
Janus-Pro:Unified Multimodal Understanding and Generation with Data and Model Scaling
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Abstract
Janus-Pro是之前工作Janus的进阶版本
Janus-Pro结合了:
- 优化的训练策略
- 扩展的训练数据
- 更大的模型规模
Janus-Pro在多模态理解和文本到图像的指令跟随能力方面取得了显著进展,同时增强了文本到图像生成的稳定性
1. Introduction
Janus在1B参数规模上得到了验证。然而由于训练数据量有限和模型容量相对较小,它表现出一些缺点,例如在短提示图像生成上的性能不佳以及文本到图像生成质量不稳定
Janus-Pro系列包括两种模型规模:1B和7B,展示了视觉编码解码方法的可扩展性
Janus-Pro在多模态理解能力和文本到图像指令跟随性能方面均表现出色


2. Method
2.1. Architecture
- Janus-Pro的架构如下图所示,与Janus相同,整体架构的核心设计原则是解耦多模态理解和生成的视觉编码

应用独立的编码方法将原始输入转换为特征,然后由统一的自回归transformer处理:
- 对于多模态理解,我们使用SigLIP编码器从图像中提取高维语义特征。这些特征从2-D网格展平为1-D序列,并使用理解适配器将这些图像特征映射到LLM的输入空间
- 对于视觉生成任务,我们使用VQ tokenizer将图像转换为离散ID。在将ID序列展平为1-D后,我们使用生成适配器将每个ID对应的codebook嵌入映射到LLM的输入空间
然后将这些特征序列连接起来形成多模态特征序列,随后输入到LLM中进行处理。除了LLM内置的预测头(built-in prediction head)外,我们还使用随机初始化的预测头(randomly initialized prediction head)进行视觉生成任务中的图像预测
整个模型遵循自回归框架
2.2. Optimized Training Strategy
Janus采用了三阶段训练过程:
- 第一阶段专注于训练适配器和图像头
- 第二阶段进行统一预训练,在此期间除了理解编码器和生成编码器外,所有组件的参数都会更新
- 第三阶段是监督微调,在第二阶段的基础上进一步解锁理解编码器的参数进行训练
这种训练策略存在一些问题。在第二阶段,Janus按照PixArt将文本到图像能力的训练分为两部分:
- 第一部分在ImageNet数据上进行训练,使用图像类别名称作为文本到图像生成的提示,目标是建模像素依赖性
- 第二部分在正常的文本到图像数据上进行训练
