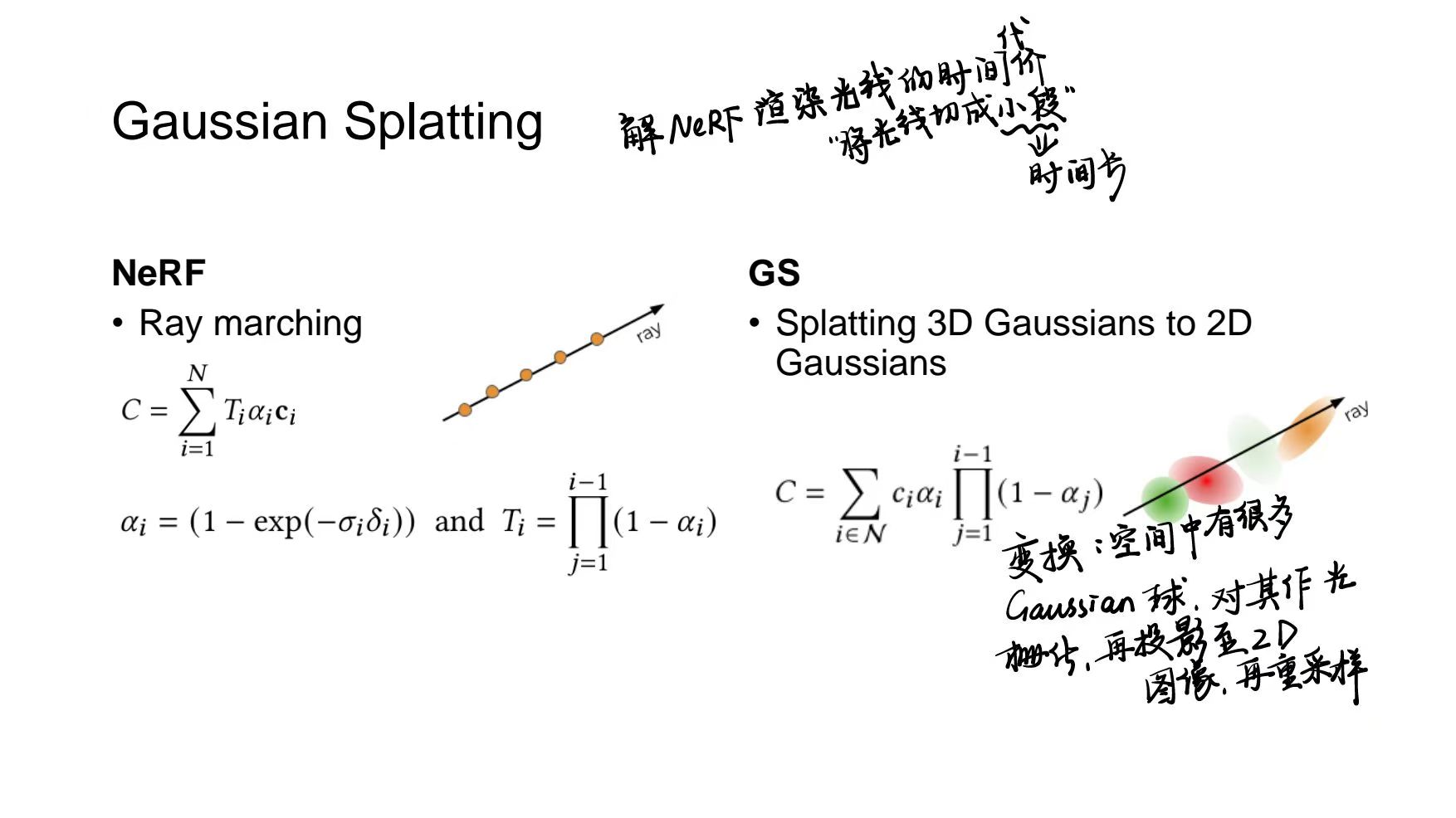
计算机视觉 10 Multi-View Stereo
Multi-View Stereo
和Two-View Stereo的区别:多张图片重建三维而非两张对应的图片
输入:使用校准相机拍摄同一物体或场景的多张图像
- 任意数量的图像
- 任意摄像机位置(摄像机网络或视频)
- 通常校准具有SFM或特殊设备的相机
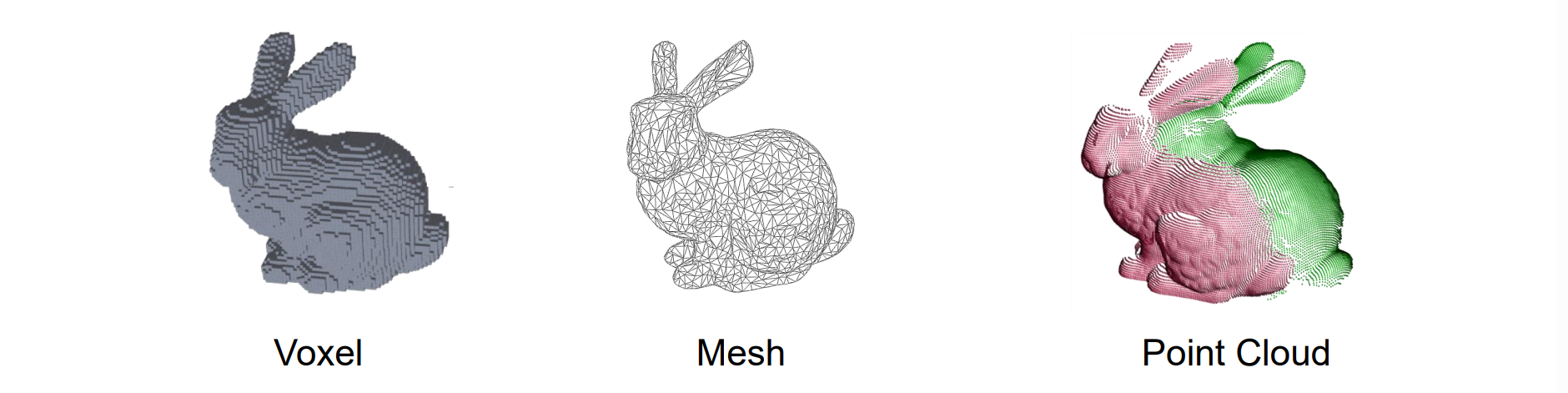
输出:计算相应 3D 形状的表示。不同于两相机的单视角深度问题,要求重建稠密的3D表达
- 体素表达:通过0,1控制显示
- 三角网络表达
- 点云表达
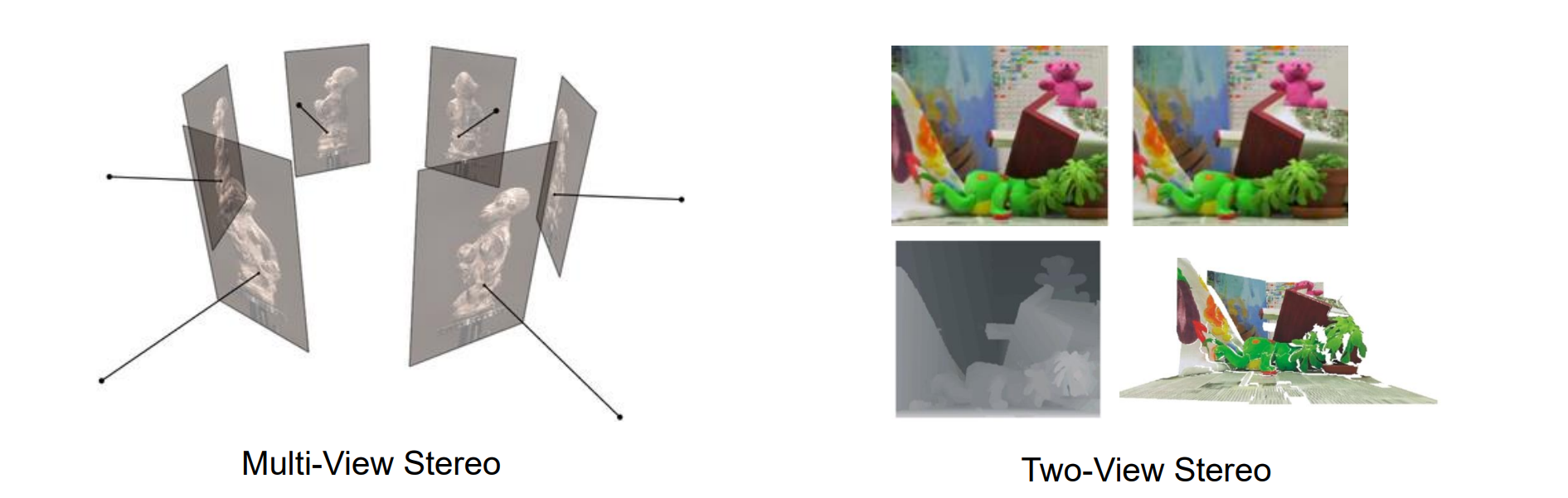
- 核心思想:多图片的一致性,稠密的重建要求稠密的一致性
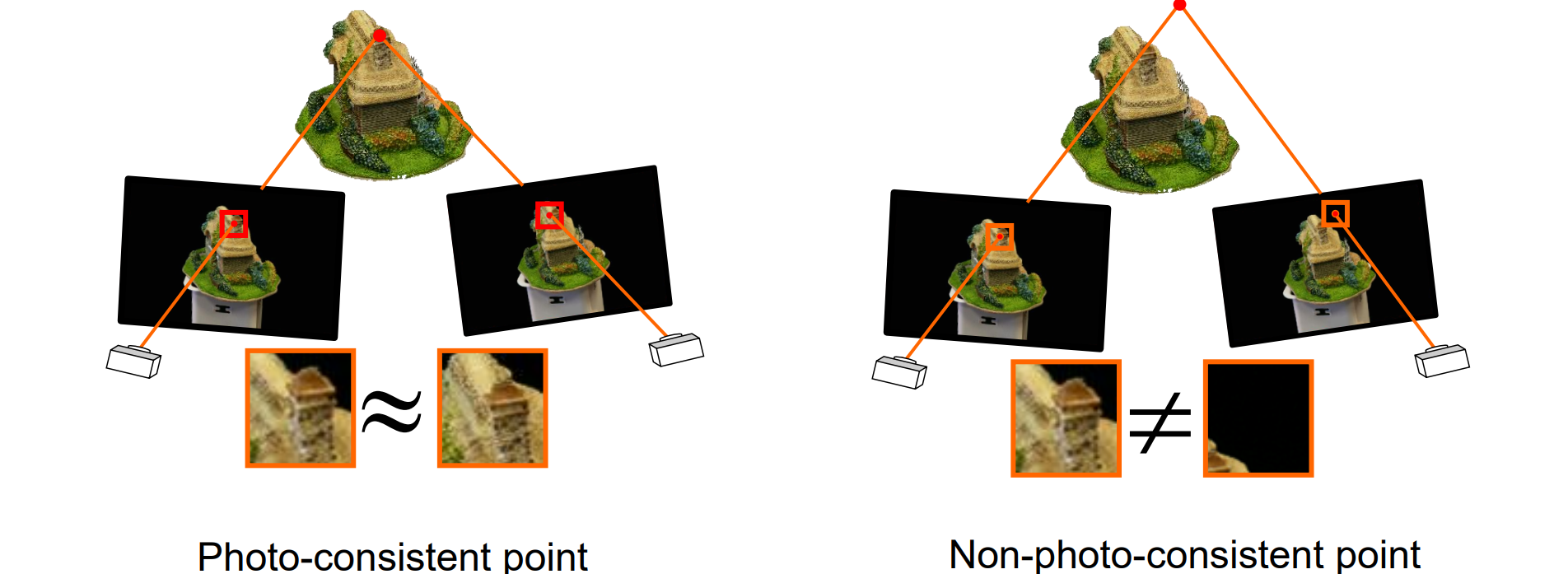
- 找一个参考图,衡量像素块的相似程度,构建函数图像找到误差最小的进行重建,其中,参考图在其他相机中的对应点都在极线上
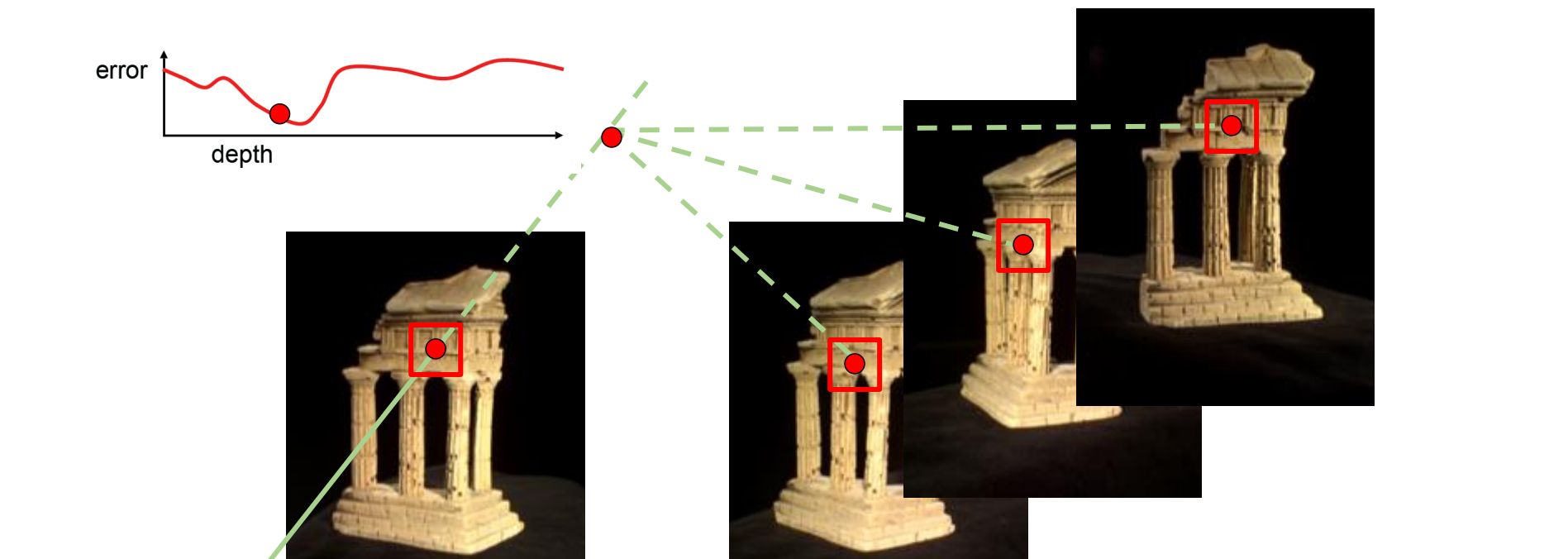
