
计算机视觉 20 RNN and Transformers
RNN
Recurrent Neural Networks: Process Sequences
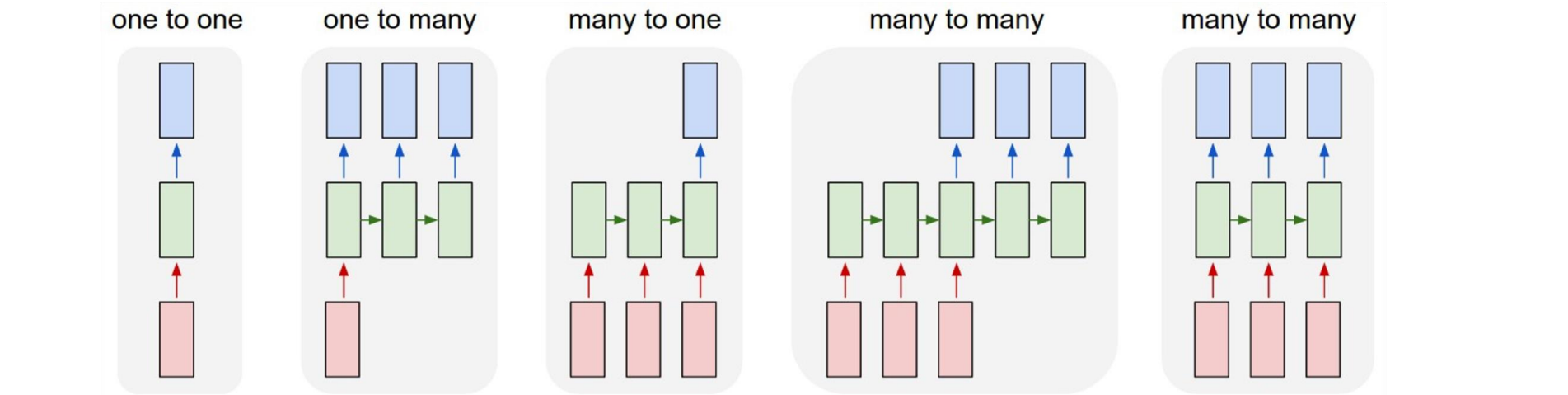
一对多:看图说话,输入一张图片输出一个文字序列,无法用CNN解决
多对一:视频分类,输入一个序列的图片,输出一个标签,无法用CNN解决
异步多对多:翻译,输入一个文字的序列,异步输出一个文字序列,无法用CNN解决
同步多对多:每帧视频分类,输入一个图片序列,输出一个标签序列,无法用CNN解决
RNN用于处理序列问题
Sequential Processing of Non-Sequential Data
- 对于非序列的数据,可以将其进行序列化转化为序列数据进行RNN
Recurrent Neural Networks
实现思想:维护一个内部状态,随输入输出不断更新
可以通过在每个时间步应用想通的递归公式来处理向量序列x,得到对应位置的y
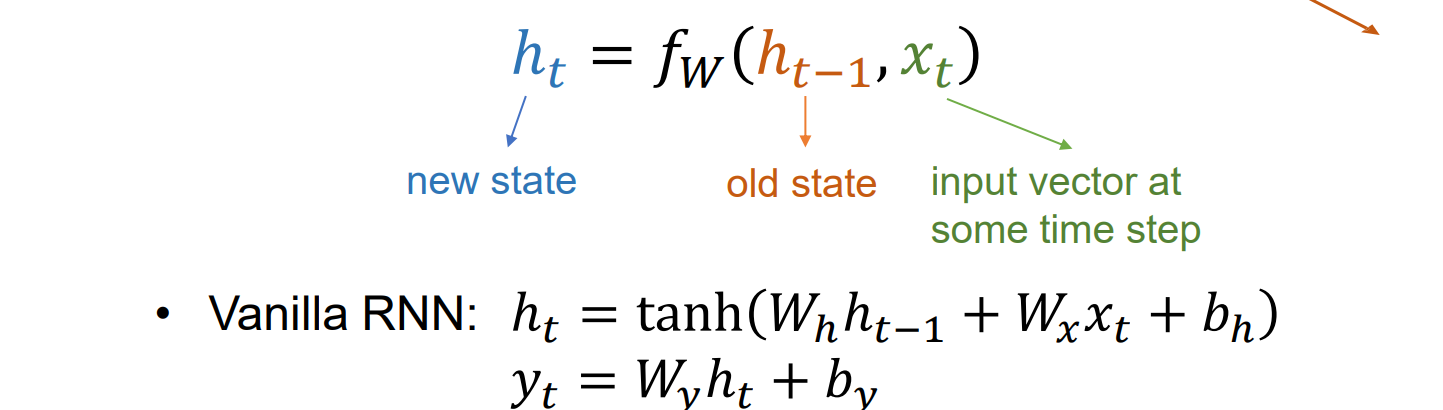
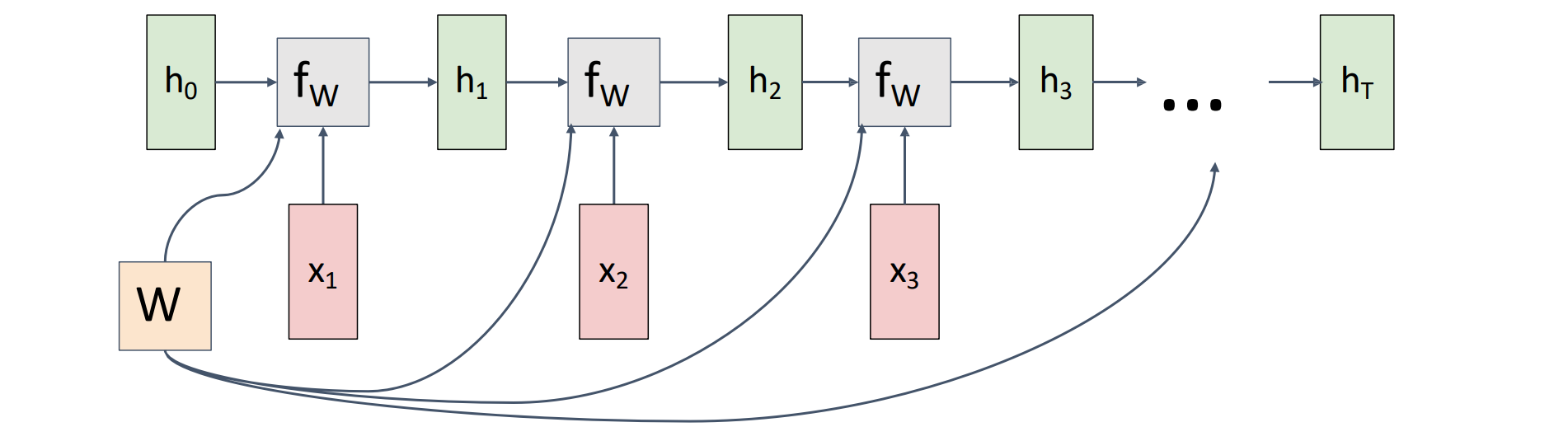
RNN Computational Graph
初始化隐藏层为0或者随机数来进行学习
在每个时间步长重复使用相同的权重矩阵
- 而many to many问题的计算图可以表示成:
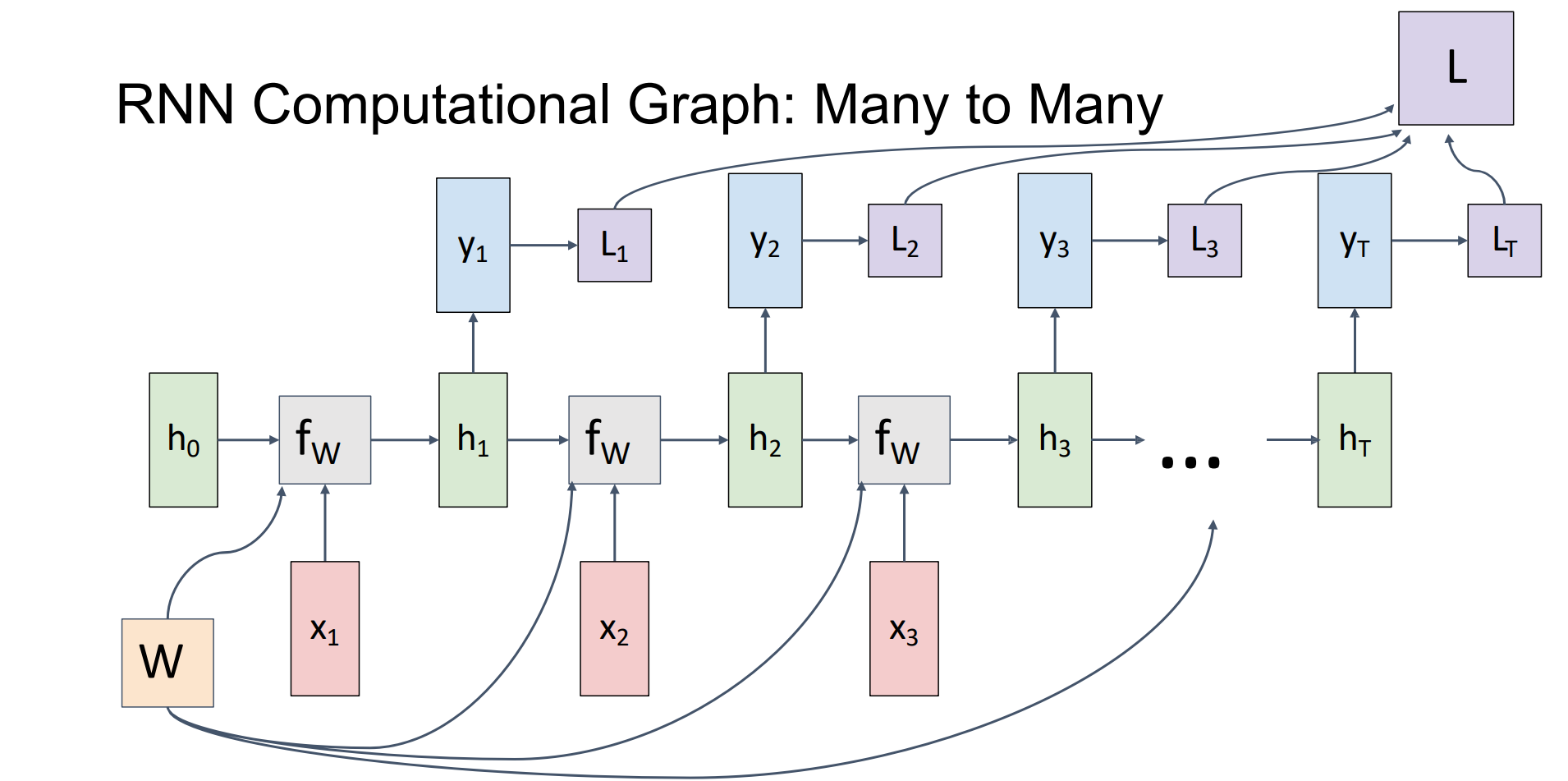
