
Janus:Decoupling Visual Encoding for Unified Multimodel Understanding and Generation
Janus:Decoupling Visual Encoding for Unified Multimodel Understanding and Generation(解耦视觉编码以实现统一的多模态理解和生成)
- 自回归模型(deepseek):自回归模型(Autoregressive Model, AR Model) 是一种统计模型,用于描述时间序列数据或序列数据中当前值与过去值之间的关系。它的核心思想是:当前时刻的值是过去若干时刻值的线性组合,并通过这种依赖关系来预测未来的值。核心特点:
- 时间依赖性:
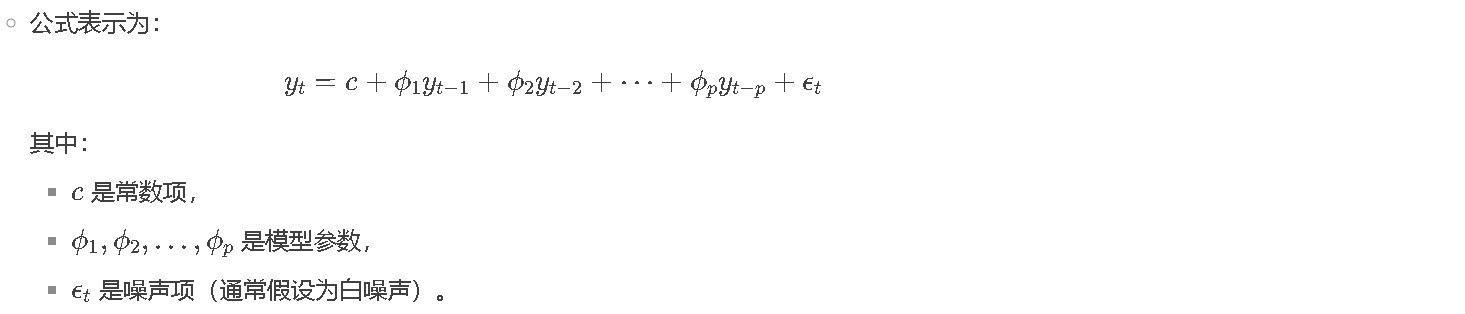
- 序列生成:自回归模型通过逐步预测序列中的下一个值来生成整个序列。例如,在文本生成中,模型根据前一个词预测下一个词,逐步生成完整的句子
- 时间依赖性:
Abstract
Janus是一个自回归框架,统一了多模态理解和生成
先前的研究通常依赖于单一视觉编码器来处理这两个任务,然而由于多模态理解和生成所需的信息粒度不同,这种方法可能导致次优性能,尤其是在多模态理解方面
为了解决这个问题,可以将视觉编码解耦为独立的路径,同时仍然利用单一的统一Transformer架构进行处理:
- 缓解了视觉编码器在理解和生成中的角色冲突
- 强了框架的灵活性
Janus超越了之前的统一模型,并与任务特定模型的性能相当或更好,具有简洁性、高灵活性和有效性
1. Introduction
在多模态理解领域,研究人员遵循LLaVA的设计,使用视觉编码器作为桥梁,使大语言模型(LLMs)能够理解图像
在视觉生成领域,基于扩散的方法取得了显著成功
最近一些工作探索了自回归方法用于视觉生成,取得了与扩散模型相当的性能。为了构建更强大和通用的多模态模型,研究人员试图将多模态理解和生成任务结合起来
一些研究尝试将多模态理解模型与预训练的扩散模型连接起来。例如,Emu使用LLM的输出作为预训练扩散模型的条件,然后依赖扩散模型生成图像
然而,这种方法不能被视为真正的统一模型,因为视觉生成功能由外部扩散模型处理,而多模态LLM本身缺乏直接生成图像的能力
一些方法使用单一Transformer来统一多模态理解和生成任务,这提高了视觉生成的指令跟随能力,解锁了潜在的涌现能力,并减少了模型冗余。这些方法通常使用单一视觉编码器来处理这两个任务的输入
然而,多模态理解和生成任务所需的表示差异很大,将这两个任务的表示统一在同一空间中会导致冲突和权衡:
- 在多模态理解任务中,视觉编码器的目的是提取高级语义信息(例如,图像中的对象类别或视觉属性)。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理。视觉编码器的表示粒度主要集中在高维语义表示上
- 相比之下,在视觉生成任务中,主要关注生成局部细节并保持图像的全局一致性。在这种情况下,表示需要低维编码,能够表达细粒度的空间结构和纹理细节
为了解决这个问题,我们提出了Janus,一个统一的多模态框架,解耦了多模态理解和生成的视觉编码
