
大模型基础与对齐 03 DeepSeek & LLaMA
DeepSeek Details
The DeepSeek-V3 Architecture
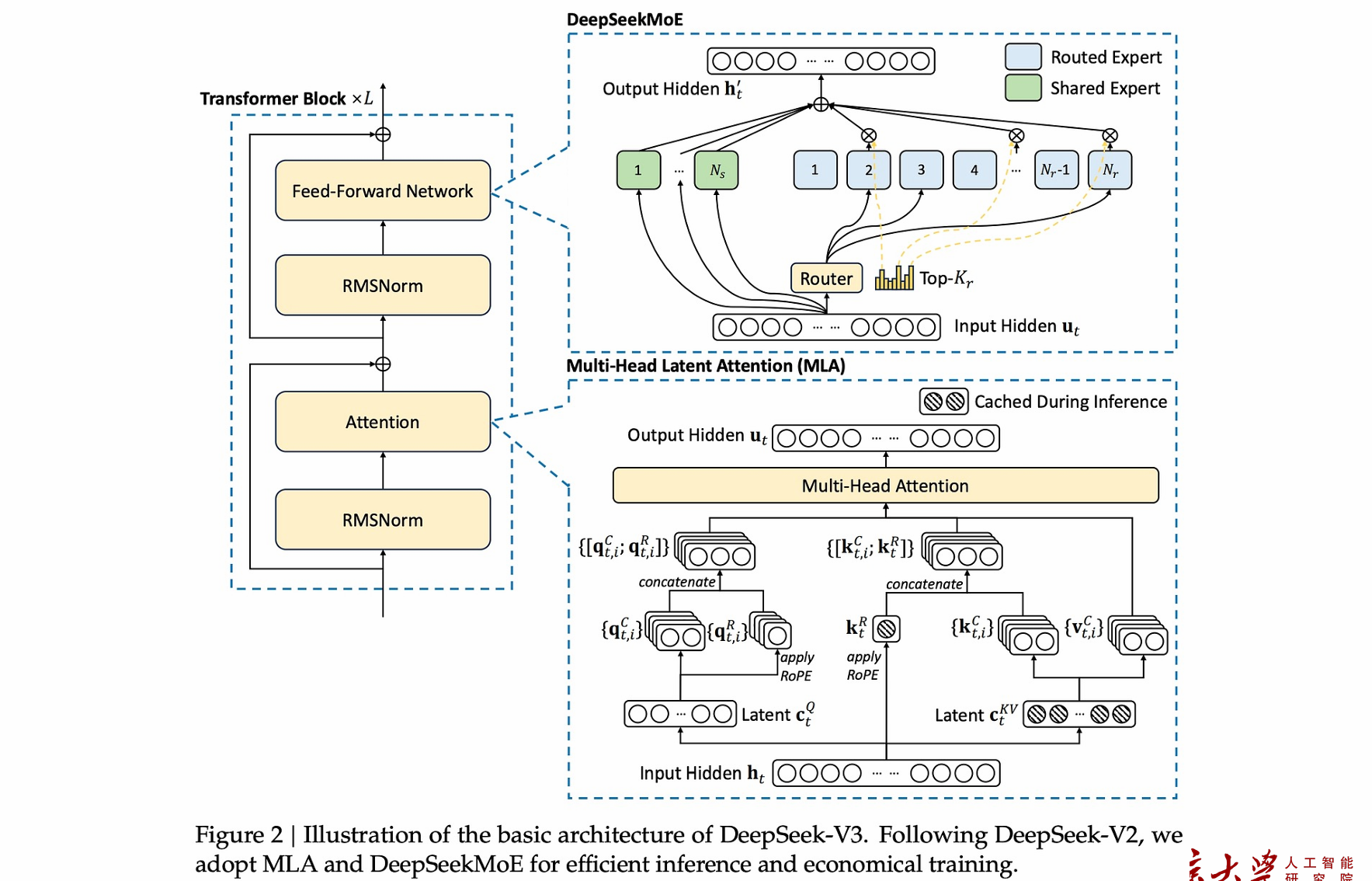
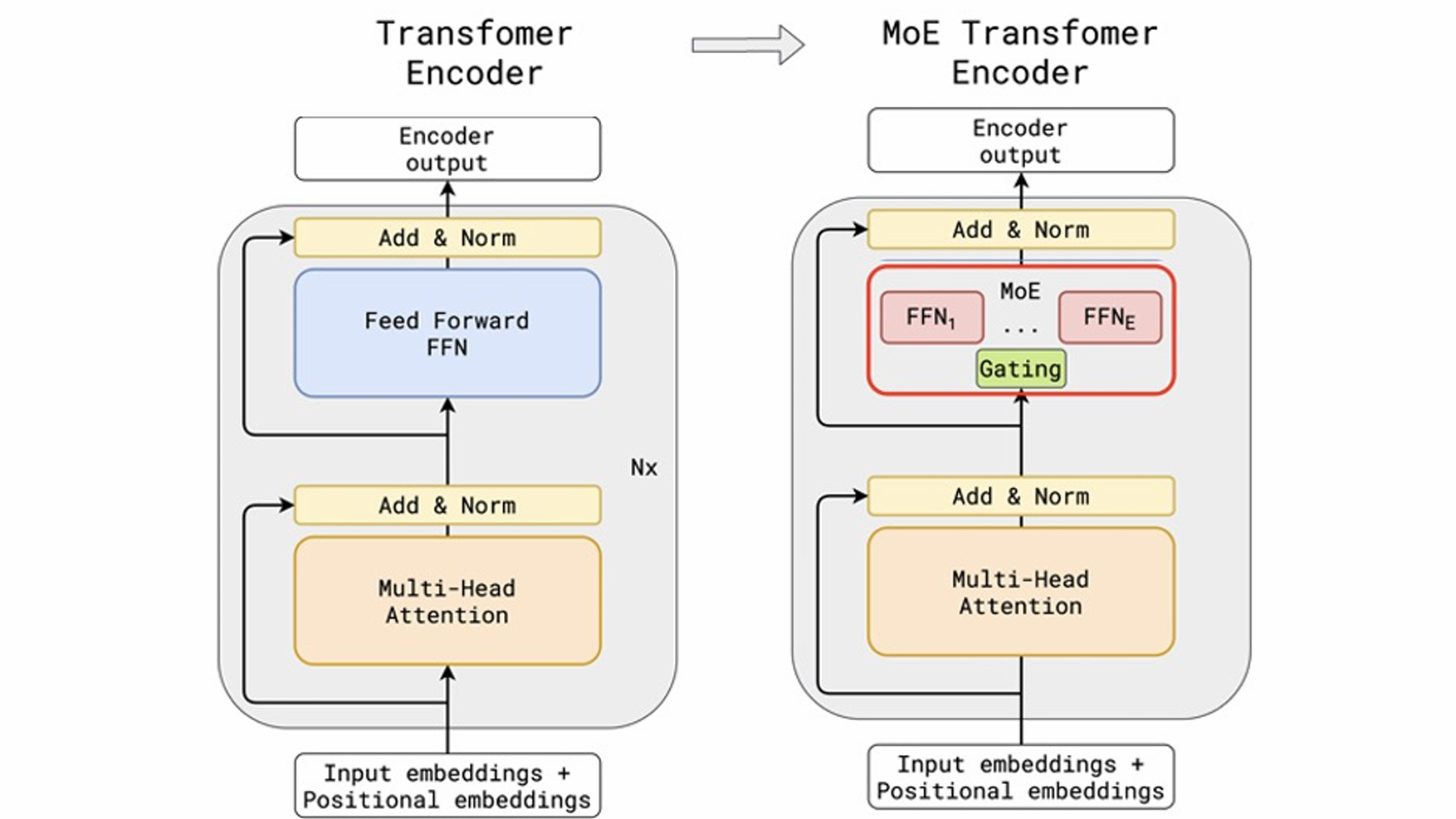
The Mixture of Expert(MoE)
将transformer中的FNN编程多个小的FNN
决定走哪个小的FNN取决于专家选择,将专家合在一起
总的计算量不变
- 专家数量增加,颗粒度越精细,同时设置shared专家
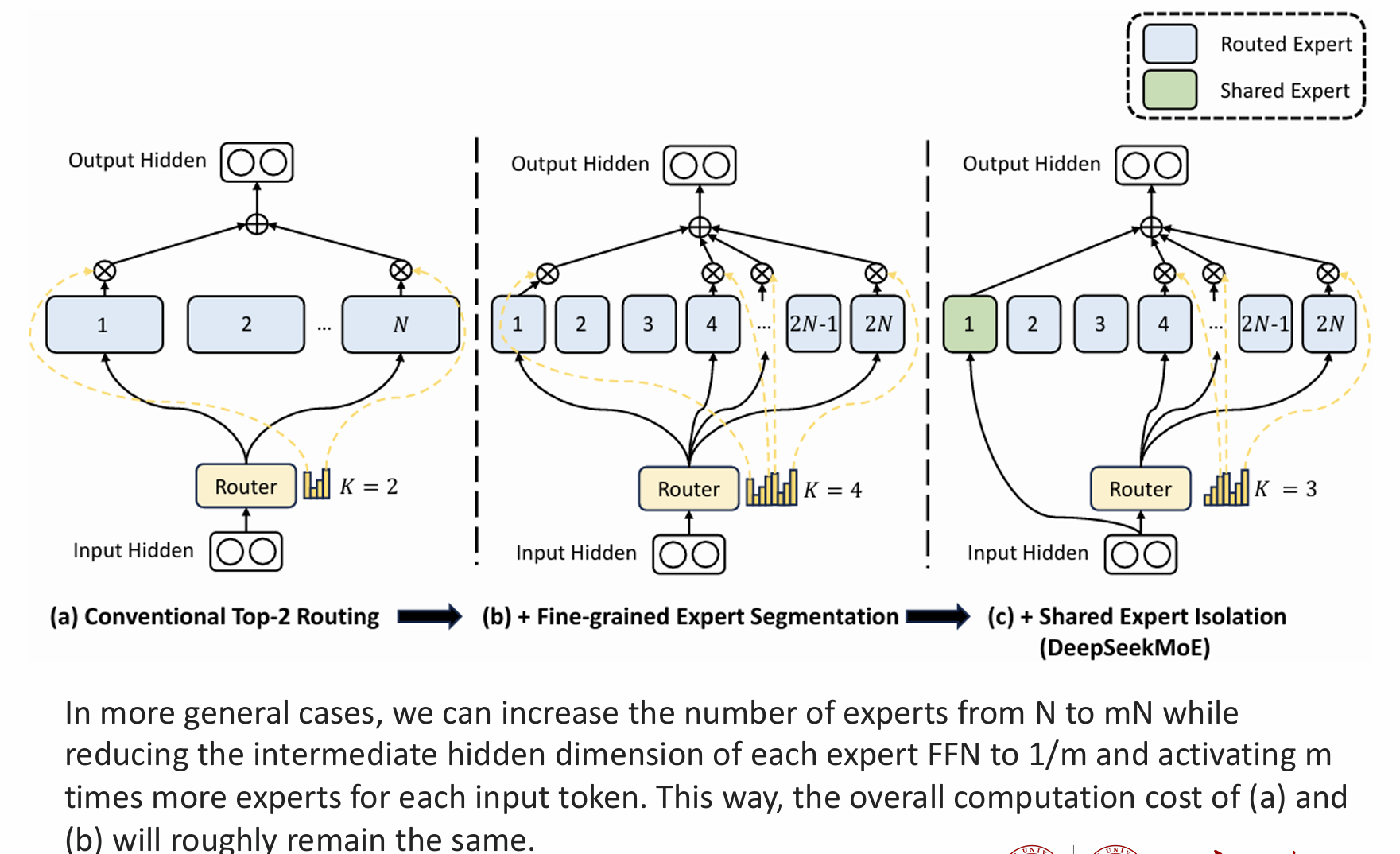
负载均衡的路由策略:为解决MoE中专家负载失衡可能导致的“路由塌陷”问题(即部分专家过载而模型性能下降),DeepSeek-V3提出了无辅助损失的负载均衡策略。传统MoE(如 GShard、Switch Transformer)需要在损失函数中加入均衡项来惩罚不均衡,但过强的辅助损失会损害模型性能
DeepSeek-V3引入动态偏置:为每个专家的得分增加一个可调偏置,仅用于路由决策,不影响实际输出权重。训练中每步监控各专家的使用量,若某专家过载则降低其偏置,反之增加偏置,以动态平衡专家流量
Expert choice: 让expert选token而不是token选expert,传统的token选择expert方法在路由过程中无法控制每个专家接收的token数量,容易导致负载不均衡
偏执项不直接参与作用到梯度计算中,避免了权衡load balance在loss中的权重
The Multi-head Latent Attention
- 低秩key-value压缩:MLA的核心思想是压缩key-value成一个更紧凑的表示——latent vactor,存储的时候只用存latent vector