- 其中总损失函数是累加而得,因为权重矩阵是相同的(复制),因此总梯度是局部梯度累加而得,通过梯度下降法更新
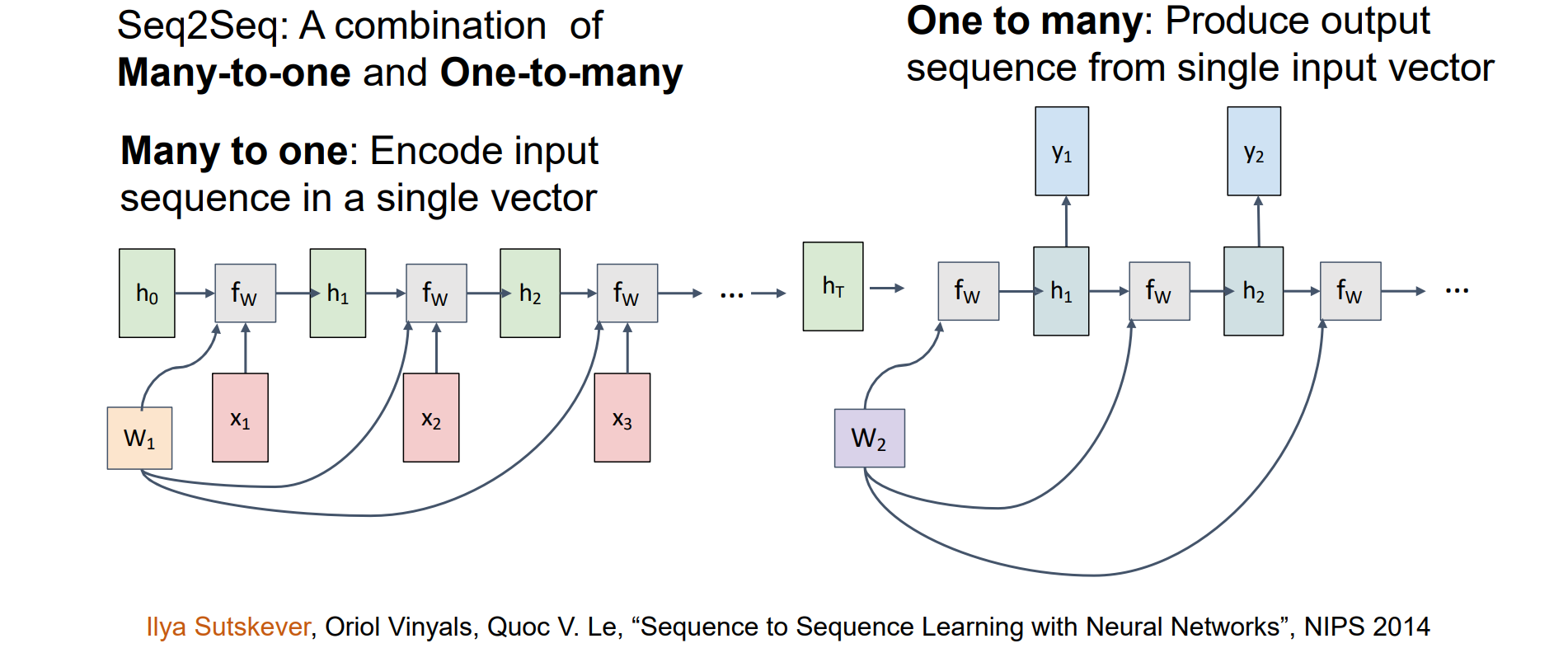
RNN Computational Graph: Sequence to Sequence
Seq2Seq:是Many-to-one和One-to-many的组合:
- Many to one:在单个向量中编码输入序列
- One to many:从单个输入向量生成输出序列
相当于先对输入进行理解形成隐状态,再从隐状态中解码获得输出,设置隐状态的原因是异步Seq2Seq任务是需要对整个输入序列进行理解,例如对整个句子进行翻译
Example: Language Modeling
- 目标:给定字符1,2,…,t-1,模型预测字符 t,将1,2,…,t-1吸收为隐状态
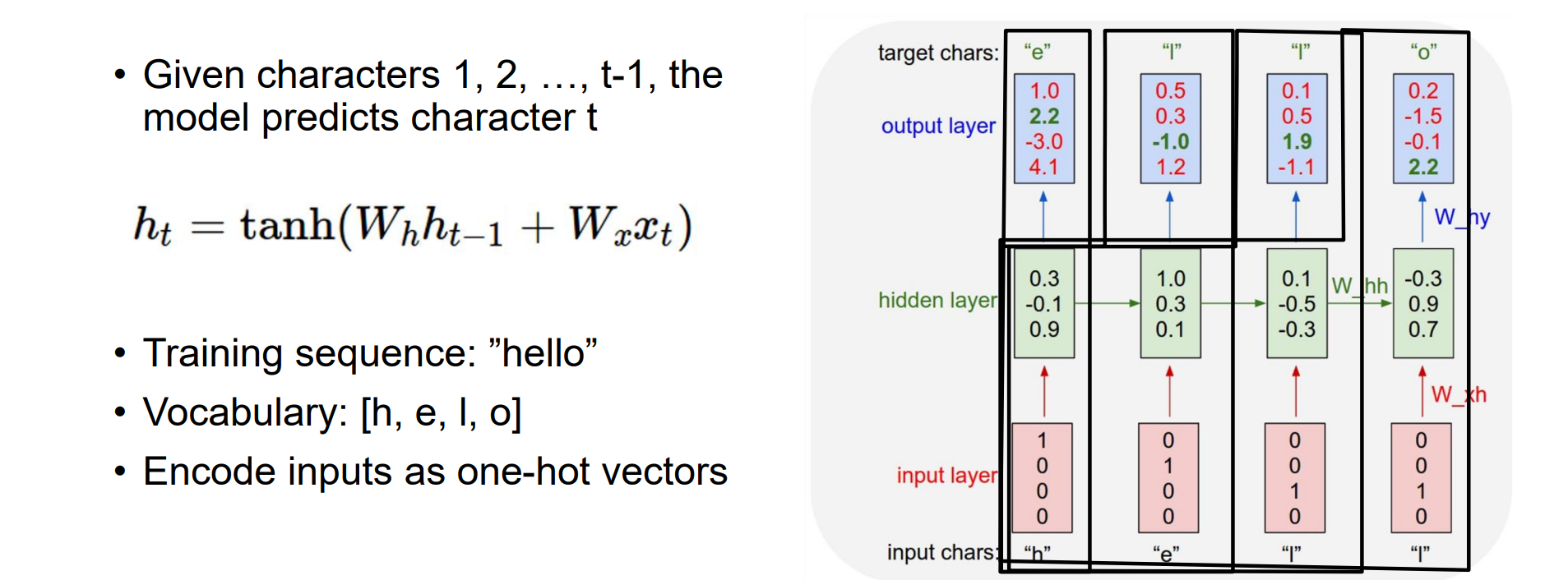
在测试时,生成新文本:一次一个示例字符,反馈给模型。先给定h,e作为真实的预测值进行训练,然后将h,e作为输入,l作为真实的预测值进行训练…
将每一个字映成one-hot编码形式
GPT的原理类似
训练方式被称为teach forcing:训练时有真实标签,测试时没有真实标签
Backpropagation Through Time
- 向前遍历整个序列以计算loss,然后向后遍历整个序列以计算梯度
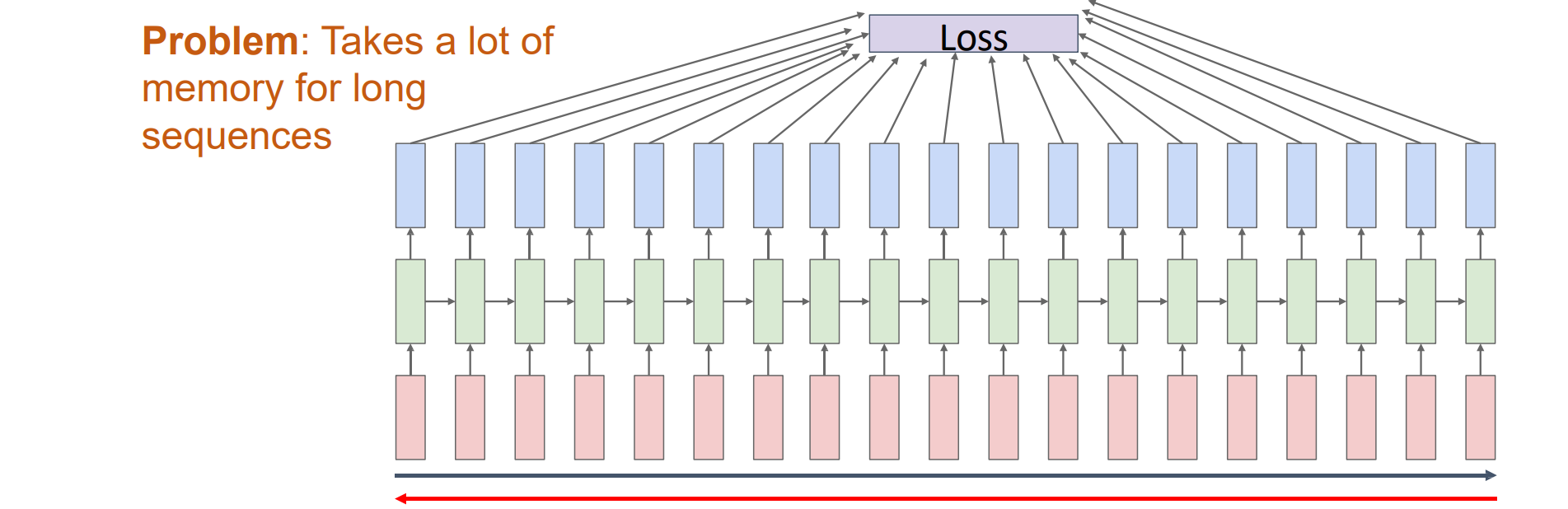
