计算机视觉 21 Image Segmentation
Computer Vision Tasks: Semantic Segmentation
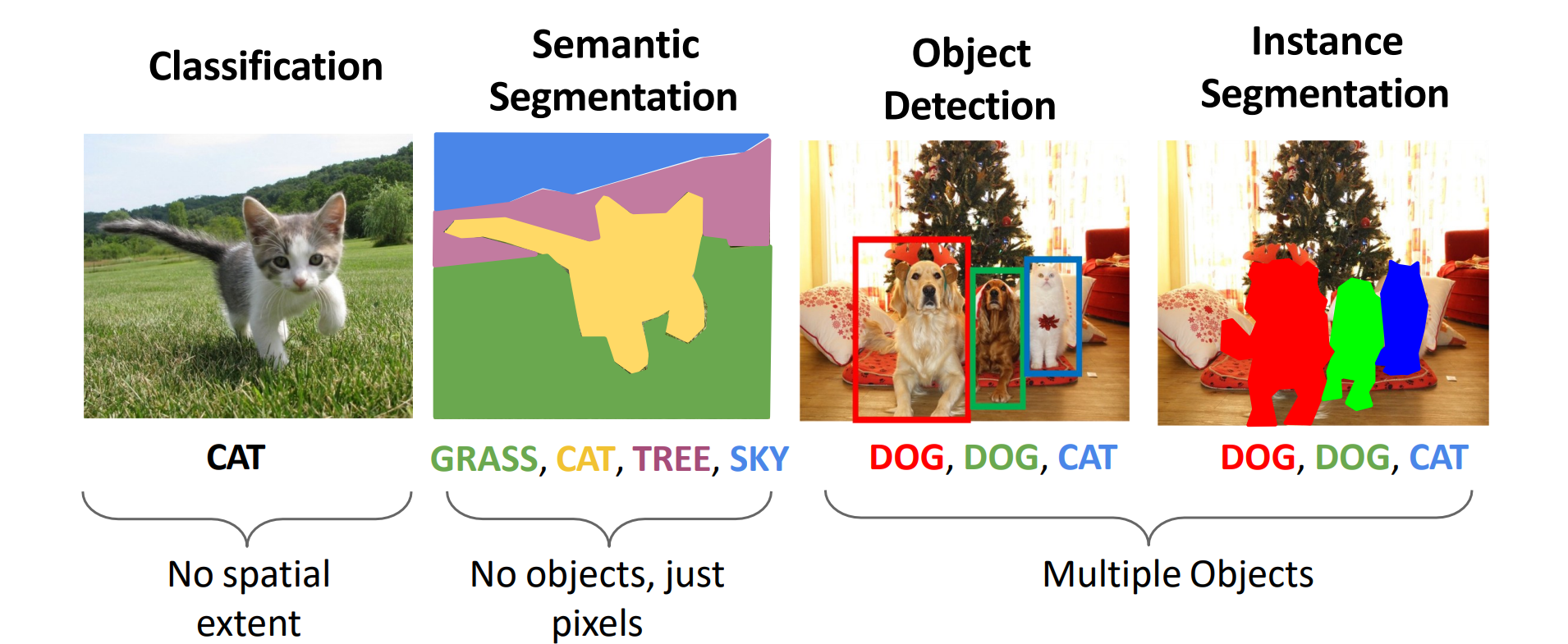
语义分割(semantic segmentation):每个像素分配一个标签
物体检测(object detection):每个物体分配一个包围盒,再给每个包围盒赋予一个标签
实例分割(instance segmentation):物体检测+语义分割