Why Multi-View Stereo?(为什么需要多个视角)
- 对象表面上的不同点在某些相机子集中将更加清晰可见。如果视角不够则可能出现遮挡,倾斜的情况从而导致重建出的3D物体不完整
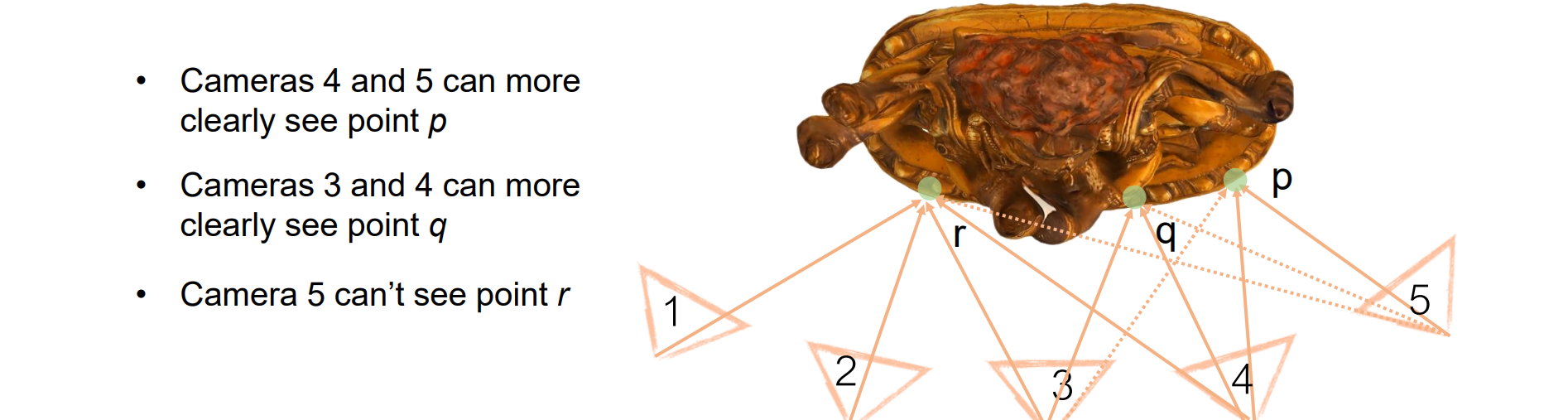
- 多视角可以减小误差使得相交区域更小从而形成更强的约束
MVS
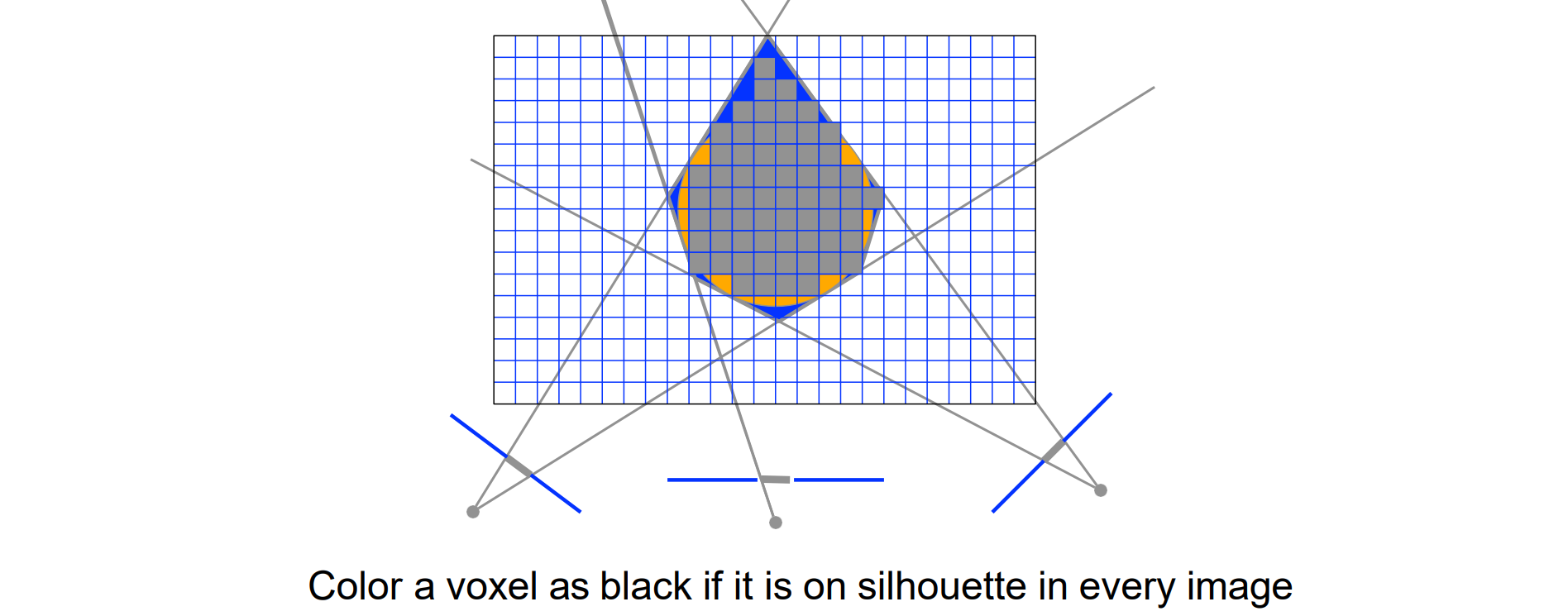
Visual Hull based MVS(基于体素)
核心思想:在多个(3个)视角进行拍摄,重建轮廓线:
- 有像素的部分记为1
- 没有像素的部分记为0
- 然后投影至3D
- 求交进行重建
如下图所示,三个相机进行拍摄,货色部分为物体的投影,然后投影到3D进行求交,重建
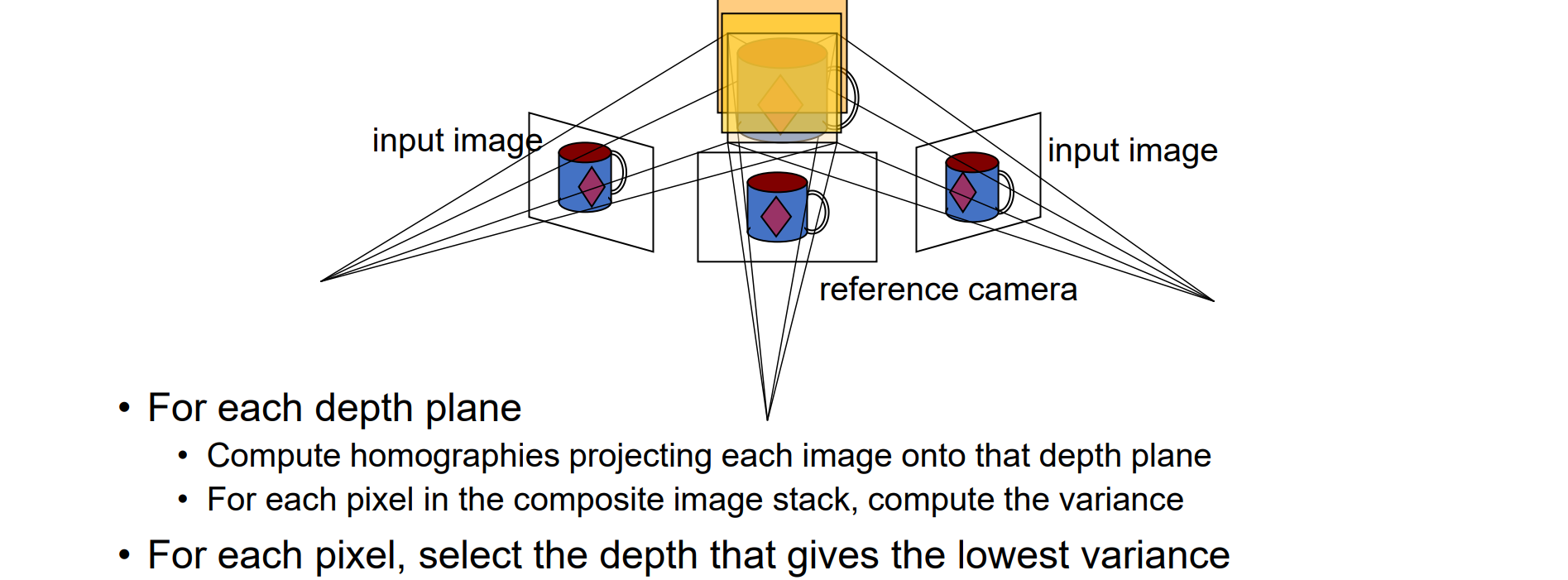
Plane-Sweep Stereo(基于体素)
- 核心思想:
- 首先设位于中间的相机为reference相机,设若干深度值,将图像映到不同深度的平面上
- 对于两侧的相机应用homography变换映射到不同的深度平面上
- 对于不同深度的每一个像素进行三图像的叠加,计算体素的颜色方差D
