计算机视觉 18 Convolutional Networks2
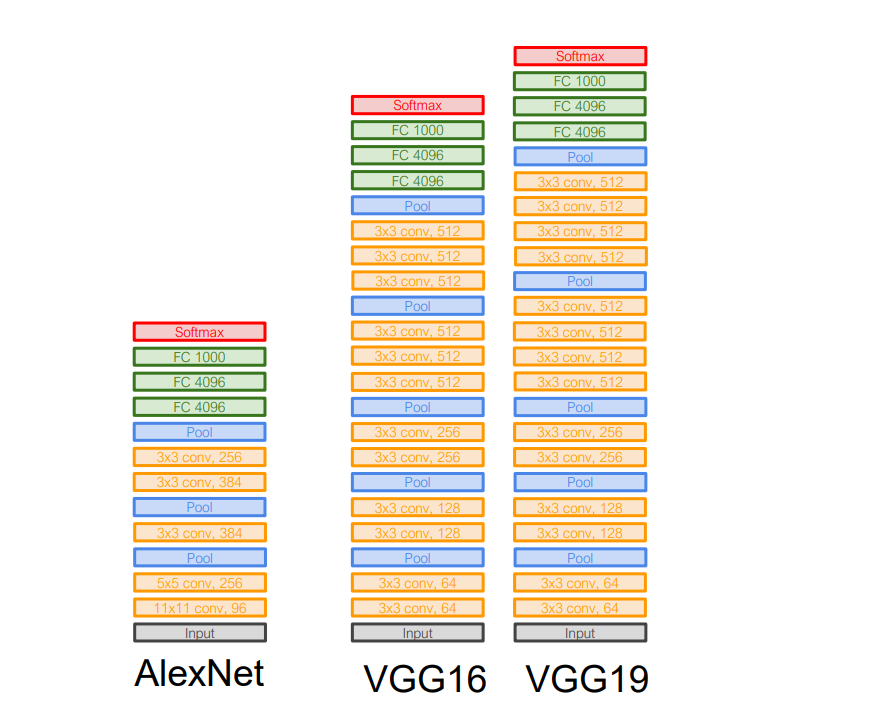
VGG: Deeper Networks, Regular Design
核心思想:更深,卷积层数更多;标准化模块,卷积有标准化
VGG设计规则:
- All conv are 3x3 stride 1 pad 1
- All max pool are 2x2 stride 2
- After pool, double #channels,在分辨率压缩的同时保持信息量
VGG的5个stages:
- Stage 1: conv-conv-pool
- Stage 2: conv-conv-pool
- Stage 3: conv-conv-pool
- Stage 4: conv-conv-conv-[conv]-pool
- Stage 5: conv-conv-conv-[conv]-pool
VGG19比VGG16在stage4和5中多一个卷积层
Why 3x3 layers?
- 标准化,容易加速
