
计算机视觉 19 Visualizing Models and Generating Images
Visualize Neural Networks
Directly visualize the neural network weights
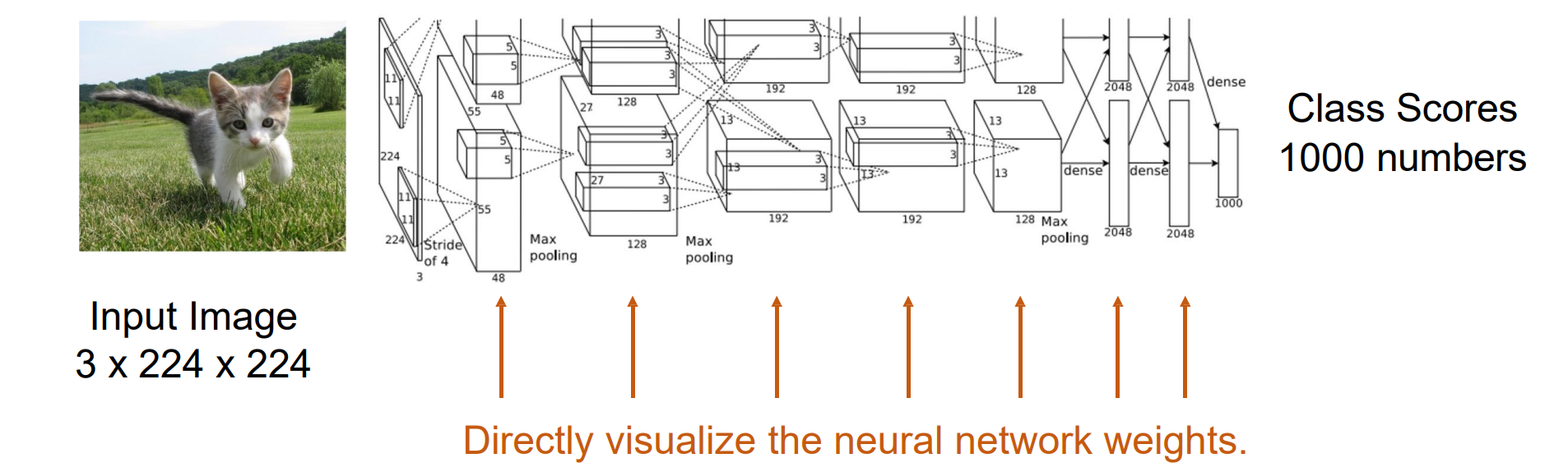
将weight折叠成图像的形状,然后将像素值映射到0-255
浅层layer主要学习不同方向的边缘提取,blogs提取特征。更关注形状和颜色特征而非语义

- 高层layer无法通过这个方法进行可视化,可视化结果维度很高而且效果较差

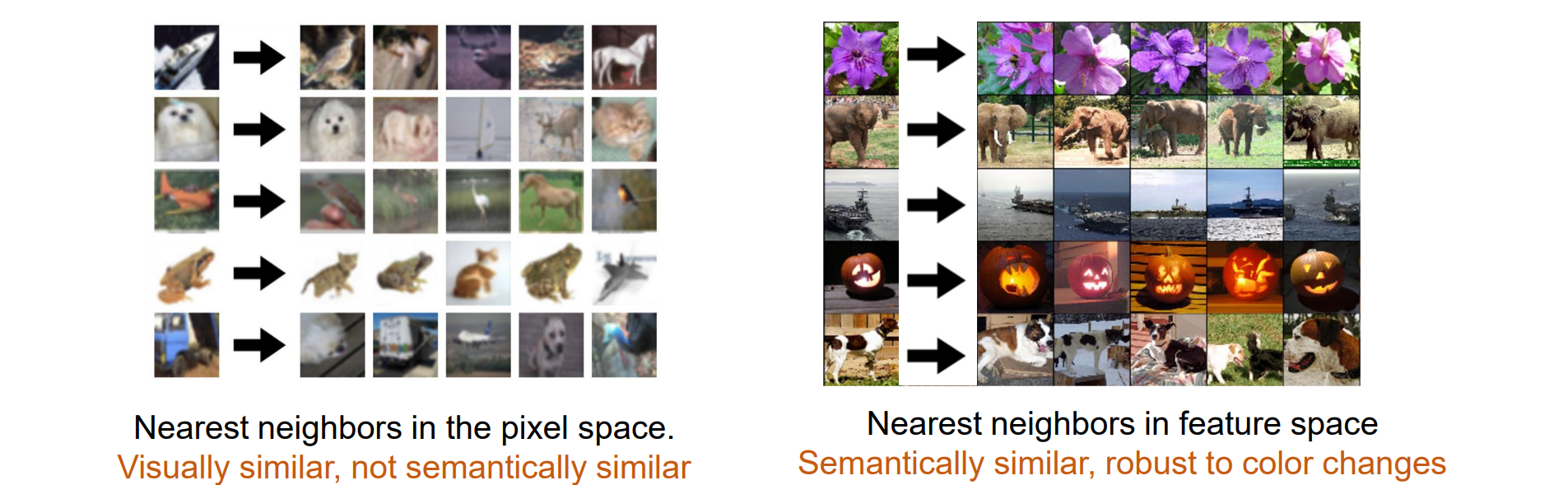
最后一层layer可以通过最近邻进行可视化:从分类器之前的图层中提取图像的 4096 维特征向量,然后找到最近的邻居
最后一层提取出的特征对颜色鲁棒,而对语义比较敏感
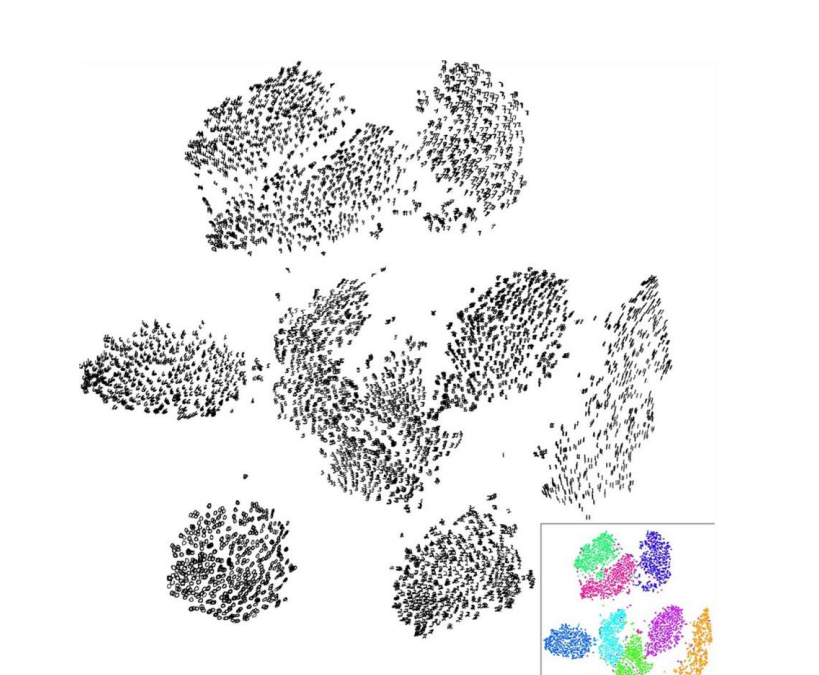
- 最后一层layer可以进行将为可视化:通过PCA或t-SNE将向量的维数从 4096 维降低到 2 维,可视化 FC7 特征向量的“空间”
Understand Input Pixels
Maximally Activating Patches
实现思路:
- 选择想要可视化的图层和通道
- 通过神经网络运行许多图像,记录所选通道的值,即激活值feature
- 计算并裁剪相对应的感受野,可视化与最大激活度相对应的图像块
优点:可以可视化中间层
缺点:每个图片都需运行,计算量大

