
大模型基础与对齐 02 Transformer & GPT-3
GPT-3: Next Token Generation
- 任务:每次预测下一个单词,选择概率最高的作为输出

问题:一词多义,WSD问题。因此需要进行上下文的语义理解
解决方法:通过attention机制来进行上下文的理解
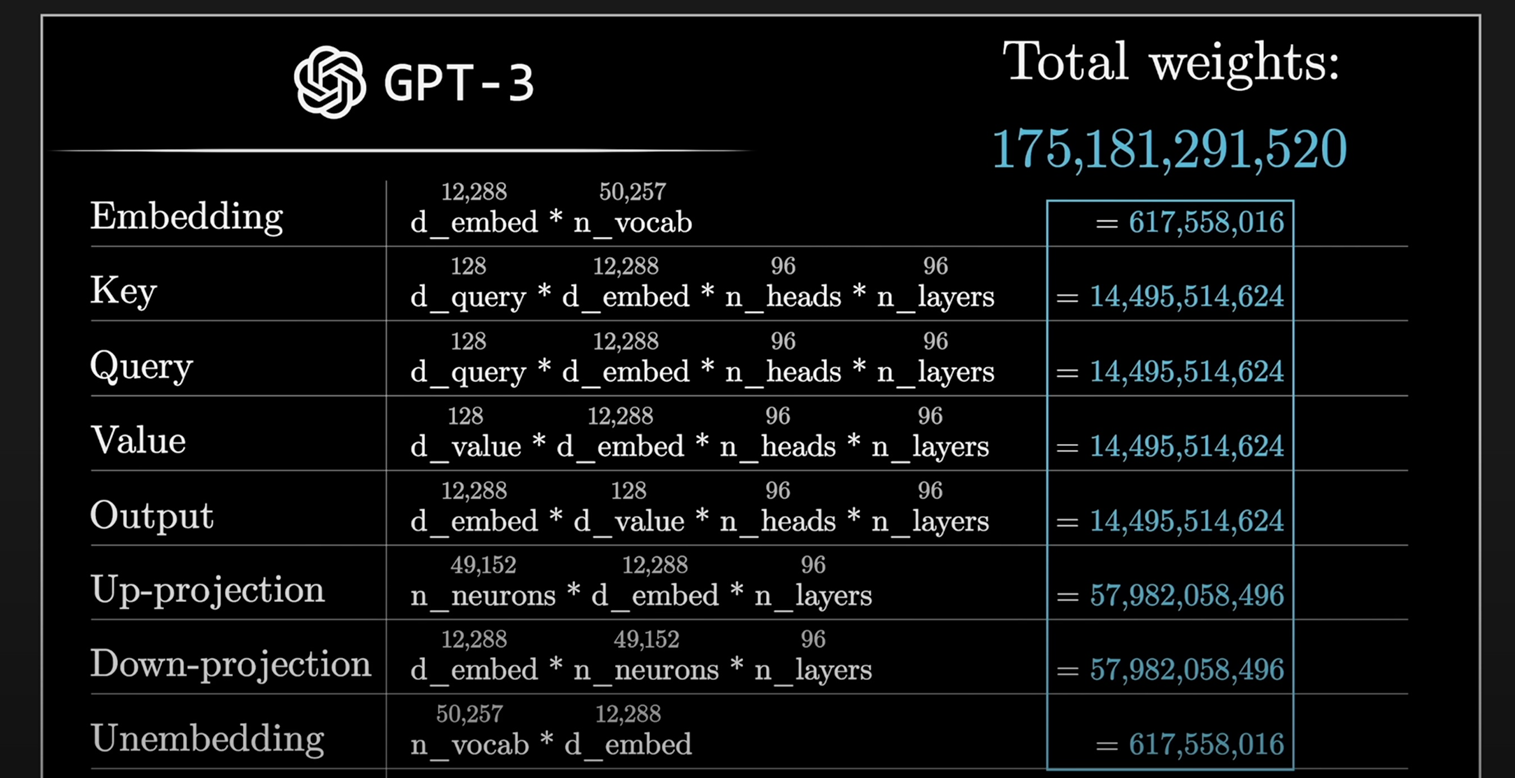
可以通过GPT-3的参数量的计算了解其运行的原理:175B
Word Embedding: update in leanring
