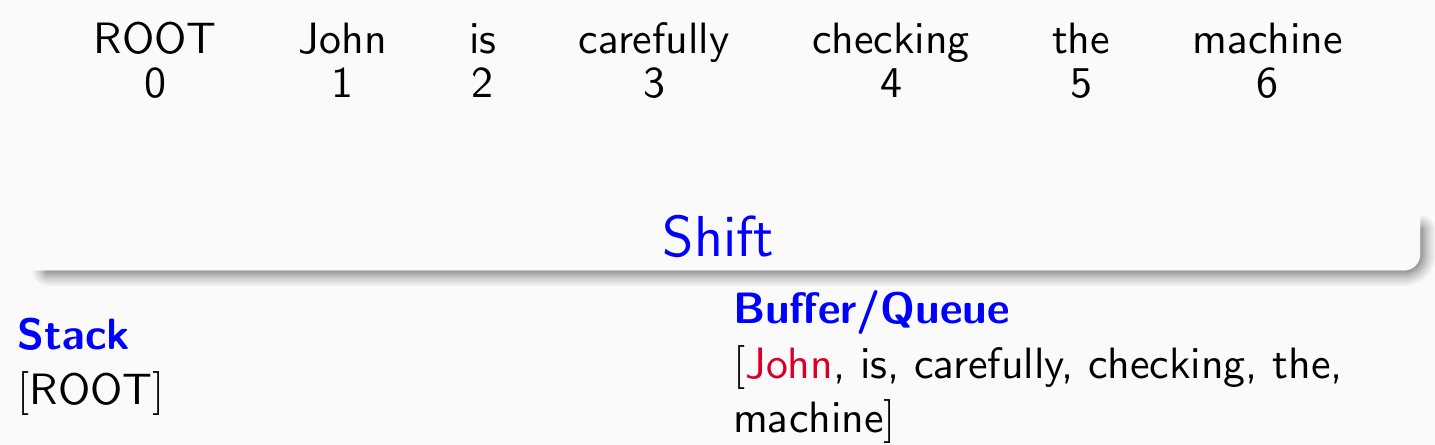
Example: Arc-standard algorithm
- 初始状态如图:

- 考察第一个单词John,分类器给出shift操作:
- 考察第二个单词is,分类器给出shift操作:

- 考察第三个单词carefully,分类器给出shift操作:
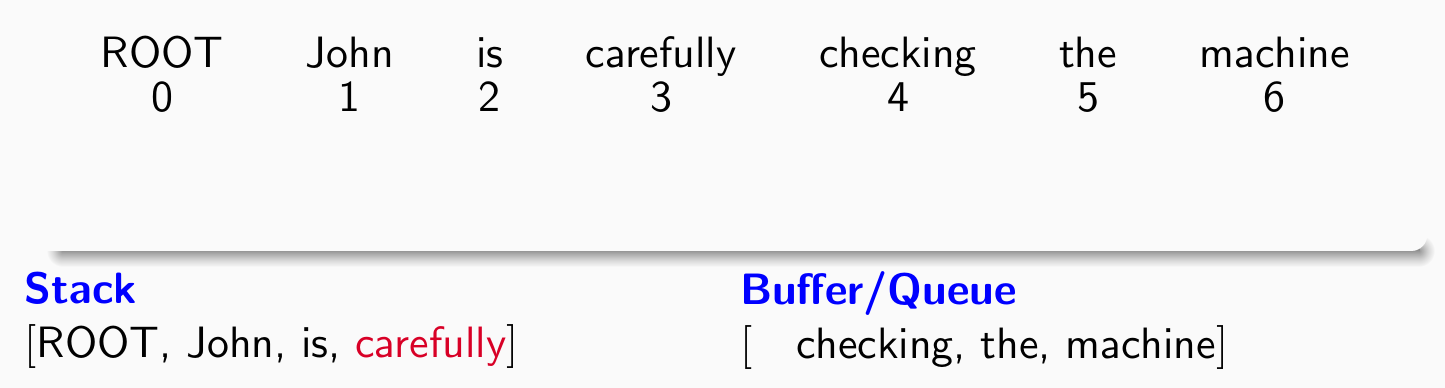
- 考察第三个单词checking,分类器给出left-arck(buffer -> stack)操作:
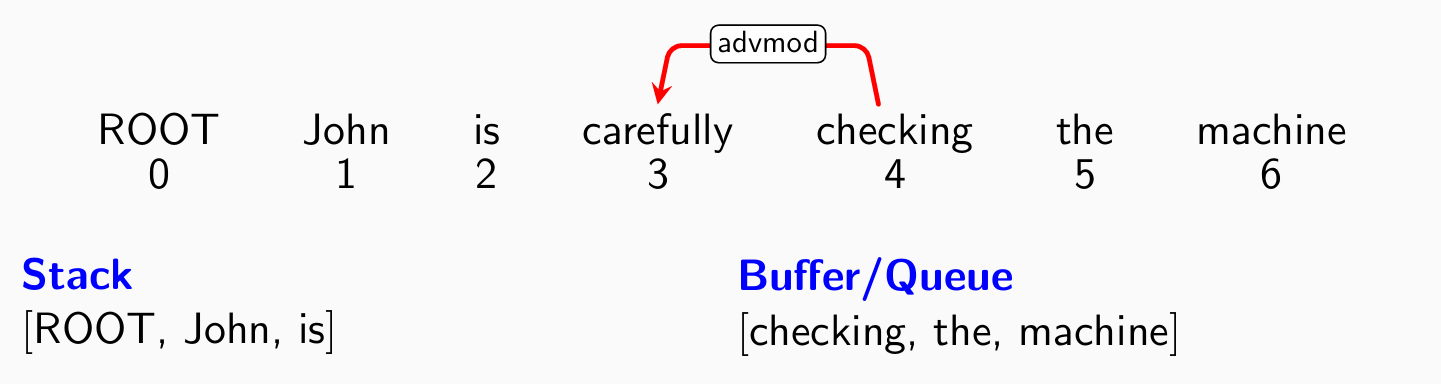