- 当序列比较长的时候w需要经过多次复制,因此梯度传播路径很长,计算所需空间内存较大
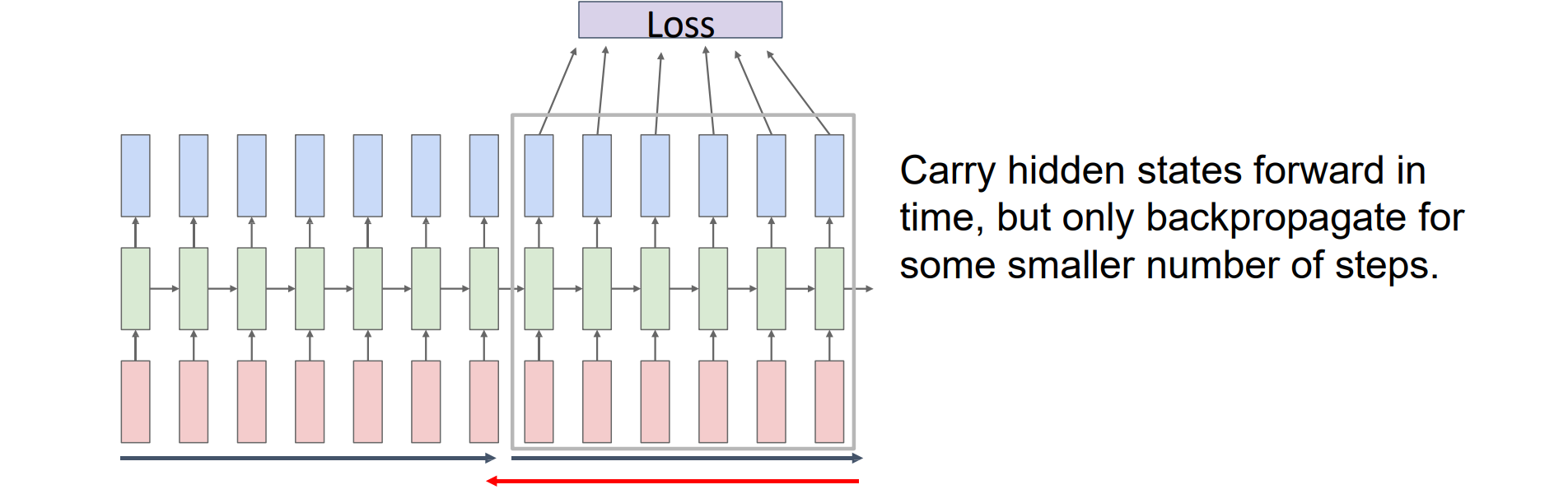
Truncated Backpropagation Through Time
向前和向后运行序列的块,而不是整个序列,采样batch计算梯度来进行截断
在时间上向前推进隐藏状态,但仅对少量步骤进行反向传播
Example: Image Captioning with RNN
字典:常见字符
先用CNN进行图像特征提取得到feature,再把feature输入到RNN中进行图像描述任务
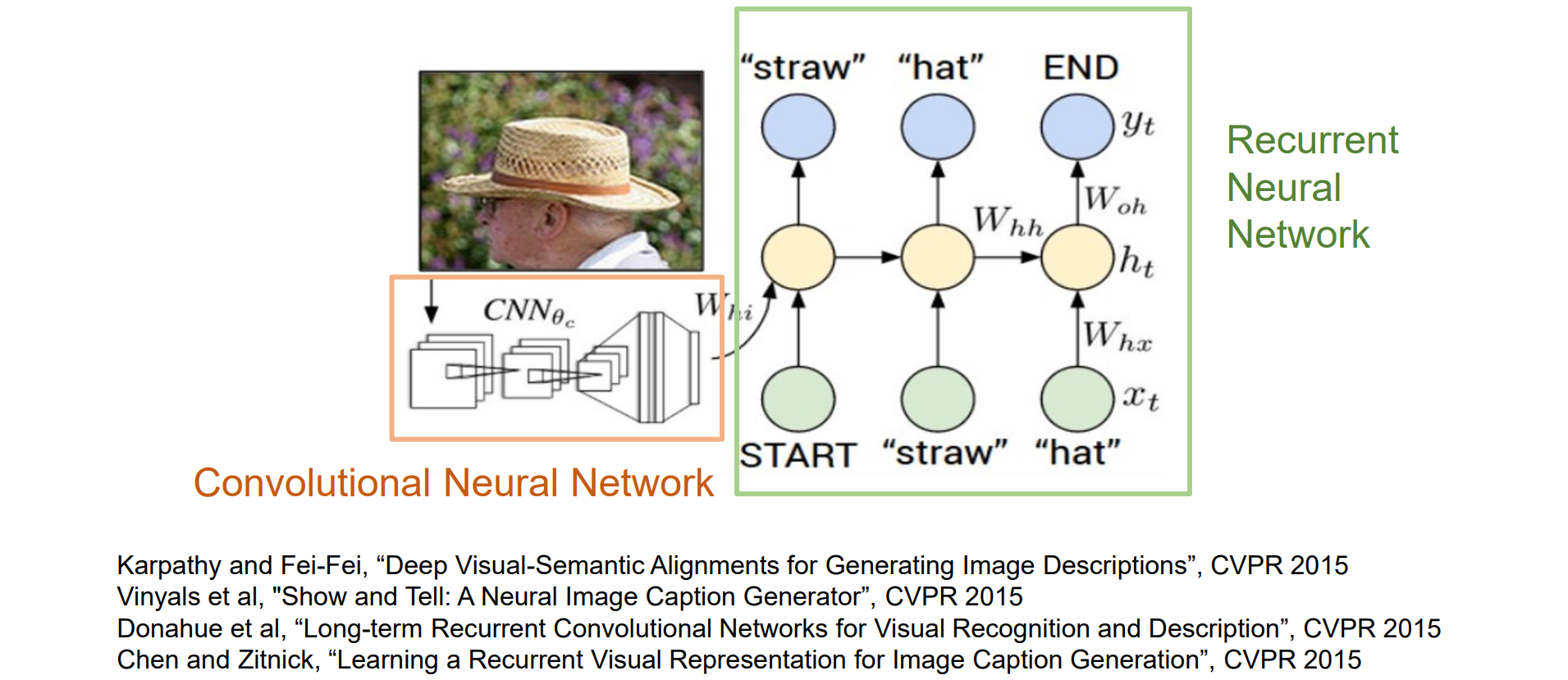
- 如何将feature加入到RNN中:
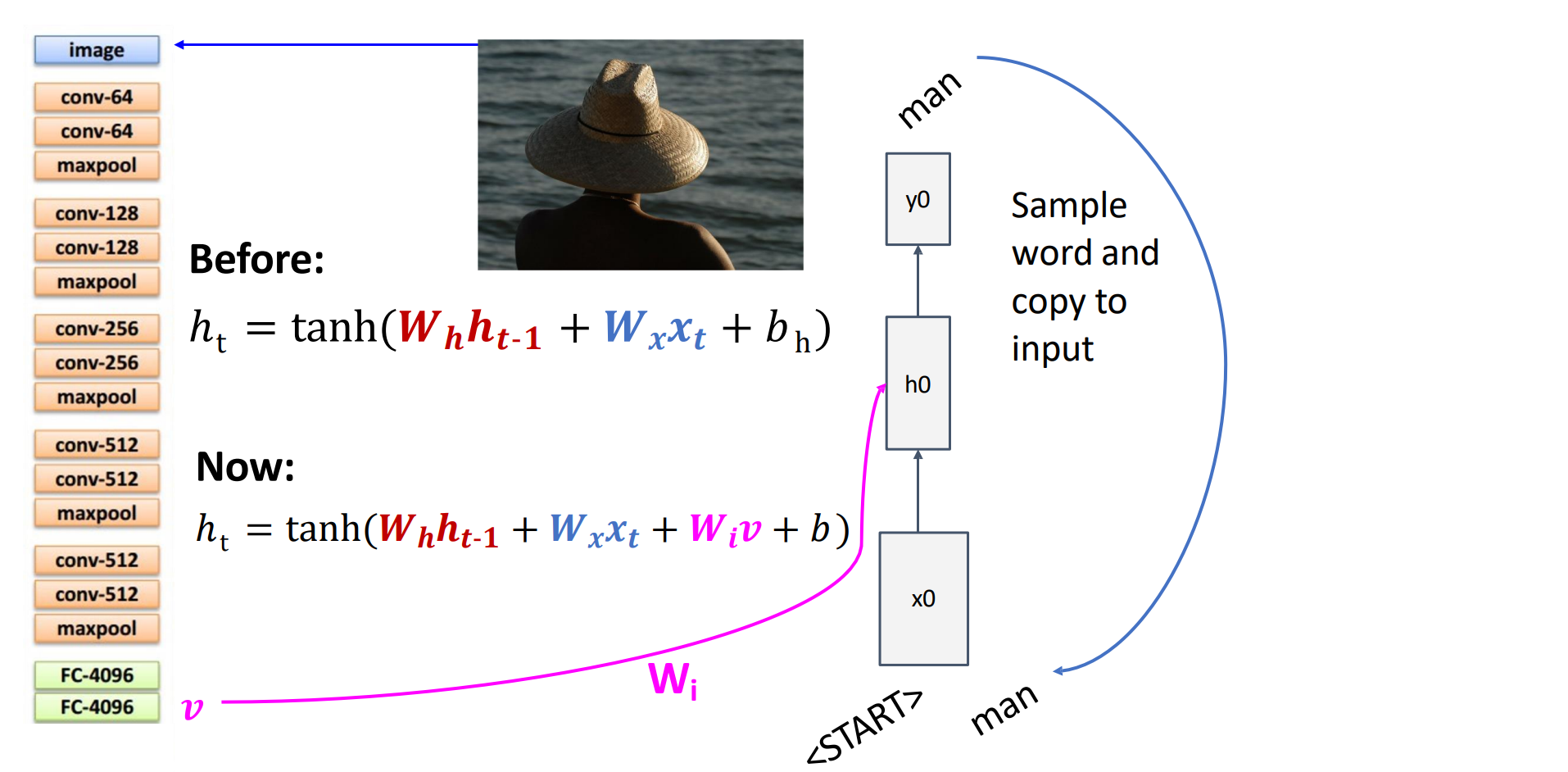
- 注意训练是异步的
Vanilla RNN Gradient Flow
以下红线代表梯度反向传播中梯度的流动方向
问题:训练不稳定,出现梯度消失和爆炸的问题
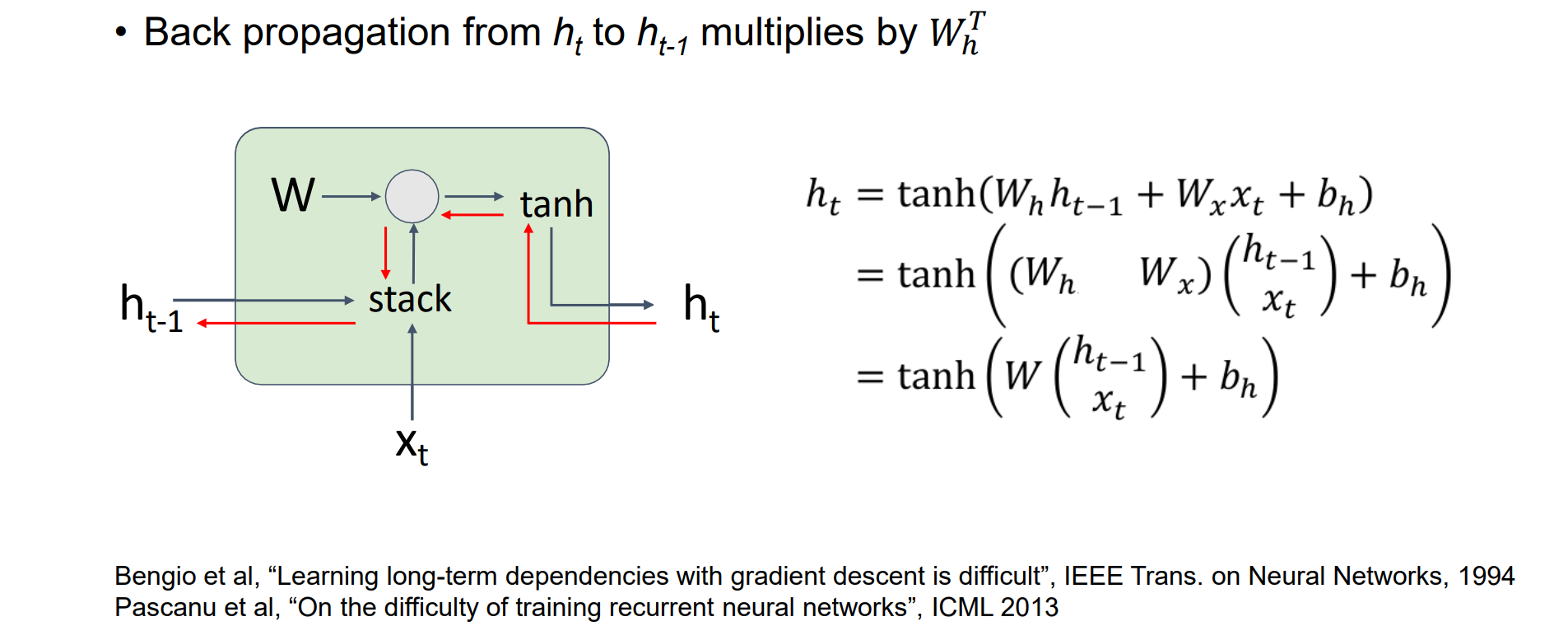
- 公式化简说明:RNN可以视为被循环使用的线性层
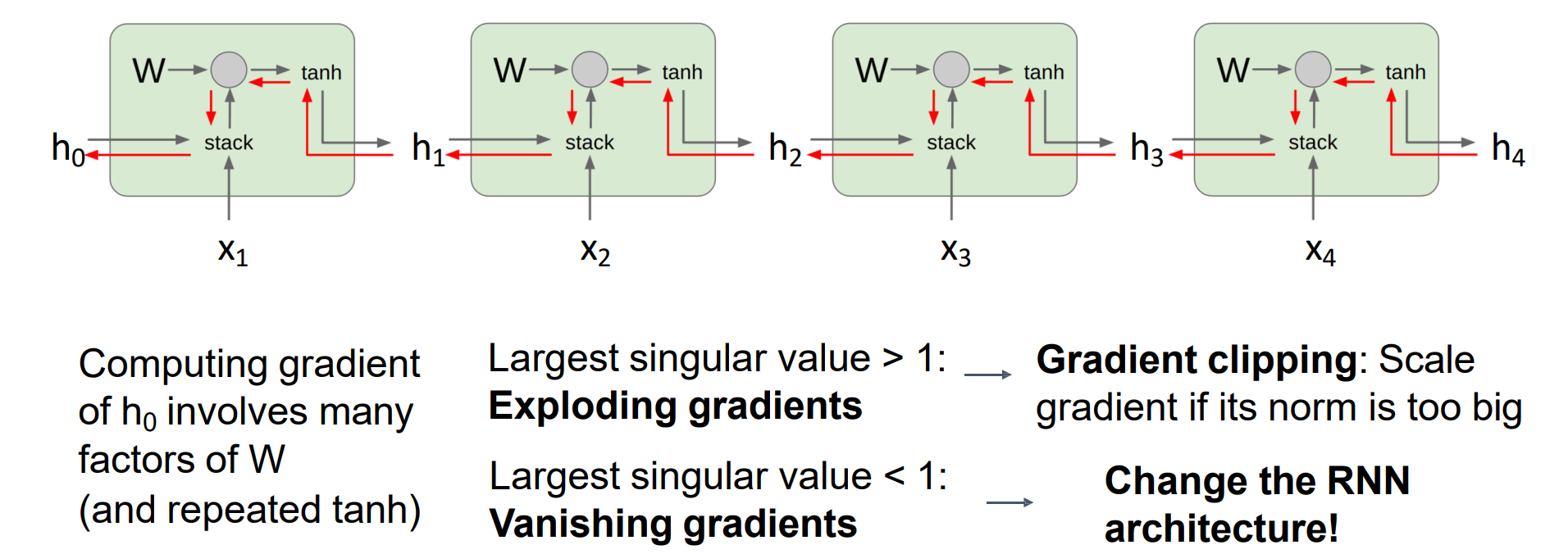
梯度传播过程中一系列的w相乘:
- 若奇异值>0,则会出现放大作用,可能导致梯度爆炸
- 若奇异值<0,则会出现减小作用,可能导致梯度消失
解决方法:加入LSTM,可以类比于ResNet
Vanilla RNN:
1 | import torch |
Long Short Term Memory (LSTM)
和RNN相比多了cell层和门,梯度可以再流畅传播,解决了梯度消失爆炸的问题
i是输入门,决定有多少状态更新cell
f是遗忘门,决定有多少概率忘记
g是更新后的feature
历史(Ct-1)一部分忘记(ft),一部分输入(it)更新cell state,cell state和ot来更新隐层藏ht
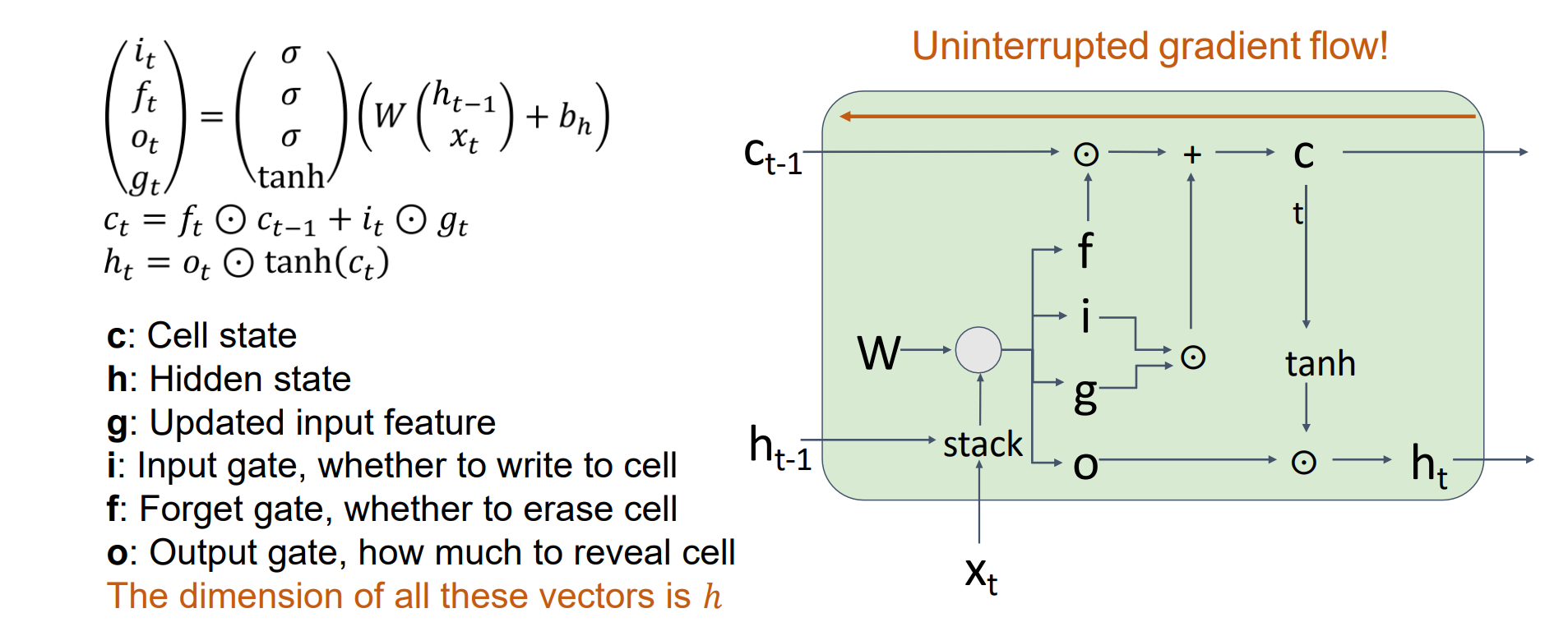
- LSTM_RNN:
1 | import torch |
Multi-Layer RNNs
- 将隐藏状态从一个 RNN 作为输入传递到另一个 RNN,形成多层RNN
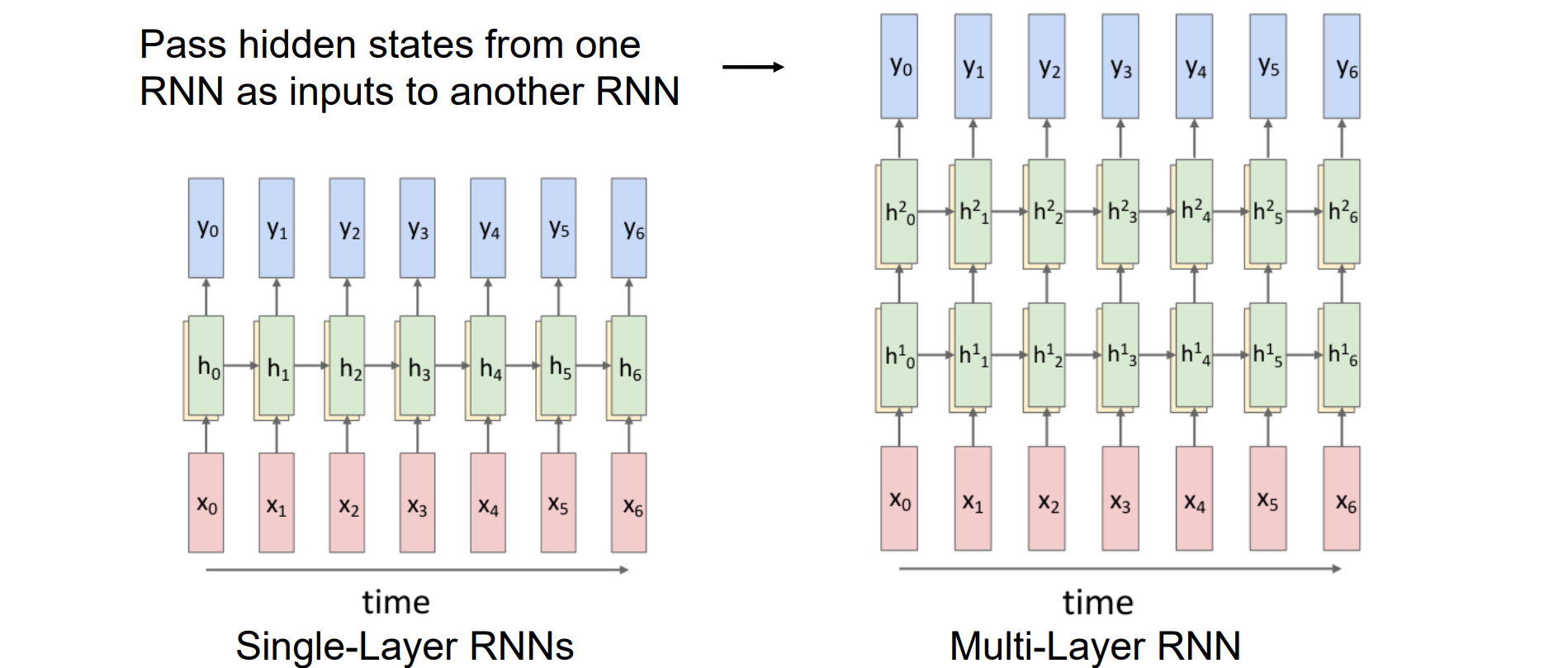
- 其中每一列都可以视为一个CNN
Transformer
Motivation of Attention
RNN的优点:计算高效
RNN的缺点:使用 RNN 的Seq2Seq模型的问题:输入序列通过固定大小的向量出现bottlenet问题,压缩成隐藏层时信息有损失,希望能够输出与输入直接有关联
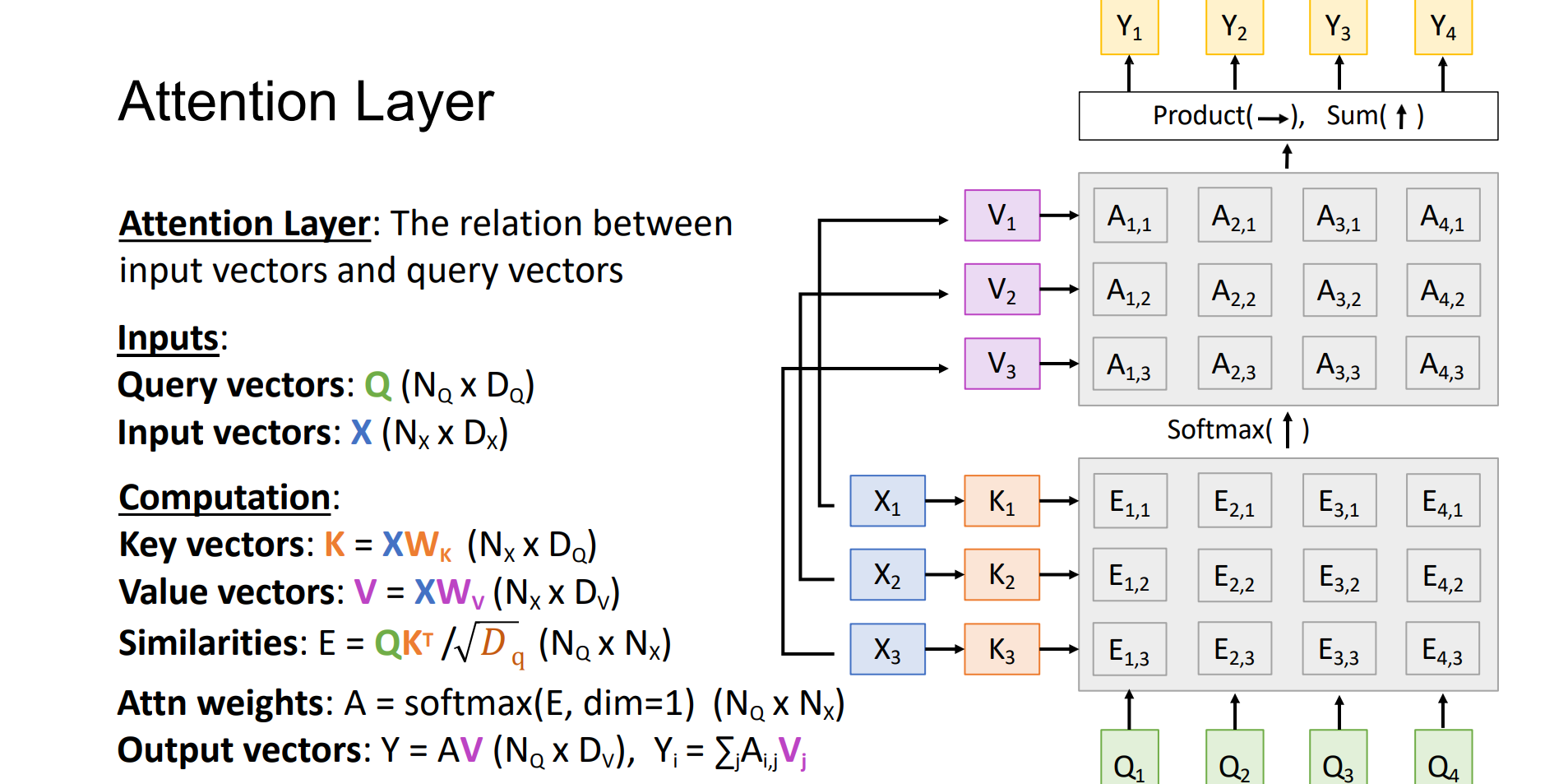
Attention Layer
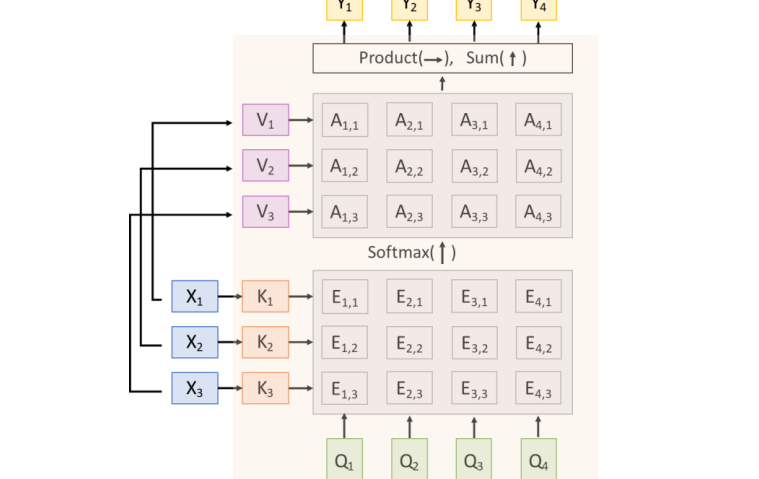
Attention Layer:input vectors和query vectors找相互关系,类似于可微分的检索