- 可以看到浅层网络关注一些特征和概念,而深层网络更加关注高层次的语义
Which Pixels Matter: Saliency via Occlusion
实现思路:遮罩图像的一部分,检查预测概率变化的程度
裁剪一个图像块用灰色噪音进行遮盖,可以得到哪一部分对理解语义帮助最大
优点:无需每个照片都处理,可以只对一个照片进行处理
patch大小是参数,需要调整

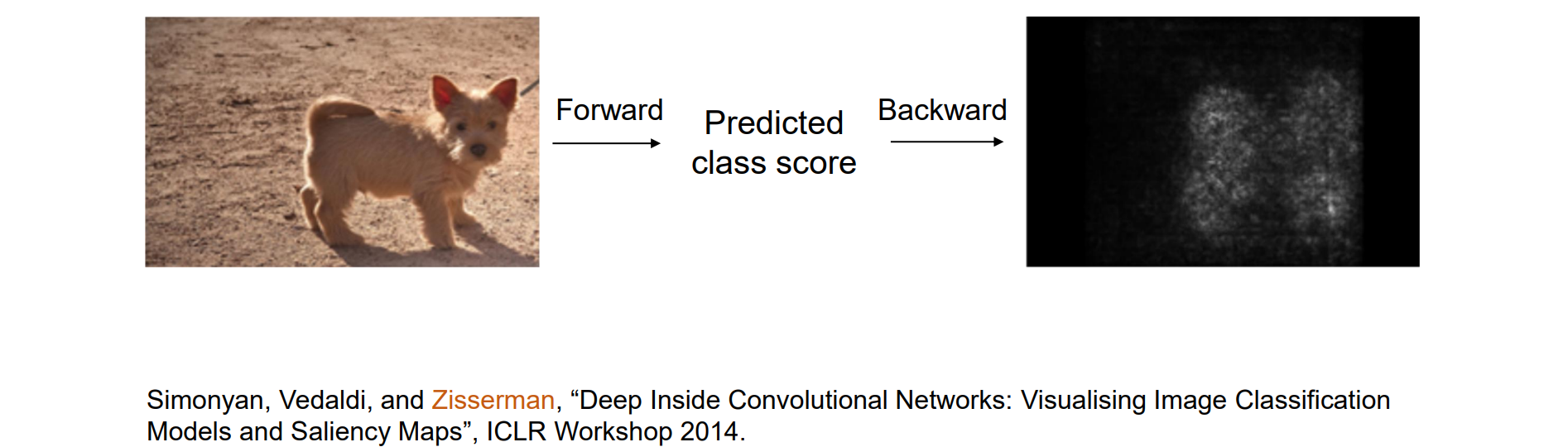
Which Pixels Matter: Saliency via Back Propagation
“影响最大” -> 梯度
实现思路:计算每类得分(未归一化,在softmax之前实现)相对于图像像素的梯度;获取绝对值并在所有通道上最大化
Saliency Maps: Segmentation without Supervision
- 如果已经获得语义对应,则可以设置阈值区分前景后景进行抠图

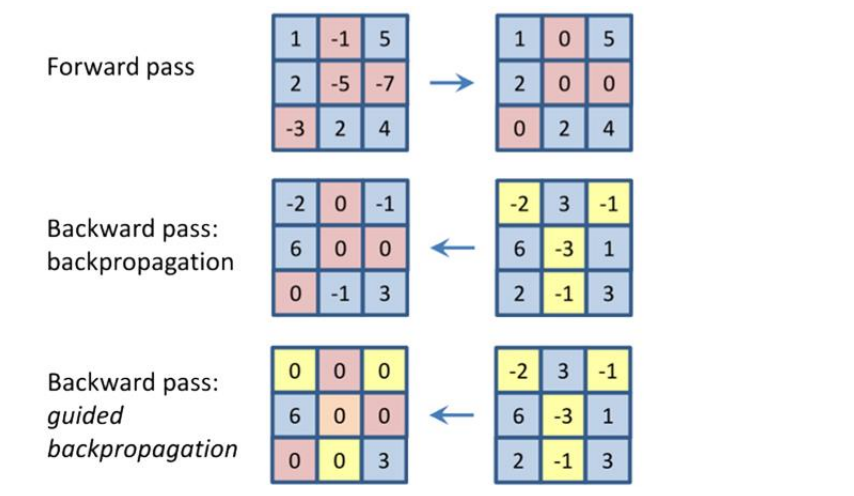
Saliency via Guided Back Propagation
问题:并非所有图像经过Saliency via Back Propagation处理完都是合理的
实现思路:
- 给定图像,前向运算神经网络
- 在网络中选择一个中间神经元,不限于最终的预测分数
- 在网络中选择一个中间神经元,不限于最终的预测分数
- 如果仅通过每个 ReLU 反向传播正梯度,结果看起来会更好(guided)
前向运算后删除负值并置为0,反向传播时负梯度不再进行反传