- 多个3x3的卷积核可以形成大卷积核:two 3x3 layers – 5x5 receptive field;three 3x3 layers – 7x7 receptive field
- 多个3x3的卷积核提供了更多的非线性,拟合能力强
- 感受野相同的前提下参数量更少:Conv(5x5, C → C): 25𝐶² parameters;Conv(3x3, C → C): 2 × 9𝐶² = 18𝐶² parameters
VGG16:
1 | import torch |
GoogLeNet
- 核心思想:多分支模式;全局平均池化;中间层分类器
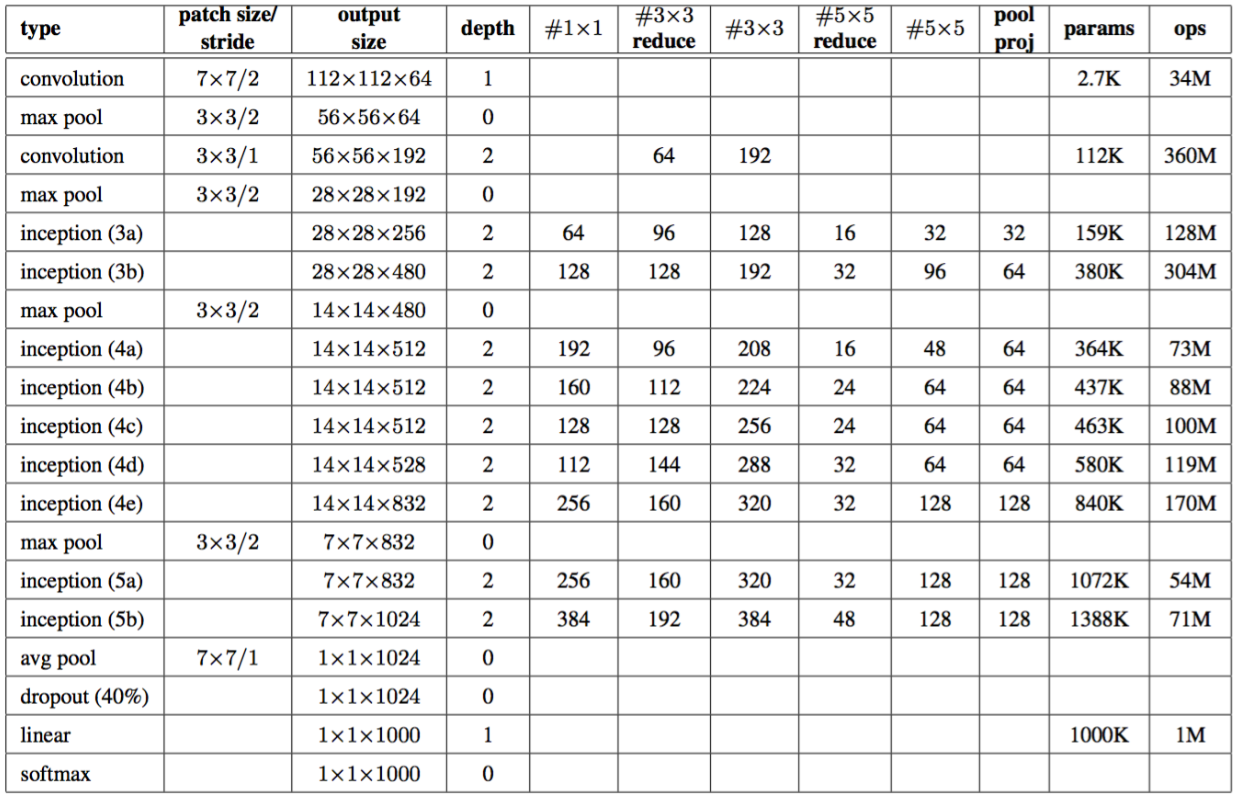
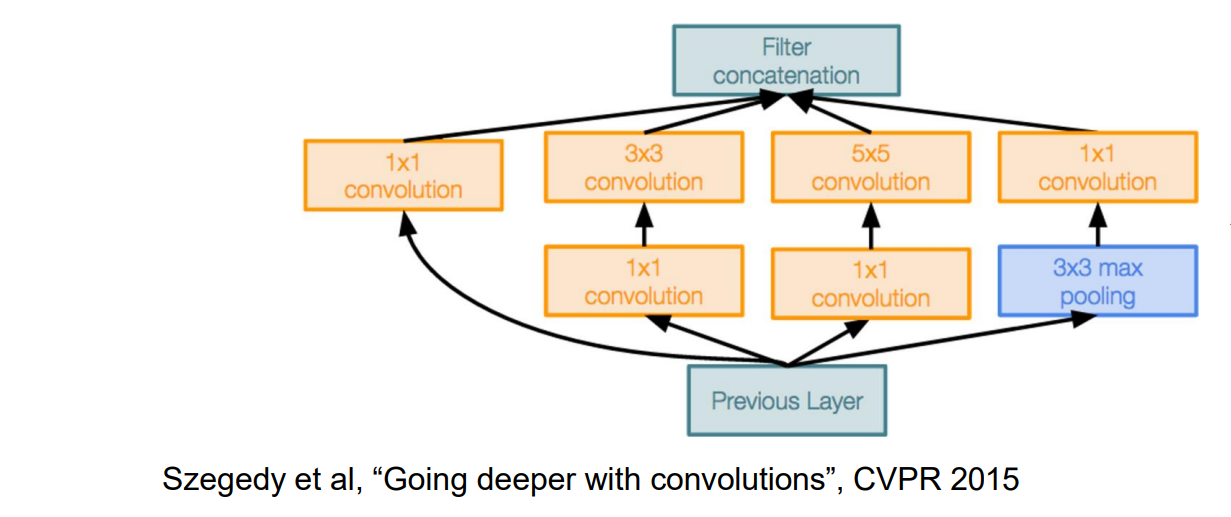
GoogLeNet #1: Inception Module
Inception 模块:具有并行分支的本地单元。由于无法确定卷积层的最佳大小,于是采用不同分支用不同大小的卷积,自动选择最好的分支
使用1x1”Bottleneck”:提高了非线性性;增大了中间通道数
GoogLeNet #2: Global Average Pooling
最后没有大的 FC 层,减少了参数量
使用全局平均池化来减少空间维度,并使用一个线性层来生成类分数