引入了两个独立的视觉编码路径:一个用于多模态理解,另一个用于多模态生成,由相同的Transformer架构统一,优点:
- Janus缓解了多模态理解和生成的不同粒度需求带来的冲突,消除了在选择视觉编码器时在两个任务之间进行权衡的需要
- Janus是灵活且可扩展的。解耦后,理解和生成任务都可以采用特定领域的最先进编码技术
- Janus未来还可以容纳其他输入类型,例如点云、脑电信号或音频数据,其中独立的编码器可以提取特征,然后使用统一的Transformer进行处理
第一个强调在统一的多模态理解和生成框架中解耦视觉编码的重要性的
Janus在具有可比参数规模的情况下超越了现有的统一模型,在多模态理解和生成基准测试中取得了最先进的结果。Janus甚至优于一些参数显著更多的任务特定模型

2. Related Work
2.1. Visual Generation
自回归模型受到语言处理成功的启发,利用Transformer预测离散视觉标记(codebook IDs)的序列。这些模型将视觉数据标记化,并采用类似于GPT风格的预测方法
掩码预测模型借鉴了BERT风格的掩码方法,预测视觉输入的掩码部分以提高合成效率,并已适应于视频生成
同时,连续扩散模型展示了在视觉生成中的强大能力,通过概率视角补充了离散方法
2.2. Multimodal Understanding
多模态大语言模型(MLLMs)集成了文本和图像,通过利用预训练的LLMs,MLLMs展示了强大的多模态信息理解和处理能力
最近的进展探索了将MLLMs与预训练的扩散模型结合以促进图像生成,这些方法属于工具利用类别:
- 其中扩散模型用于根据MLLM输出的条件生成图像,而MLLM本身不具备直接执行视觉生成的能力
- 此外,整个系统的生成能力通常受到外部扩散模型的限制,使其性能不如直接使用扩散模型本身
2.3. Unified Multimodal Understanding and Generation
统一的多模态理解和生成模型被认为在促进跨不同模态的无缝推理和生成方面具有强大能力
这些模型中的传统方法通常使用单一视觉表示来处理理解和生成任务,无论它们是基于自回归(AR)模型还是扩散模型
然而这种做法可能导致次优结果,因为视觉编码器可能面临理解和生成需求之间的权衡
Janus可以显式解耦理解和生成的视觉表示,认识到不同任务可能需要不同级别的信息
3. Janus: A Simple, Unified and Flexible Multimodal Framework
3.1. Architecture
- Janus的架构如下图所示。对于纯文本理解、多模态理解和视觉生成,我们应用独立的编码方法将原始输入转换为特征,然后由统一的自回归Transformer处理

对于文本理解,我们使用LLM的内置分词器将文本转换为离散ID,并获取每个ID对应的特征表示
对于多模态理解,我们使用SigLIP编码器从图像中提取高维语义特征。这些特征从2D网格展平为1D序列,并使用理解适配器将这些图像特征映射到LLM的输入空间
对于视觉生成任务,我们使用中的VQ tokenizer将图像转换为离散ID。在将ID序列展平为1D后,我们使用生成适配器将每个ID对应的codebook嵌入映射到LLM的输入空间