- 考察第三个单词checking,分类器给出left-arck(buffer -> stack)操作:
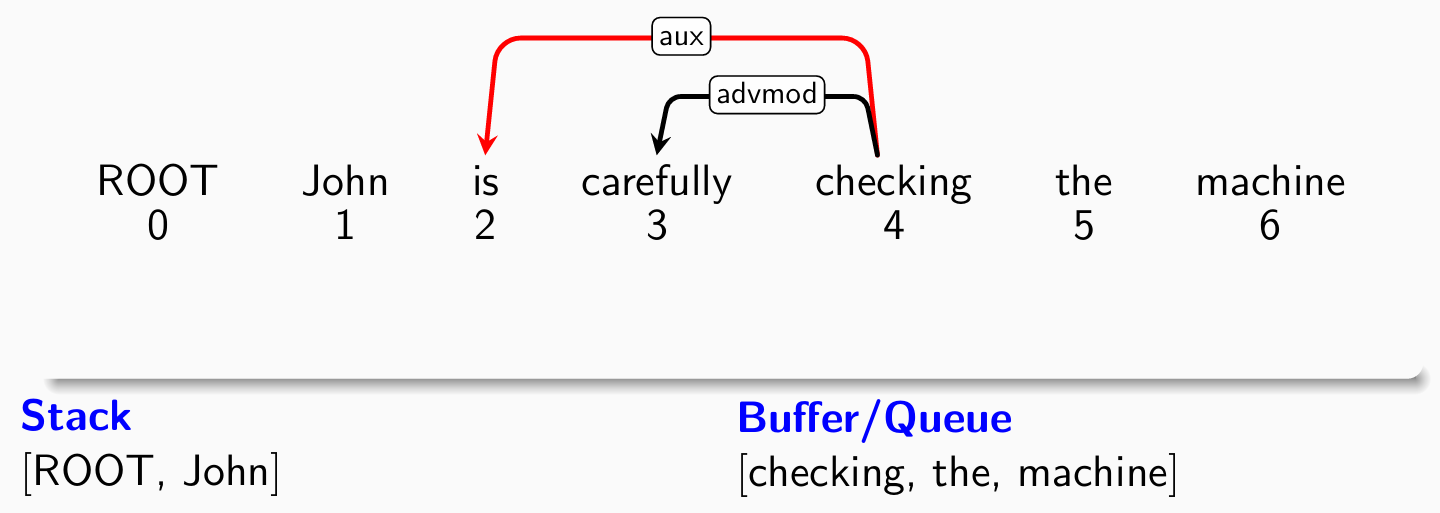
- 考察第三个单词checking,分类器给出left-arck(buffer -> stack)操作:
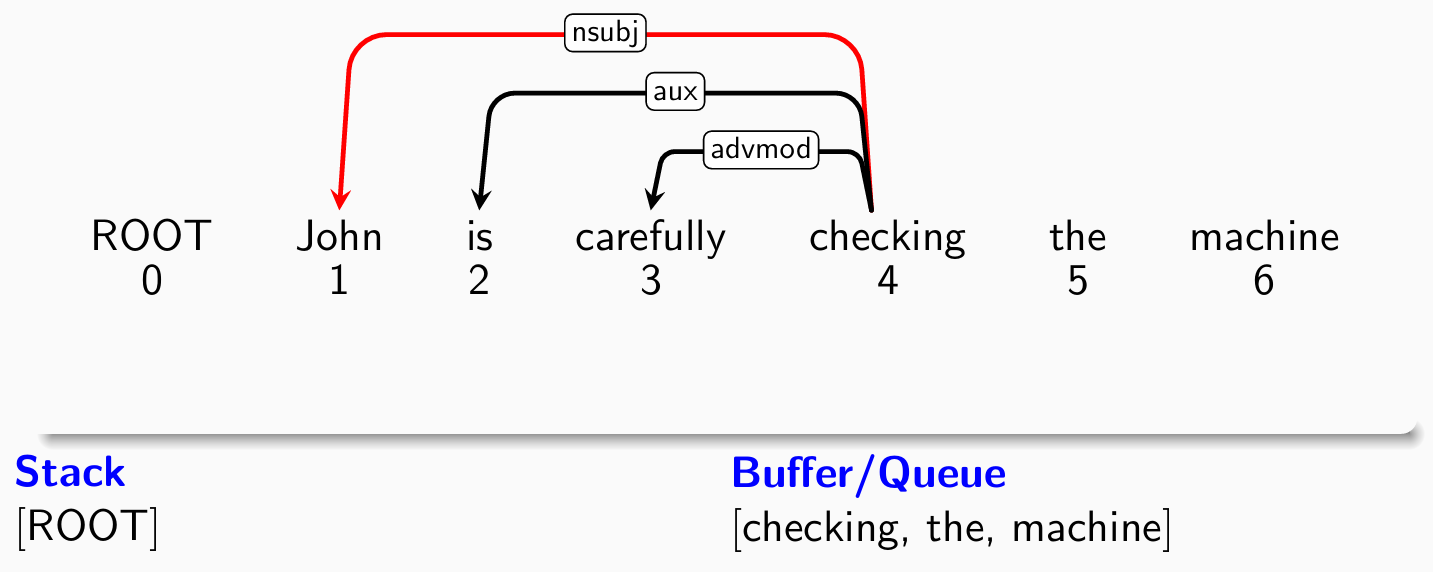