- D越小,一致性越好,选择这个深度作为所求
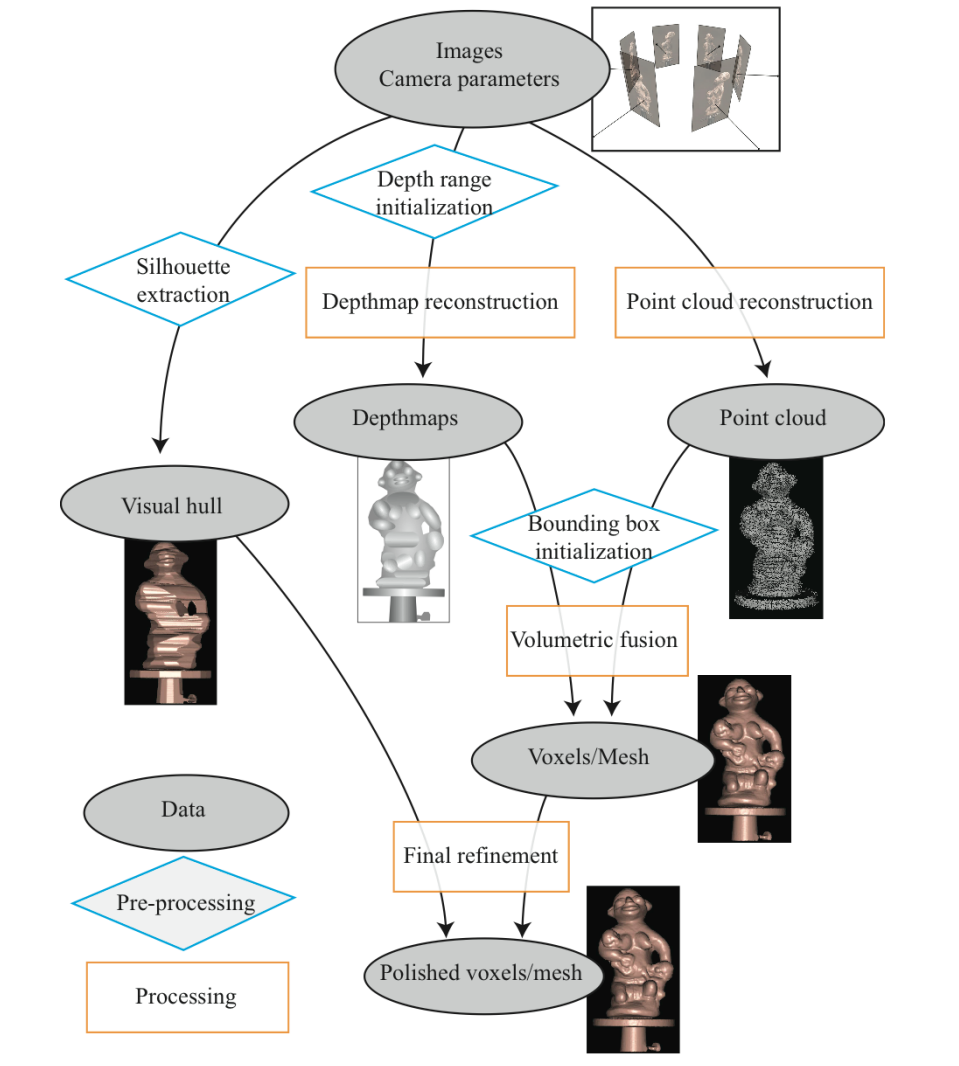
Depth Map based MVS
- 流程:(相机可以未经校准)
- 使用相邻视图计算深度图
- 将深度图合并到一个volume中。两两计算深度,投影形成点云,找重叠大的
- 从volume中提取 3D 曲面,提取连续曲面

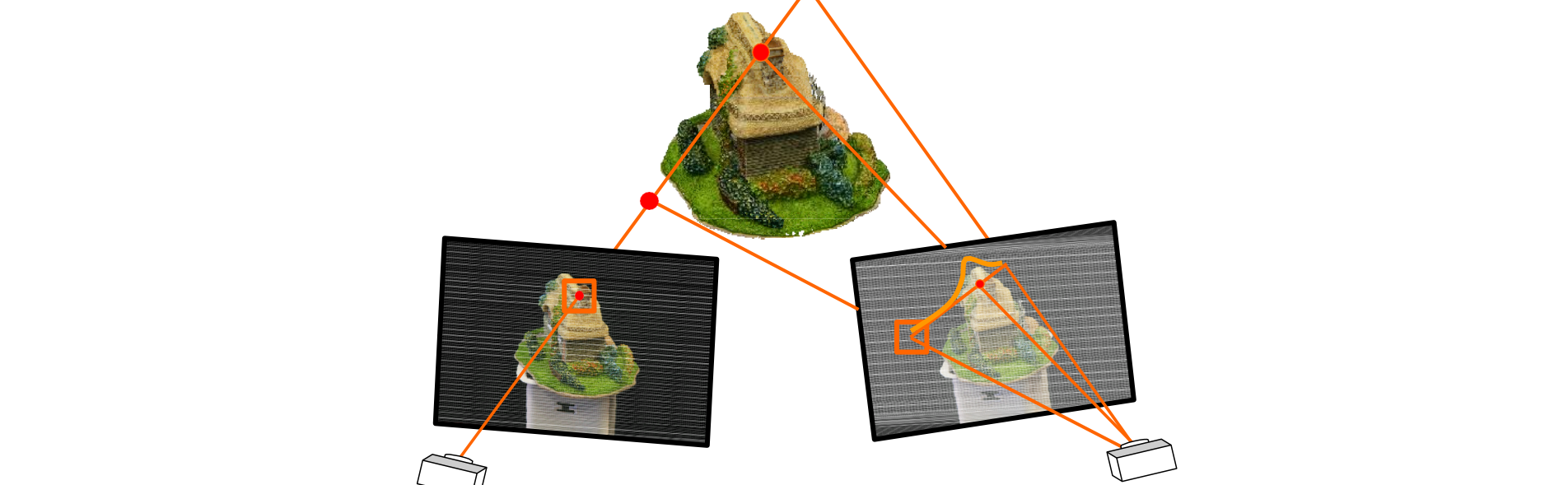
Compute Depth Maps(如何挑选邻域计算深度)
相邻视图之间的遮挡效果很小。因此选定参考图片时,选相邻图片来计算深度
使用匹配分数查找每个像素的最佳匹配,而无需进行强局部正则化;或直接使用双视图立体方法
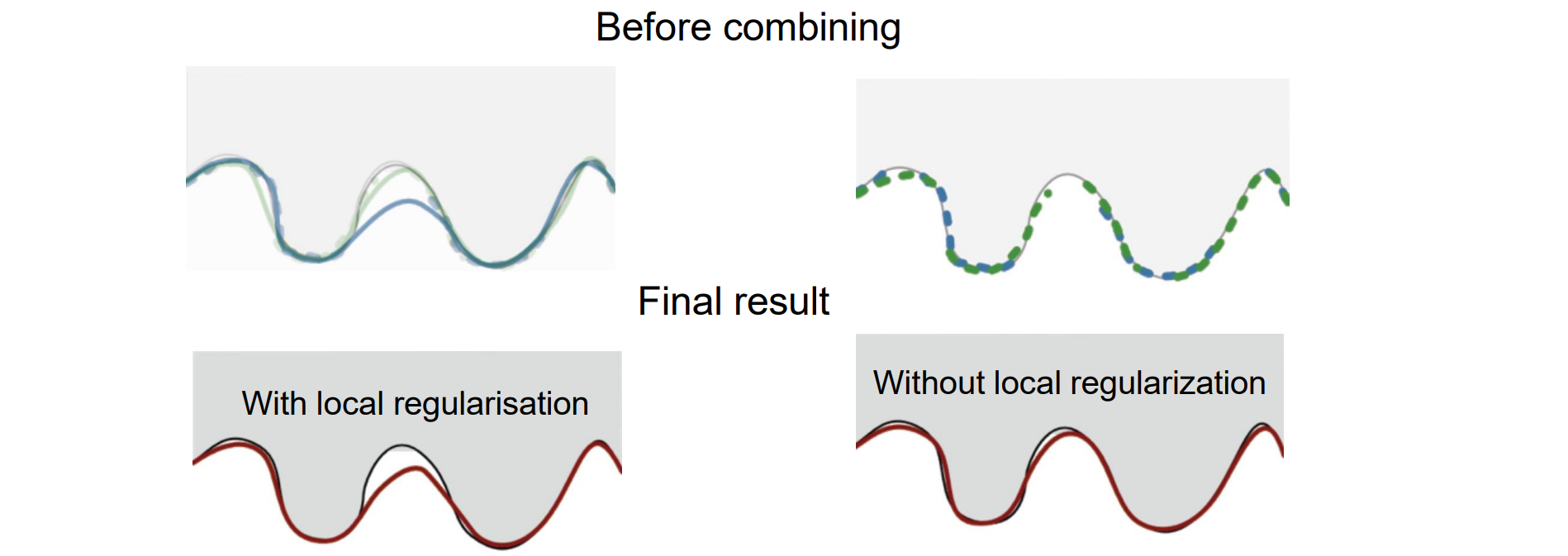
Effect of Early Local Regularization
不要过早的进行局部约束,对缺失部分进行平滑约束后于真实值相差过多,加权平均后偏离实际值很多
应该先完成拼接后进行优化
Patch-based MVS
稠密的重建需要稠密的一致性
核心思想:基于patch的重建 + 迭代扩展和过滤