然后我们将这些特征序列连接起来形成多模态特征序列,随后输入到LLM中进行处理。LLM的内置预测头(built-in prediction head)用于纯文本理解和多模态理解任务中的文本预测,而随机初始化的预测头(randomly
initialized prediction head)用于视觉生成任务中的图像预测整个模型遵循自回归框架,无需专门设计的注意力掩码
3.2. Training Procedure
- Janus的训练分为三个阶段,如下图所示
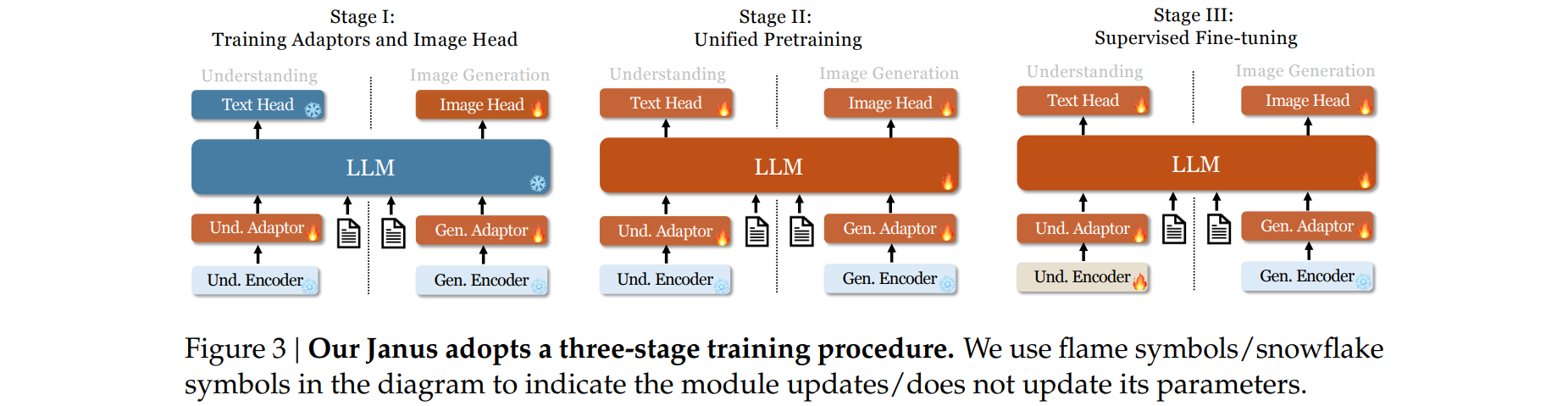
Stage I: Training Adaptors and Image Head
此阶段的主要目标是在嵌入空间中创建视觉和语言元素之间的概念连接,使LLM能够理解图像中显示的实体并具备初步的视觉生成能力
在此阶段,我们冻结视觉编码器和LLM,仅允许理解适配器、生成适配器和图像头中的可训练参数更新
Stage II: Unified Pretraining
在此阶段,我们使用多模态语料库进行统一预训练,使Janus能够学习多模态理解和生成
解冻LLM并利用所有类型的训练数据:纯文本数据、多模态理解数据和视觉生成数据
受Pixart启发,我们首先使用ImageNet-1k进行简单的视觉生成训练,以帮助模型掌握基本的像素依赖关系。随后,我们使用通用文本到图像数据增强模型的开放域视觉生成能力
Stage III: Supervised Fine-tuning
在此阶段,我们使用指令调优数据对预训练模型进行微调,以增强其指令跟随和对话能力
微调除生成编码器外的所有参数
专注于监督答案,同时屏蔽系统和用户提示
为了确保Janus在多模态理解和生成方面的熟练程度,我们不会为某个任务单独微调模型。相反,我们使用纯文本对话数据、多模态理解数据和视觉生成数据的混合,确保在各种场景中的多功能性
3.3. Training Objective
- Janus是一个自回归模型,我们在训练期间简单地采用交叉熵损失:

这里,P(⋅∣⋅)表示由Janus的权重θ建模的条件概率
对于纯文本理解和多模态理解任务,我们在文本序列上计算损失
对于视觉生成任务,我们仅在图像序列上计算损失。为了保持设计简单,我们没有为不同任务分配不同的损失权重
3.4. Inference(推理)
在推理过程中,我们的模型采用下一个标记预测方法
对于纯文本理解和多模态理解,我们遵循从预测分布中顺序采样标记的标准做法
对于图像生成,我们使用无分类器指导(CFG)对于每个标记,logit lg计算为:lg=lu+s(lc−lu),其中lc是条件logit,lu是无条件logit,s是无分类器指导的尺度。默认的s值为5,用于以下评估
3.5. Possible Extensions
Multimodal Understanding
对于多模态理解组件,可以选择更强的视觉编码器,而无需担心编码器是否能够处理视觉生成任务,例如EVA-CLIP、InternViT等
为了处理高分辨率图像,可以使用动态高分辨率技术。这允许模型扩展到任何分辨率,而无需对ViTs进行位置嵌入插值
可以进一步压缩标记以节省计算成本,例如使用像素洗牌操作
Visual Generation
对于视觉生成,可以选择更细粒度的编码器以在编码后保留更多图像细节,例如MoVQGan
可以采用专门为视觉生成设计的损失函数,例如扩散损失