- 最终会形成一个embedding矩阵,并在learning过程中不断更新

在词义空间embedding space中,每个词向量都有方向,且方向表征一定的含义和词义间的关系
例如复数可由cats - cat得到,复数和带复数形式单词的点乘结果会更大(说明其更相关):

- 每个symbol都会有一个embedding向量:
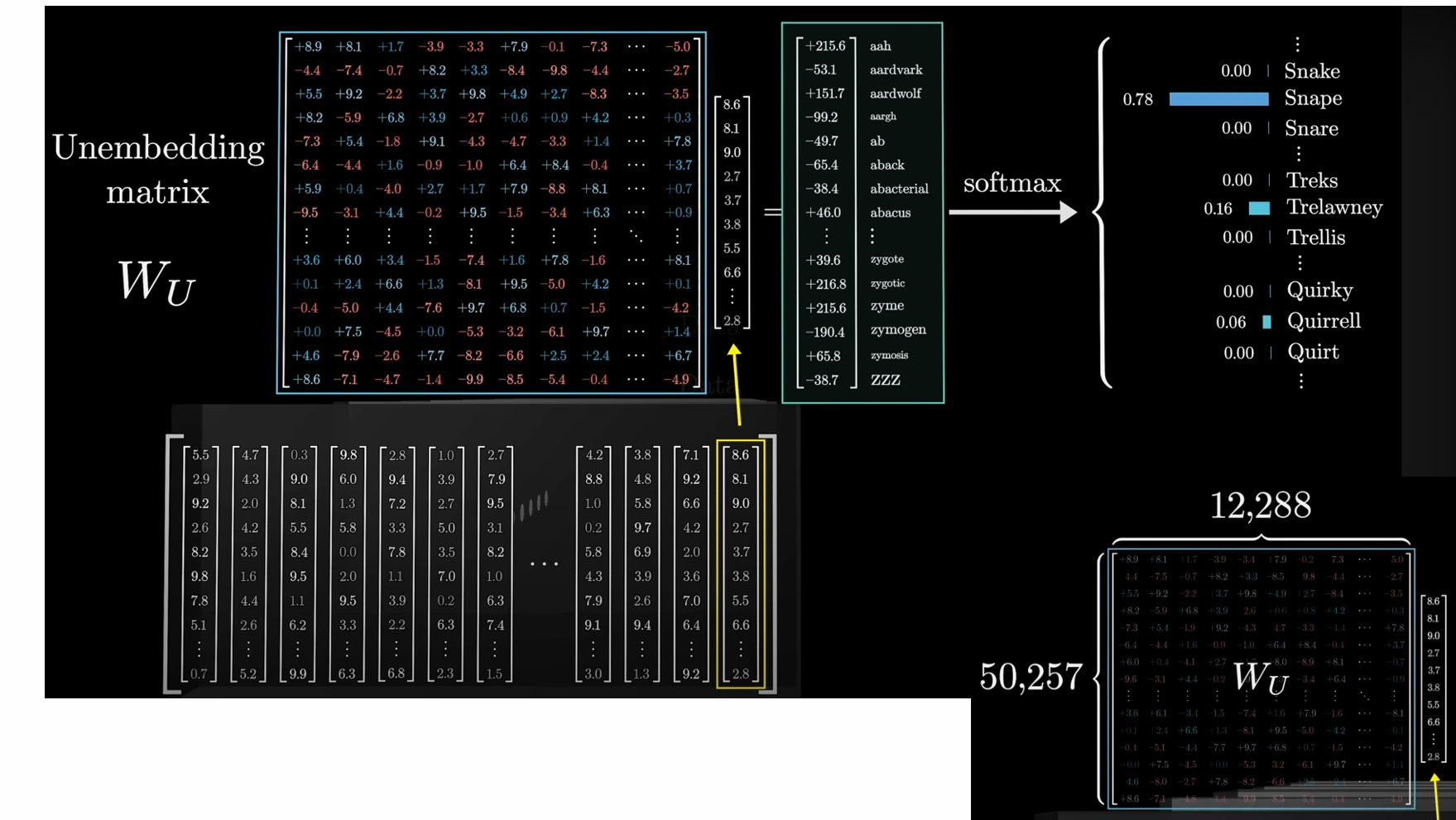
The output layer: the logits