- 为了更进一步的节约显存,也可以对query进行压缩:
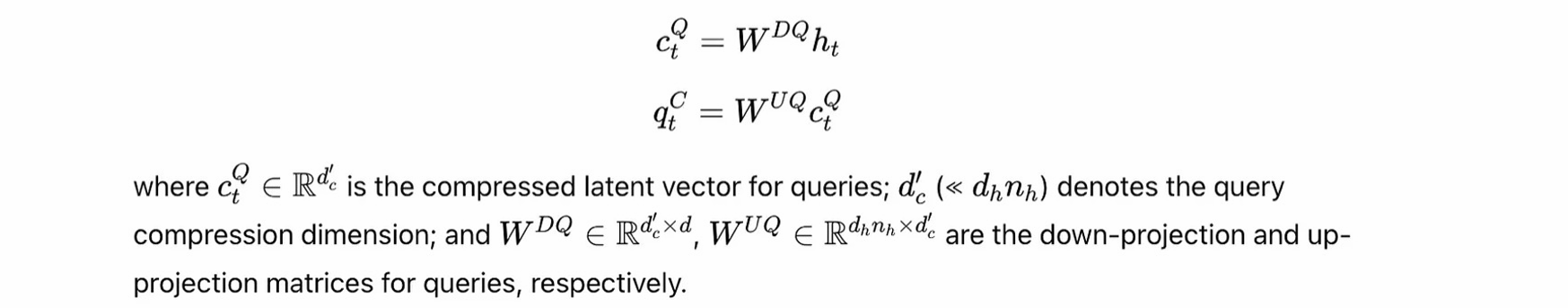
降低显存可以进一步增加窗口长度,提高了对长窗口上下文的支撑能力
DeepSeek-V3能够支持超长上下文(其上下文长度经两阶段扩展到32K乃至128K)而不会因为缓存开销爆炸
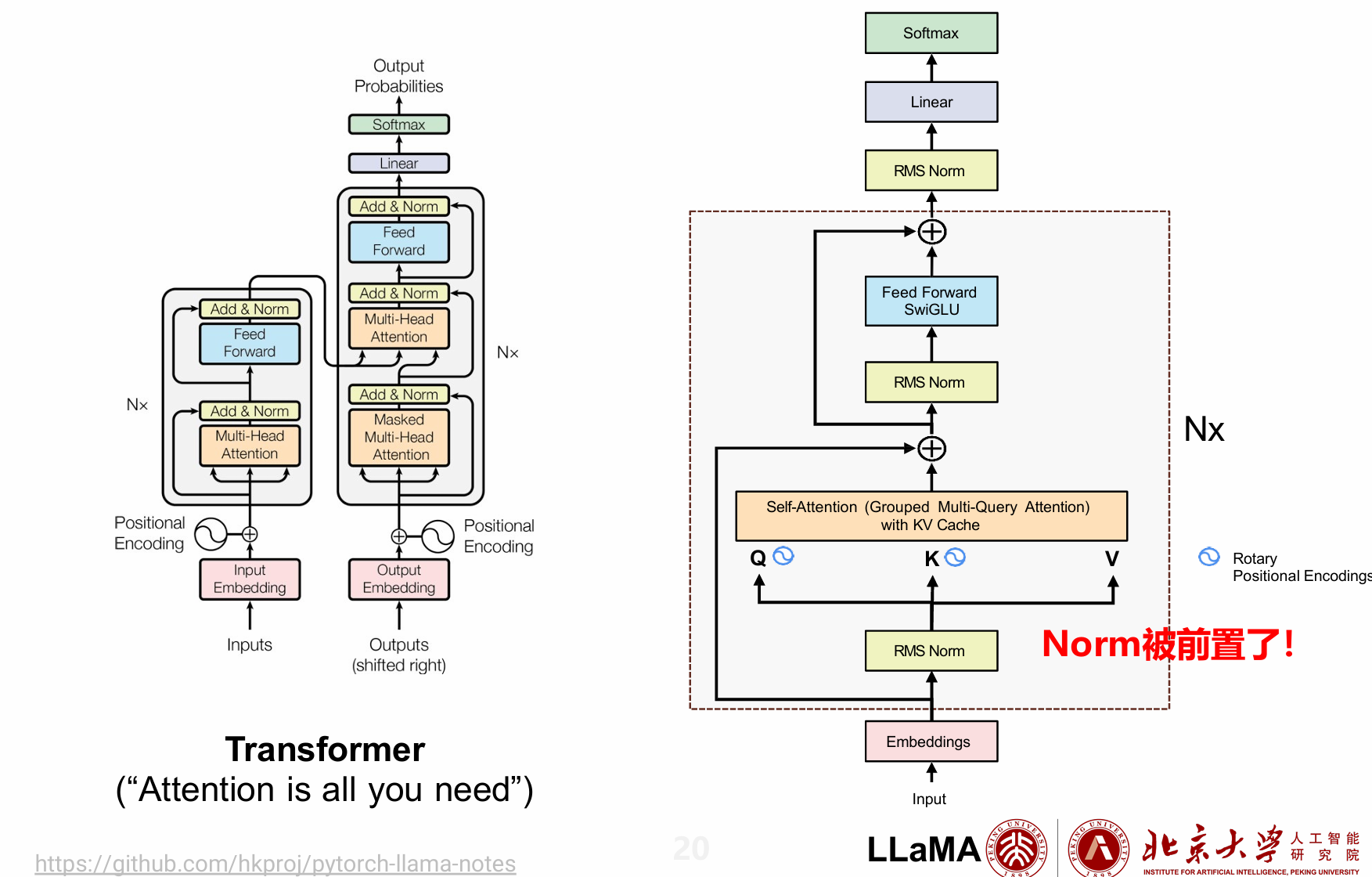
The Llama Architecture
- New Architecture:
- Architectural differences between the vanilla Transformer and LLaMA
- RMS Normalization (with review of Layer Normalization)
- Rotary Positional Embeddings
- KV-Cache
- Multi-Query Attention
- Grouped Multi-Query Attention
- SwiGLUActivation Function
The Llama Architecture
The Layer Normalization
Batch norm在NLP不适用,因为句子会变长,没有办法每个batch中句子的长度
LayerNorm的问题:计算均值非常消耗时间,从而引入RMSNorm,但是计算准确度会降低一些
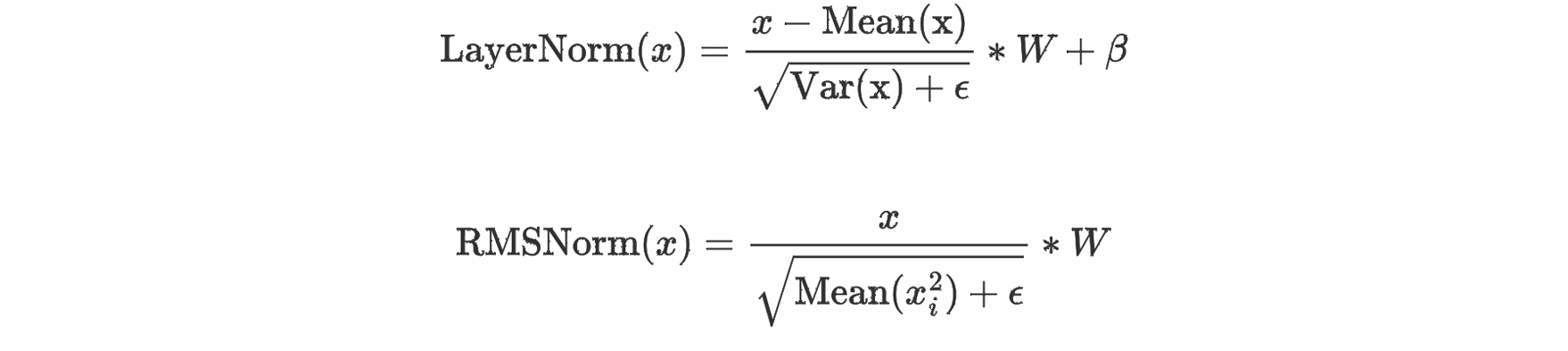