- 考察第三个单词checking,分类器给出shift操作:
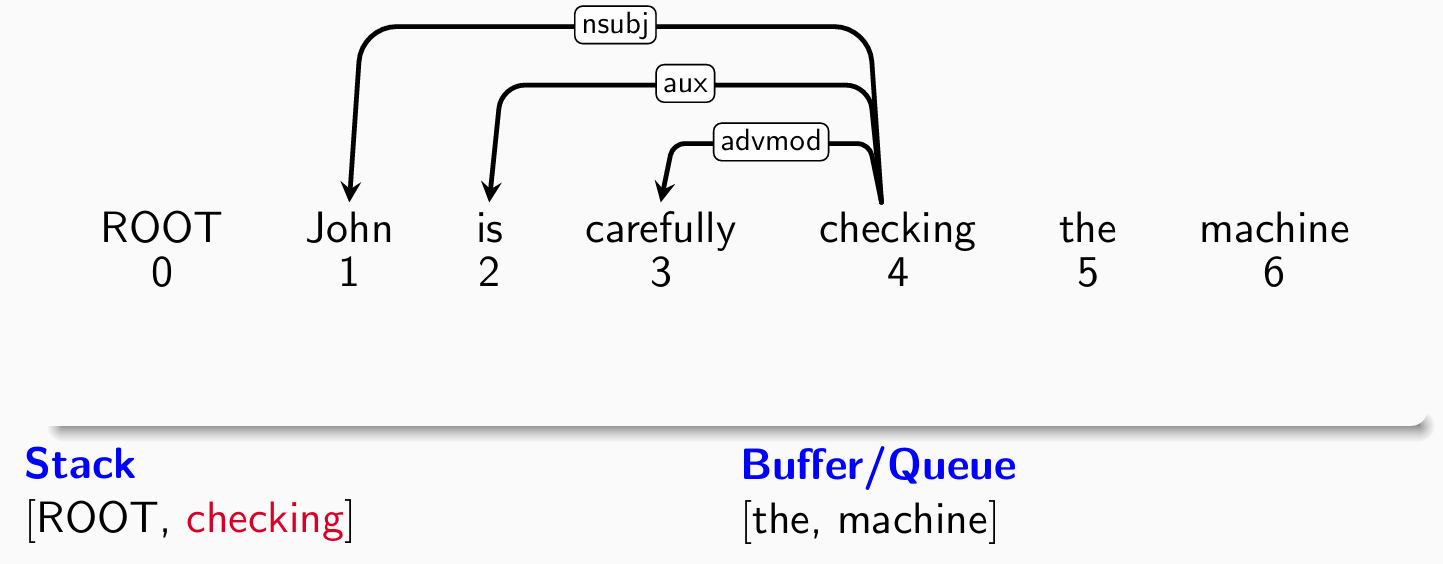
- 考察第四个单词the,分类器给出shift操作:
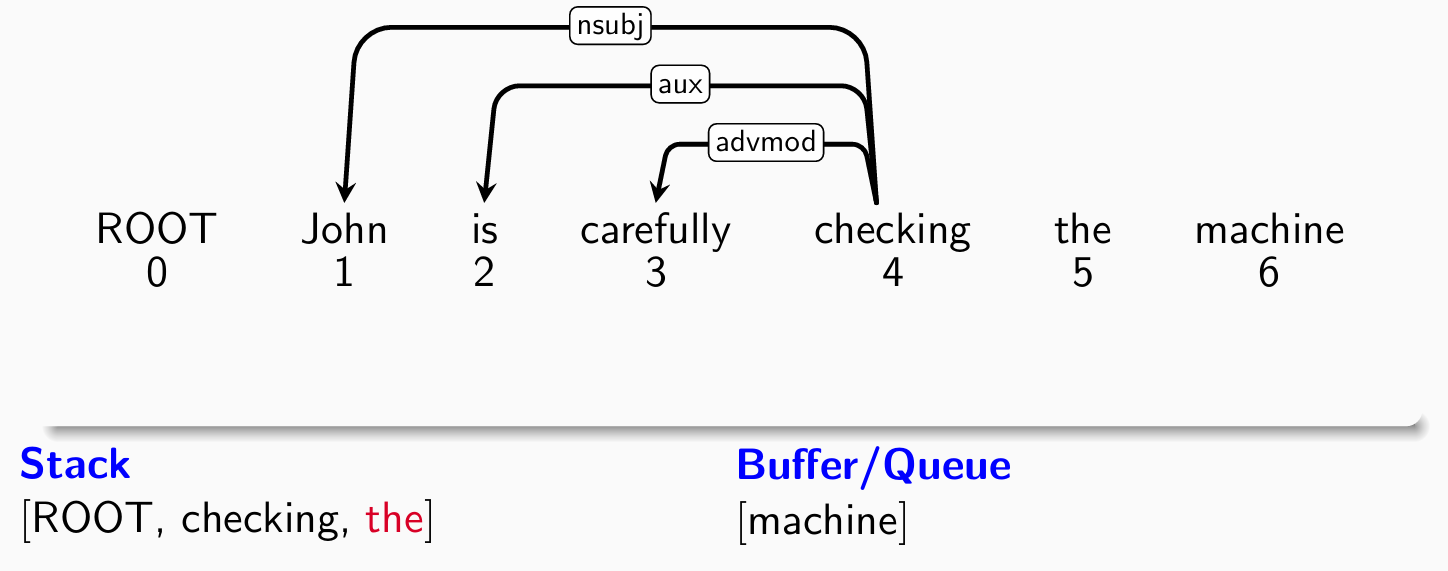