输出需要是单词,即logits,所以需要unembedding矩阵把embedding转化为logits
转化后的乘积仍为向量,还需要通过softmax层转化为概率形式,选择概率最大的单词输出:
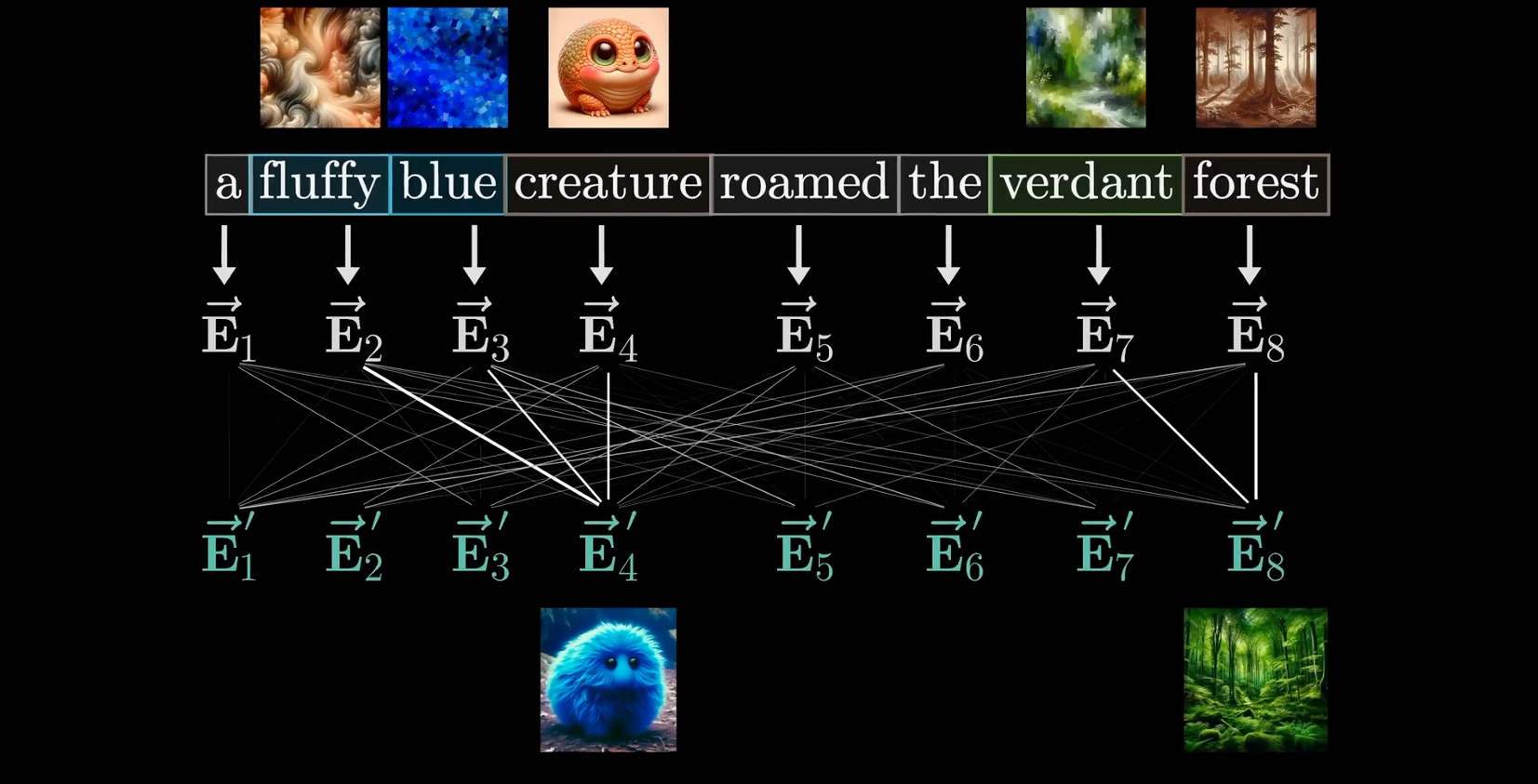
The Attention on the high level
- 词与词之间通过相互修饰的关系,利用attention形成新的embedding
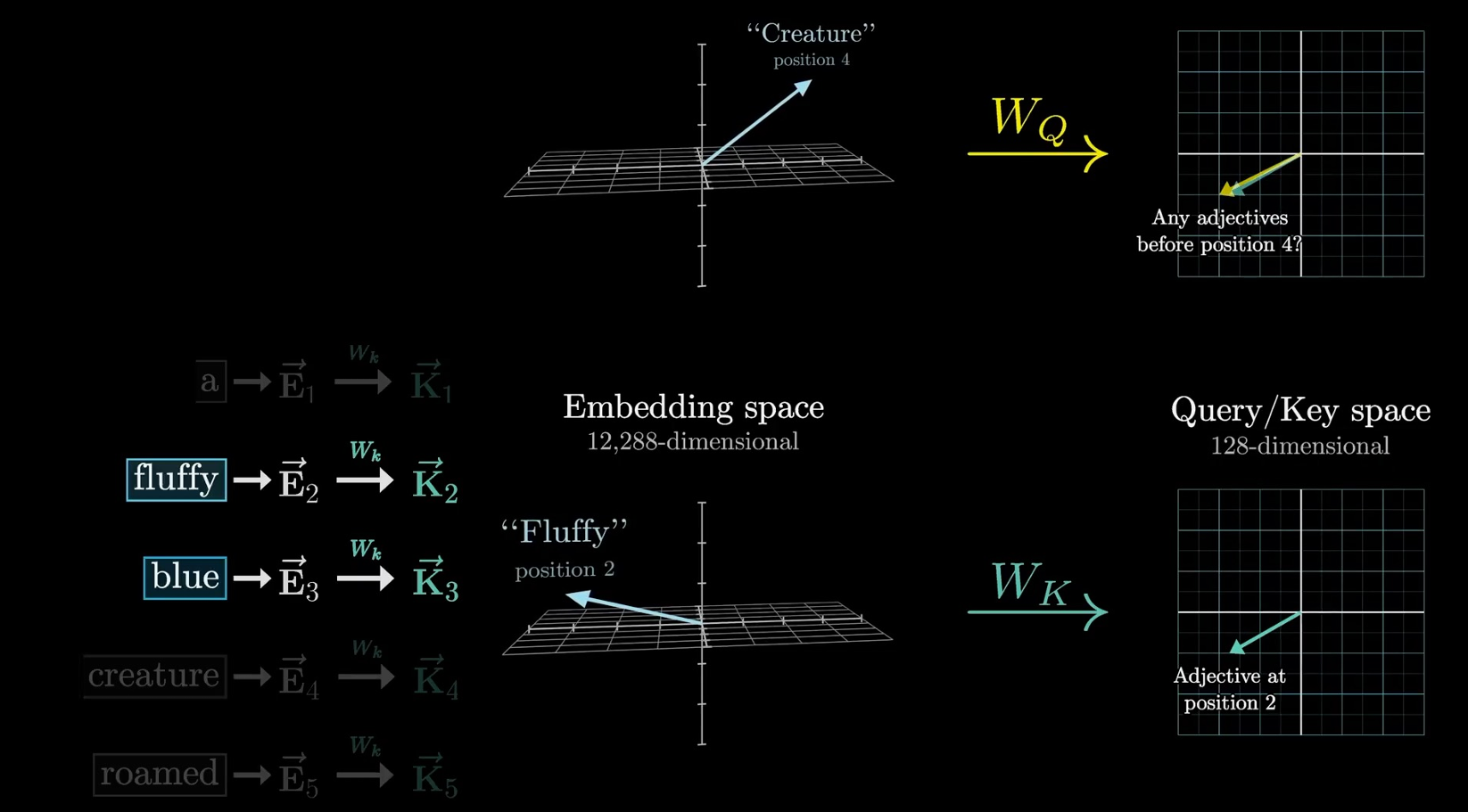
- attention公式:

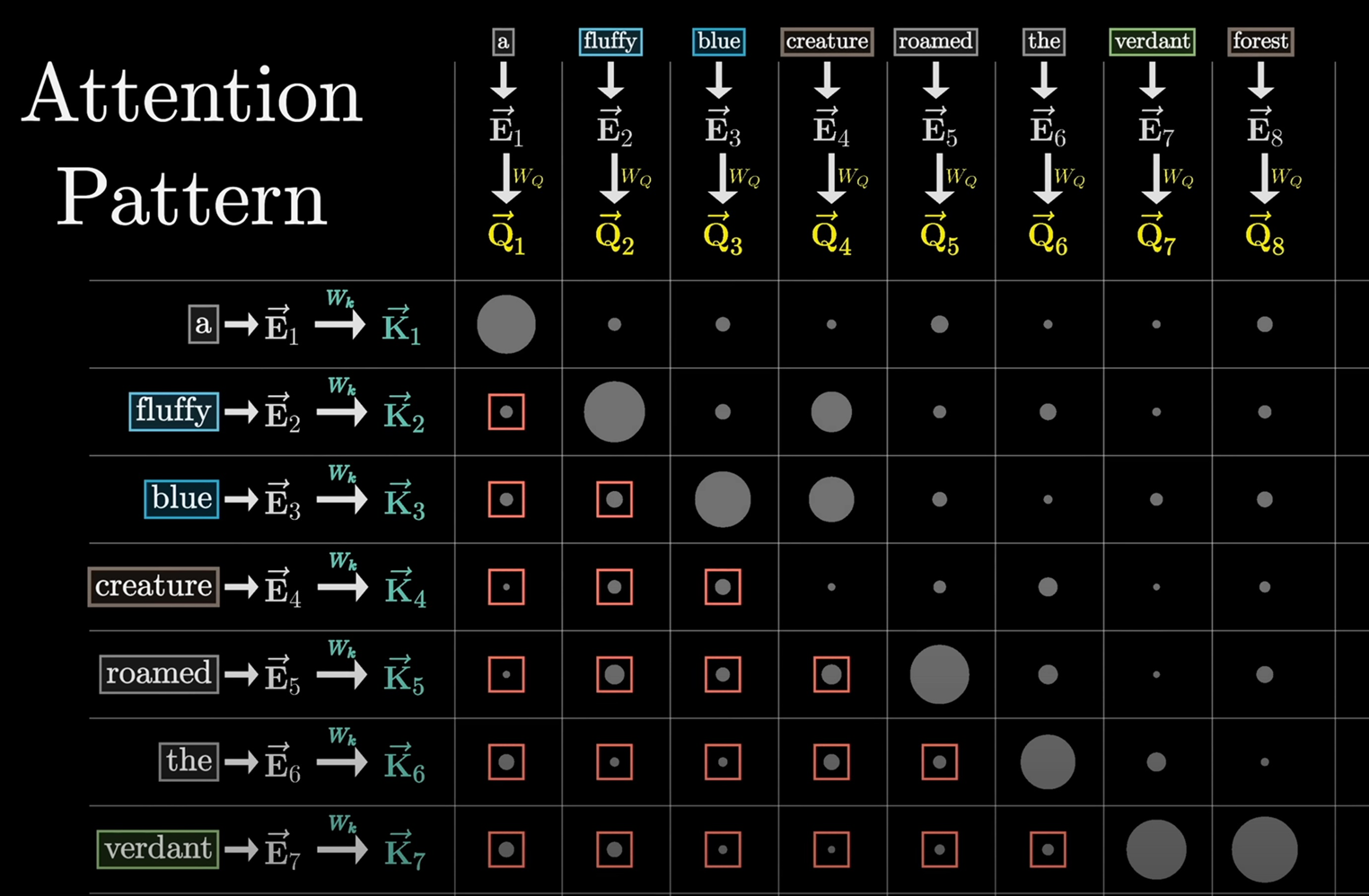
每个词查询其他所有单词,考察其相关性。可以理解为Q一直在问问题:是adj?是动物?只是这样的问询方式在黑盒中。通过这样的问询即可得到词与词间的修饰关系
K的作用是回答上述问题,回答单词在句子中的作用。QK匹配通过内积,内积越大说明相关性修饰性越强
然后用softmax进行归一化
attention pattern:对于每一列,每一行的单词有多相关?
需要mask未来的单词,以保证前面的单词无法预知未来的单词