Class Activation Mapping (CAM) with Global Avg. Pooling
- 原理:观察到先进行全局平均池化在连接全连接层,和先进行全连接层再进行全局平均池化时效果相同的,GAP和fc的顺序可以交换,证明如下:
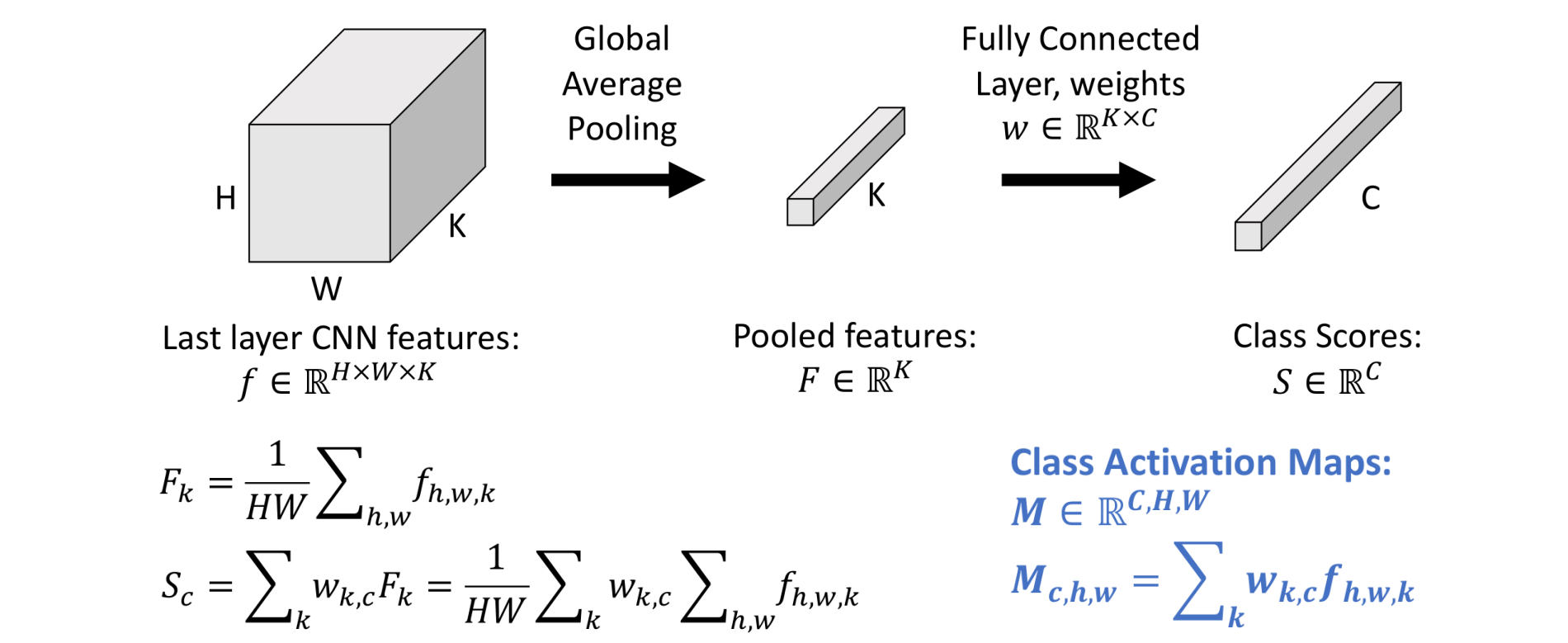
- 因此可以在feature map上做分类,然后再进行全局平均池化。分类:每个通道做点乘,相当于在区域上进行检测,效果如下图:
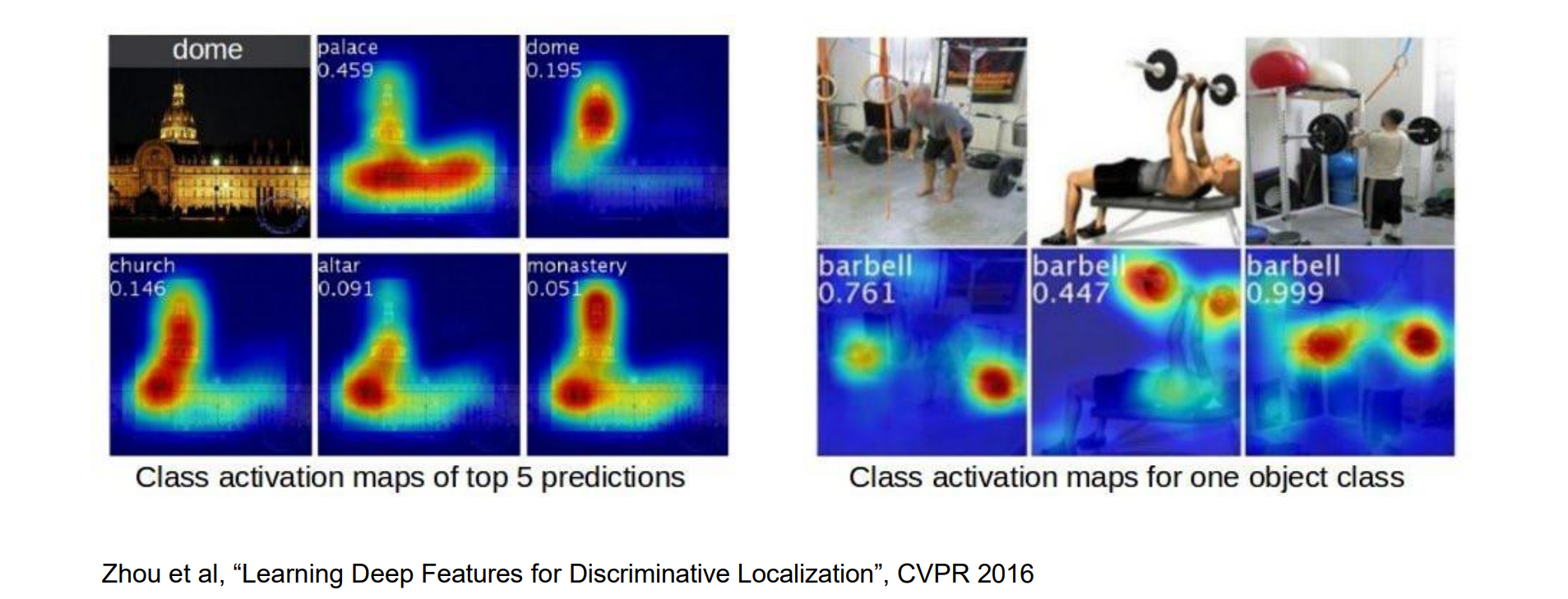
- 问题:只适用于最后一层layer应用全局平均池化的方法