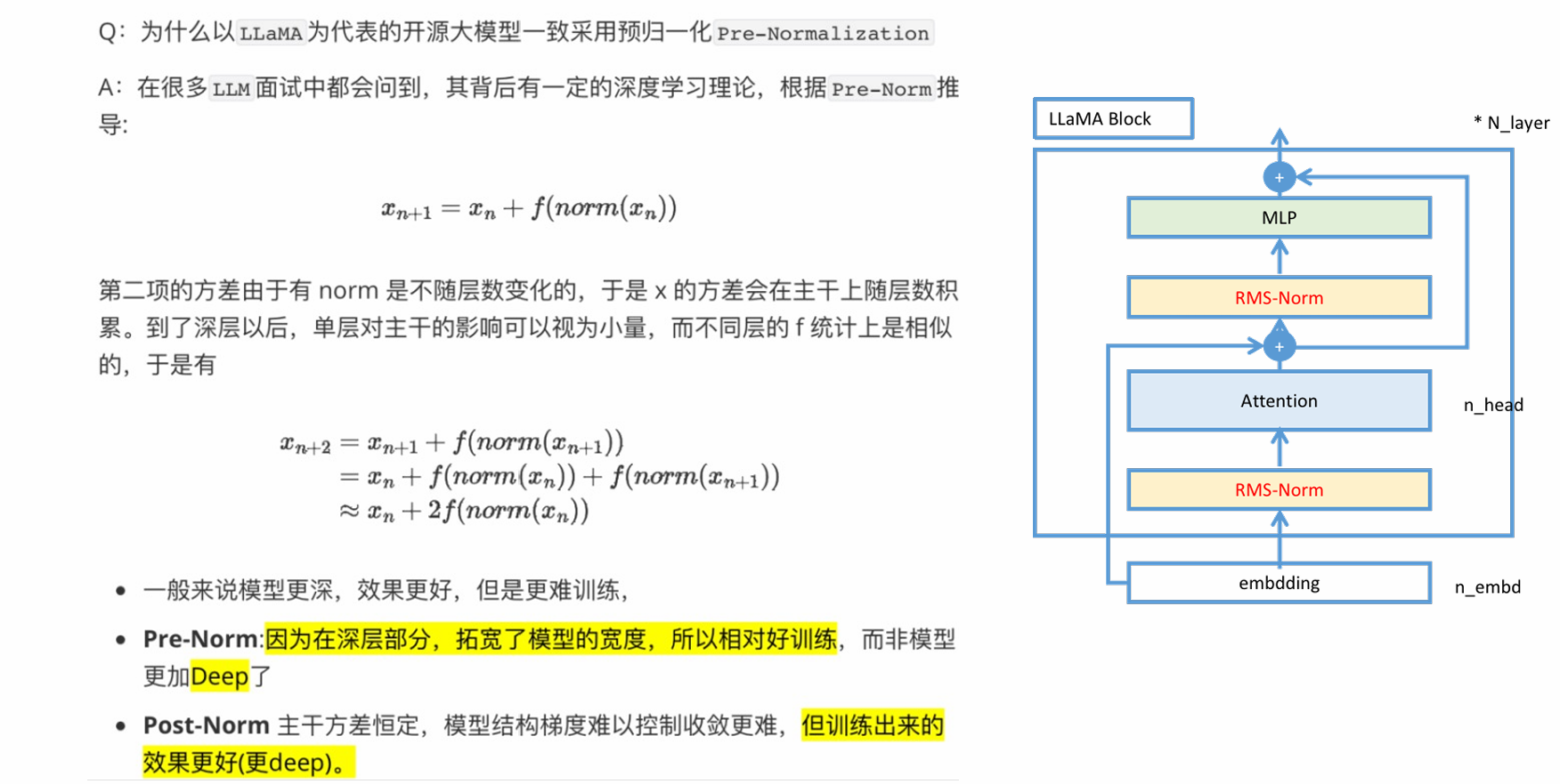
- 前置layer norm的原因:
The Position Embedding
在 NLP 任务中,输入通常是序列化的数据(如句子),单词的顺序是非常重要的
虽然 Transformer 能够通过自注意力机制捕捉输入序列中各个元素之间的关系,但它本身对输入的顺序信息并不敏感
因此需要一种方式将顺序信息传递给模型,这就是Positional Embedding的作用
为什么不能用01编码:
- 不高效
- 不能表达距离越远越不重要,距离越近的上下文影响越大
固定位置编码
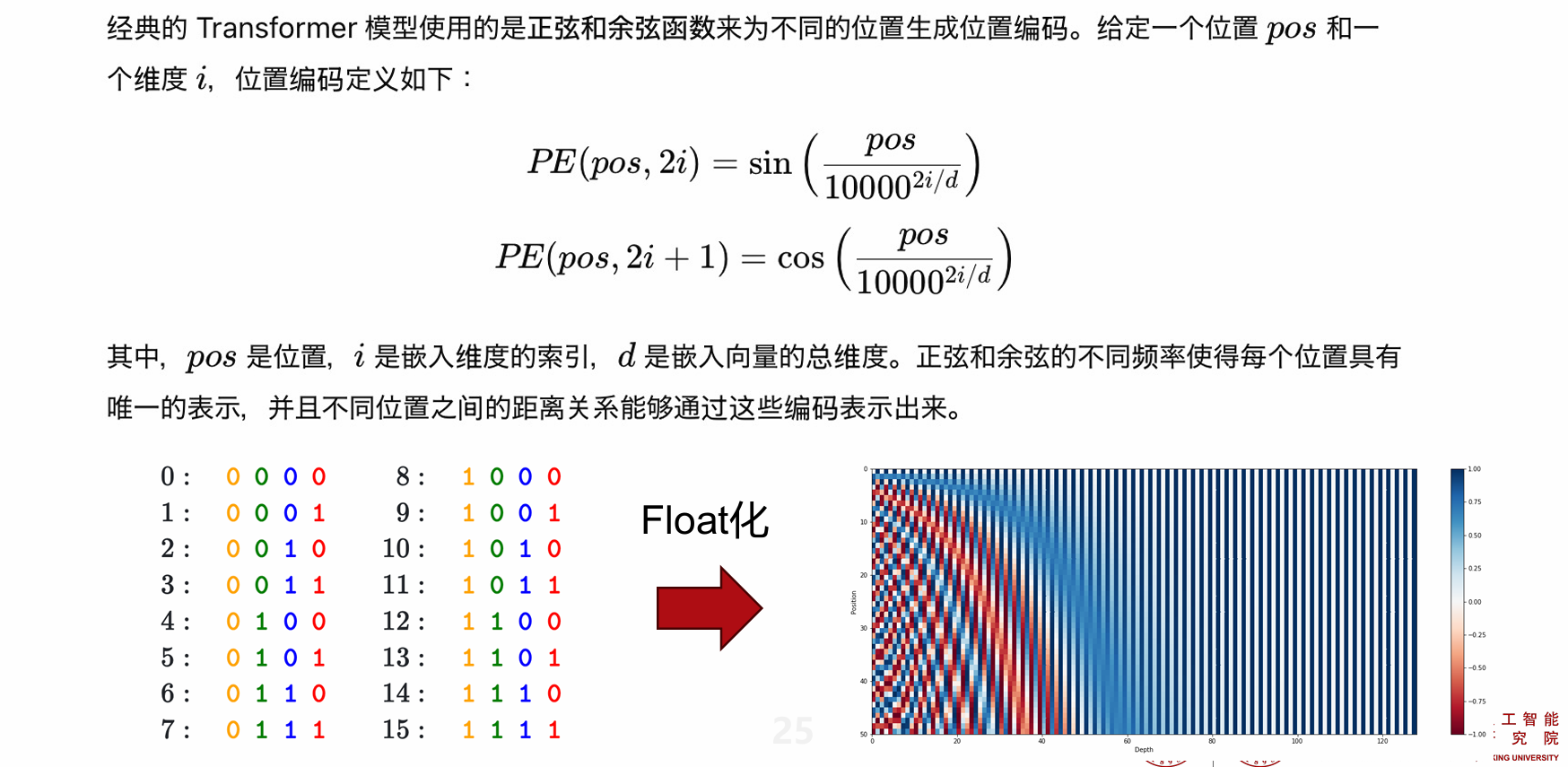
sin/cos编码的优点:
- 位置编码具有平滑性
- 具有相对位置信息
- 具有周期性可以无限延伸,具有可扩展性
position embedding和embedding的size一定相同,直接相加形成embedding input
相对位置编码
绝对位置编码:固定的向量,添加到词元的嵌入中,用于表示该词元在句子中的绝对位置。因此,它一次只处理一个词元。e.g.猫在桌子上,猫是第一个单词
相对位置编码:一次处理两个词元,并在我们计算注意力时起作用,由于注意力机制捕捉的是两个词之间的“关联强度”,相对位置编码告诉注意力机制这两个词之间的距离。因此,给定两个词元,我们会创建一个表示它们距离的向量。e.g.不关注猫出现在第几个单词,而是猫出现在前面还是后面,距离强度