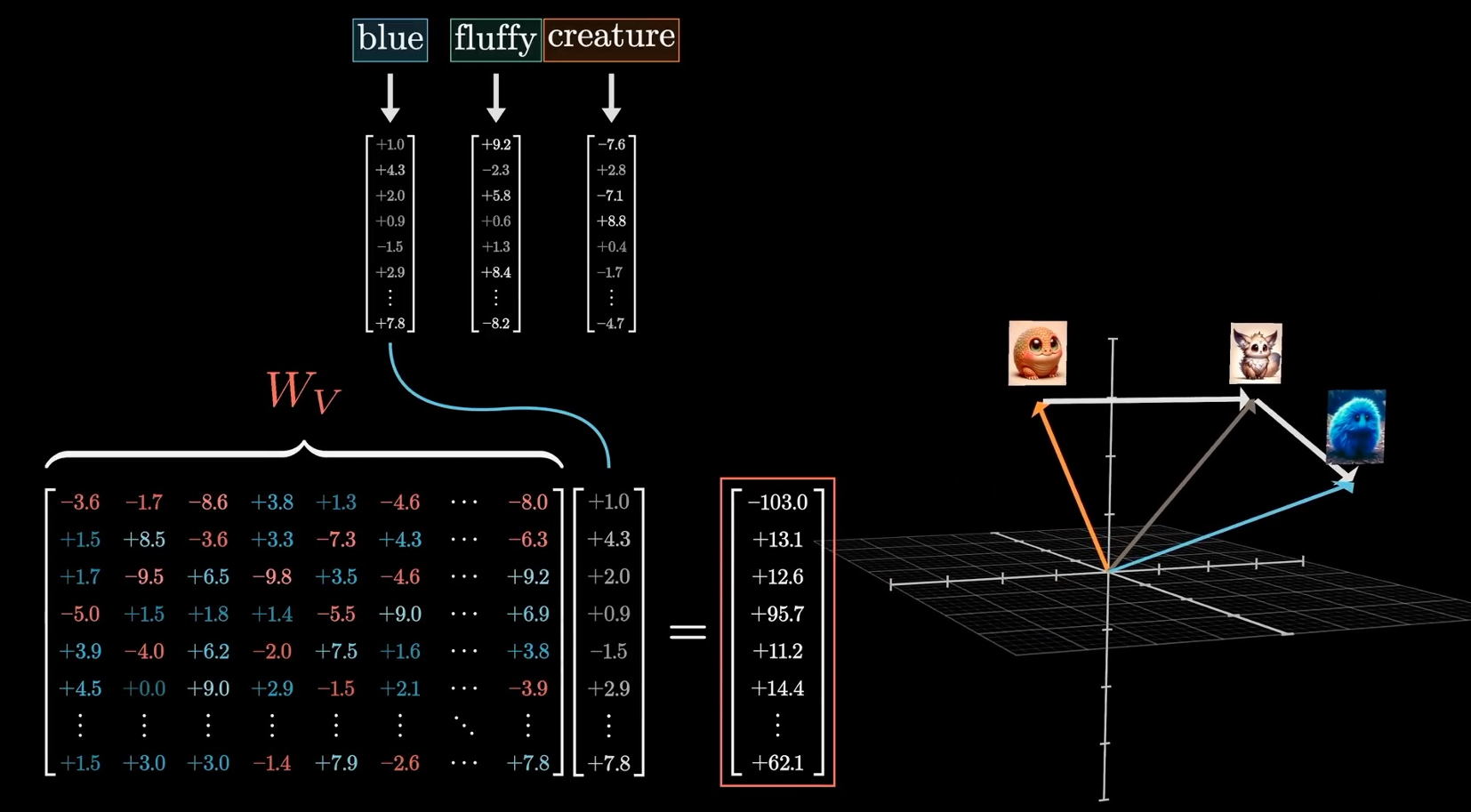
The Value Block
- Q,K解决的是单词方向的问题,而V解决的是模长(单词幅度)的问题
- value矩阵可以通过低秩变换分解为12288x128的上投影矩阵和128x12288的下投影矩阵
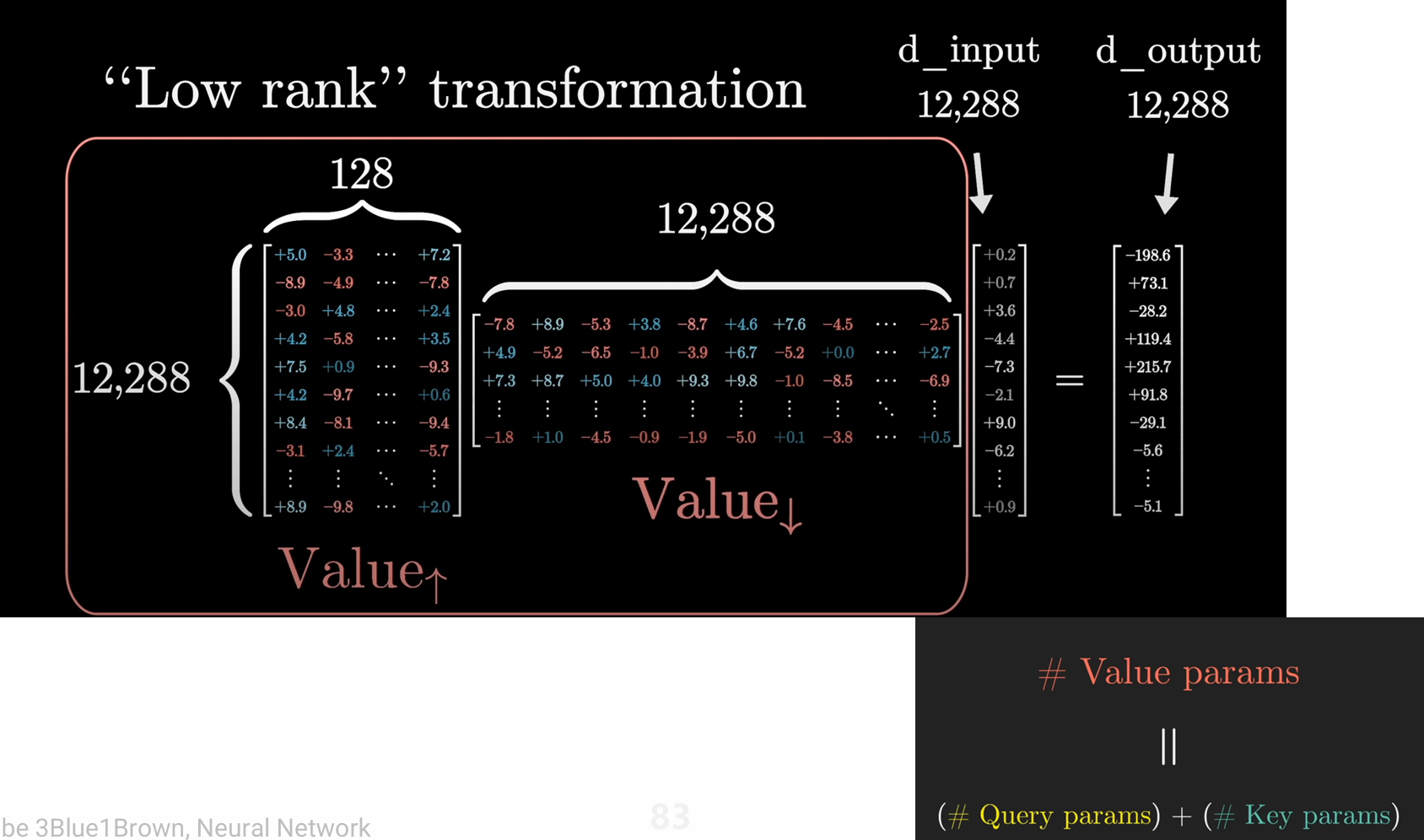
parameters of attention

其中value为下投影矩阵的参数量,output是上投影矩阵的参数量