一个块一个块的找一致性,重建图像块,迭代,对初始重建拓展,最后将不合理的过滤
流程:
- Feature detection:Harris corner; DoG
- Feature matching
- Patch expansion and filtering

What is a Patch
A patch consists of:
- Position (x, y, z)(中心位置)
- Normal (nx, ny, nz)(法向方向)
- Visible images V(p)(可见度0,1)
- Extent (radius)(半径,覆盖范围)
Patch:切线平面近似
设置范围,使 p 在 V(p) 中大约为 9x9 像素

Why Patches
容易转化为其他的3D表达,容易添加约束
可以灵活的表达物体和场景
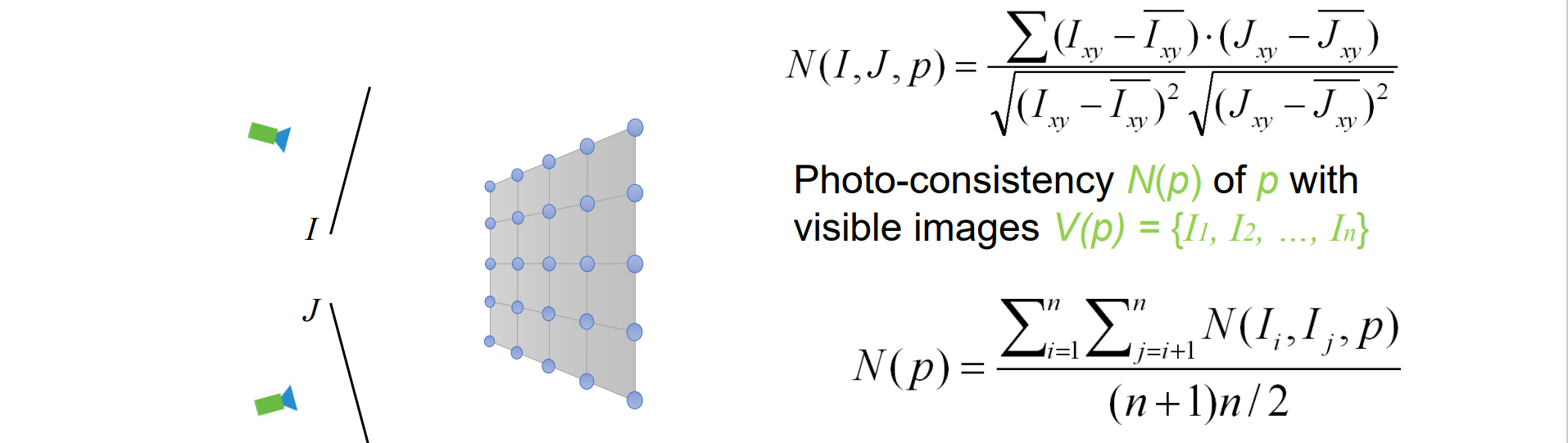
Photo Consistency
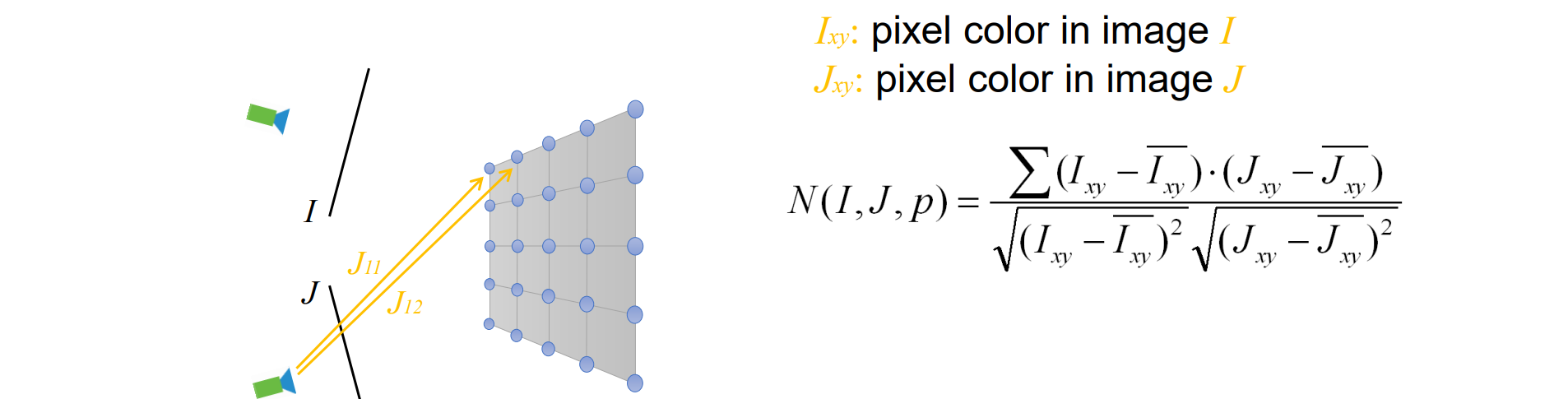
优化patch需要误差函数,而误差函数基于一致性N(I,J,p),其中I,J是图片,p是patch