The ROPE Position Embedding
注意力机制中使用的点积是一种内积,可以看作是点积的一种广义形式
能否找到一种内积,作用于注意力机制中使用的两个向量 q(查询)和 k(键),使其只依赖于这两个向量和它们所代表的词元之间的相对距离

写成矩阵形式,在二维相当于乘了一个旋转矩阵
ROPE只作用在Q和K上,将相对位置的编码加入到QK点乘计算中
n维通项公式:

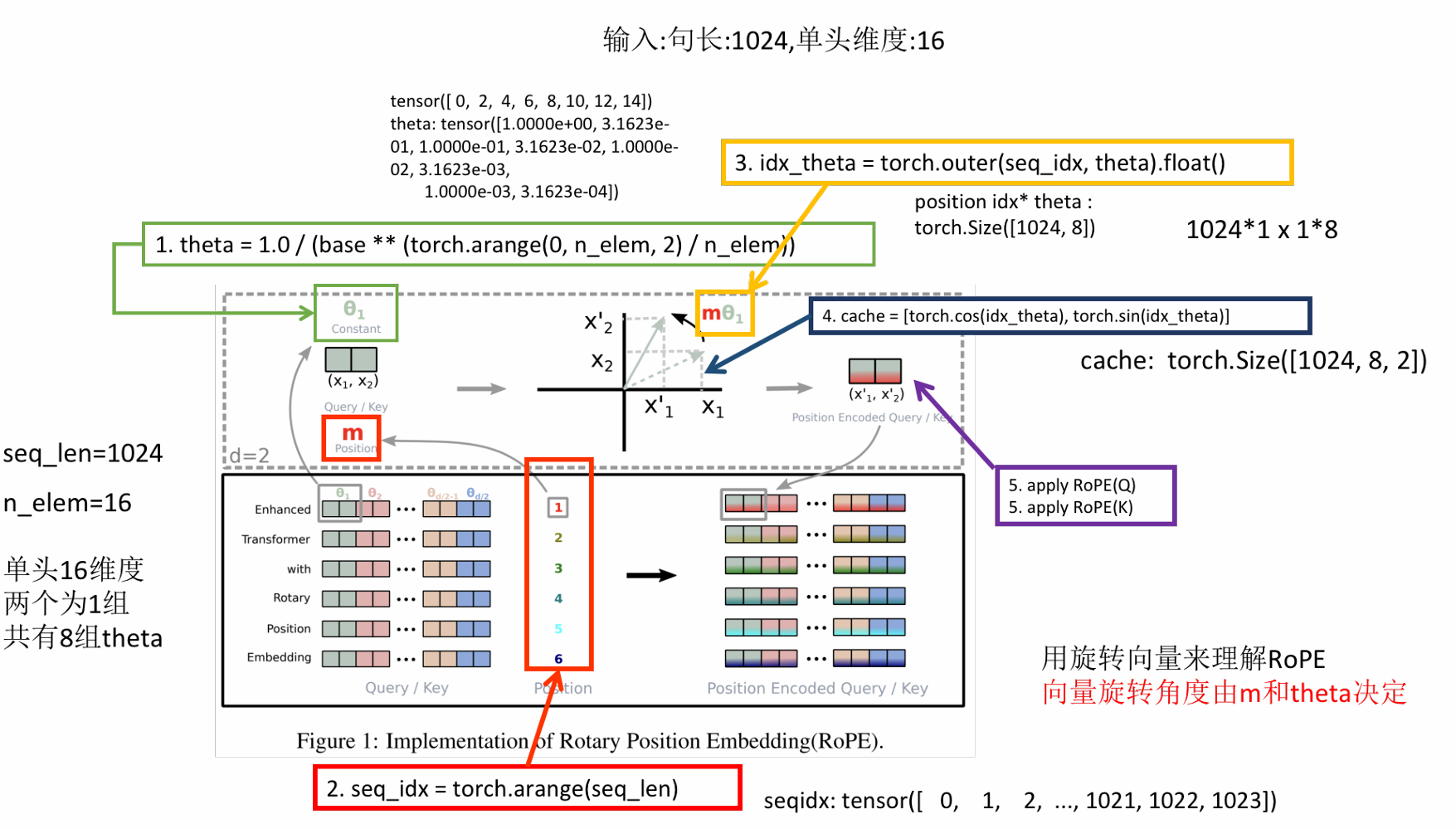
ROPE实现思路:
- 计算旋转因子theta:

- 计算序列索引:

- 计算旋转角度索引:

- 缓存sin和cos位置编码:

- 应用ROPE:

- 计算旋转因子theta:
应用ROPE后由于sin/cos的特性,距离越近的单词强度越大,影响越大,而距离远的单词的影响小
通过预训练或者SFT阶段进行长文本的拓展
长文本中的新位置是原位置的position/scale
只需要少量的成文本微调即可
拉长窗口


- 窗口过短:agent应用的时候无法处理强推理的任务
KV Cache
思路:每次新来一个Q,此前的K和V已经算过了,因此可以将其存储下来,此前的K和V本身不会改变
每次计算完以后,k,v矩阵只会加一行或一列
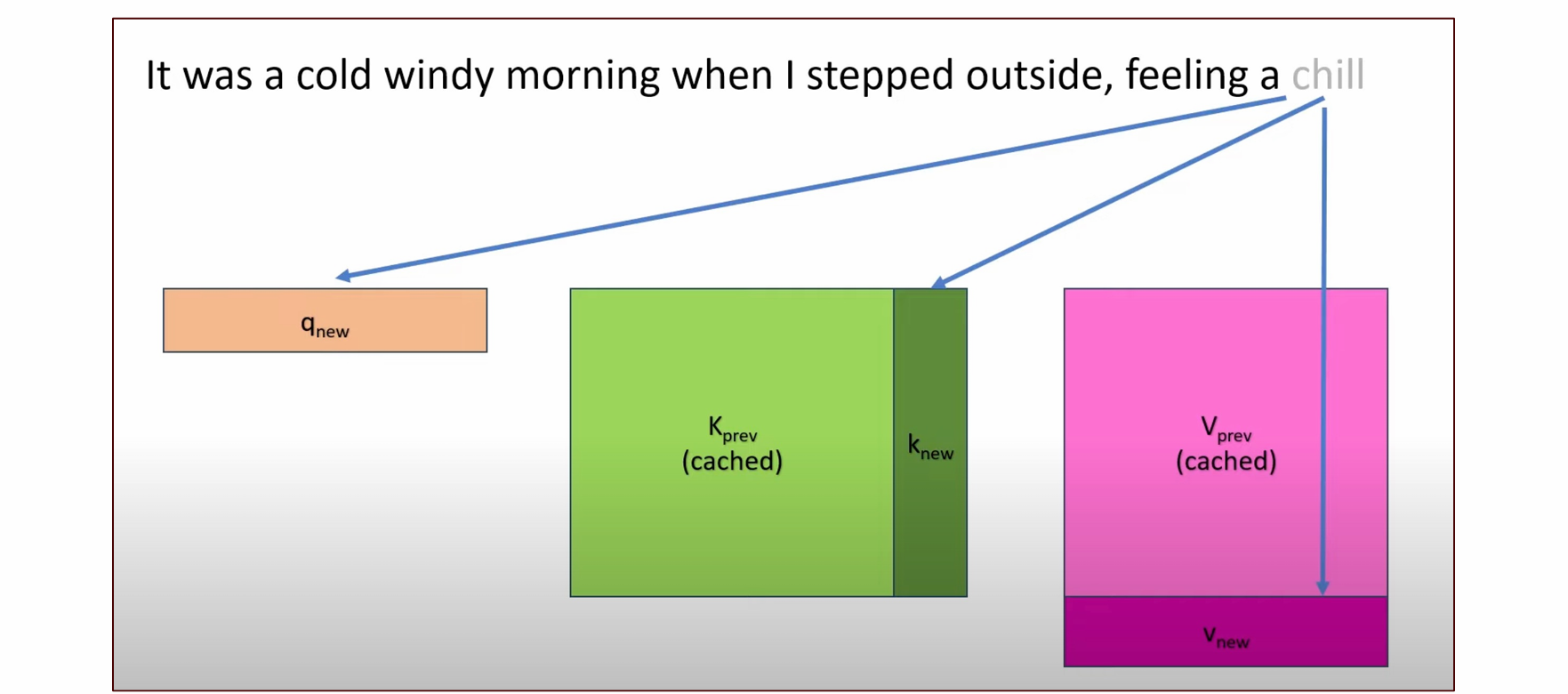
可以提高计算速度,是“空间换时间”,损失更多显存,空间占用率非常高
也正因如此,问完问题后,第一个单词生成时间很慢,而后续单词的计算时间大幅提高

- KV Cache处理不当会导致三个层面现存浪费:
- Reservation 涉及为页面或块预留空间以加速存储管理,某片空间不能使用
- Internal fragmentation 是由于固定大小的页面未被完全利用造成的内存浪费,固定大小的内存块还没用完就去用其他块
- External fragmentation 是由于分散的空闲内存块无法形成连续空间,导致无法为较大请求分配足够的内存
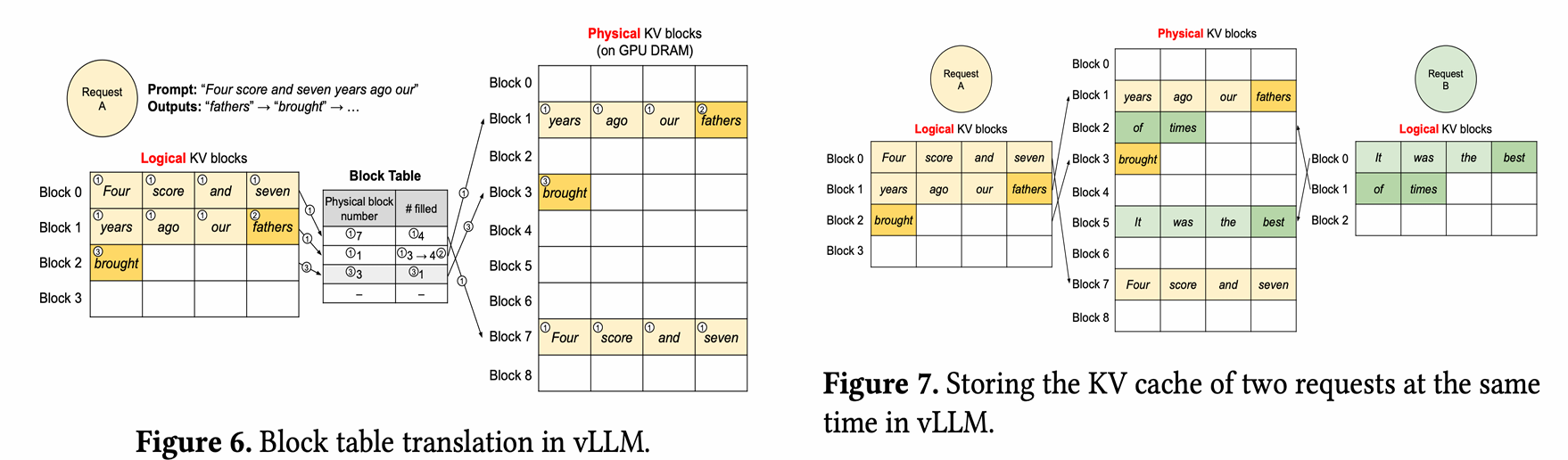
Paged Attention with KV Cache
PagedAttention 将数据的逻辑组织与其物理存储分离。属于同一序列的逻辑块通过一个块表映射到可能不连续的物理块上
划分 KV 缓存:KV 缓存被划分为固定大小的块或“页面”。每个块包含来自原始缓存的部分键值对
构建查找表:构建并维护一个查找表(block table),将查询键映射到存储相应值的特定页面。该表将每个可能的查询键映射到存储对应值的特定页面,从而实现快速分配和检索
选择性加载:在推理过程中,模型只加载处理当前输入序列所需的页面。与加载整个 KV 缓存相比,这减少了总体内存占用