attention层大约只占了总175B的1/3,剩下的2/3由非MLP层占用
The MLP layer stores facts: it tells how each input aligns with specific direction
- MLP作用:存储一些先验知识,一些名词自带的属性。例如:爱因斯坦自带物理学家的属性
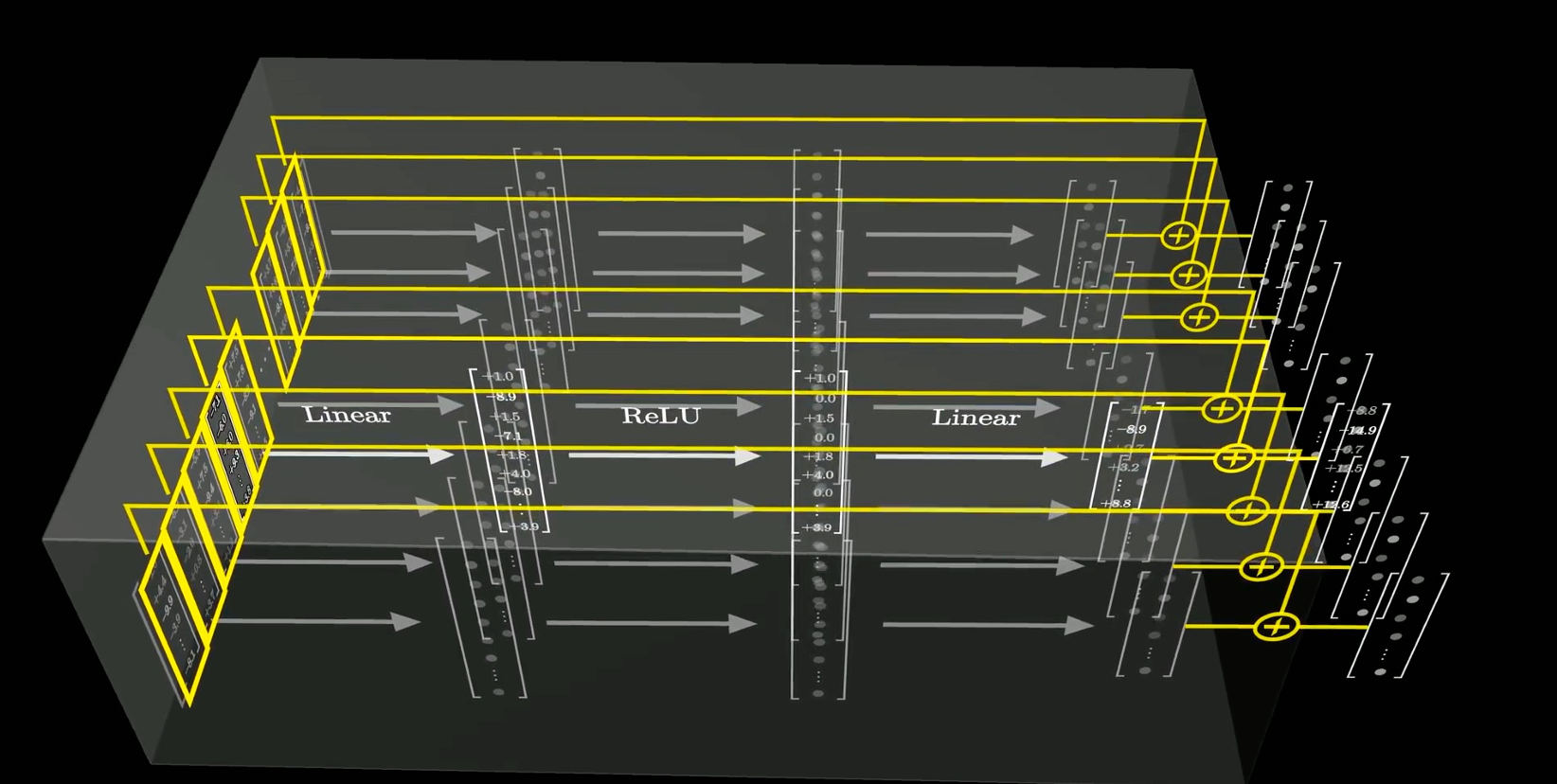
每个层中的每一行都相当于在问某个词的问题,从而修饰每个词。例如:是迈克尔乔丹还是约旦?