Photo-consistency N(I, J, p) of p between two images I and J:首先将照片I渲染到图像中,颜色为Ixy。然后将图片J渲染到图像中,颜色为Jxy
- 多个图像Muti-View的N函数叠加得到优化函数N(p),N(p)与c(p)和n(p)相关
Reconstruct Patch p
给定初始估计:Position c(p)、Normal n(p)、Visible images V(p)
通过如下公式优化c(p),n(p):
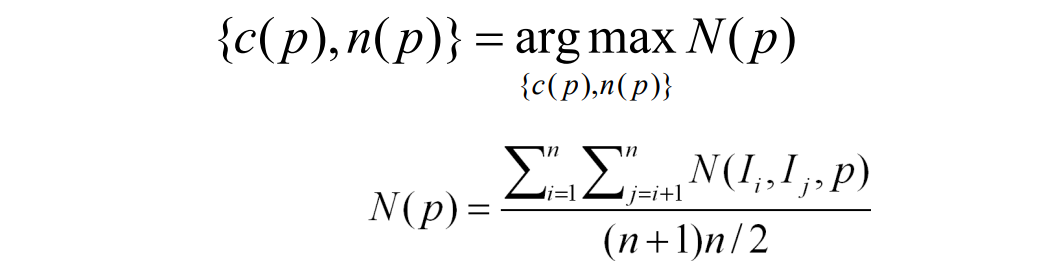
优化position c(p):约束patch在法向量上前后移动,在法向量线上计算argmaxN
优化normal n(p):约束patch在固定position上左右旋转,找到argmaxN(p)
优化V(p):如果投影后覆盖不足,就置为0。启发式更新V(p)
- 图像间两两计算N
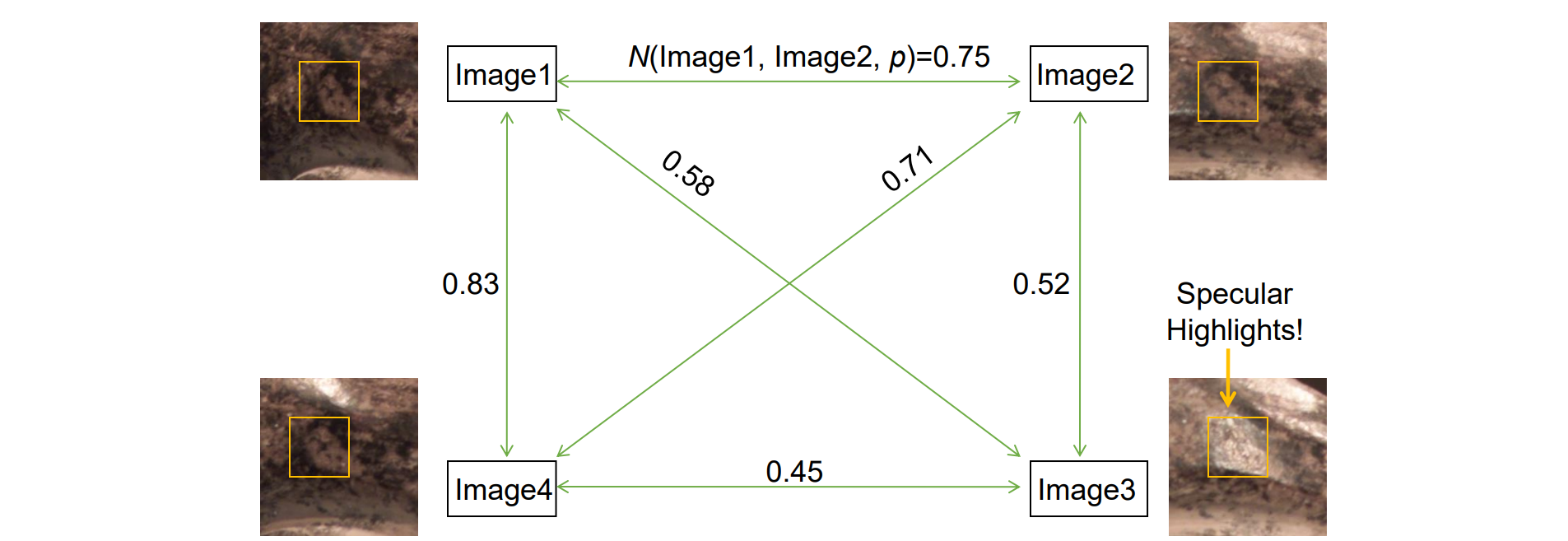
- 依次假设某图像为ref,计算与该图像相关的Nsum,得到一致性
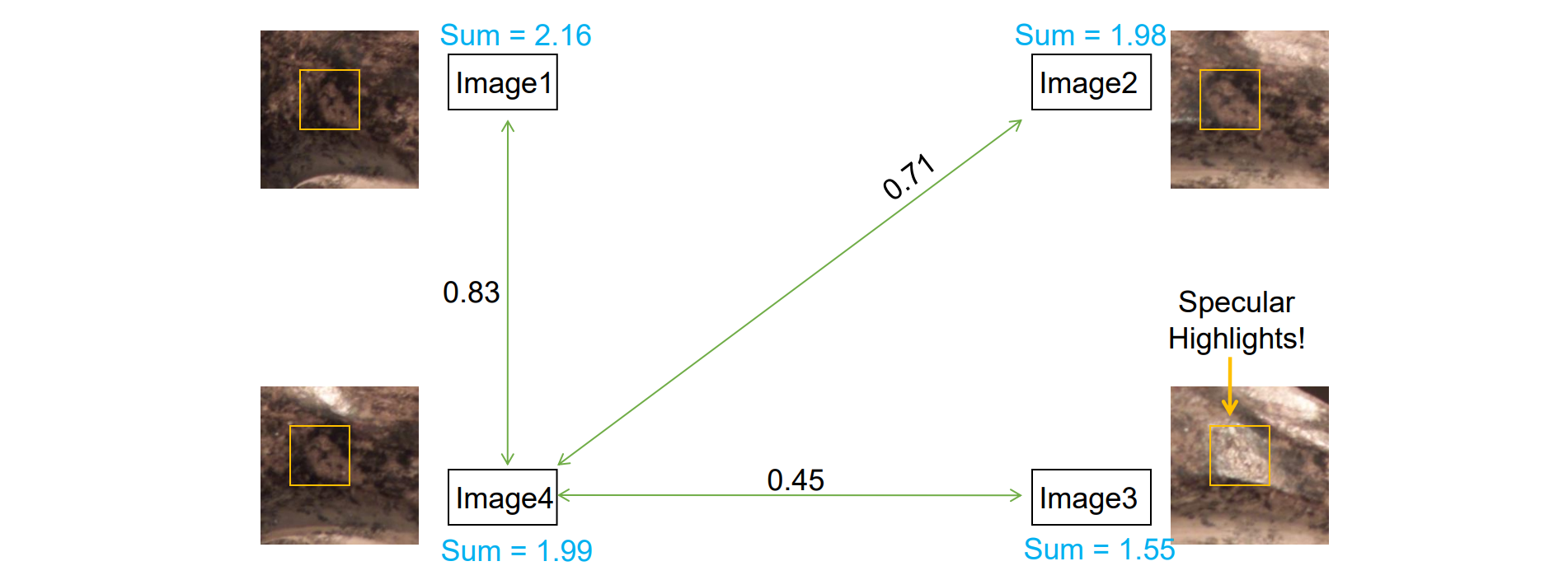
- 将patch绑定到Nsum最大的image中,记为ref_image