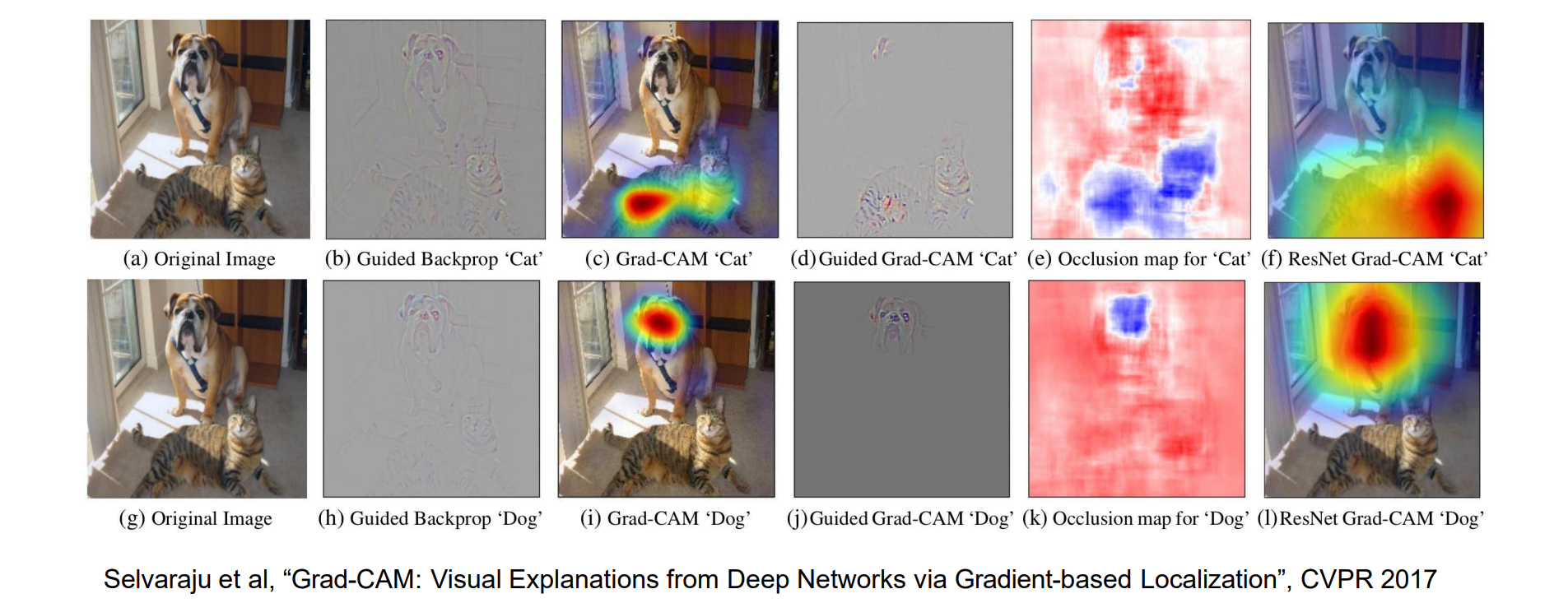
Gradient-Weighted Class Activation Mapping
实现思路:近似输出和要通过全局平均池化和 FC 可视化的图层之间的网络层,让其等效于进行了全局平均池化
Grad-CAM 通过将 CAM 与guided backpropagation相结合来扩展:
- 选择激活为 A 的任意层
- 计算类分数 S 相对于 A 的梯度
- Global Average Pool the gradients (全局平均池化) 以获得权重
- 计算激活映射M