输入:
- Query vectors: Q (NQ x DQ),有NQ个q,维度是DQ
- Input vectors: X (NX x DX),有NX个x,维度是DX
key和value均为XW计算得到
用Q在X中找最近邻,和什么key最相似
Similarities: E = QK.T / sqrt(𝐷q)x(NQ x NX)
Attn weights: A = softmax(E, dim=1) (NQ x NX),得到的是概率矩阵,每一列相加为1
Output vectors: Y = AV (NQ x DV), Yi = ∑jA(i,j)Vj
Self Attention: compute 𝑄 from 𝑋, 𝑄 = 𝑋𝑊𝑞,Q与X相关。否则称为Cross Attention
Scaled Dot-Product Attention: 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(𝑄,𝐾,𝑉) = 𝑠𝑜𝑓𝑡𝑚𝑎x(E),使用sqrt(dk):当 DK 较大时,点积的幅度会增大,从而将 SoftMax 函数推入梯度极小的饱和区。÷sqrt(dk)后方差为1
Attention is permutation equivariant(交换不变性):考虑排列 input 向量,那么 Queries、Keys、Values 和 Outputs 将相同,但也进行了置换
因此需要显式的将位置信息加入到神经网络中:将位置编码 PE 连接或添加到输入,PE 可以是学习的查找表,也可以是位置的 sin/cos 特征