GoogLeNet #3: Auxiliary Classifiers
在中间层加入全局平均池化和分类器,使得梯度可以从深的位置传到浅层位置
在网络末端使用 loss 进行训练效果不佳: 网络太深,梯度不能很好地传播
深度监督:在网络中的几个中间点附加“辅助分类器”,这些中间点试图对图像进行分类并接收损失
有了 BatchNorm后,不再需要使用这个技巧
GoogLeNet:
1 | import torch |
Deep Networks are Hard to Train
- 神经网络仍然不能过深,会出现梯度消失、梯度爆炸的问题
Weight Initialization
Gradient Vanishing
- 乘方差较小的噪音时会导致值趋于0,深层网络都为0,从而使得梯度为0,出现梯度小时的问题


Gradient Exploding
- 方差过大导致大的数累乘,使得梯度进入饱和区(如下图)或导致梯度爆炸


Xavier Initialization
- “Xavier” initialization: Var(w) = 1 / N, N is the dimension of 𝑥,以全连接层为例推导:
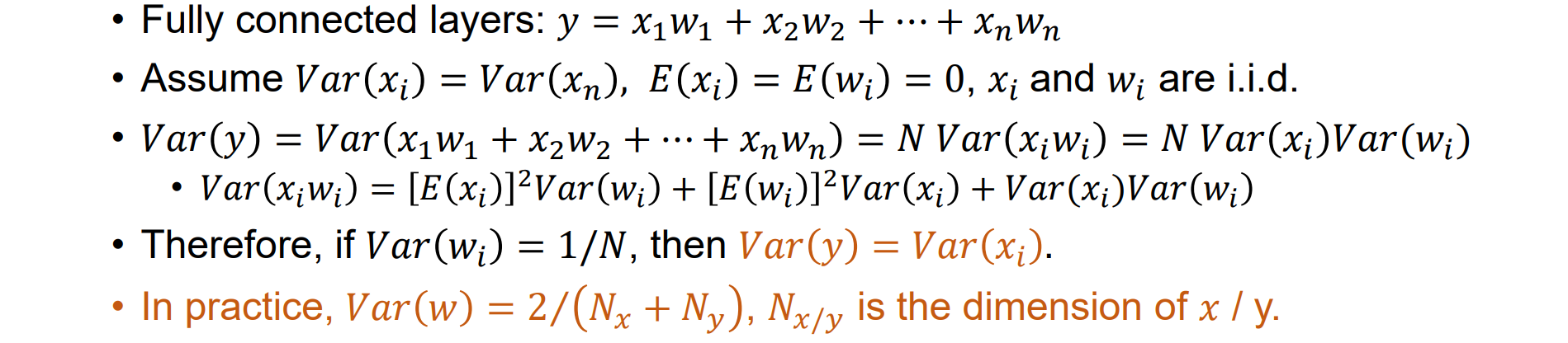
Xavier initialization没有考虑激活函数,其中tanh函数效果最好,其他激活函数也可以使用
而对于卷积层,则可以把卷积层当成多个小的全连接层,对于卷积层,N 为 kernel_size² * (input_channels + output_channels) / 2

Kaiming Initialization
层数过多使用ReLU激活函数时,Xavier初始化仍会导致梯度问题
Kaiming initialization: Var(w) = 2 / N, N is the dimension of 𝑥 (For ReLU),以全连接层为例推导:
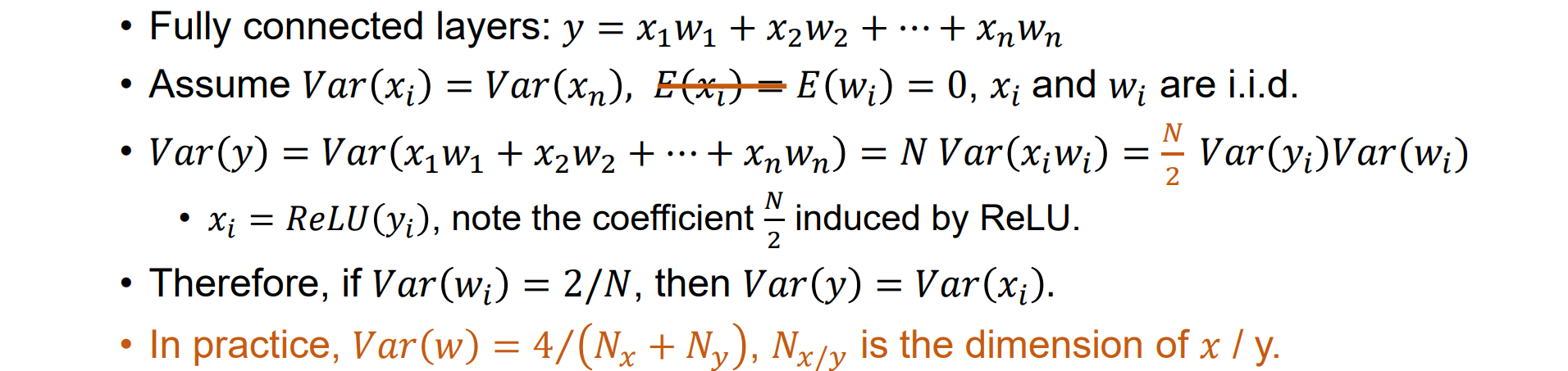
- Kaiming初始化最适配于ReLU激活函数
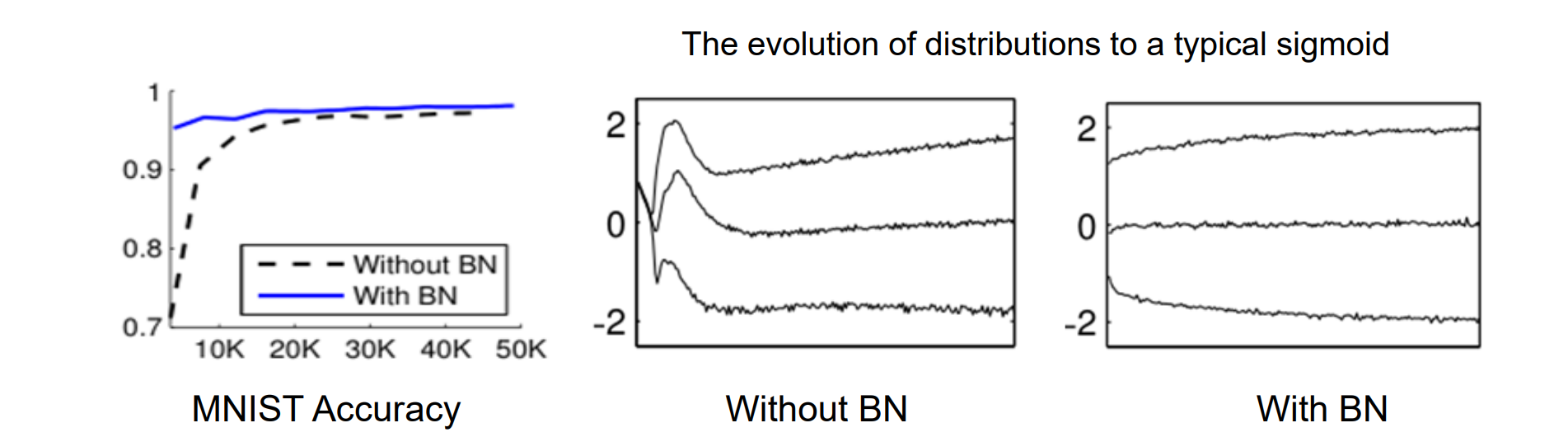
Batch Normalization
核心思想:“动态”标准化每一层的输出,使其均值和方差为零,归一化内部特征以稳定训练,减少梯度消失和爆炸