Visualization with Optimization
Visualizing CNN Features by Optimization
- 通过在 softmax 之前最大化类分数 Sc 来查找图像:给定噪音通过优化使得Sc(I)最大,使得像素尽可能小的前提下激活大
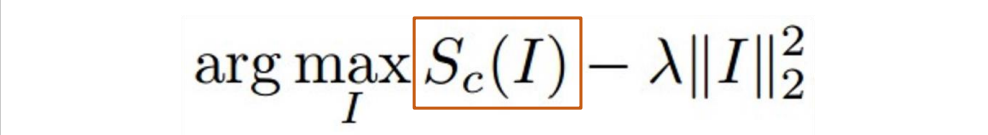
将图像初始化为零:CNN 在以零为中心的图像上进行训练
通过反向传播和梯度上升(下降)优化损失来更新图像
将训练集均值图像添加回结果

- Better regularization terms:
- L2 norm:防止一些极端像素值主导结果
- Gaussian blur:惩罚结果中的高频细节
- 将小值的像素置为 0:如果区域不明显,则保持为零
- 将具有小梯度的像素置为 0

Adversarial Examples
对于图像 x,选择任意标签l,让其分类为另一个类别,产生的噪音进行攻击
通过最小化以下目标函数来调整图像:𝑙𝑜𝑠𝑠(𝑓(𝑥 + 𝑟),𝑙) + 𝑐 ⋅ |r|,其中f是神经网络
神经网络的安全问题:
- Adversarial Attack:为网络生成对抗示例
- Adversarial Defense:更改网络架构或训练设置,使其更难受到攻击
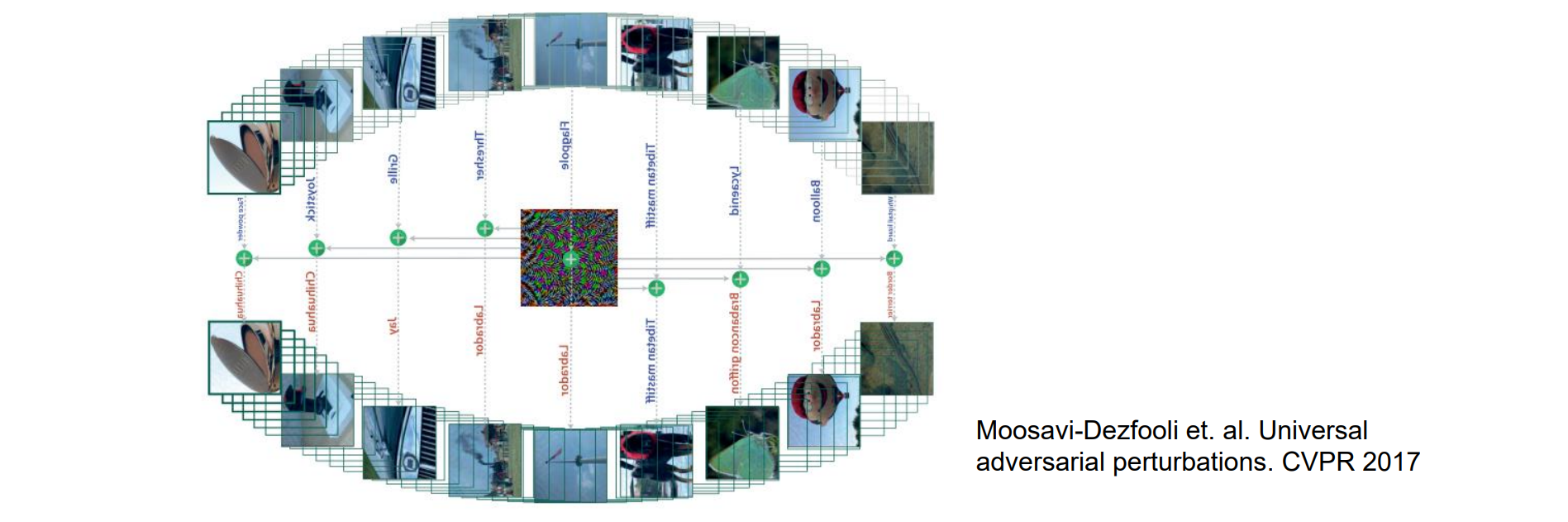
Universal Adversarial Perturbations
- 存在一个通用的(与图像无关的)且非常小的扰动向量,它会导致自然图像被错误分类的可能性很高
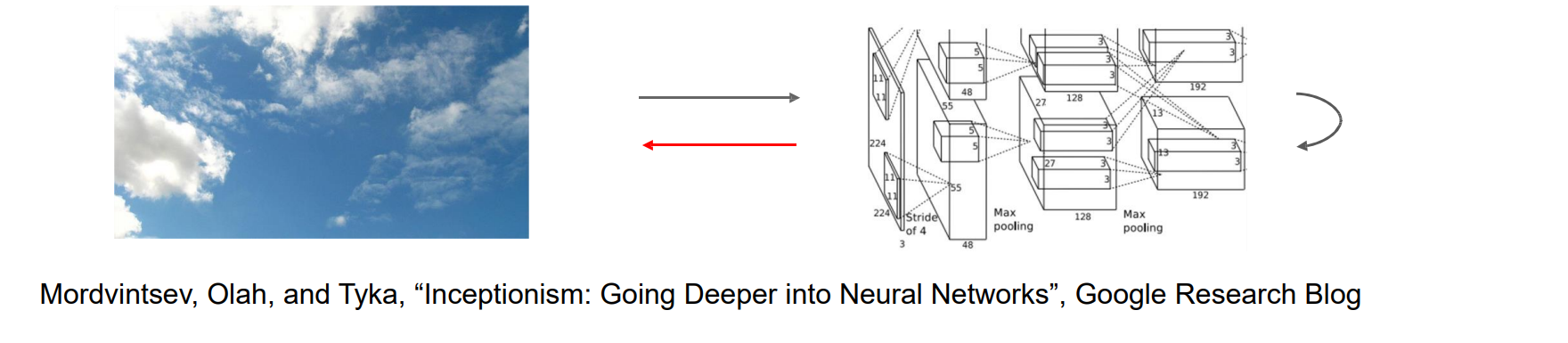
Feature Amplification: DeepDream
还可以通过以下方式放大网络中某个层的神经元激活,而不是合成图像以最大化特定神经元,例如在天空的图片中放大动物的激活
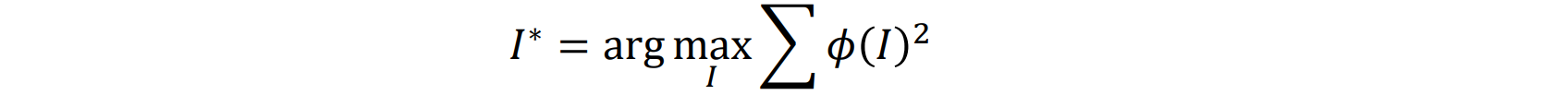
- 选择image和CNN φ中的一个layer,迭代更新图像