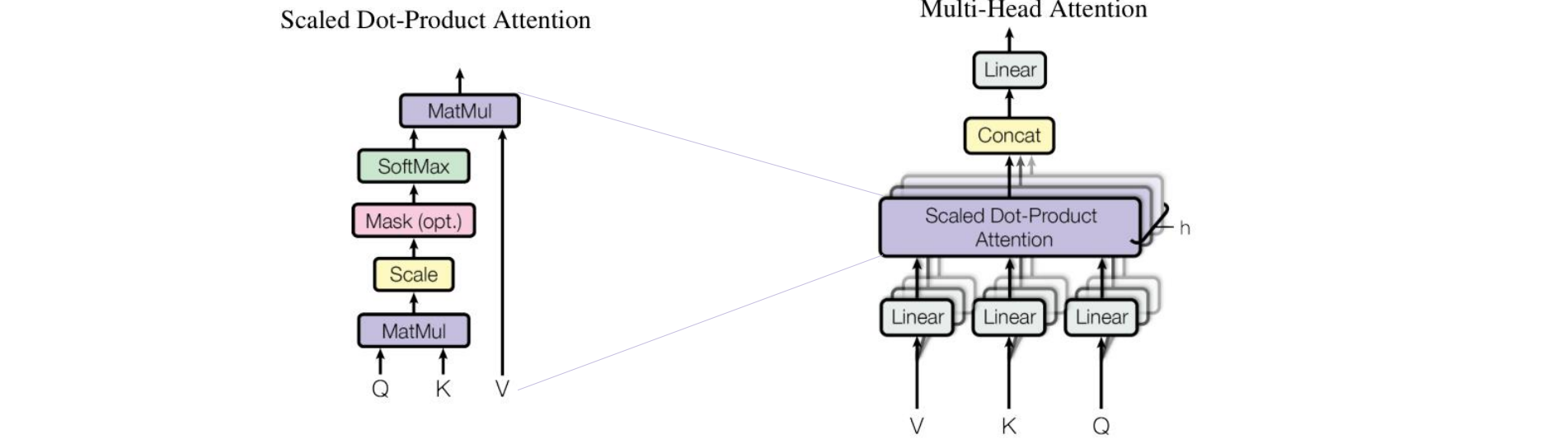
Multi-Head Attention
问题:Q点乘K只有一种可能得结果,相互关系太简单,因此要进行分组
实现思路:
- 线性投影查询、键和值 h 次
- 并行执行 h 次的 attention 函数,然后拼接并投影结果
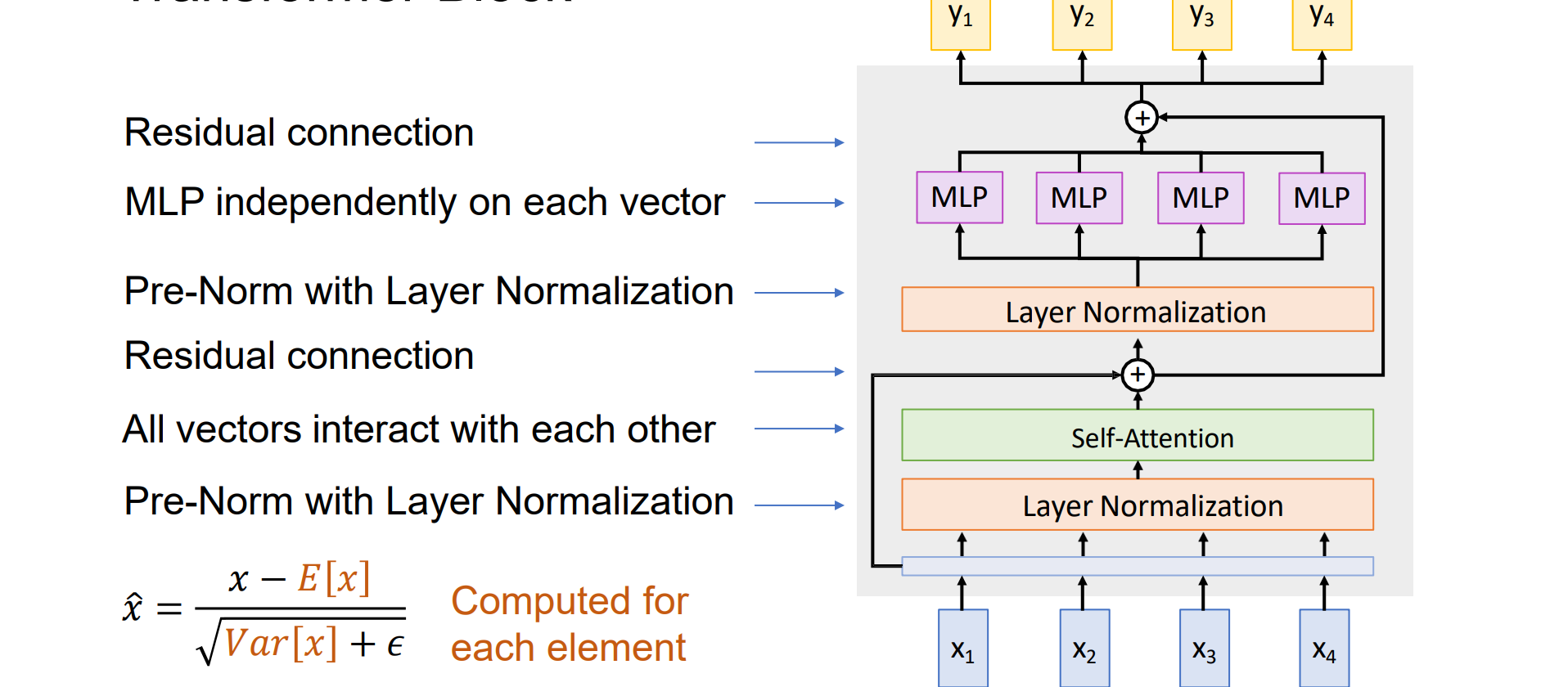
Transformer Block
Transformer Block由多个self-attention层和多个MLP层拼接而成
实现思路:
- 先对x进行正则化,应该对c个通道正则化,沿着D维度进行正则化
- 然后用attention计算元素相互关系
- 加入残差连接
- 进行正则化
- MLP进行通道间的变换
- 加入残差连接
可以高度并行化,规模化实现
LayerNorm 和 MLP向量独立工作,Self-attention是向量之间唯一的交互
- Transformer Block:
1 | import torch |
Transformer
Transformer由多个transformer block形成
Vaswani et al: 12 blocks, DQ=512, 6 heads
Transformer:
1 | import torch |
Three Ways of Processing Sequences
RNN
优点:省内存