Semantic Segmentation
使用类别标签标记图像中的每个像素,输入:照片;输出:语义
不能区别示例,只能给像素标签分类
Semantic Segmentation: Sliding Window
- 滑动窗口:把窗口中图像块的语义作为中心像素的语义。循环中心像素,为每个像素分类标签
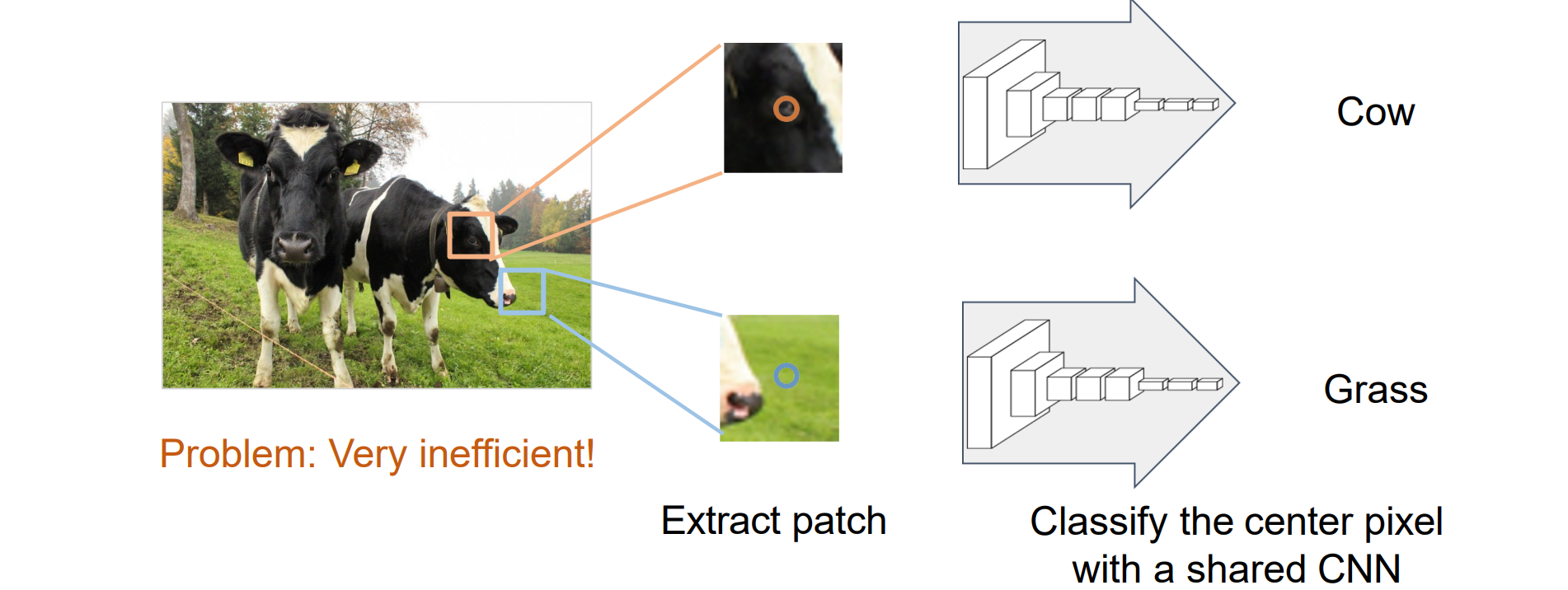
- 缺点不高效,应该使用共享计算,复用计算