可以在视觉生成过程中结合AR(因果注意力)和并行(双向注意力)方法,以减少视觉生成过程中的累积误差
Support for Additional Modalities
- Janus的简单架构允许轻松集成更多编码器,适应各种模态,例如3D点云、触觉和脑电图。这使Janus有潜力成为更强大的多模态通用模型
4. Experiments
4.1. Implementation Details
使用DeepSeek-LLM(1.3B)作为基础语言模型,最大支持序列长度为4096
对于理解任务中使用的视觉编码器,我们选择SigLIP-Large-Patch16-384
生成编码器的codebook大小为16,384,并将图像下采样16倍
理解适配器和生成适配器都是两层MLP,所有图像都调整为384×384像素
对于多模态理解数据,我们将图像的长边调整大小并用背景颜色(RGB: 127, 127, 127)填充短边以达到384
对于视觉生成数据,短边调整为384,长边裁剪为384
训练期间使用序列打包以提高训练效率
Janus使用HAI-LLM进行训练和评估,这是一个基于PyTorch构建的轻量级高效分布式训练框架。整个训练过程在16个节点的集群上进行了7天,每个节点配备8个Nvidia A100(40GB)GPU
4.2. Data Setup
Stage I
使用一个包含1.25百万图像-文本配对字幕的数据集(来自ShareGPT4V)用于多模态理解,以及大约1.2百万样本(来自ImageNet-1K)用于视觉生成
ShareGPT4V数据格式为”/(image)(text)”。ImageNet数据使用类别名称组织为文本到图像数据格式:”/(category_name)(image)”
Stage II
- 我们将数据组织为以下类别:
- 纯文本数据。我们使用DeepSeek-LLM的预训练文本语料库
- 交错图像-文本数据。使用WikiHow和WIT数据集
- 图像字幕数据。使用来自的图像。其中,我们使用开源多模态模型重新为中的图像生成字幕。图像字幕数据格式化为问答对,例如”/(image)Describe the image in detail.(caption)”
- 表格和图表数据。我们使用来自DeepSeek-VL的相应表格和图表数据。数据格式为”/(question)(answer)”
- 视觉生成数据。我们利用来自各种数据集的图像-字幕对,包括,以及2M内部数据。视觉生成数据的格式为:”(caption)(image)”
Stage III
- 使用以下格式进行指令调优:”User::(Input Message)\n Assistant: (Response)”。对于多轮对话,重复此格式以结构化数据。
4.3. Evaluation Setup
Multimodal Understanding
Visual Generation
4.4. Comparison with State-of-the-arts(与最先进模型比较)
Multimodal Understanding Performance
Janus在相似规模的模型中取得了总体最佳结果。可以归因于Janus解耦了多模态理解和生成的视觉编码,缓解了这两个任务之间的冲突
与规模显著更大的模型相比,Janus仍然具有高度竞争力
Visual Generation Performance