- 在实施过程中,第二阶段的文本到图像训练步骤的66.67%分配给第一部分
通过进一步的实验,我们发现这种策略并不理想,并且会导致显著的计算效率低下。为了解决这个问题,我们做了两个修改:
- 第一阶段更长的训练:增加了第一阶段的训练步骤,允许在ImageNet数据集上进行充分的训练。即使LLM参数固定,模型也能有效地建模像素依赖性,并根据类别名称生成合理的图像
- 第二阶段集中训练:在第二阶段,我们放弃了ImageNet数据,直接使用正常的文本到图像数据来训练模型,以生成基于密集描述的图像。这种重新设计的方法使第二阶段能够更有效地利用文本到图像数据,从而提高训练效率和整体性能
第三阶段监督微调过程中调整了不同类型数据集的数据比例,将多模态数据、纯文本数据和文本到图像数据的比例从7:3:10改为5:1:4
通过略微减少文本到图像数据的比例,我们观察到这种调整使我们能够在保持强大视觉生成能力的同时,实现更好的多模态理解性能
2.3. Data Scaling(数据扩展)
- 在多模态理解和视觉生成方面扩展了用于Janus的训练数据
Multimodal Understanding
对于第二阶段的预训练数据,我们参考了DeepSeek-VL2并增加了大约9000万个样本。这些包括图像字幕数据集(例如YFCC),以及表格、图表和文档理解数据(例如Docmatix)
对于第三阶段的监督微调数据,我们还加入了来自DeepSeek-VL2的额外数据集,如MEME理解、中文对话数据以及旨在增强对话体验的数据集
这些添加显著扩展了模型的能力,丰富了其处理多样化任务的能力,同时提升了整体对话体验。
Visual Generation
之前版本的Janus使用的现实世界数据质量不高且包含大量噪声,这通常导致文本到图像生成的不稳定,产生美学上较差的输出
在Janus-Pro中,我们加入了大约7200万个合成美学数据样本(公开的),使统一预训练阶段的真实数据与合成数据的比例达到1:1
当在合成数据上训练时,模型收敛速度更快,生成的文本到图像输出不仅更稳定,而且美学质量显著提高
2.4. Model Scaling
之前版本的Janus使用1.5B LLM验证了视觉编码解耦的有效性。在Janus-Pro中,我们将模型扩展到7B
当使用更大规模的LLM时,多模态理解和视觉生成的损失收敛速度相比小模型显著提高,进一步验证了该方法的强大可扩展性
3. Experiments
3.1. Implementation Details
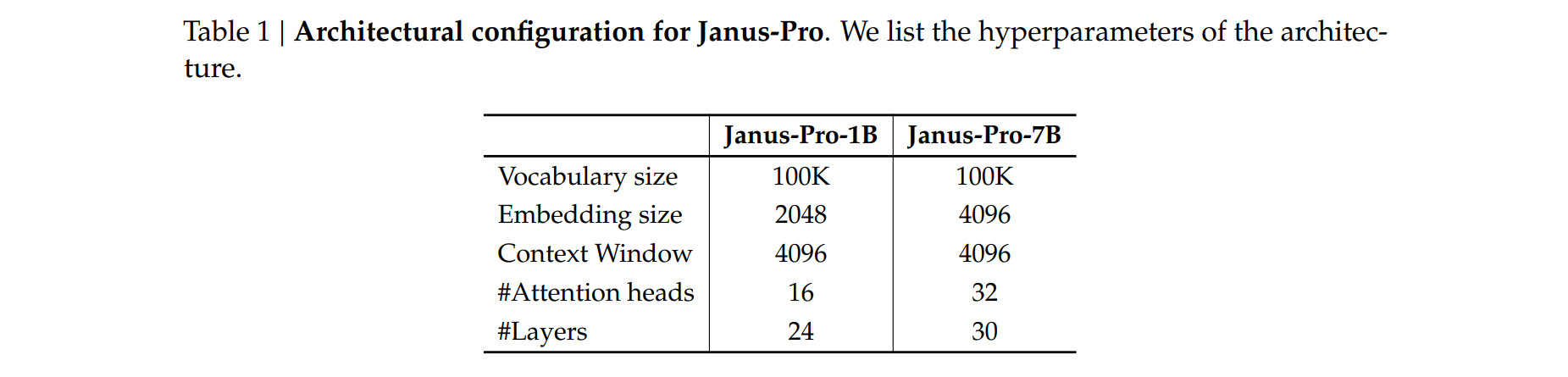
使用DeepSeek-LLM (1.5B和7B)作为基础语言模型,最大支持序列长度为4096