Feature Inversion
- 给定图像的 CNN 特征向量,查找与给定特征向量匹配的新图像。通过x优化的图像和给定的feature φ0相同
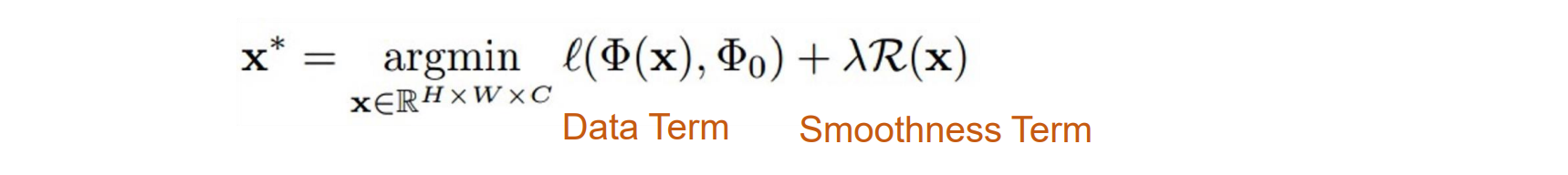
- 其中 φx 是新图像的特征,φ0 是给定的特征,可以通过反向传播计算 ∇φx
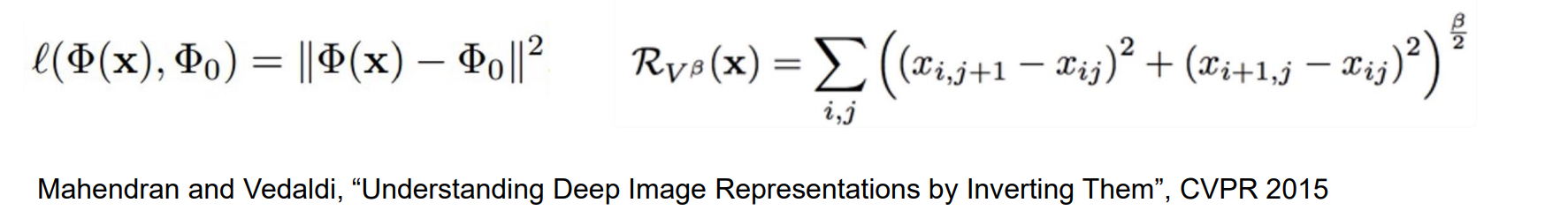
- 从 VGG-16 的不同层重建:当从更高的图层进行重建时,图像内容和整体空间结构被保留,但颜色、纹理和确切的形状却没有被保留

Texture Synthesis
- 纹理是随机而有规律的
Texture Synthesis: Nearest Neighbor

Texture Synthesis with Neural Networks
纹理可以通过神经网络特征的统计来描述
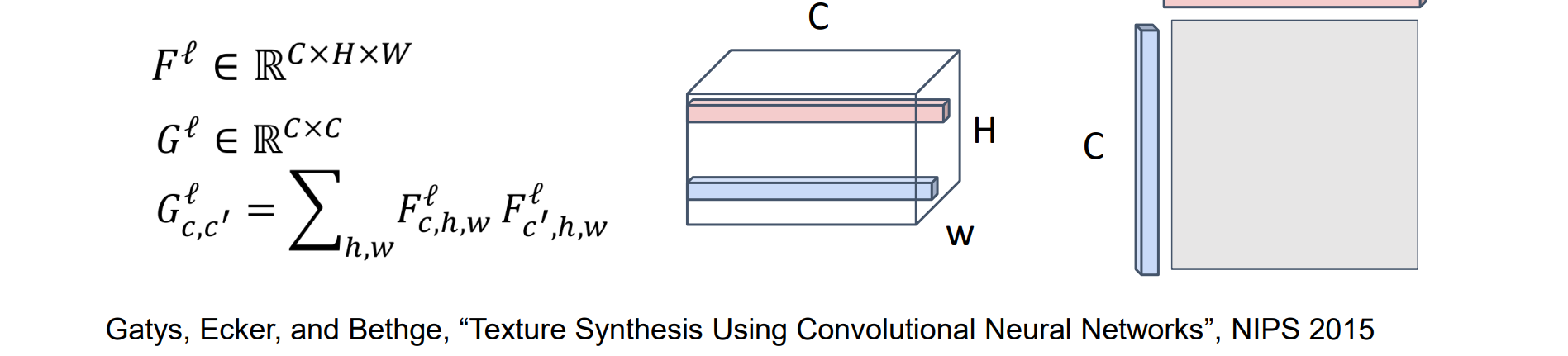
实现思路:
- CNN 的每一层都给出一个 C x H x W 张量 Fl
- 两个 C 维向量的外积得到元素乘积的 C x C 矩阵
- 所有HW对的平均值会得到一个 Gram Matrix,它可用于描述纹理
Gram矩阵的本质是所有位置的任意像素点乘,描述相似程度
Neural Texture Synthesis
- 实现思路:
- 使用预先训练的 VGG 并计算纹理的每一层 Gl 的 Gram Matrix
- 从随机噪声初始化生成的图像
- 通过梯度下降优化下面的损失函数:
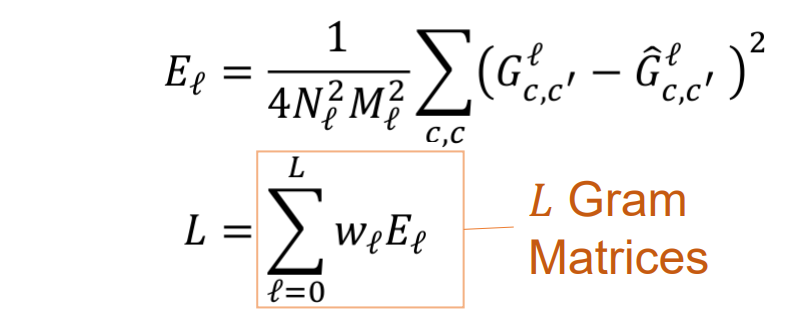
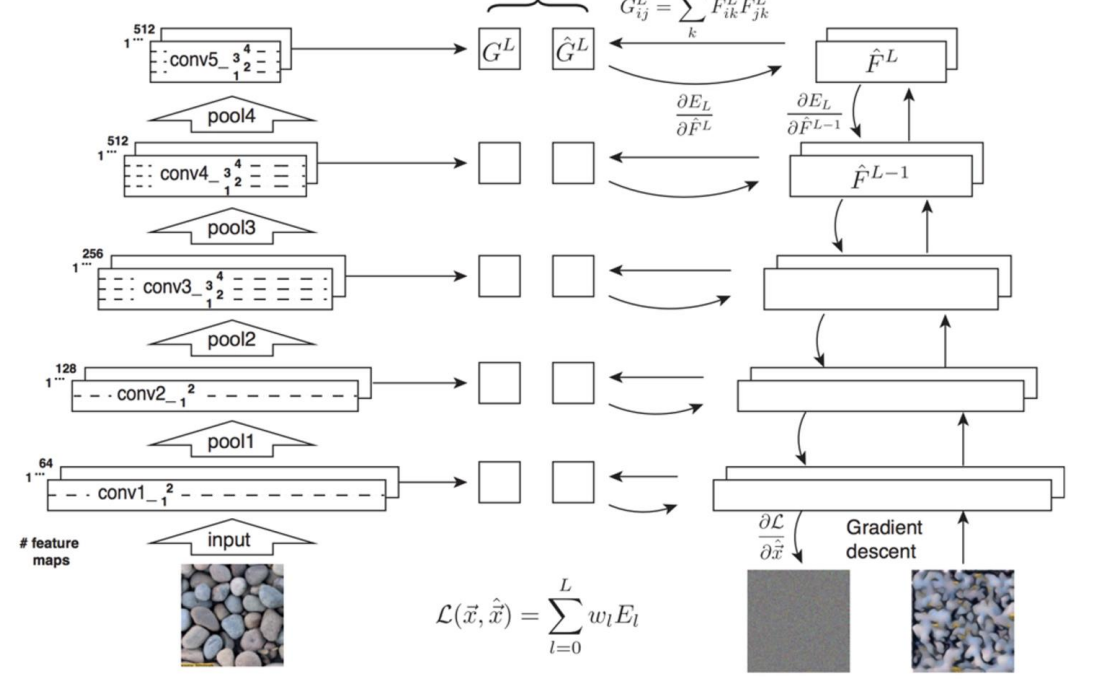
- 从较高层重建纹理可从输入纹理中恢复更大规模的结构