summary
KV cache和Page attention都是用于提高模型推理效率的技术,尤其在自注意力机制
KV cache是指在处理序列时,将计算出的键(Key)和值(Value)存储在缓存中,以避免在后续的步骤中重复计算
在自回归生成模型中,如语言模型,使用KV cache可以加速推理过程。当模型处理新的输入时,可以直接使用缓存中的键和值,从而节省计算资源和时间
Page attention是一种特定类型的注意力机制,旨在处理更长序列或更复杂的上下文
它通过将输入序列划分为多个“页面”或段落来管理内存使用,并且通常在处理长序列时,能够有效地利用KV cache来减少计算复杂性
相辅相成:KV cache可以在Page attention中被利用,以提高对长序列的处理效率。Page attention可以将长序列分段处理,同时使用KV cache来避免重复计算,从而加速整体推理过程
Multi-head Attention
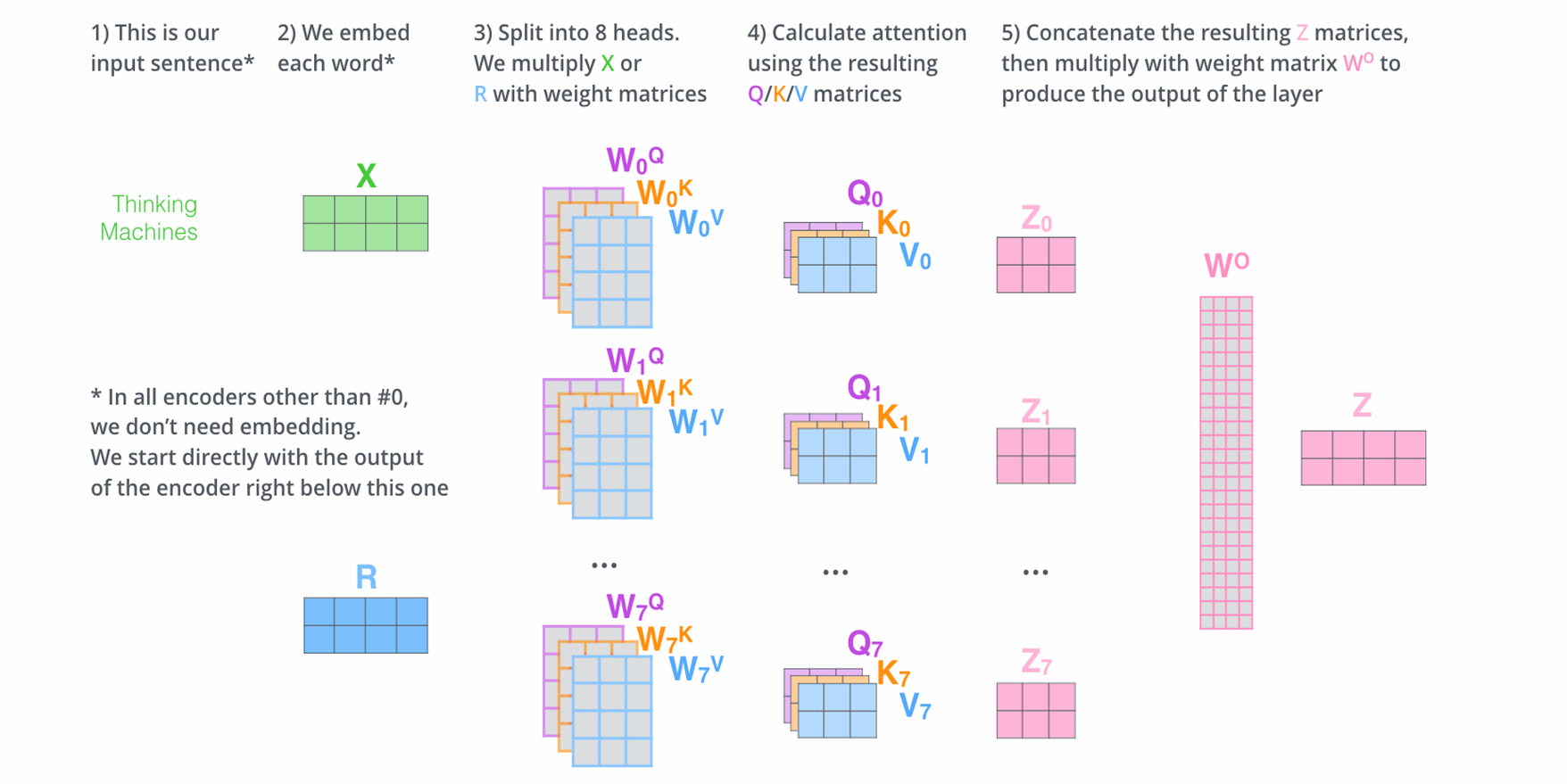
- 问题:
- 计算复杂度高
- 数据传输多,通讯效率低
- 存储墙问题


Multi-head Attention with KV Cache

因此大部分的时间都浪费在搬运算力而非计算本身
需要将Multi-head Attention和KV Cache有机统一:去掉h维度,但是不降低性能
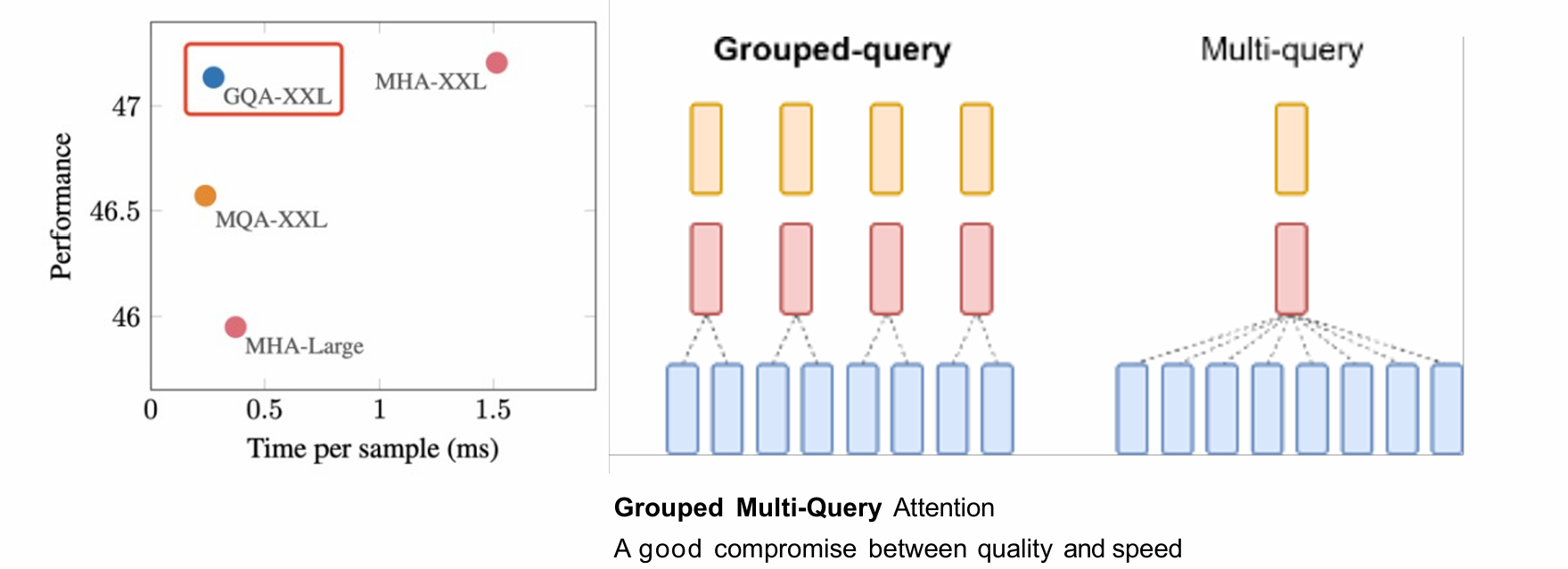
The Multi-query Attention