得到结果后向该词的方向偏移
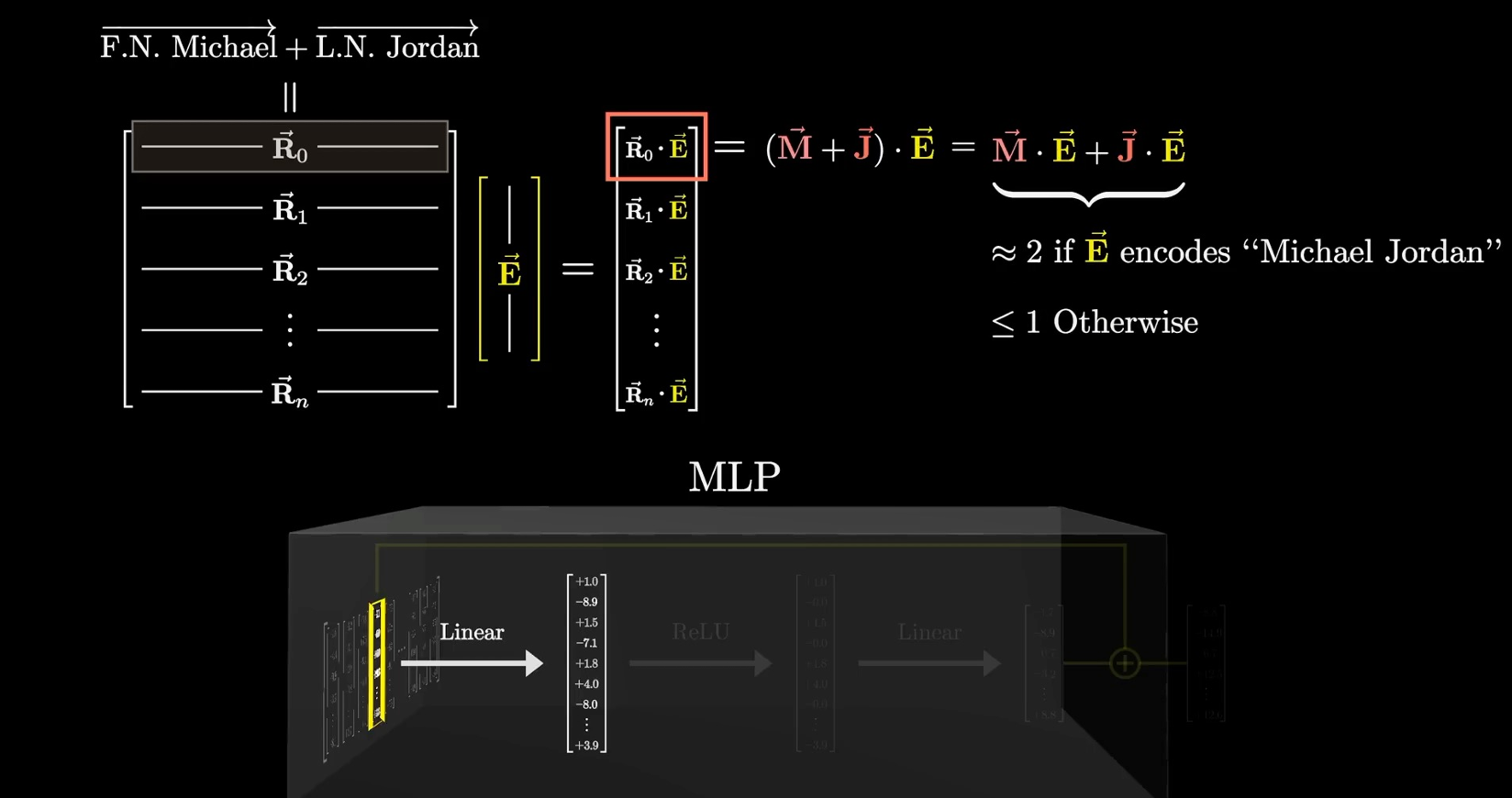
Each column stores facts: what will be added to the result if the neuron is active
- 每一列存储了某个概念的属性,例如:MJ是23号,1963年出生,拿过6次总冠军…