- 考察第五个单词machine,分类器给出left-arck(buffer -> stack)操作:
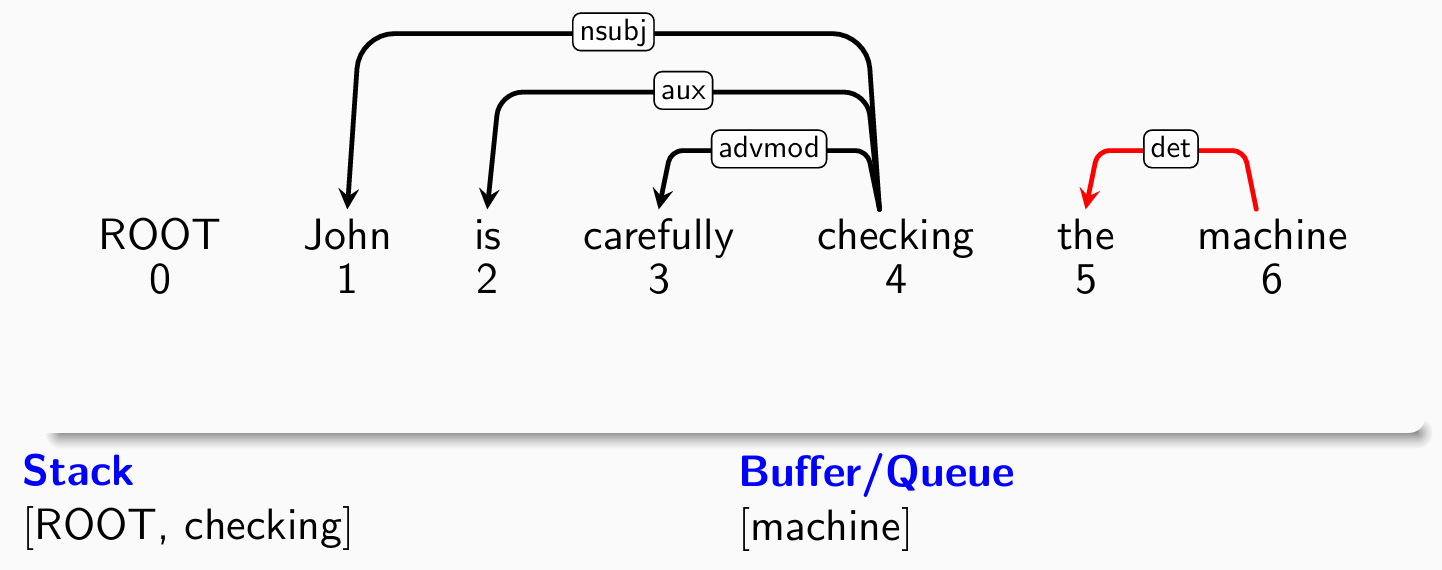
- 考察第五个单词machine,分类器给出right-arck(stack -> buffer)操作:
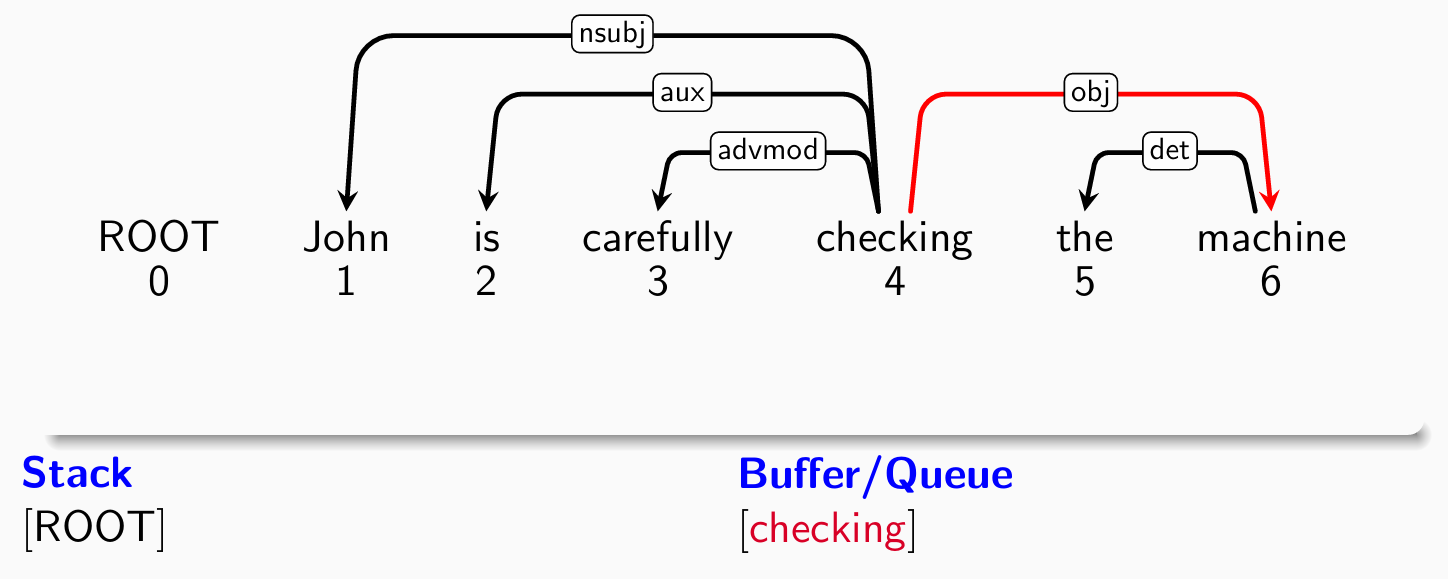
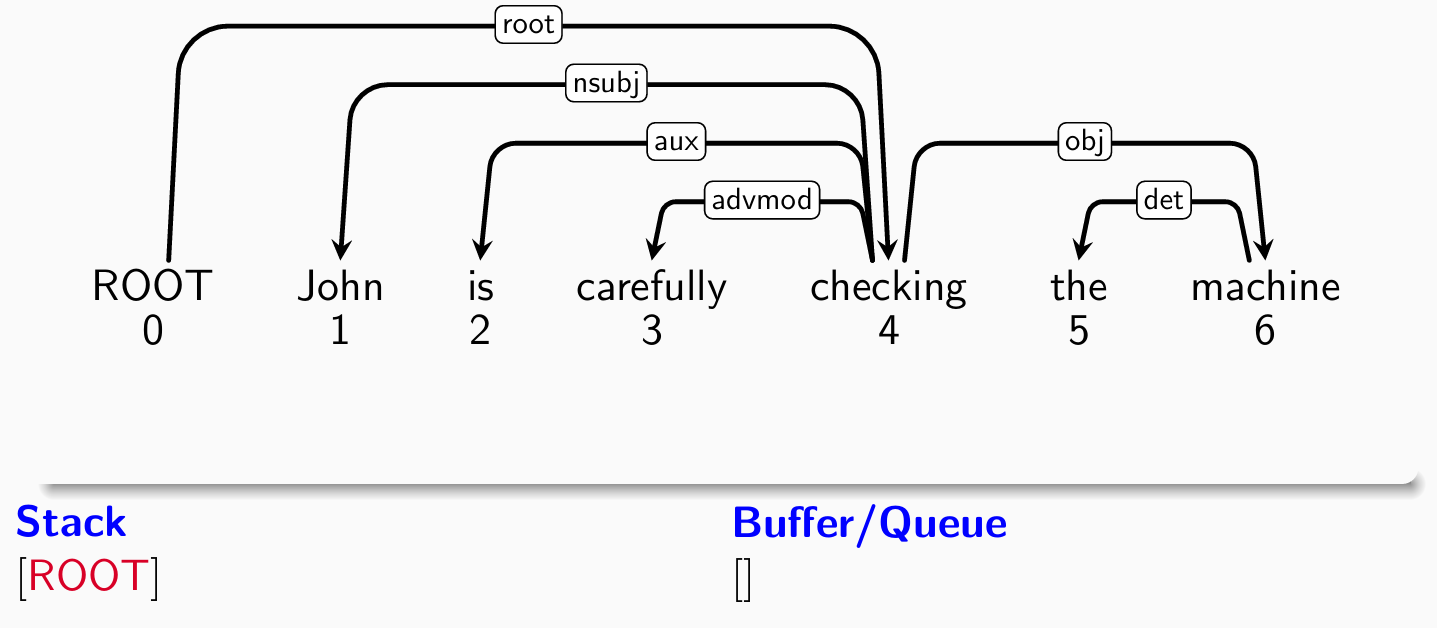
- 考察第四个单词checking,分类器给出right-arck(stack -> buffer)操作:
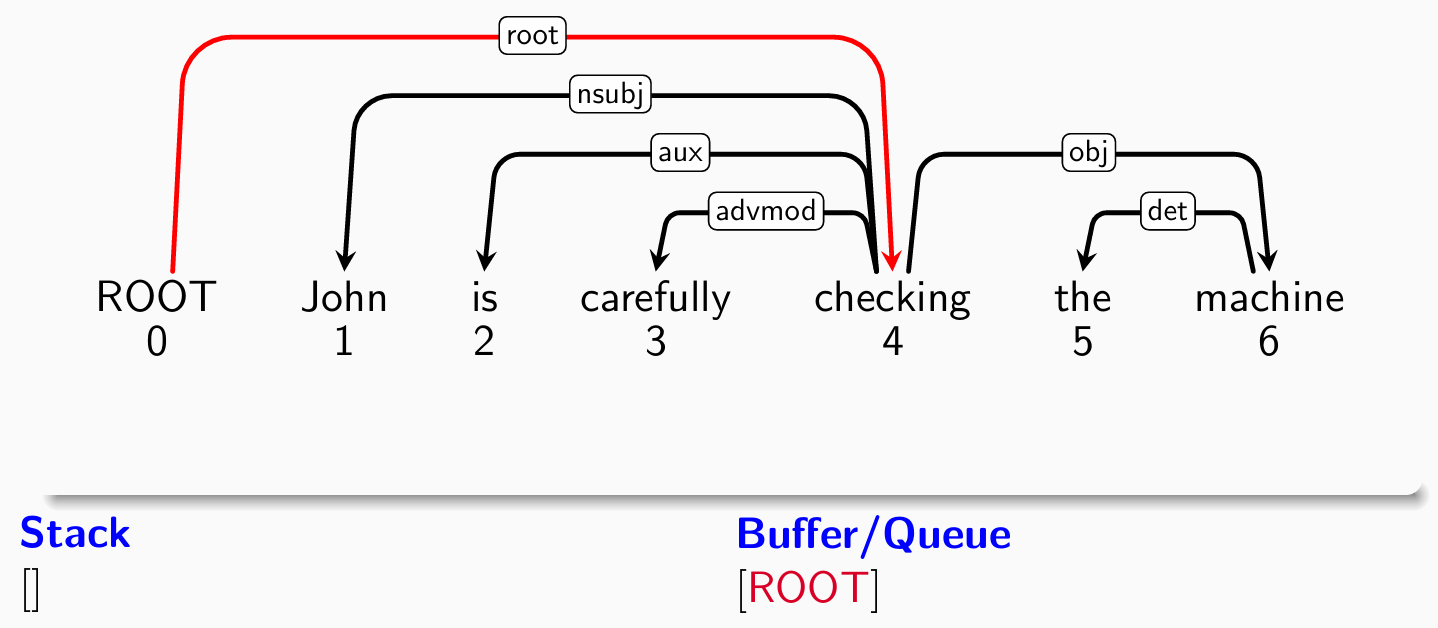