使用整个数据集的均值和方差进行归一化的代价很高;可以像这样规范化一批激活:
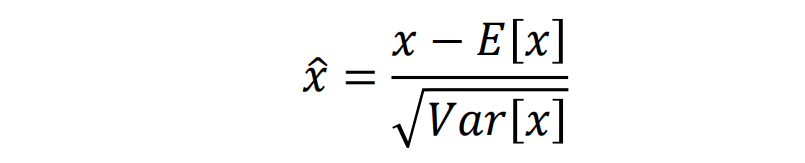
这个公式可微,可以当成一层
输入:x ∈ RN×D,动态计算均值和方差
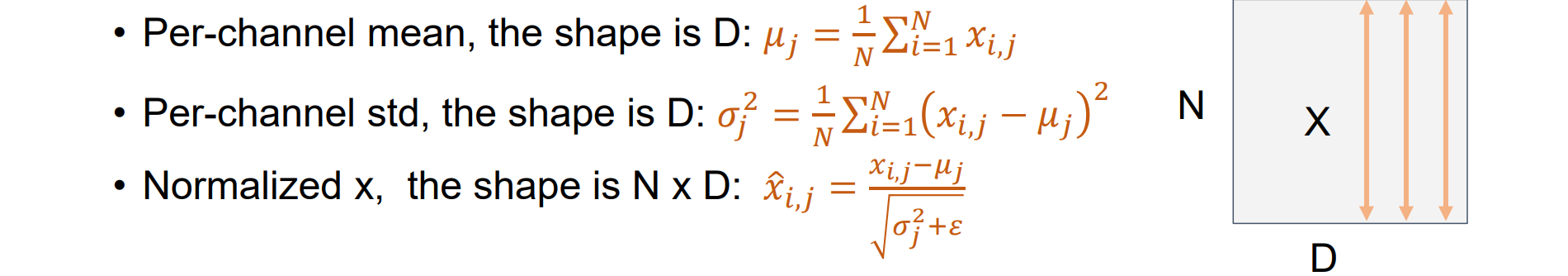
在 RD 中添加可学习的缩放和移位参数从而使其可以拟合任何分布
记录训练期间看到的 μ 和 σ 的运行平均值,因为无法在测试的时候使用
Batch Normalization for CNNs
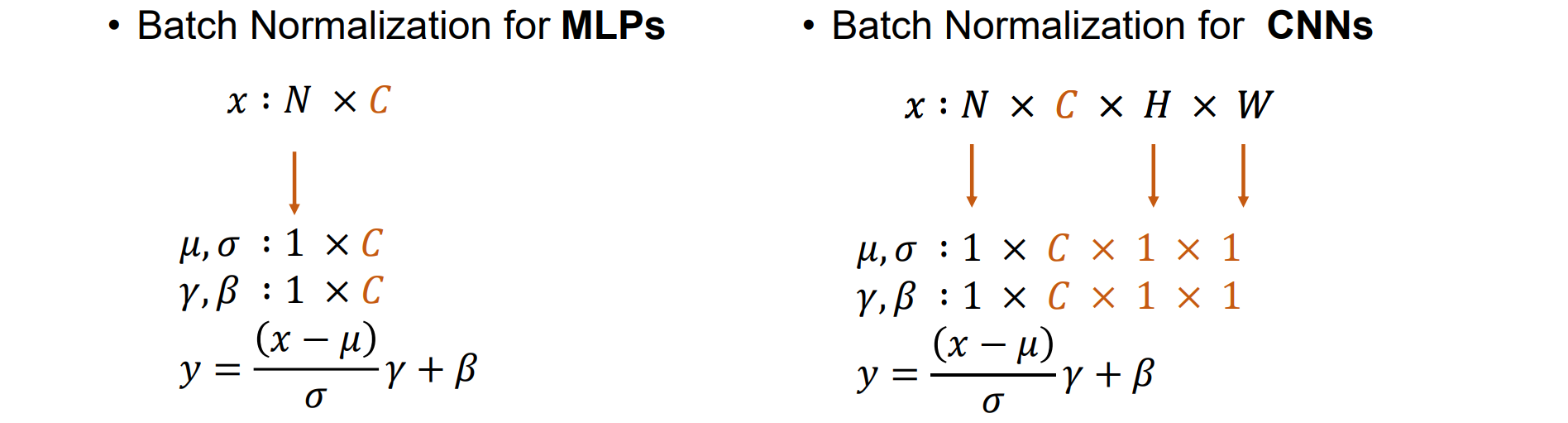
对于卷积层,希望归一化遵循卷积属性——以便同一特征图的不同元素在不同位置以相同的方式归一化
BN是在每个通道上进行计算
通常插入到全连接层或卷积层之后,非线性之前
使深度网络更易于训练,允许更高的学习率,更快的收敛
网络对初始化变得更加鲁棒
在训练期间充当正则化
缺点:缺少理论解释;训练和测试时候模式不同容易导致bug
Group Normalization
当batch变小时,BN 的误差会迅速增加
GN 的计算与批量大小无关,其准确性在很宽的范围内保持稳定,即使批量大小为2