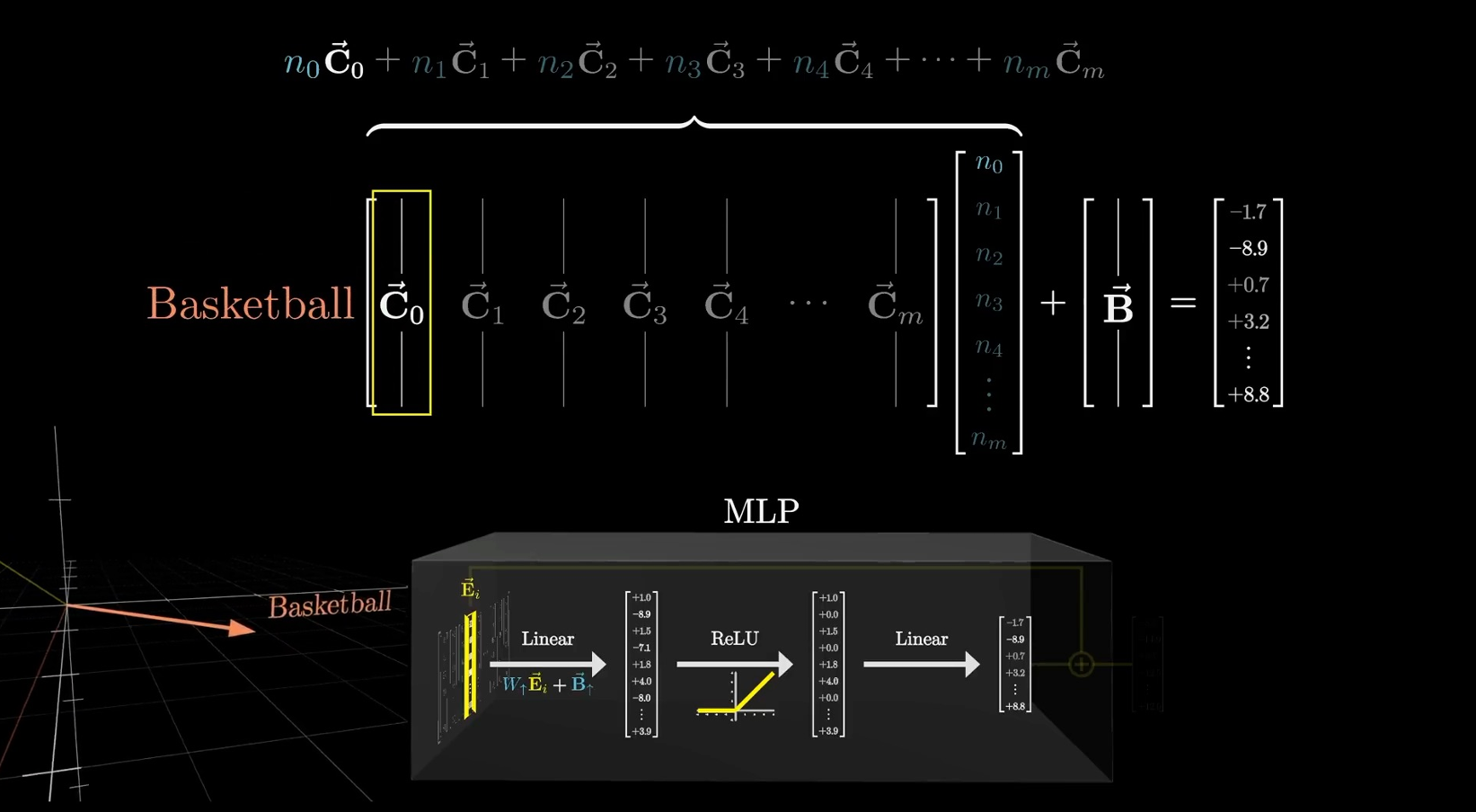
The super-position effect
- 参数量越大,表真方向越多,可以表示更多样的概念
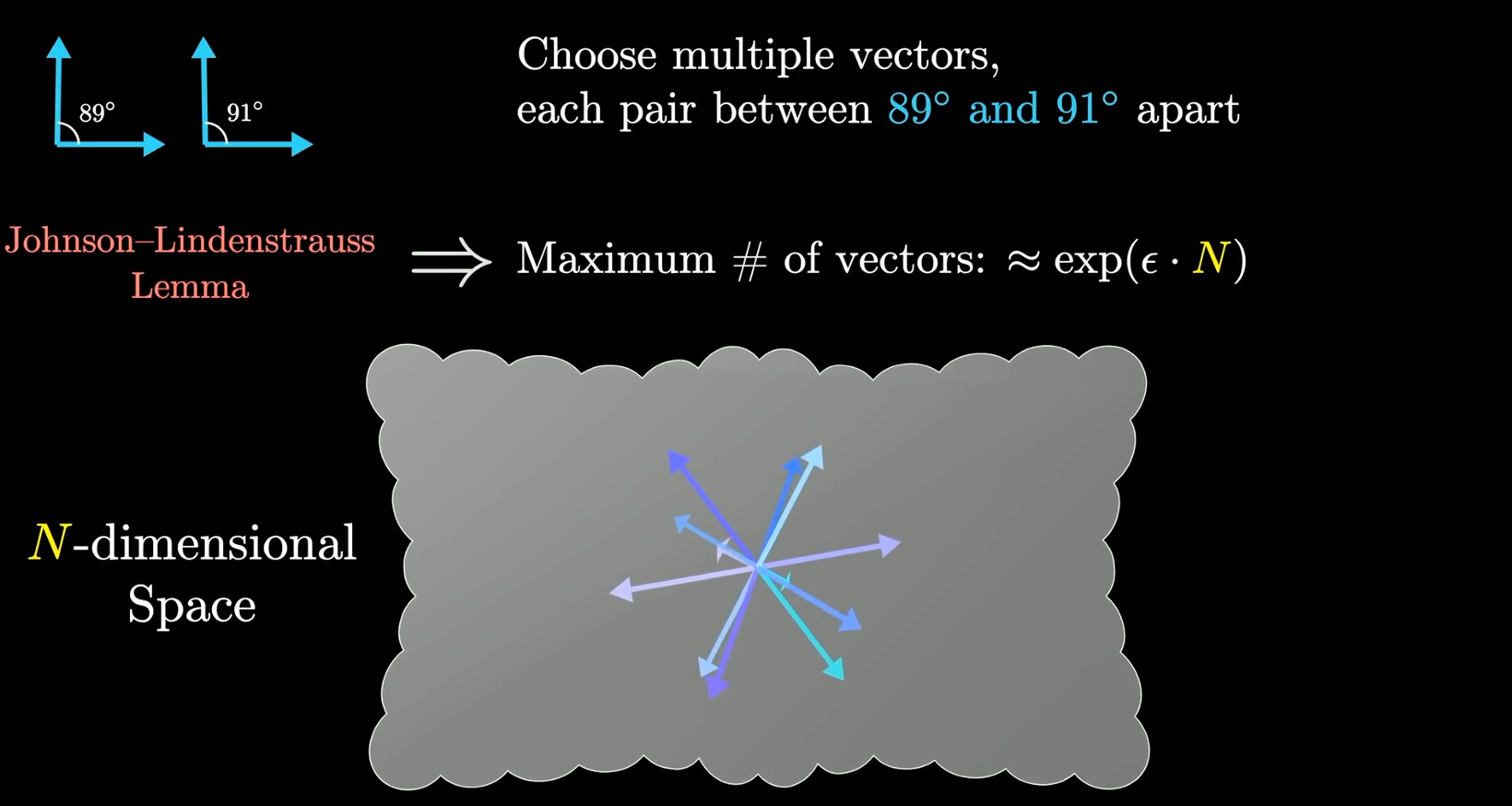
total size

Related Articles