Neural Style Transfer
Neural Style Transfer: Feature + Gram Reconstruction


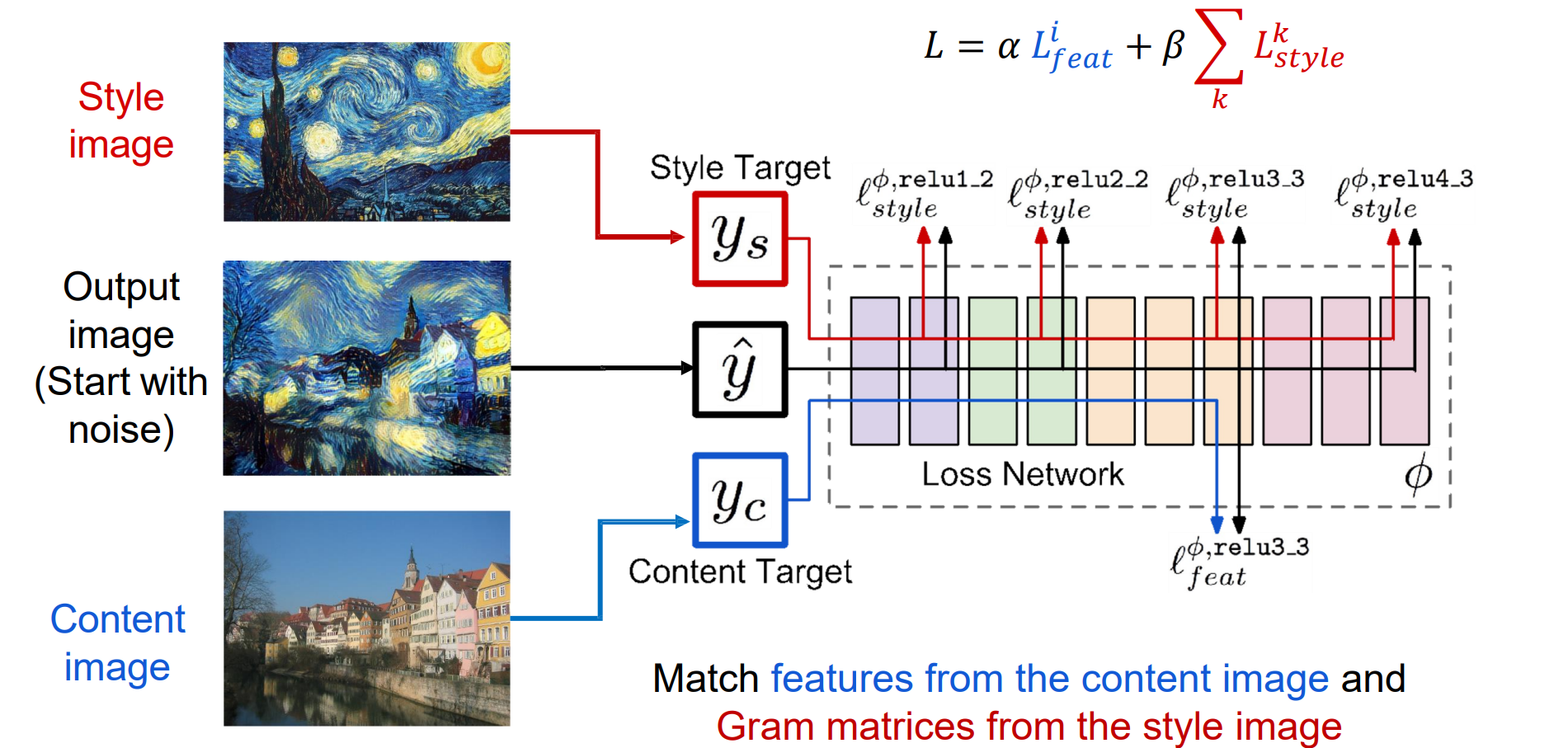
- style image计算gram matrix来提取texture,cotent image利用高层feature保留语义,丢掉特征