FCN
Make a CNN Fully Convolutional
FCN是全连接的CNN
FC(MLP)可以作为特殊的卷积层,可以视为一个大卷积核的卷积层
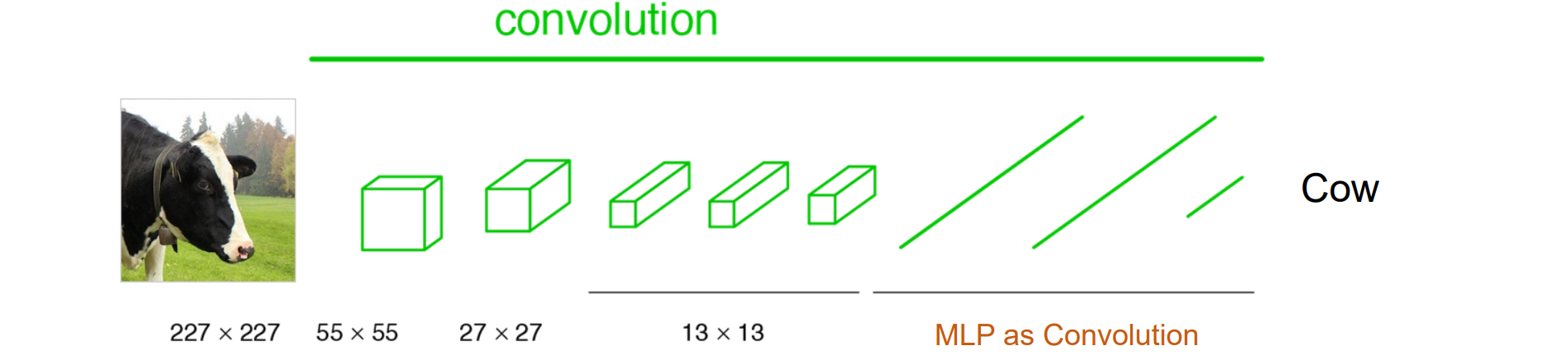
- 最后上采样,形成大的feature map
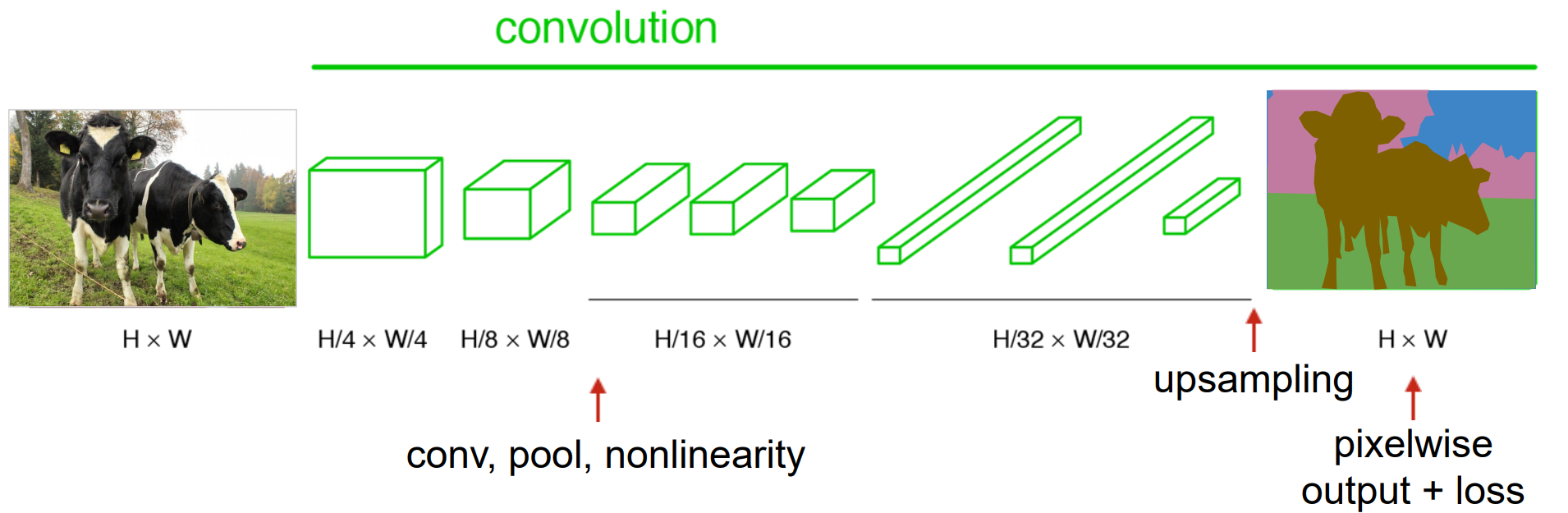
中间的卷积层权重共享,从而更为高效
问题:上采样32倍过大,细节丢失严重