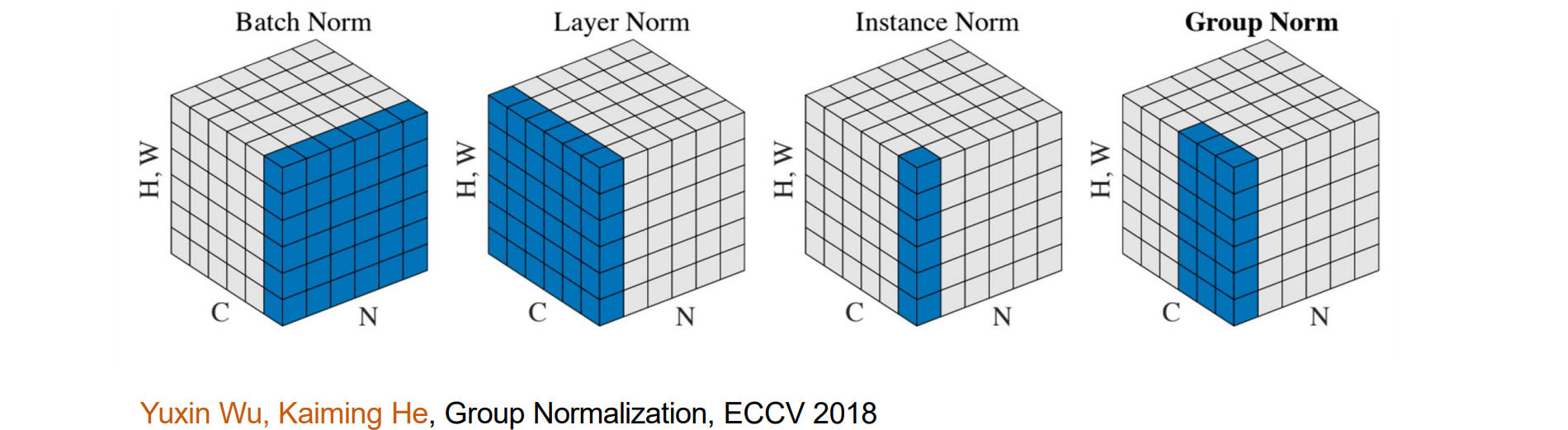
- GN在通道中分组,在每个组中计算均值和方差
Deep Residual Learning
With Batch Normalization and proper initialization, we can train networks with 10+ layers
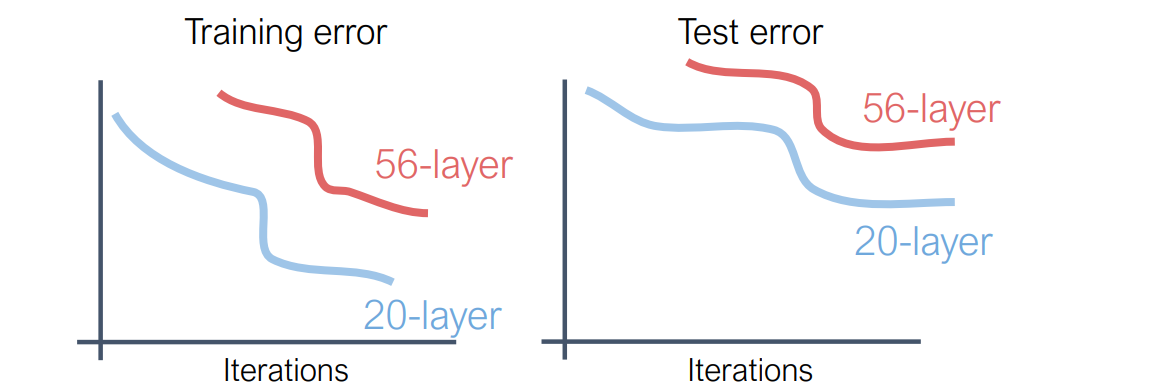
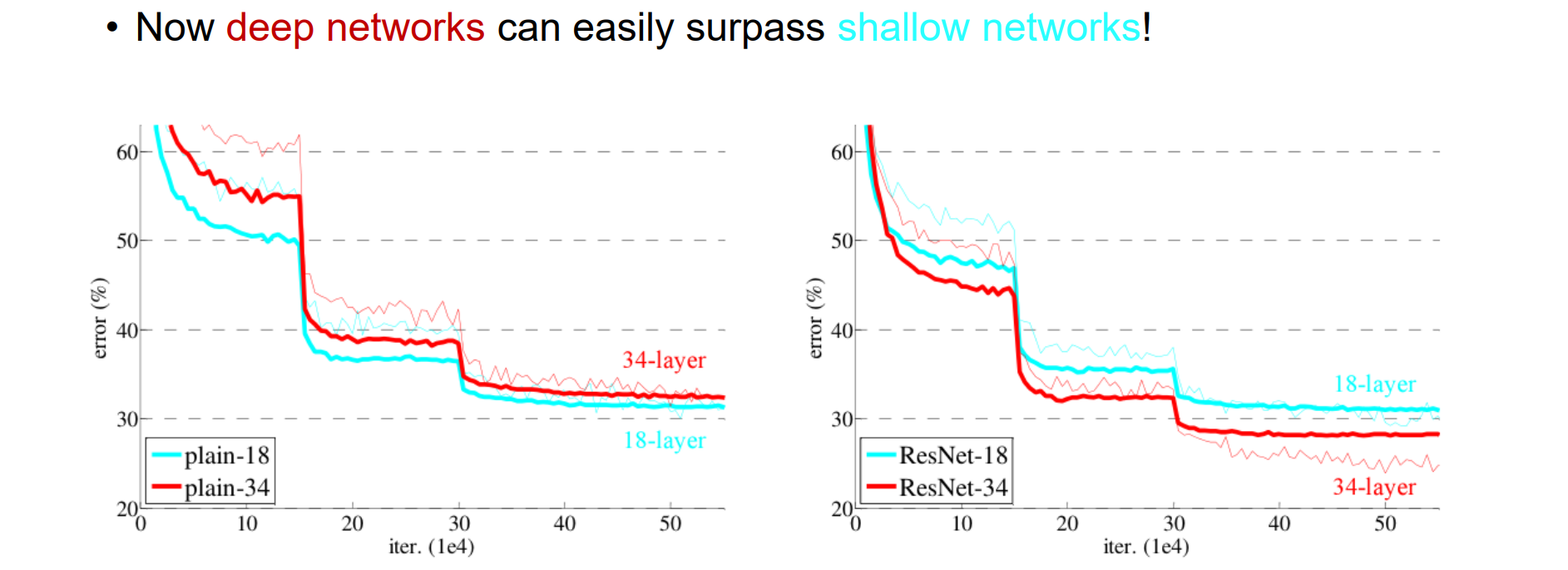
问题:The deeper model does worse than a shallow model
随着神经网络深度的增加,模型的训练误差和测试误差往往会出现先下降后上升的现象,即所谓的“退化问题”。 这并非由于过拟合引起的,因为即使在训练集上,误差也会随着深度的增加而上升。 ResNet(残差网络)通过引入残差连接(shortcut connections)有效地解决了这一问题
Residual Networks
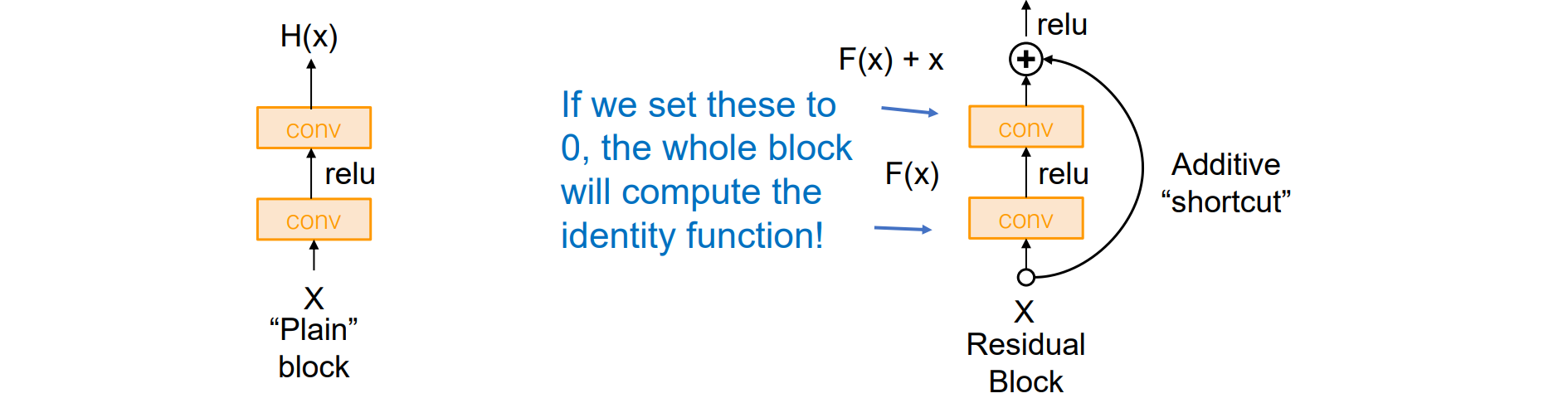