- Janus生成的图像具有良好的质量,并突出了其在视觉生成中的潜力
4.5. Ablation Studies(消融研究)
- 消融研究以验证Janus设计理念的有效性:
- 设计了实验来验证解耦视觉编码的重要性和好处
- 研究了统一训练对多模态理解或视觉生成等单个任务的影响
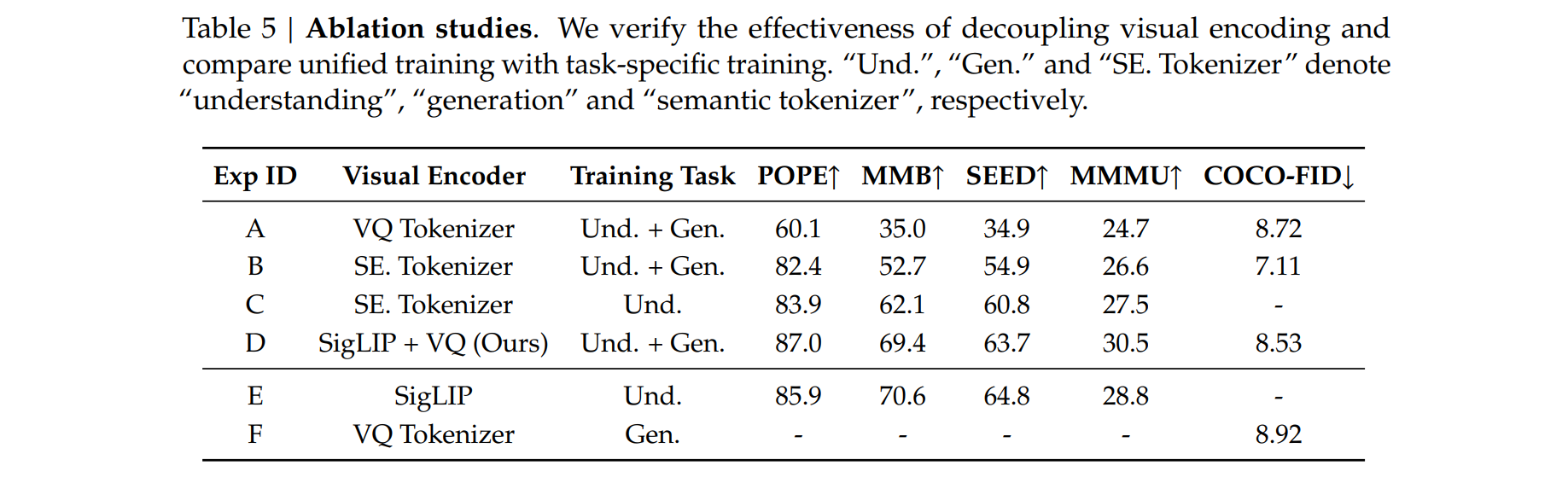
Baseline Construction
根据之前的工作,我们选择VQ tokenizer来编码图像用于多模态理解和生成任务,作为基线(Exp-A)
考虑到Exp-A中的VQ tokenizer在提取语义信息方面可能较弱,使其对多模态理解效果不佳,我们还构建了一个更强的基线Exp-B:采用SigLIP来蒸馏一个增强的语义tokenizer 3,可以从图像中提取高级语义信息,同时具有将图像转换为离散ID的能力
Impact of Decoupling Visual Encoding(解耦视觉编码的影响)
从Exp-A的结果中,我们发现模型在视觉生成基准上取得了令人满意的性能(COCO上的8.72 FID)然而,Exp-A与我们的模型(Exp-D)在理解基准上存在显著差距
当比较Exp-B与Exp-A时,结果显示多模态理解有明显改善,尽管与我们的方法相比仍有相当大的差距。在视觉生成方面,Exp-B优于Exp-D:
- 语义tokenizer生成的离散ID在语义上更连贯,为LLM提供了更合理的预测目标
- Exp-B中的视觉编码器比Exp-D中的生成编码器具有显著更多的参数
为了研究使用单一视觉编码器是否会导致多模态理解和生成之间的权衡,我们进一步设计了基于Exp-B的Exp-C,仅专注于多模态理解训练。Exp-C的多模态理解能力显著优于Exp-B。这表明Exp-B中的视觉编码器在多模态理解和生成之间进行了权衡,最终牺牲了其多模态理解能力。上述实验说明了解耦视觉编码的重要性
Unified Model vs. Pure Understanding & Pure Generation
比较了统一训练(Exp-D)与纯理解(Exp-E)和纯生成(Exp-F)训练的性能
对于纯理解,我们省略了视觉生成数据;对于纯生成,我们排除了理解数据
统一训练和纯理解训练在理解部分经历了相同的步骤。同样,统一训练和纯生成训练在视觉生成部分经历了相同的步骤
实验结果表明,统一训练的性能与仅进行理解或仅进行视觉生成的训练相当。这表明我们的模型Janus能够在最小化影响多模态理解性能的同时,融入强大的生成能力
4.6. Qualitative Results
Visualizations of Visual Generation
- 下图提供了我们的模型、基于扩散的模型(如SDXL)和自回归模型 LlamaGen之间的定性比较

我们的模型在视觉生成方面表现出卓越的指令跟踪能力,准确地捕捉了用户提示中的大部分细节。这表明统一模型在视觉生成领域的潜力
下图展示了 Janus 的多模态理解能力与 Chameleon和 Show-o的定性结果

Janus 准确地解读了文本标题并捕捉了模因中传达的情感。相比之下,Chameleon 和 Show-o 都在努力准确识别图像中的文本
与 Chameleon 和 Show-o 使用的共享编码器相比,解耦的视觉编码器显著增强了 Janus 的细粒度多模态理解能力