长序列:在一个 RNN 层之后“看到”整个序列
缺点:难以并行
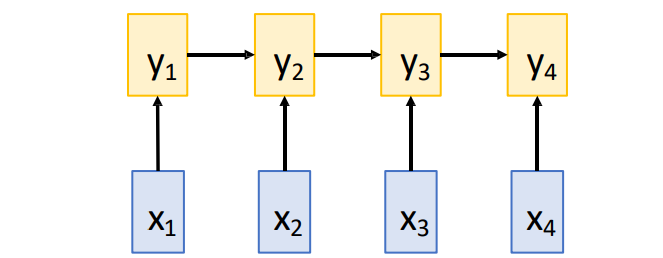
1D Convolution
优点:容易并行
缺点:长序列的感受野小
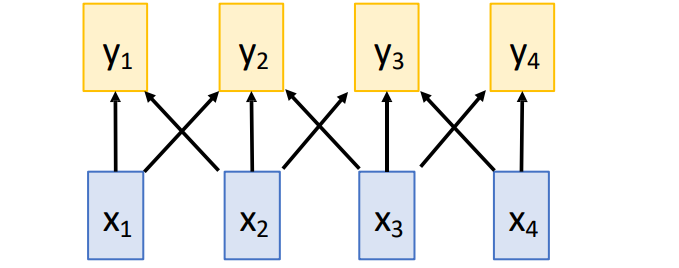
Self-Attention Layer
优点:每一个输出可以看到每一个输入,容易并行化规模化
缺点:耗内存
Transformers on Pixels
- 将图像转换为序列:从左到右从上到下扫描形成序列
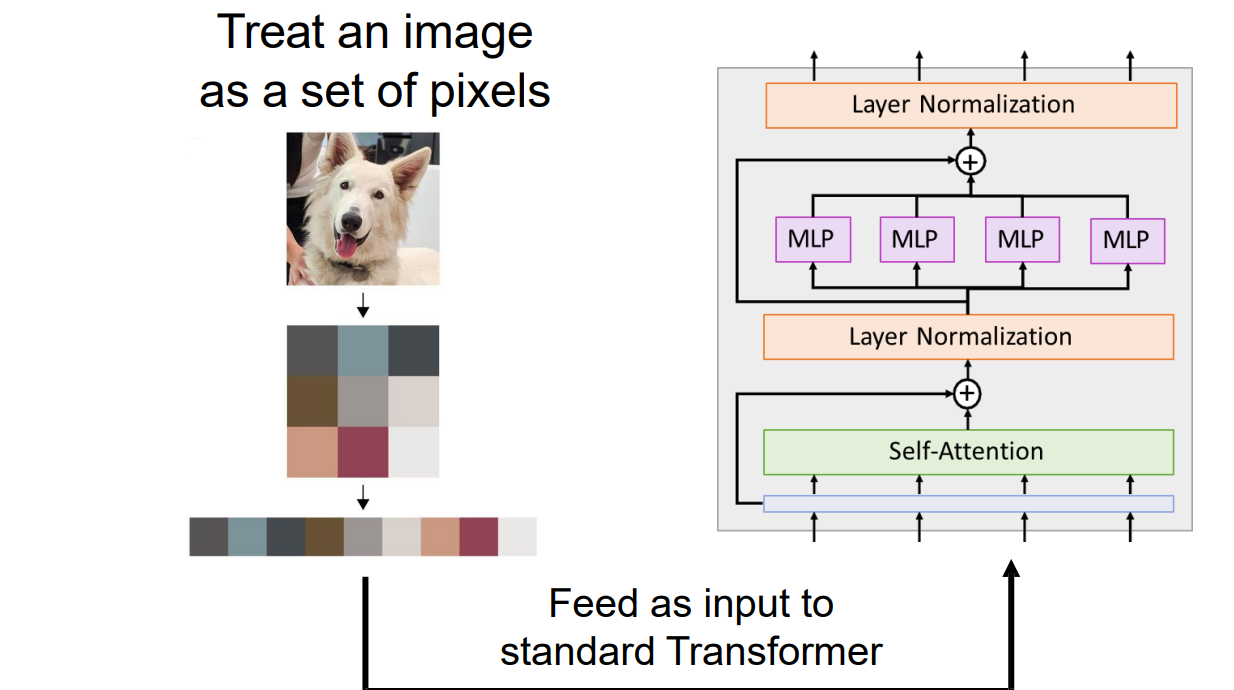
- 问题:高像素会导致计算存储都很大。R x R 图像每个attention矩阵需要 R4 个元素;对于 R=128、48 层、16 个头,单个示例的attention矩阵需要 768GB 的内存
Transformers on Image Patches
- 解决方法:将一个image分成patch形式形成多个token

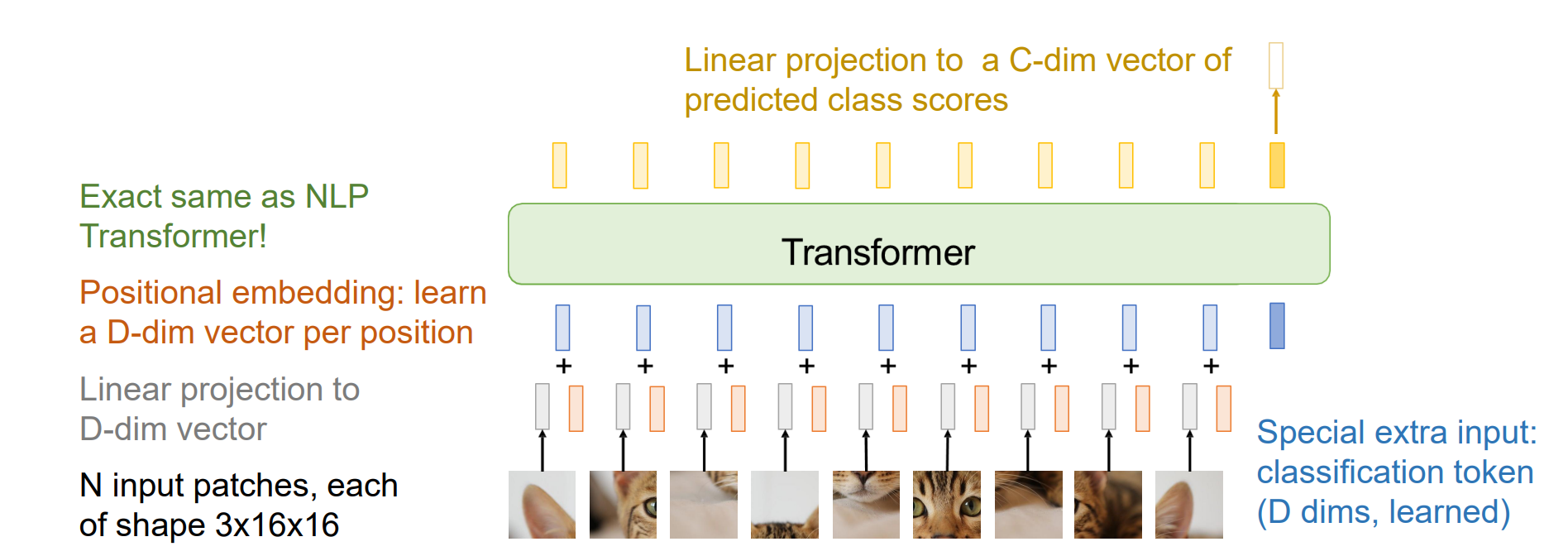
Vision Transformer (ViT)
第一个没有卷积的计算机视觉模型
ViT 在像素上比Transformer效率高得多,在大的数据集上优于ResNet
在大多数 CNN(包括 ResNets)中,随着我们在网络中深入,会降低分辨率并增加通道(分层架构Hierarchical architecture),希望在ViT中也使用Hierarchical architecture,从而更符合视觉