较深的模型可以模拟较浅的模型:从较浅的模型复制层,即f(x)=x映射,设置额外的层作为标识,因此,较深的模型至少应该与较浅的模型一样好
假设:这是一个优化问题。更深的模型更难优化,甚至无法学习恒等函数来模拟浅层模型
解决方案:更改网络,以便学习具有其他额外层的函数
在传统的深度神经网络中,随着层数的增加,网络需要学习一个复杂的映射函数。 然而,直接学习复杂的映射函数可能导致训练困难,甚至性能下降。 ResNet提出了一种新的思路:将目标映射分解为输入与输出之间的“残差”,即:H(x)=F(x)+x
其中,H(x) 是期望的目标映射,F(x) 是需要学习的残差函数,x 是输入。 通过这种方式,网络只需学习输入与输出之间的差异,而非直接学习复杂的映射。 这使得深层网络的训练变得更加容易,避免了退化问题
残差连接通过将输入直接添加到输出,允许梯度在反向传播时直接传递到前面的层,缓解了梯度消失或爆炸的问题
残差网络是许多残差块的堆栈
常规设计如VGG:每个残差块有两个 3x3 卷积
网络分为几个阶段: 每个阶段的第一个块将分辨率减半(使用 stride-2 conv)并将通道数增加一倍
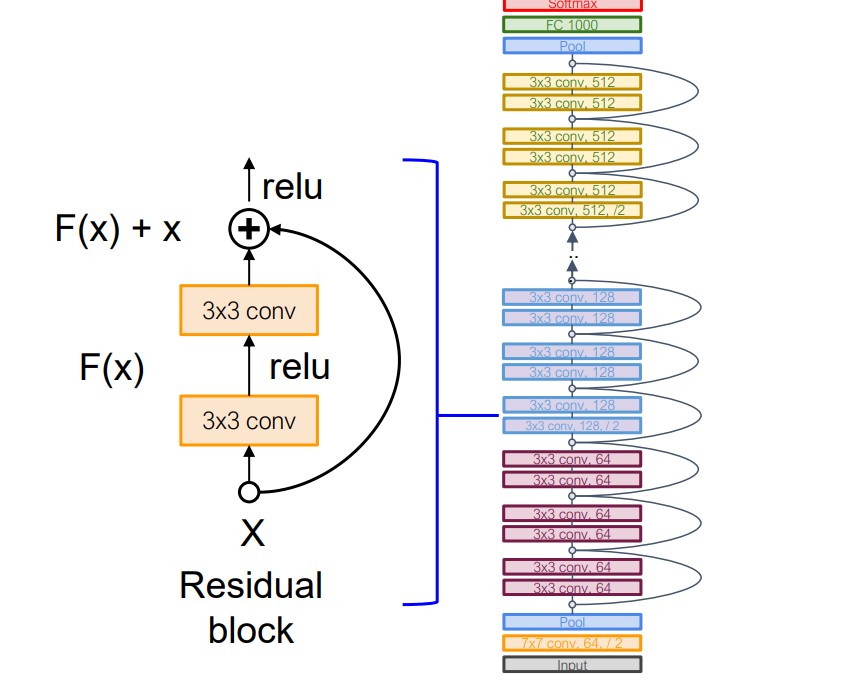