- 考察其他图片与ref_image的N,如果大于设定的阈值则V(p)=1,否则置为0
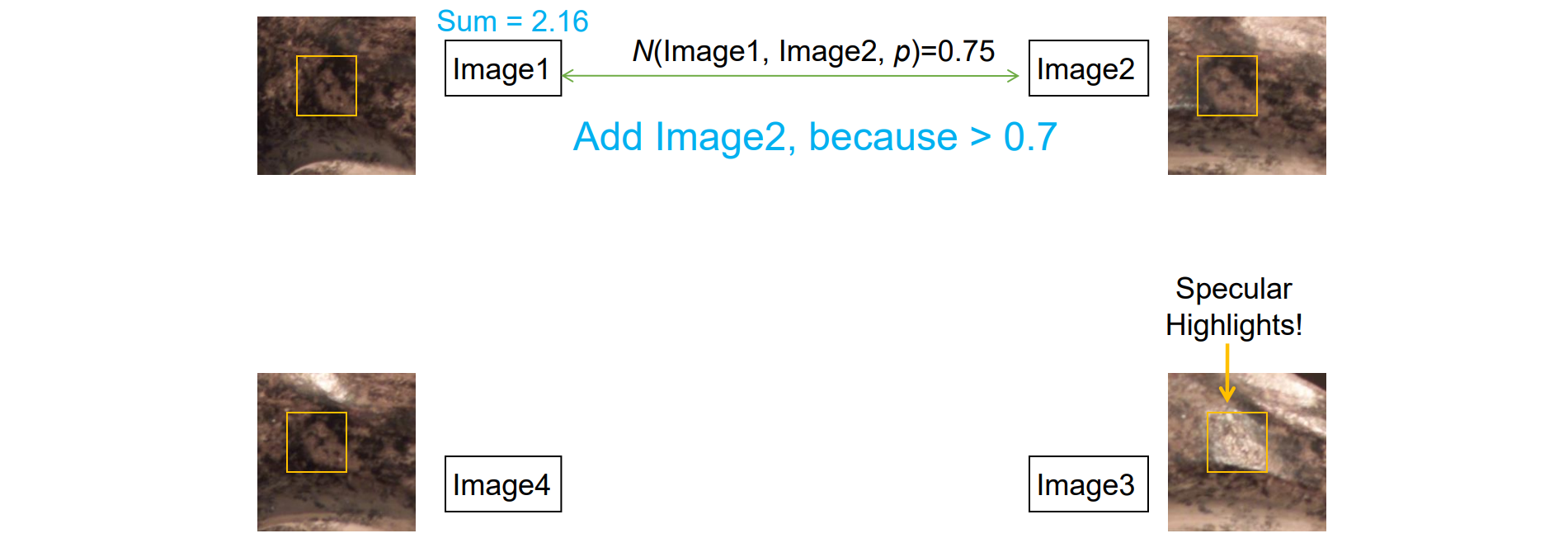

- 图像间两两计算N
Verify a Patch
为什么要再次验证:
- 纹理可能会意外匹配
- 光一致性必须相当高才具有置信度
验证的流程:
- 在V(p)中必须保持很高的一致性,N足够大
- V(p) ≥ 3,至少有三张照片可见
满足上述条件的patch保留,否则删去
Feature Detection
- 在局部用Harris corner detector进行角点检测,使用DoG检测blobs
Feature matching
Initial Feature Matching
- 先用triangulation得到c(p),然后用极点几何进行热证匹配,对应点一定在极线上,因此可以沿着极线找到最佳匹配。同时将image1,2加入到v(p)中
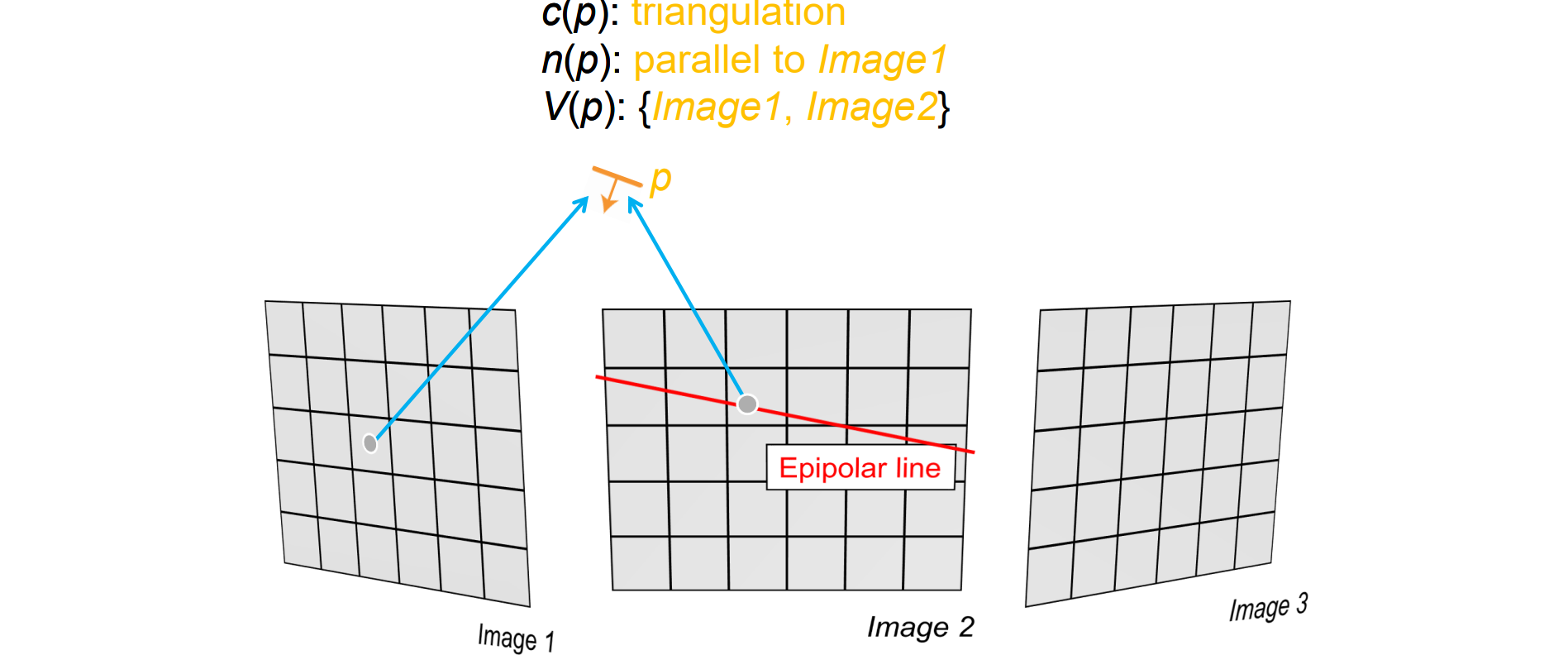
- 渲染后看image3是否可见,设置阈值和N进行比较
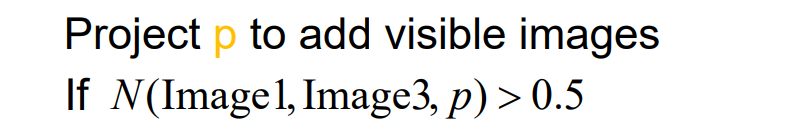