Hierarchical ViT: Swin Transformer
- 进行若干次attention后进行一次降采样:2x2的图像块映射到更高维
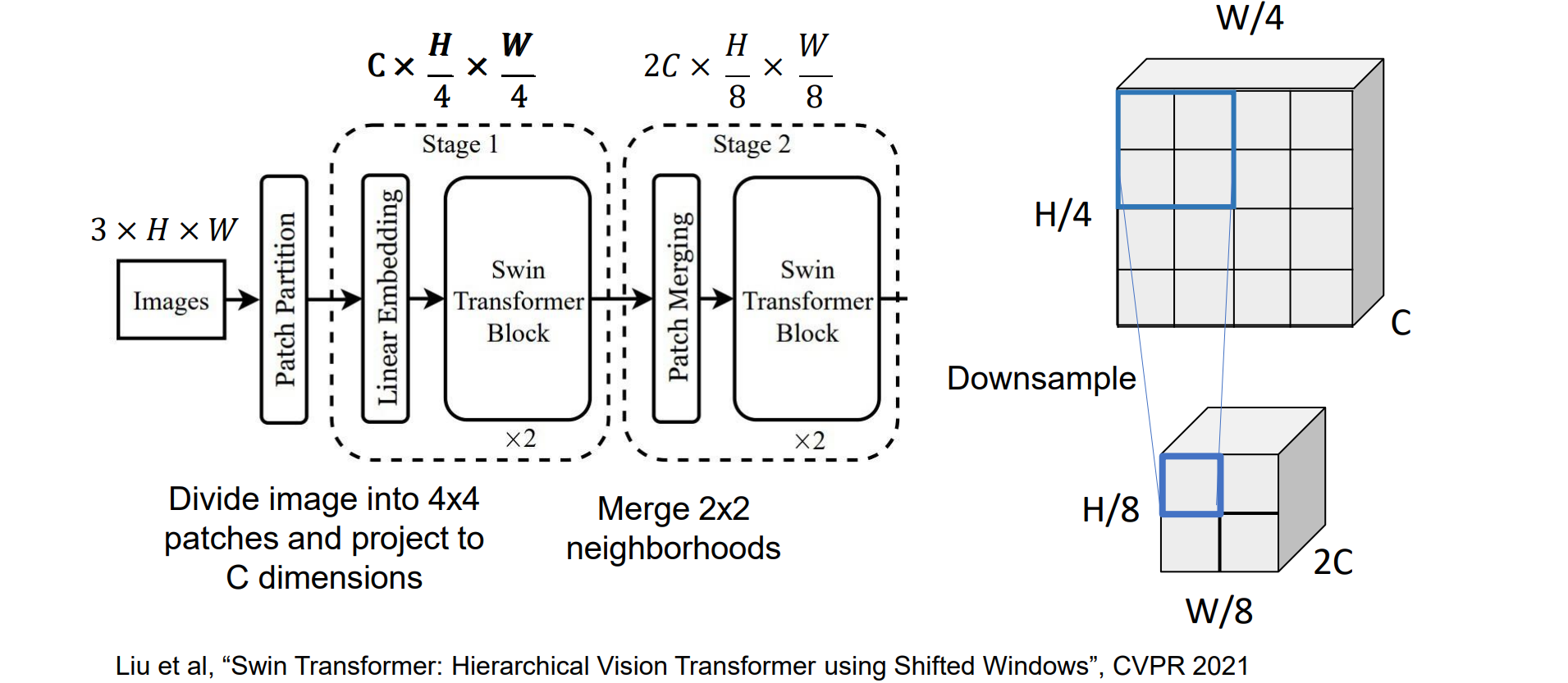
问题:元素多,计算量大
解决方法:进行图像分块(patch),在每一块上进行attention
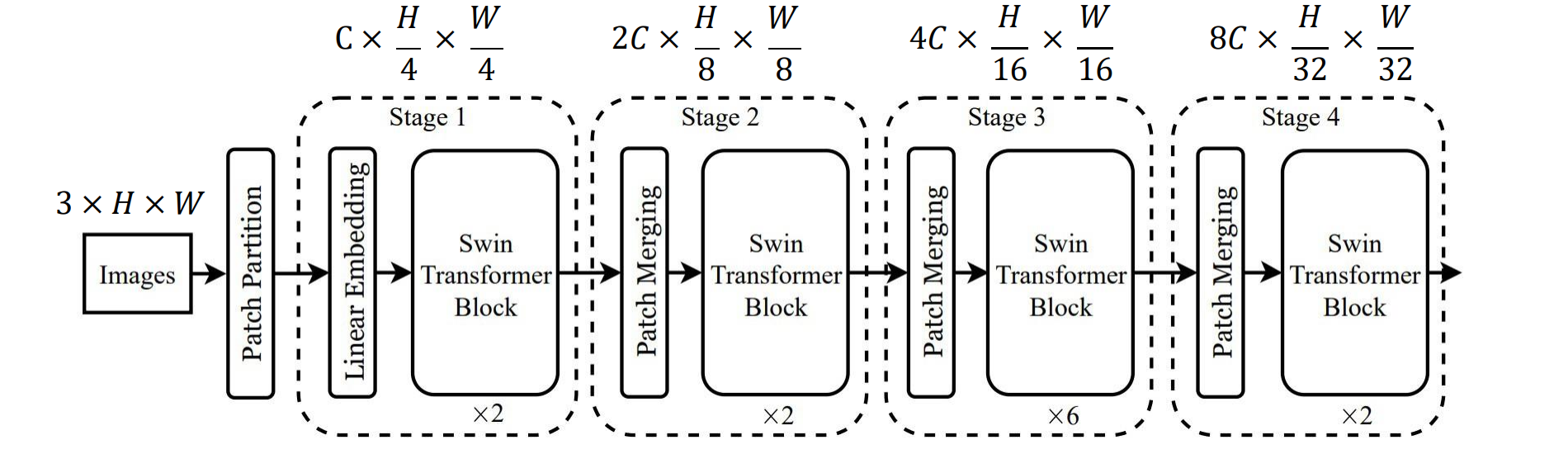
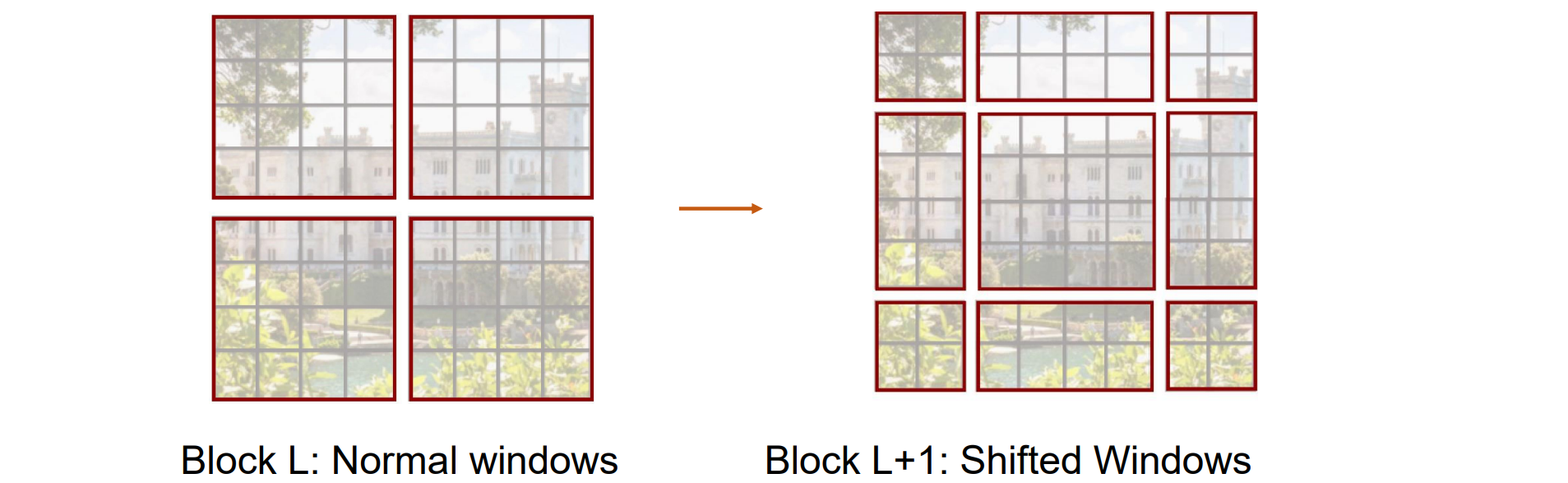
Swin Transformer: Window Attention
使用 H x W 标记网格,每个注意力矩阵都是(H^2)(W^2),即图像大小的二次方
不让每个 Token 关注所有其他 Token,而是将图像划分为 M x M Tokens 的窗口(此处为 M=4);仅计算每个时段内的注意力
所有注意力矩阵的总大小现在为:(M^4)(H/M)(W/M) = (M^2)HW
问题:Tokens仅与同一窗口内的其他Tokens交互;没有跨Windows交互
解决方法:在连续的 Transformer 块中交替使用普通窗口和移位窗口,更换窗口的划分形式,迭代几次
ViT 为输入标记添加了位置嵌入,对图像中每个标记的绝对位置进行编码
Swin 不使用全局位置嵌入,而是在计算注意力时对patches之间的相对位置进行编码

- Swin:
1 | import torch |