当需要更改第一个块中的通道时,skip 连接可以实现为恒等函数或 1x1 卷积
bottleneck残差块包含的参数较少且较深
Batch Normalization在conv和relu之间应用
- ResNet:
1 | import torch |
Improving ResNet: ResNeXt
FLOPs:浮点数运算次数
分组进行,更加高效
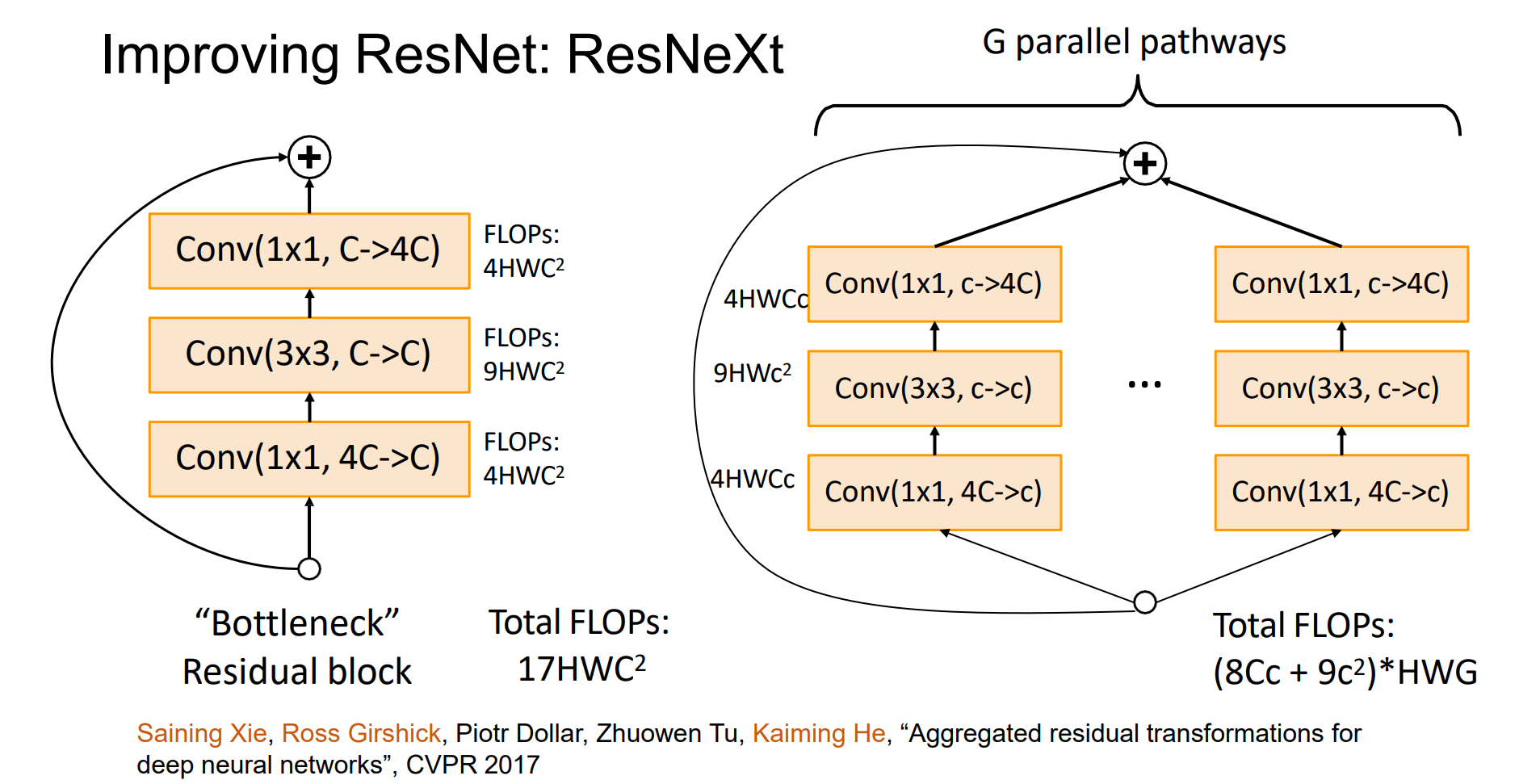
效率可以提高G倍,G是group数
ResNeXt:
1 | import torch |
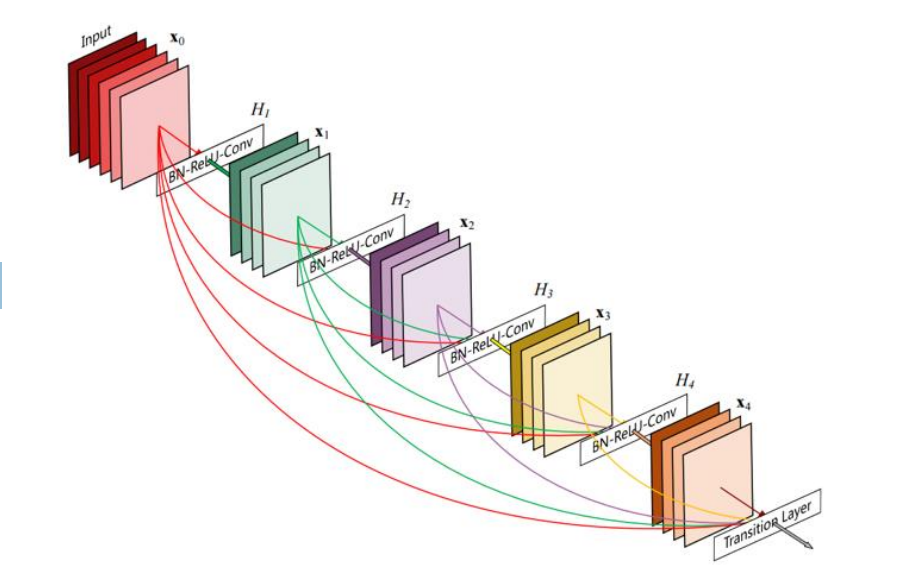
DenseNet
DenseNet 每一层都和后面的所有层相连
对于每个层,所有前面层的特征图被连接起来(ResNet 对特征图求和)并用作输入,它自己的特征图被用作所有后续层的输入,将梯度拼在后面
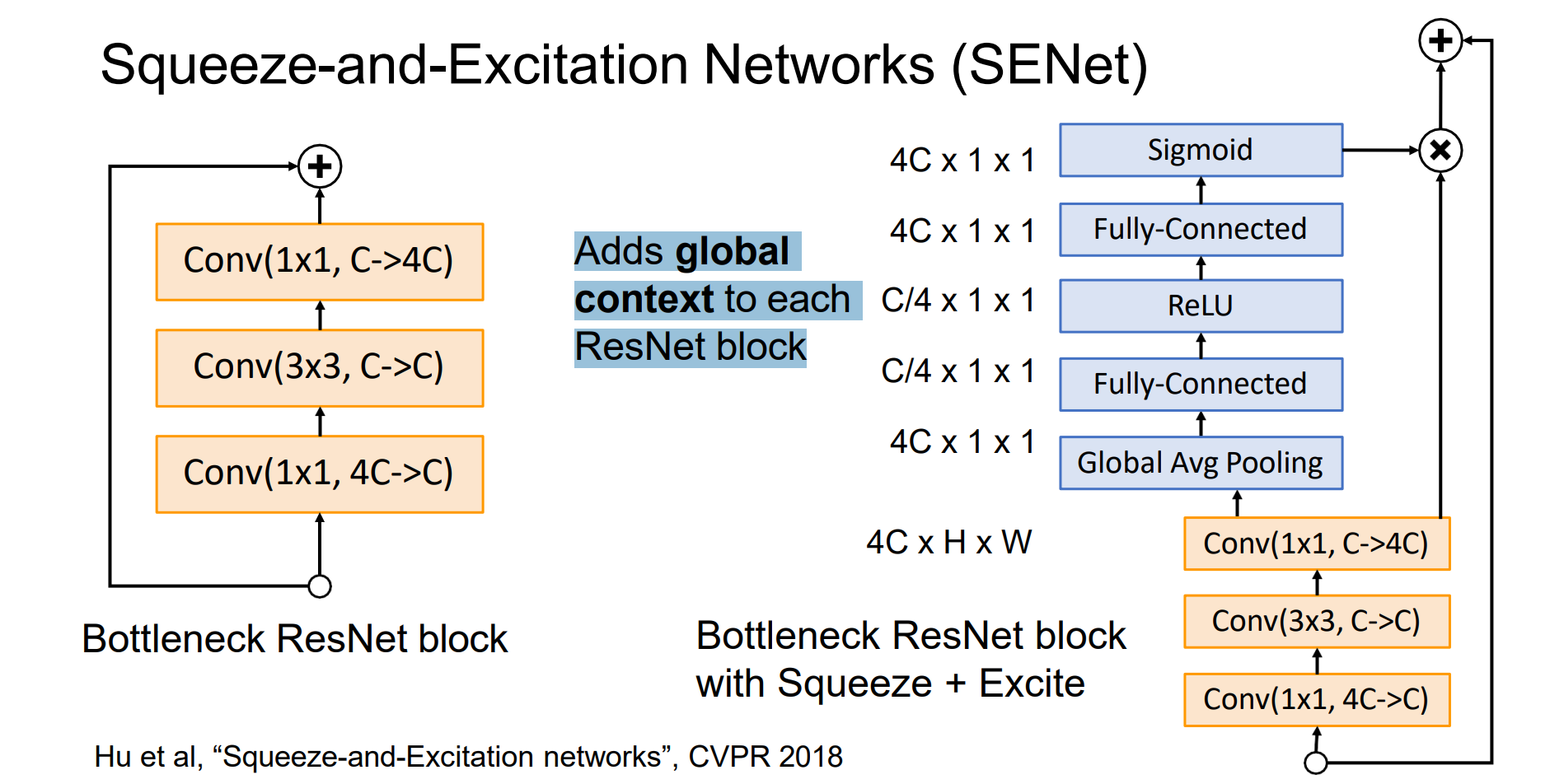
Squeeze-and-Excitation Networks (SENet)
- 调制通道,使得通道对全局的感受能力更强,将全局观念添加到每个 ResNet 块中