- 然后进行优化:
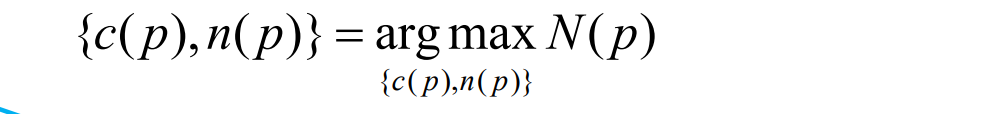
- 然后检验是否保留,验证并更新v(p)

- 最后将保留的patch标记,代表已经重建。重复上述过程
Patch Expansion
首先先得到初始的patch,然后对每个patch进行循环:
如果一个patch没有被重建,但是邻居都已经被重建,这时候什么都不做
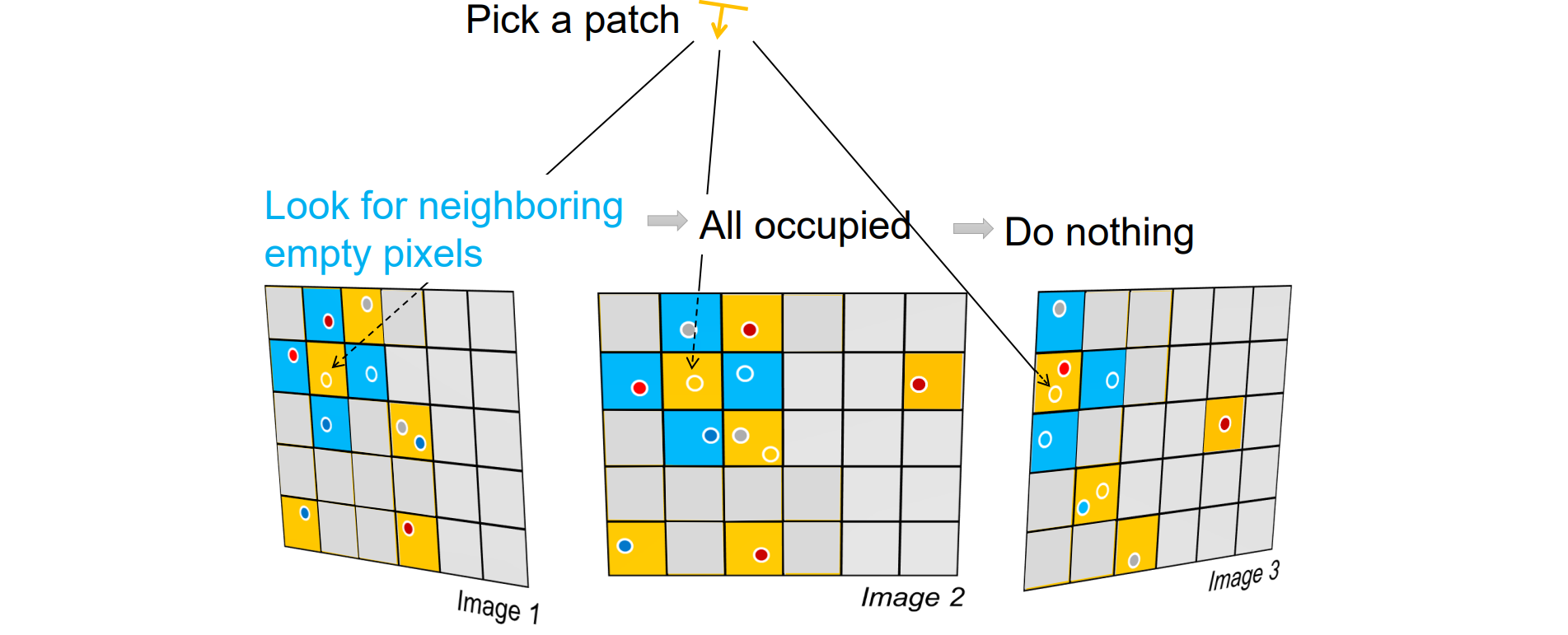
- 如果找到patch,其邻居没有被重建,那么就用这个patch初始化邻居进行expansion
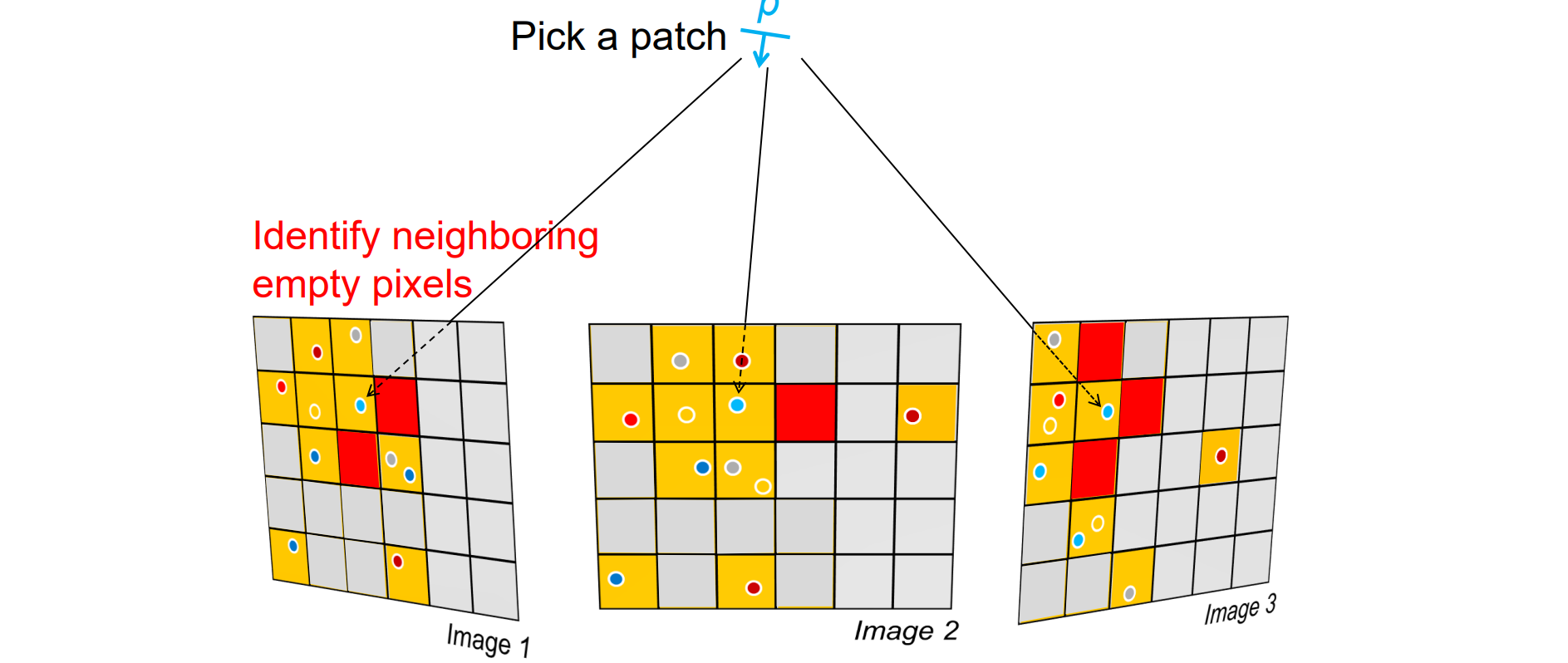
- 先用p重建q,然后再对q和邻居的patch进行调整,最后进行验证
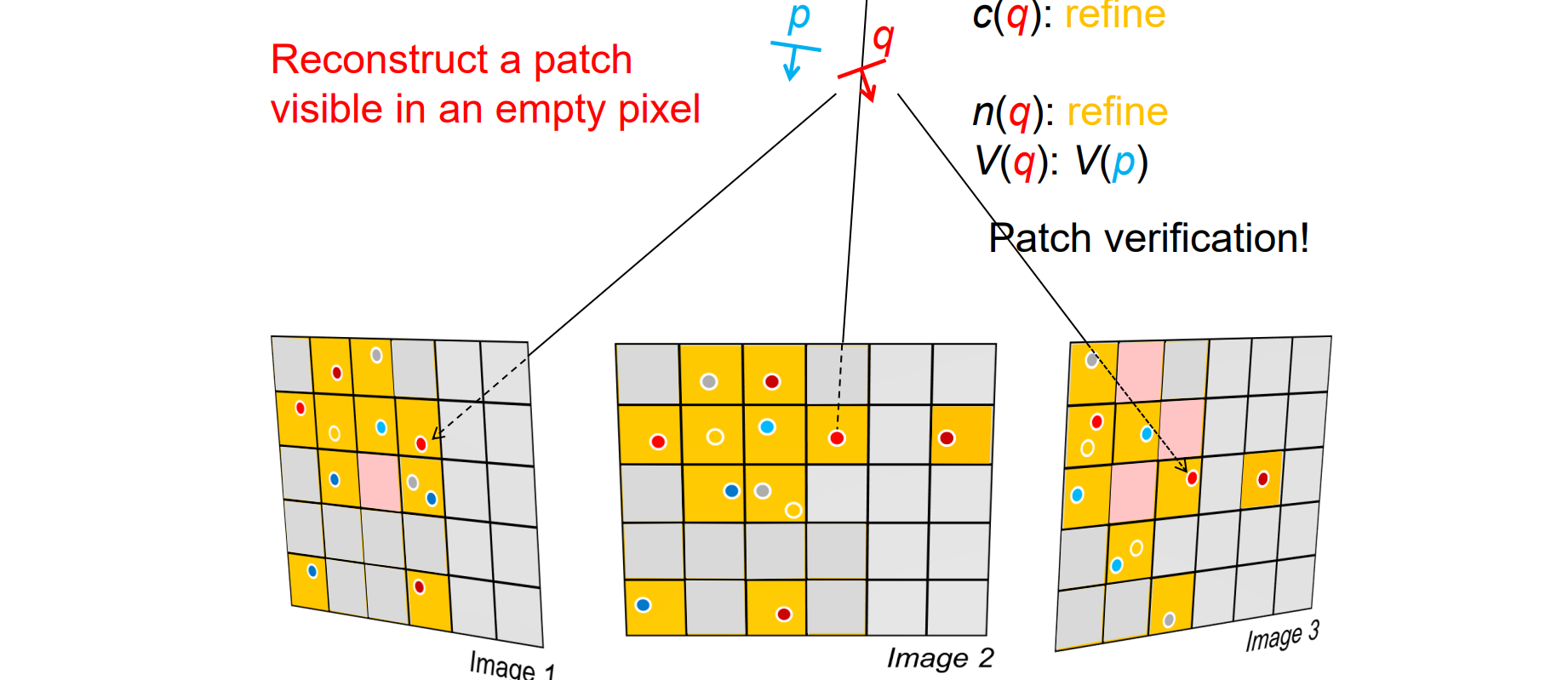
- 迭代流程:
- 先通过特征检测和匹配选出置信度高的patch
- 然后用这些置信度高的patch更新扩展邻居空patch
Patch Filtering
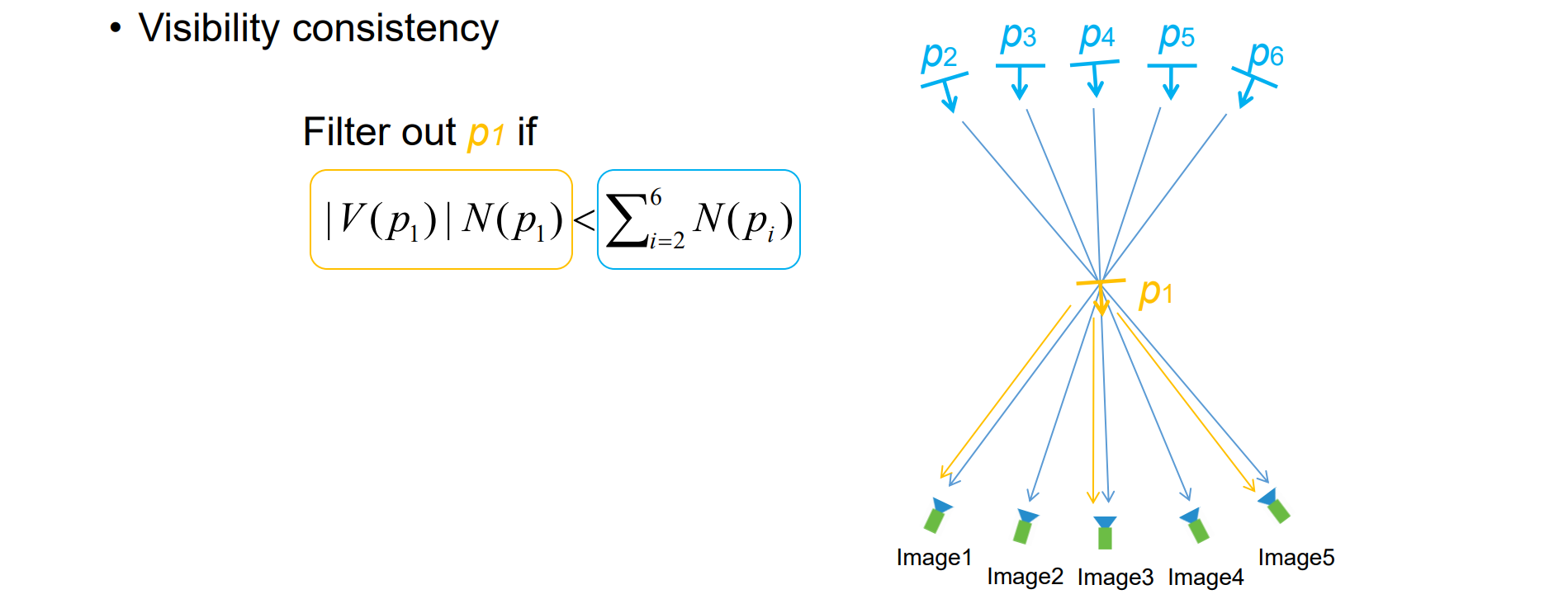
summary of Patch-based MVS