5. Conclusion
Janus是一个简单、统一且可扩展的多模态理解和生成模型
Janus的核心思想是解耦多模态理解和生成的视觉编码(decouple visual encoding for multimodal understanding and generation),这可以缓解理解和生成对视觉编码器的不同需求带来的冲突
Janus灵活且易于扩展。除了在多模态理解和生成方面具有显著的改进潜力外,Janus还可以轻松扩展以纳入更多输入模态
deepseek要点总结
核心问题
现有统一多模态模型(如Chameleon)使用单一视觉编码器同时处理多模态理解(需高维语义)和视觉生成(需低维细节),导致性能妥协(尤其理解任务表现下降)。
创新点
- 解耦视觉编码
o 双路径设计:
- 理解路径:使用SigLIP提取高维语义特征。
- 生成路径:使用VQ tokenizer生成低维离散编码。
o 统一架构:共享Transformer处理多模态序列,保留自回归生成能力。
- 灵活性与扩展性
o 各任务可独立选择最优编码器(如EVA-CLIP、MoVQGan)。
o 支持未来扩展更多模态(点云、EEG等)。
方法设计
- 架构
o 文本处理:LLM内置分词器。
o 多模态理解:SigLIP编码 + MLP适配器 → LLM输入。
o 视觉生成:VQ编码 + MLP适配器 → LLM输入。
o 预测头:文本任务用LLM原生头,图像任务用新初始化的头。 - 三阶段训练
o 阶段I:冻结LLM和编码器,训练适配器与图像头(建立视觉-语言关联)。
o 阶段II:解冻LLM,混合文本、理解、生成数据统一预训练(学习基本像素依赖与复杂场景)。
o 阶段III:指令微调(提升对话与指令跟随能力)。 - 推理优化
o 生成任务采用无分类器指导(CFG),增强生成可控性。
实验结果
- 多模态理解性能
o 超越统一模型:在MMBench、SEED-Bench、POPE等基准上,1.3B参数的Janus显著优于7B参数的LLaVA-v1.5和Qwen-VL-Chat。
o 对比任务专用模型:与纯理解模型相比,性能接近甚至更优(如POPE 87.0 vs. LLaVA-v1.5 85.9)。 - 视觉生成性能
o 质量领先:在MSCOCO-30K(FID=8.53)和GenEval(准确率61%)上超越DALL-E 2、SDXL等生成专用模型。
o 效率优势:仅需1.3B参数,性能媲美更大模型(如7B参数的LWM)。 - 消融实验验证
o 解耦必要性:共享编码器(Exp-B)导致理解性能下降约20%。
o 统一训练不影响单任务性能:与纯理解/生成训练相比,统一模型表现相当。
核心贡献
- 首次提出在多模态统一框架中解耦视觉编码,解决任务需求冲突。
- 灵活架构:支持多模态扩展,兼容先进编码技术。
- 性能突破:小参数模型超越大模型,验证解耦设计的有效性。
未来潜力
• 扩展至更多模态(如3D点云、音频)。
• 结合并行生成方法(如双向注意力)进一步优化生成效率。
• 探索多语言生成能力(实验显示未训练中文/日文仍可生成合理结果)。
总结
Janus通过解耦视觉编码路径,在统一框架中兼顾多模态理解与生成的差异化需求,以简洁设计实现性能突破,为下一代多模态通用模型提供了新思路。