- 将k和v复制多份,并没有降低性能,因为仍是多头注意力机制
The Group-query Attention
SwiGLU Activation Function
- SwiGLU非单调,在0处连续,精度比ReLU要高
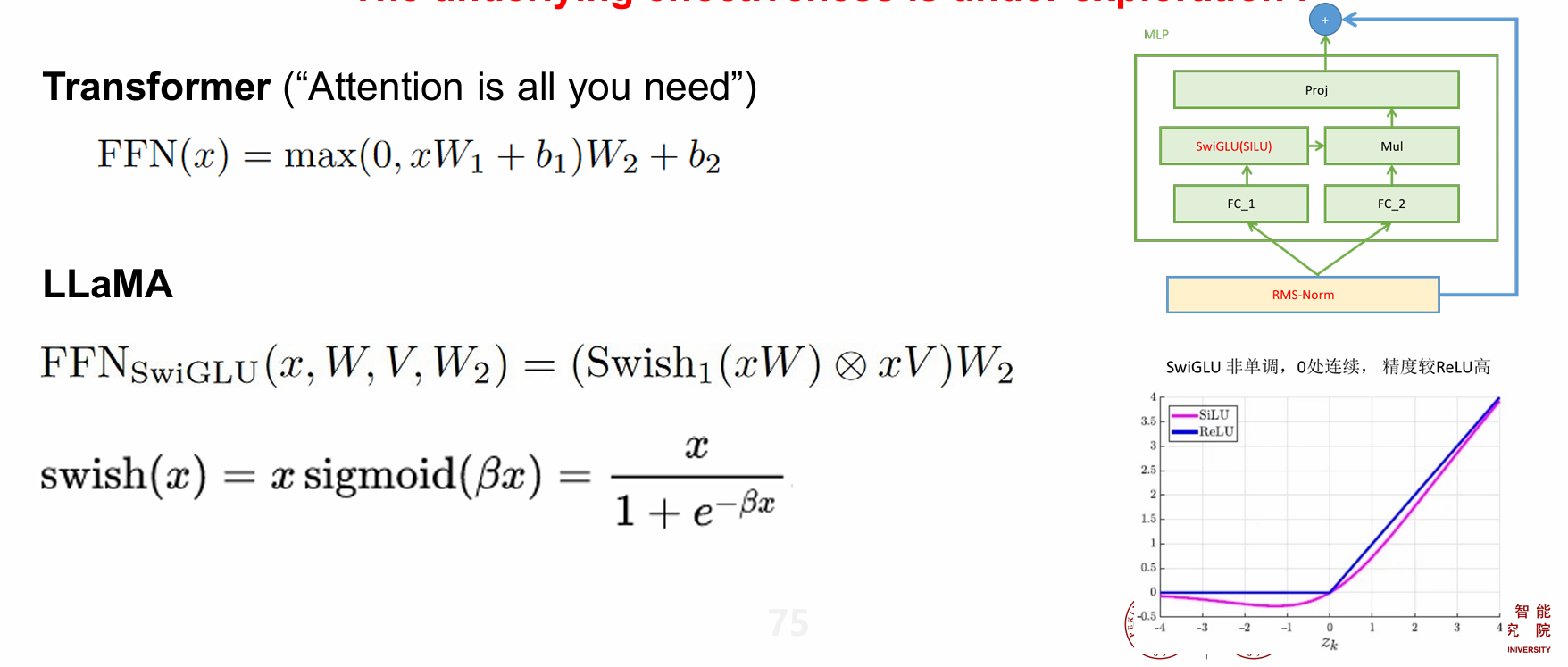
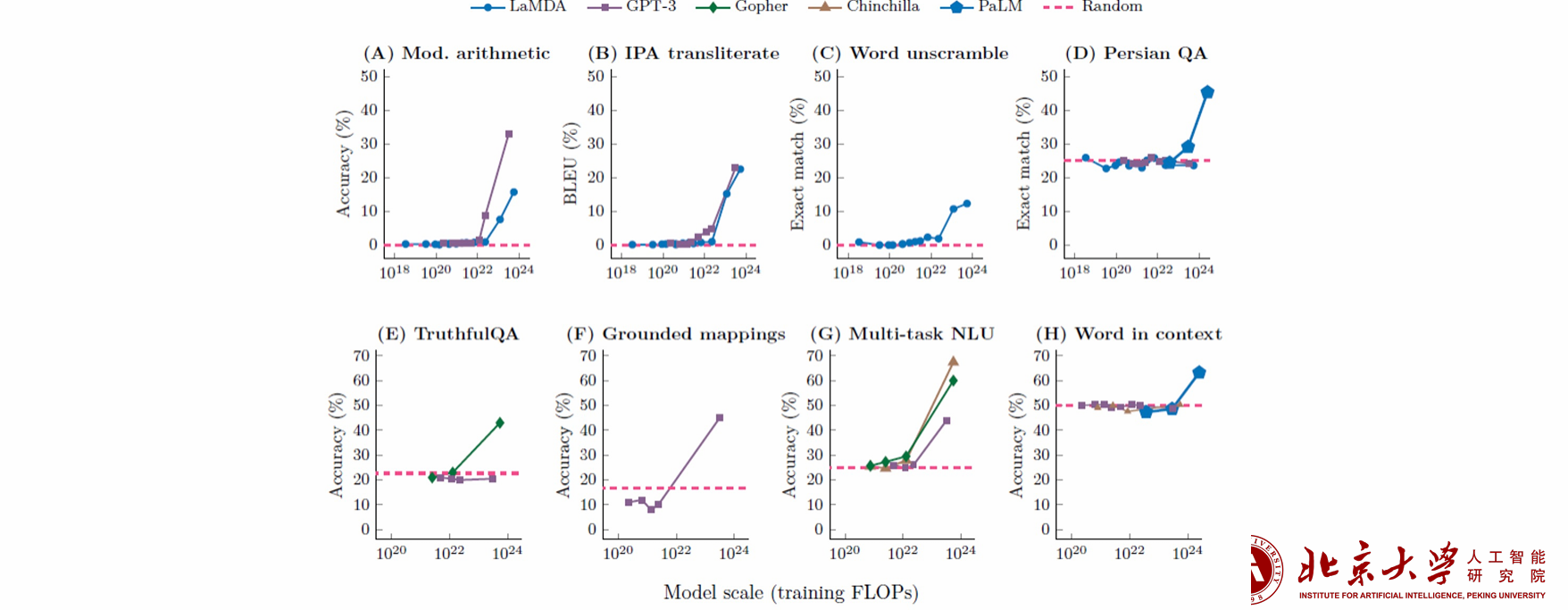
Emergent Capability
涌现是指系统中的量变导致行为的质变
性能几乎是随机的,直到达到某个临界阈值,然后大幅提高。可能的解释:emergent abilities
涌现能力只存在于大模型中,在小模型中不存在
锐度:涌现能力瞬间从不存在过渡到涌现
不可预见:转变出现涌现能力的规模是不可预见的
其他的解释:
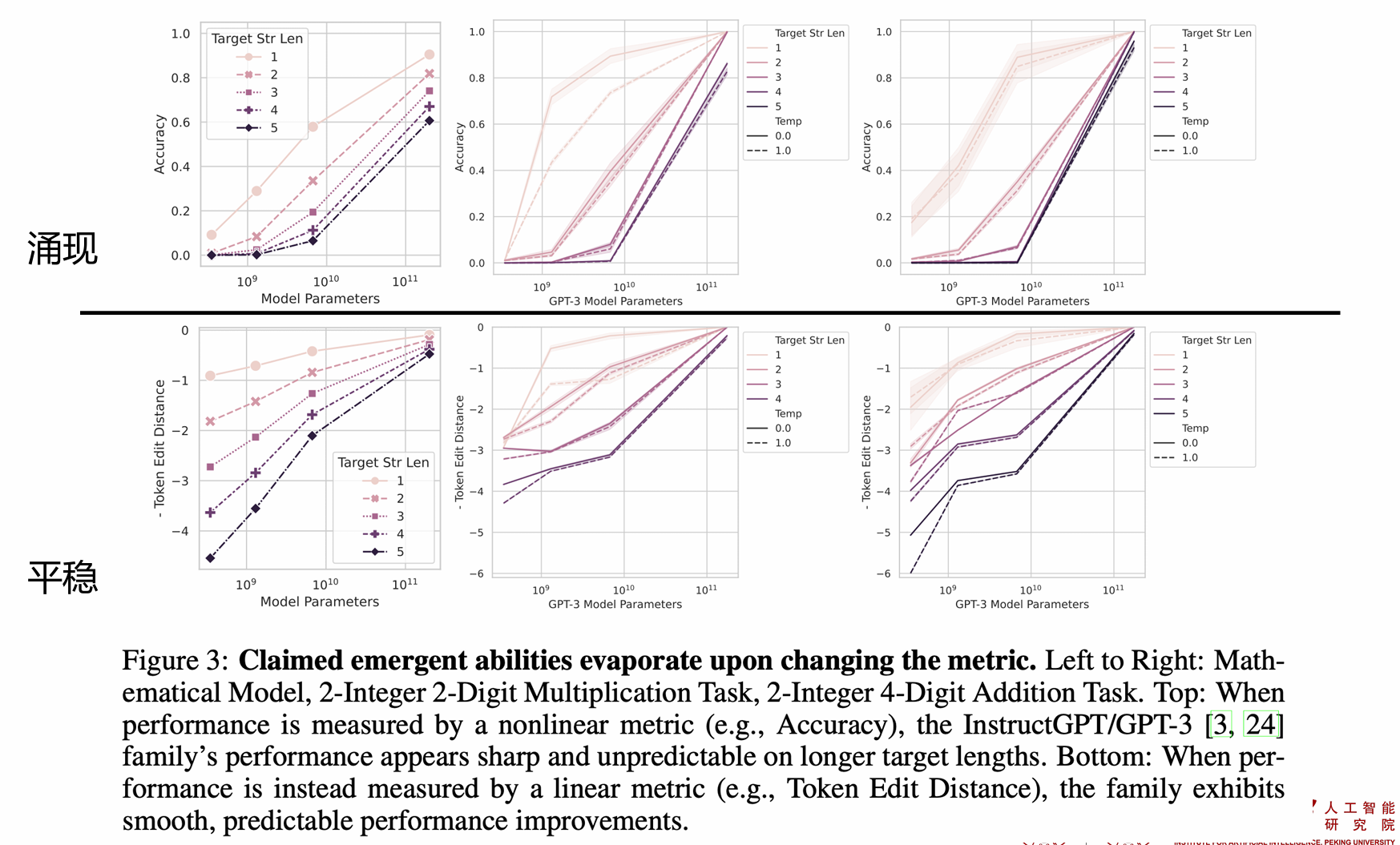
- 尽管模型族的 per-token 错误率会随着模型规模的增加进行平滑、持续且可预测地变化,但看似尖锐和不可预测的变化可能是由研究者选择的测量方法引起的
- 涌现能力的成因并非是随规模增长而导致的模型行为的本质变化,而是对非连续度量的使用
- 大模型的“涌现能力(Emergent Abilities)”并不是由模型规模本身导致的,而是由研究人员选择的评估指标(metrics)决定的。如果换用更平滑的指标(如Token Edit Distance),能力变化会显得更加平稳。Token Edit Distance 计算的是输出与正确答案的编辑距离,数值是连续变化的