优点:
- 灵活,用patch
- 容易抽取出3D网格
- 可以当成黑盒
- 对物体和场景都是高效的
缺点:
- 严重依赖一致性N函数
- 容易受到光照,阴影的影响
- 运行时间长
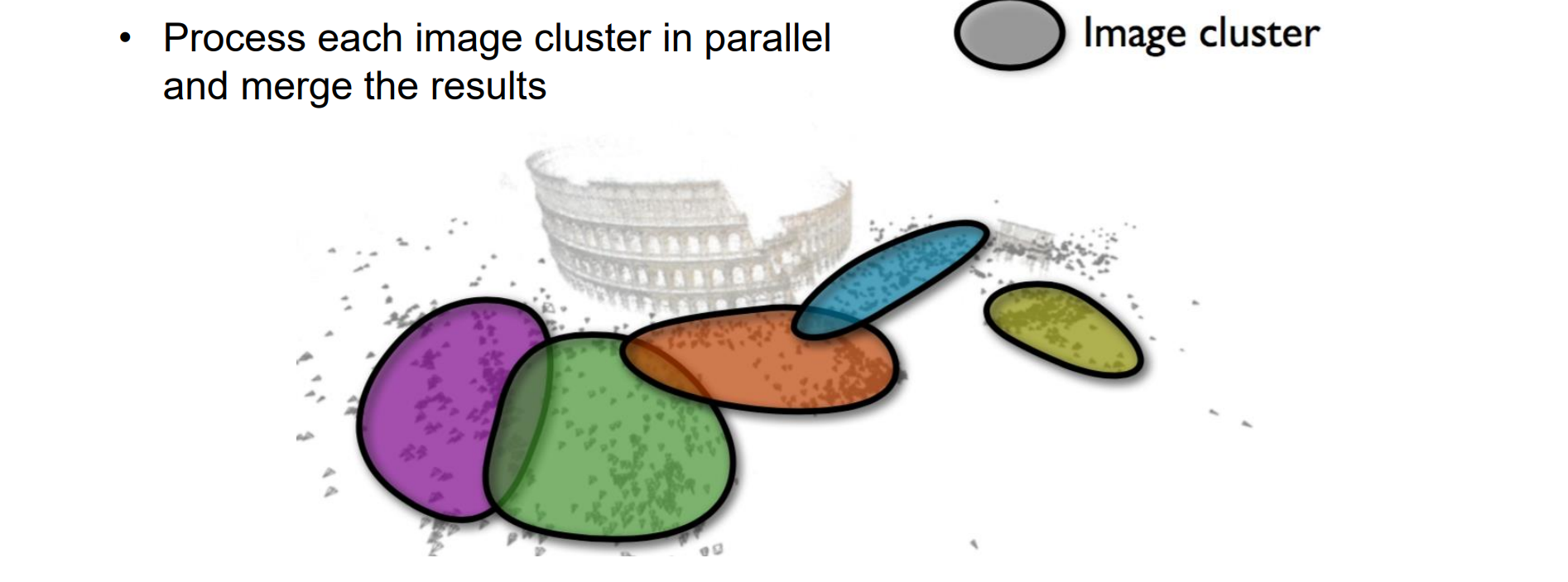
Towards Internet-Scale Multi-View Stereo
- 采用分而治之的思想,运用聚类先将摄像机分成小块,在小块中使用MVS
COLMAP MVS
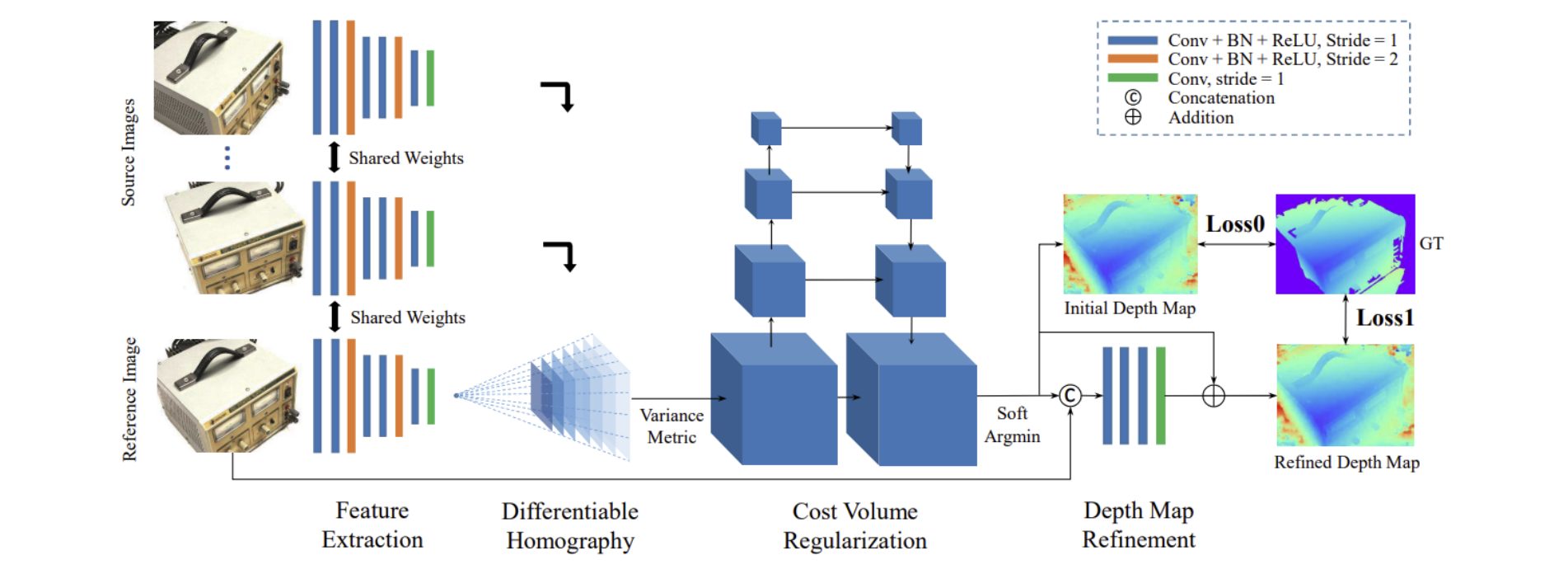
Deep Learning for MVS
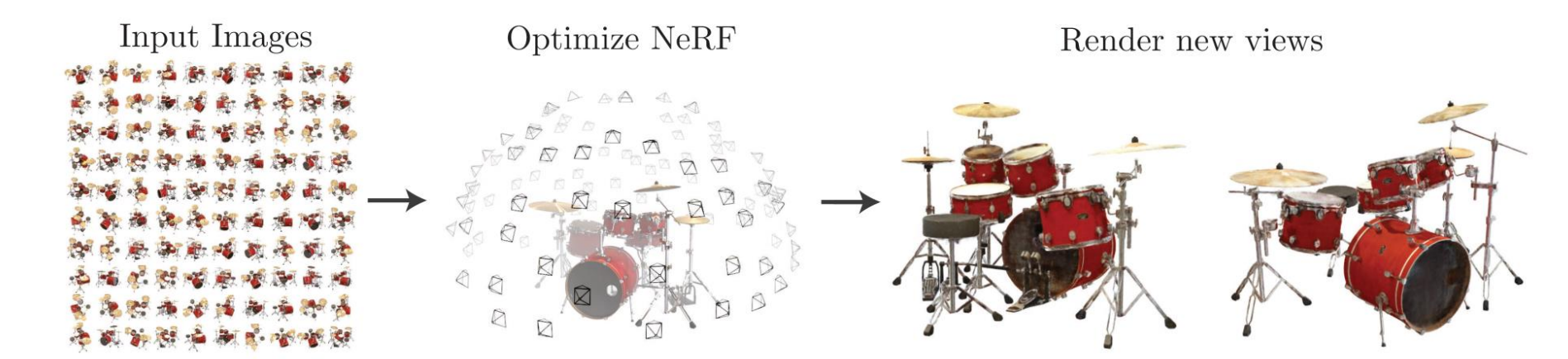
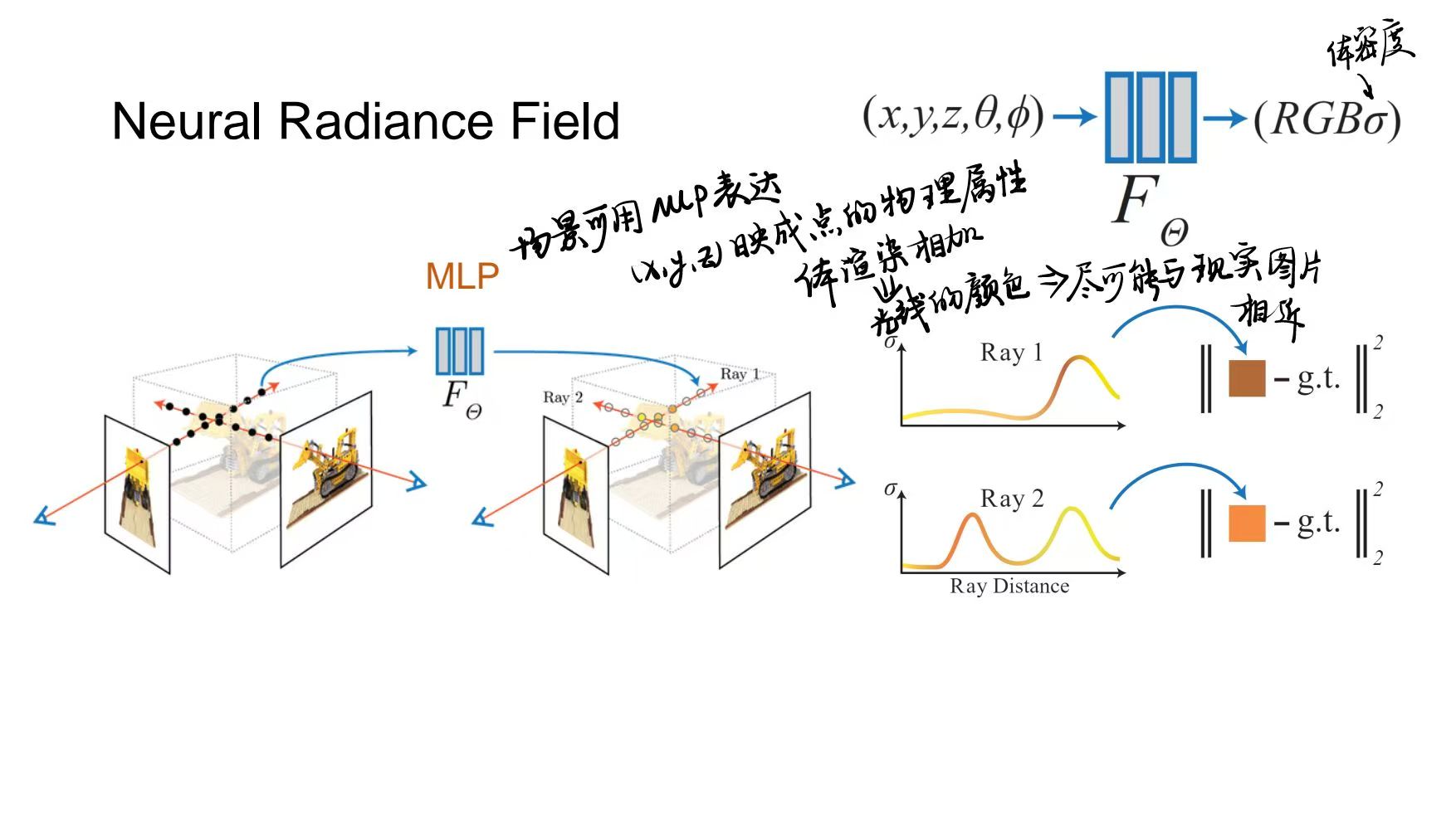
Neural Radiance Field
- 输入输出和MVS基本相同。输入不同视角下的多张图片,先用SFM估计相机参数变为已知,然后优化表达3D
Volume Rendering(体渲染)
只吸收的体渲染
只发光的体渲染
Volume Rendering: Absorption Only


Gaussian Splatting