对于理解任务中使用的视觉编码器,我们选择了SigLIP-Large-Patch16-384。生成编码器的codebook大小为16,384,并将图像下采样16倍。理解适配器和生成适配器都是两层MLP。对于第二阶段,我们采用了早停策略,在270K步时停止。所有图像都调整为384 × 384像素
对于多模态理解数据,我们将图像的长边调整并填充短边以达到384,背景颜色为RGB: 127, 127, 127
对于视觉生成数据,短边调整为384,长边裁剪为384
在训练期间使用序列打包以提高训练效率,按照指定的比例在单个训练步骤中混合所有数据类型
Janus-Pro使用HAI-LLM进行训练和评估,这是一个基于PyTorch构建的轻量级高效分布式训练框架。整个训练过程在16/32个节点的集群上分别花费了9/14天,每个节点配备8个Nvidia A100 (40GB) GPU
3.2. Evaluation Setup
Multimodal Understanding
- 为了评估多模态理解能力,我们在广泛认可的基于图像的视觉语言基准上评估我们的模型,包括GQA、POPE、MME、SEED、MMB、MM-Vet和MMMU
Visual Generation
- 为了评估视觉生成能力,我们使用GenEval和DPG-Bench。GenEval是一个具有挑战性的文本到图像生成基准,旨在通过提供详细的实例级分析来反映视觉生成模型的综合生成能力
3.3. Comparison with State-of-the-arts
Multimodal Understanding Performance
Janus-Pro取得了总体最佳结果。这可以归因于解耦了多模态理解和生成的视觉编码,缓解了这两个任务之间的冲突
与规模显著更大的模型相比,Janus-Pro仍然具有很高的竞争力
Visual Generation Performance
Janus-Pro-7B在GenEval上获得了80%的总体准确率,超过了所有其他统一或仅生成方法
Janus-Pro具有更好的指令跟随能力,在遵循密集指令进行文本到图像生成方面表现出色
3.4. Qualitative Results
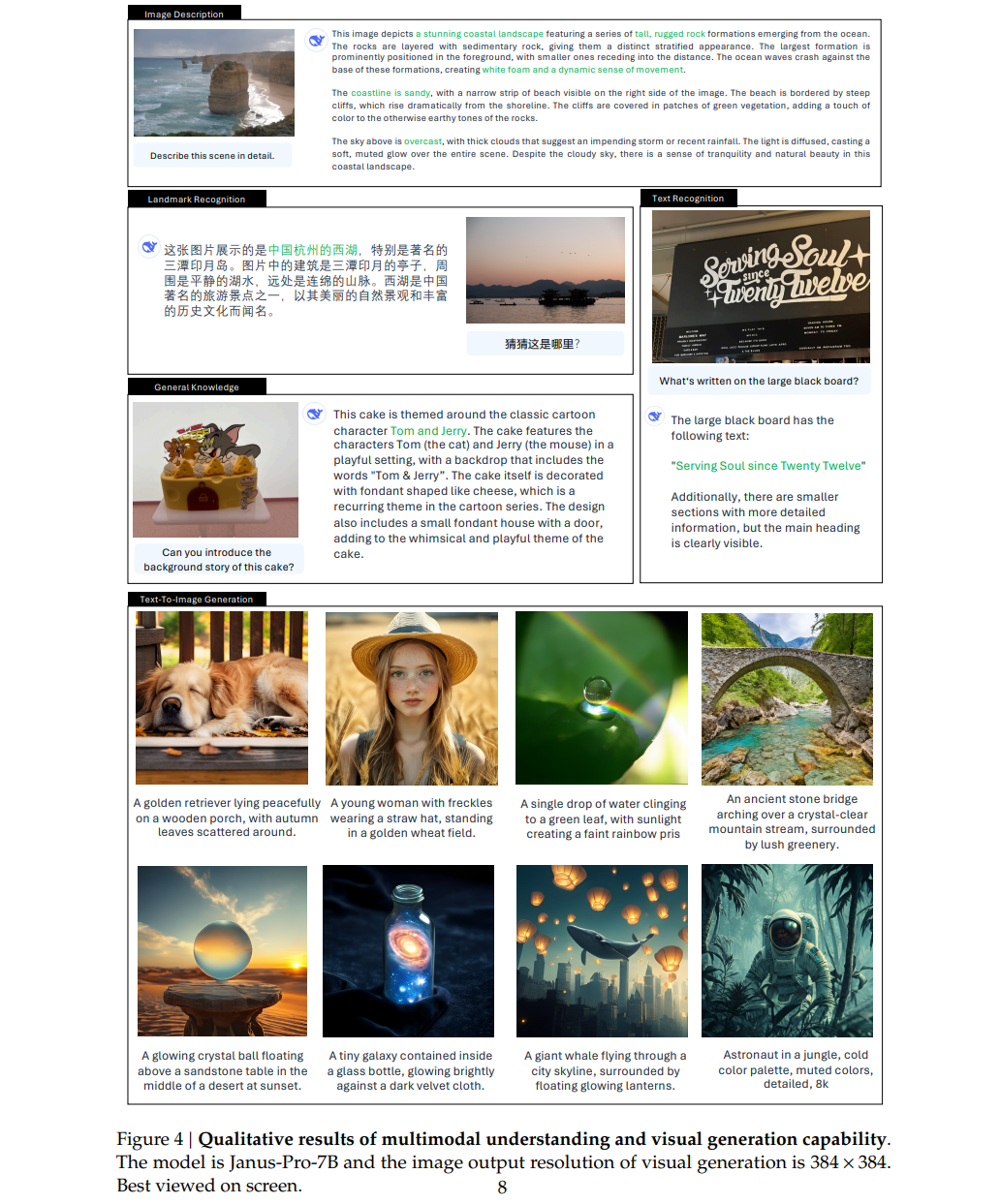
Janus-Pro在处理来自各种上下文的输入时表现出令人印象深刻的理解能力,展示了其强大的能力
Janus-Pro-7B生成的图像非常逼真,尽管分辨率仅为384 × 384,但仍包含大量细节
对于富有想象力和创造性的场景,Janus-Pro-7B准确地捕捉了提示中的语义信息,生成了合理且连贯的图像
4. Conclusion
本文从训练策略、数据和模型规模三个方面介绍了对Janus的改进
这些增强使得多模态理解和文本到图像指令跟随能力取得了显著进展
Janus-Pro仍然存在一些局限性:
- 在多模态理解方面,输入分辨率限制为384 × 384,这影响了其在OCR等细粒度任务中的表现