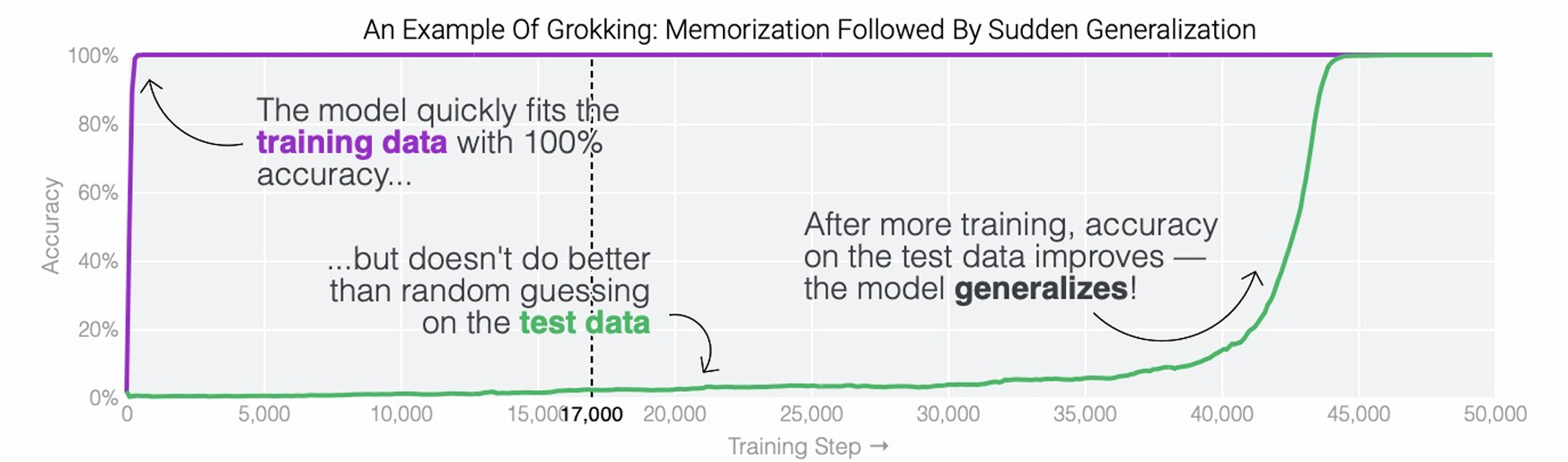
The grokking effect
泛化似乎在拟合训练数据后很长一段时间内突然发生,称为 grokking
权重衰减在提高我们研究的任务的泛化方面特别有效
随着数据集大小的减小,泛化所需的优化量会迅速增加
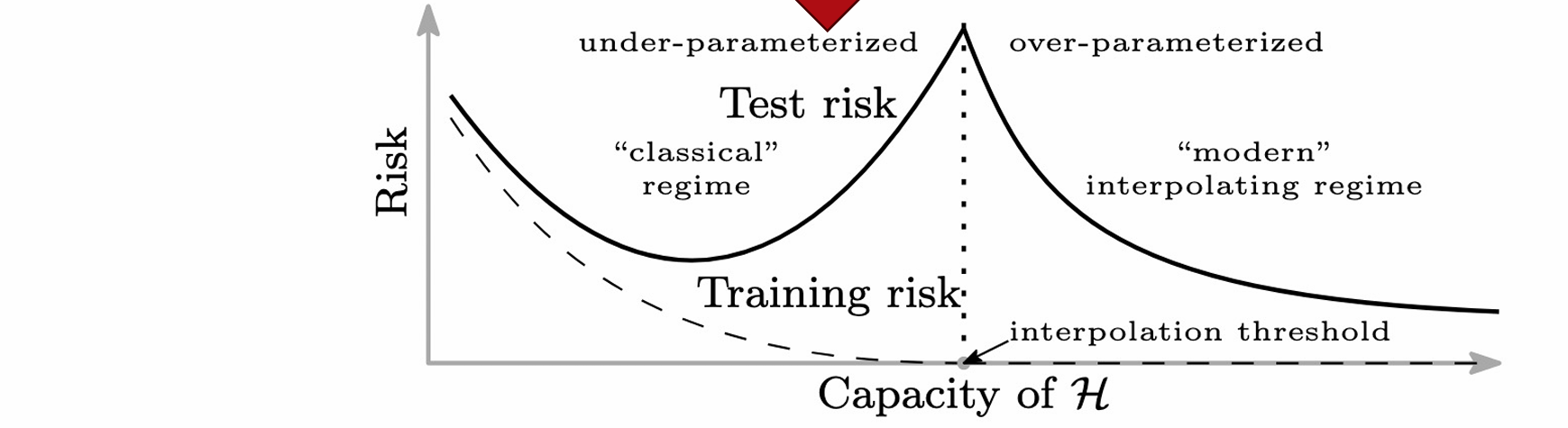
The double descent
Double Descent 的现象表明,在模型容量继续增加时,误差曲线会再次下降,形成第⼆次下降
这⼀现象打破了传统的偏差-⽅差权衡理论,在模型容量⼤到⼀定程度后,增加模型的复杂性不仅不会导致过拟合,反⽽可以改善泛化性能
模型泛化的提升:Grokking 和 Double Descent 都涉及模型在训练过程中的泛化能力如何随时间或模型容量变化。在 Grokking 中,模型通过长时间的训练获得了突然的泛化提升,而在 Double Descent 中,模型通过增加复杂性或容量来达到更好的泛化。这两个现象都表明了模型在某些条件下能够打破传统的泛化理解
异常的训练动态:Grokking 和 Double Descent 都展现了深度学习训练中的非线性、非单调的动态表现。在 Grokking 中,验证集上的误差可能在长时间内没有改善,直到突然变好。而在 Double Descent 中,误差会先上升,然后再次下降