- 考察root,分类器给出shift操作:
- 算法无法处理non-projective的情况
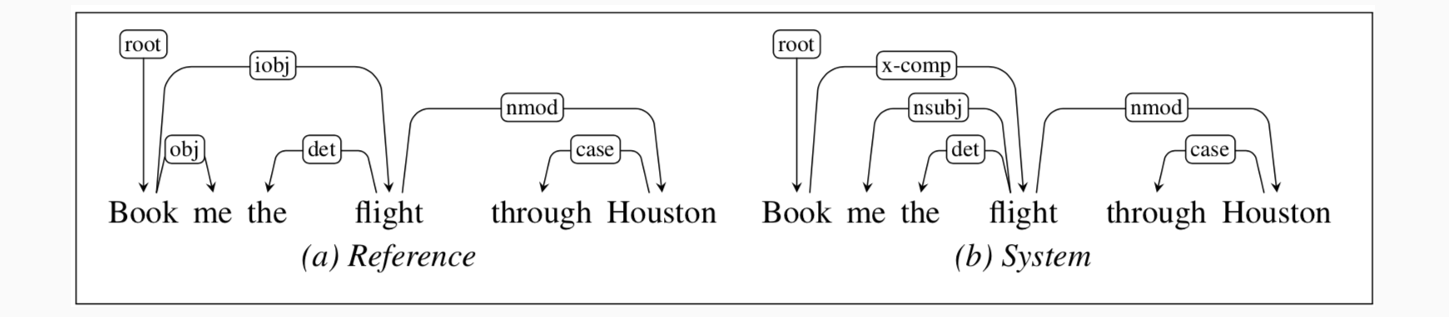
Evaluation
- 两种做Evaluation的方式:
- Exact match: how many sentences are parsed correctly?但是exact match很难,得分往往都不高
- 看边集的正确率,输入中被分配了具有正确关系的正确 head 的单词的百分比:
- Labeled Attachment Score (LAS)(值低)
- Unlabeled Attachment Score (UAS)(值高)