- 需要先对图像进行缩放,在运行style transfer algorithm之前调整样式图像的大小可以传输不同类型的特征

- 通过对 Gram 矩阵进行加权平均,从多个图像中混合样式
Fast Neural Style Transfer
问题:样式传输需要通过 VGG 进行多次前向/向后传递
解决方案:训练另一个神经网络执行风格迁移
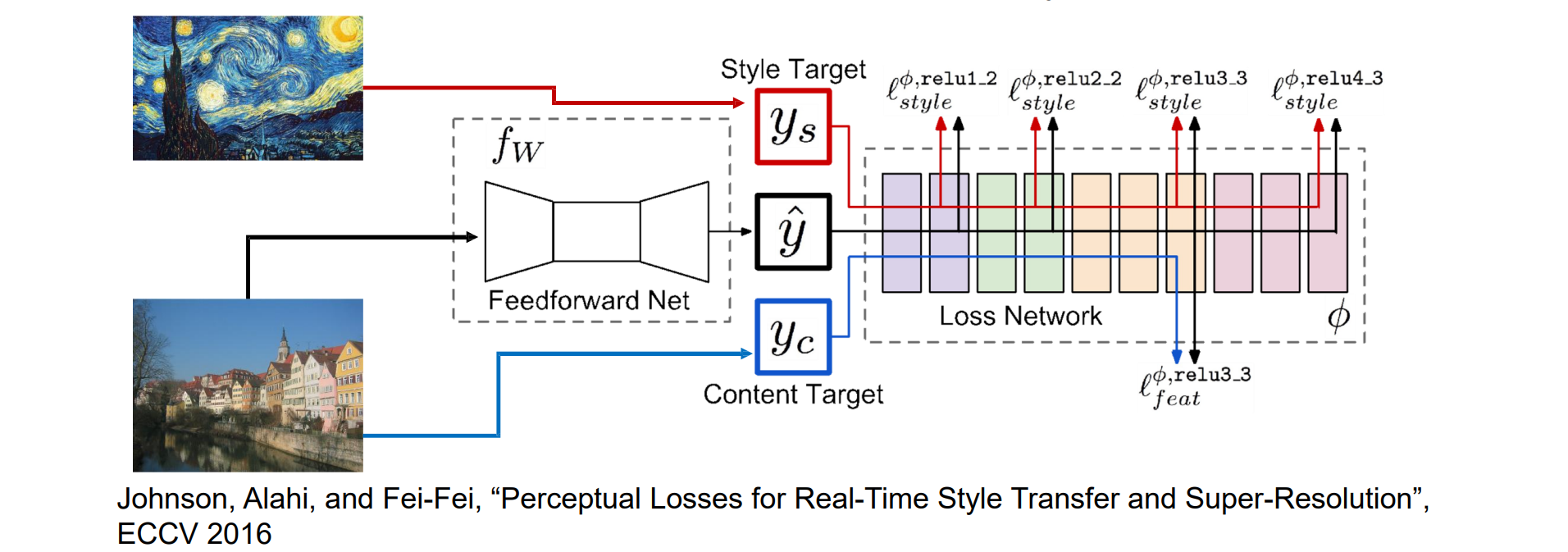
Fast Neural Style Transfer: Instance Normalization
Observation:
- 仅用 16 张示例图像训练的网络比用数千张示例图像训练的网络产生的结果要好
- 二阶统计量 (Gram Matrix) 和一阶统计量 (通道均值和方差) 的匹配对于风格迁移都有效
不能跨图像考虑统计量,因此不能使用BN将多个图片的统计量俊杰,在生成器中我们应该使用e Instance Normalization
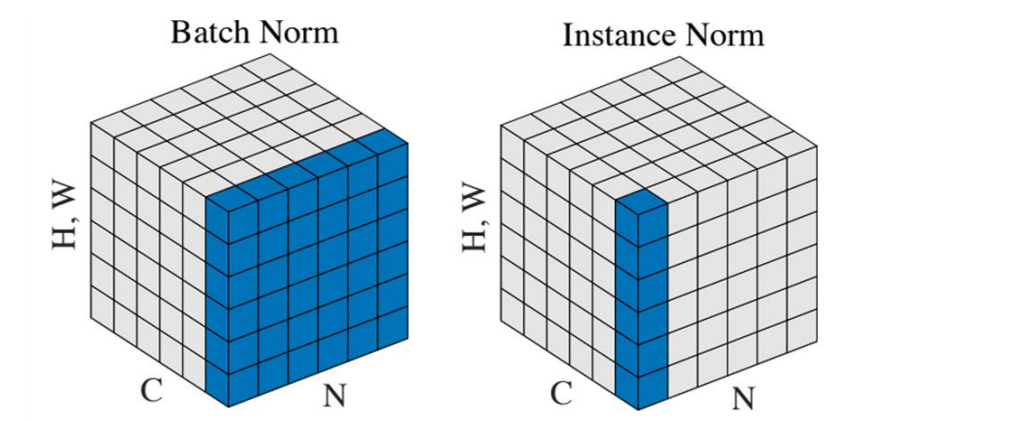
- 将 Batch Normalization 替换为 Instance Normalization 可改善结果