- 对于文本到图像生成,低分辨率加上视觉tokenizer引入的重建损失,导致生成的图像虽然语义内容丰富,但仍缺乏细节
deepseek要点总结
研究背景与问题
• 现有方法局限:
o 统一多模态模型(如Janus)使用相同视觉编码器处理理解和生成任务,导致性能冲突。
o Janus因模型规模小(1B参数)和数据不足,存在生成不稳定、短提示表现差等问题。
核心创新点
Janus-Pro通过三方面改进提升性能:
1. 优化的训练策略:
o 阶段调整:延长Stage I训练(ImageNet数据建模像素依赖),Stage II专注真实文本-图像数据。
o 数据比例优化:监督微调阶段调整多模态、纯文本、生成数据比例为5:1:4,平衡性能。
2. 数据扩展:
o 多模态理解:新增9千万样本(YFCC、Docmatix等),涵盖图像描述、表格/文档理解、中文对话。
o 视觉生成:加入7.2千万合成美学数据(真实:合成=1:1),显著提升生成质量与稳定性。
3. 模型扩展:
o 模型参数从1.5B扩展至7B,验证视觉编码解耦方法的可扩展性。
方法架构
• 双路径视觉编码:
o 理解路径:SigLIP编码器提取高维语义特征,适配器映射至LLM输入空间。
o 生成路径:VQ tokenizer将图像转为离散ID,适配器映射codebook嵌入至LLM输入空间。
• 统一自回归框架:多模态特征序列通过LLM处理,结合专用预测头生成图像。
实验结果
• 多模态理解性能:
o MMBench:Janus-Pro-7B得分79.2,超越SOTA模型(Janus 69.4,TokenFlow-XL 68.9)。
o 其他基准:MME、GQA、MMMU等任务表现全面领先。
• 文本到图像生成性能:
o GenEval:总体得分0.80,优于DALL-E 3(0.67)、SD3-Medium(0.74)。
o DPG-Bench:得分84.19,超越所有生成专用模型(如DALL-E 3、SD3)。
• 定性结果:
o 生成图像分辨率384×384,细节丰富,语义准确性高(如复杂场景描述)。
局限性
• 输入分辨率限制:384×384分辨率影响OCR等细粒度任务表现。
• 生成细节不足:小区域(如人脸)因低分辨率和重建损失缺乏精细细节。
贡献总结
• 技术改进:
o 提出解耦视觉编码的双路径架构,缓解多模态任务冲突。
o 优化训练策略与数据比例,平衡理解与生成性能。
o 验证模型扩展性(1B→7B),支持更大参数规模。
• 性能提升:
o 多模态理解和生成任务全面超越SOTA模型。
o 生成稳定性与美学质量显著提高。
实际意义
• 为统一多模态模型的设计提供新范式(解耦编码+数据/模型扩展)。
• 开源代码与模型,推动社区在视觉-语言任务中的探索。