Skip Connections
- 将高分辨率的feature map拼到低分辨率上采样的feature map中,提供精细的位置信息
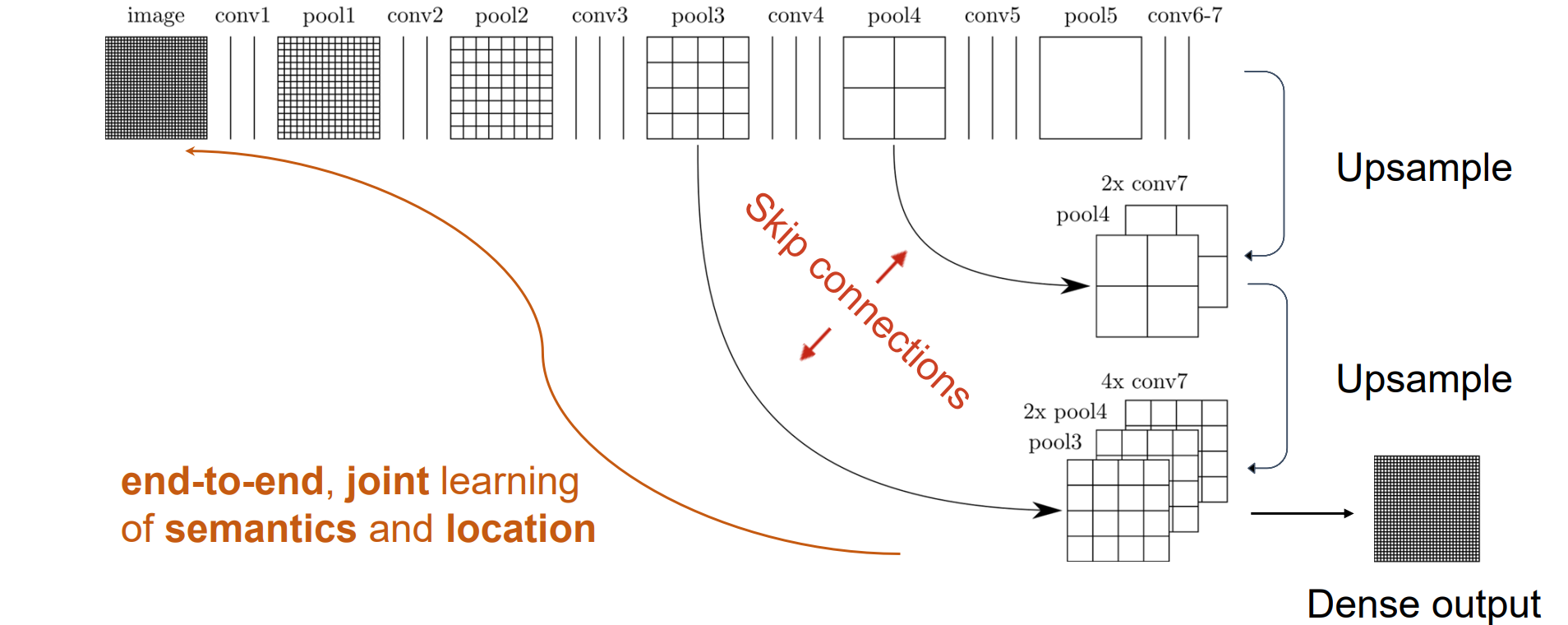
Upsampling
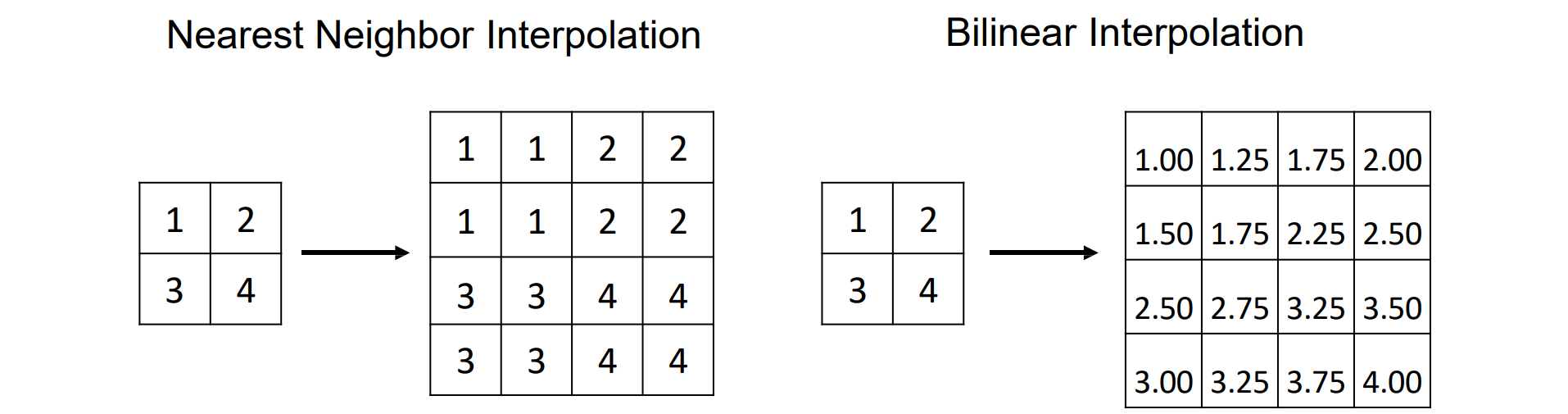
Upsampling with Interpolation
- 常见的上采样插值方法有最近邻插值和线性插值
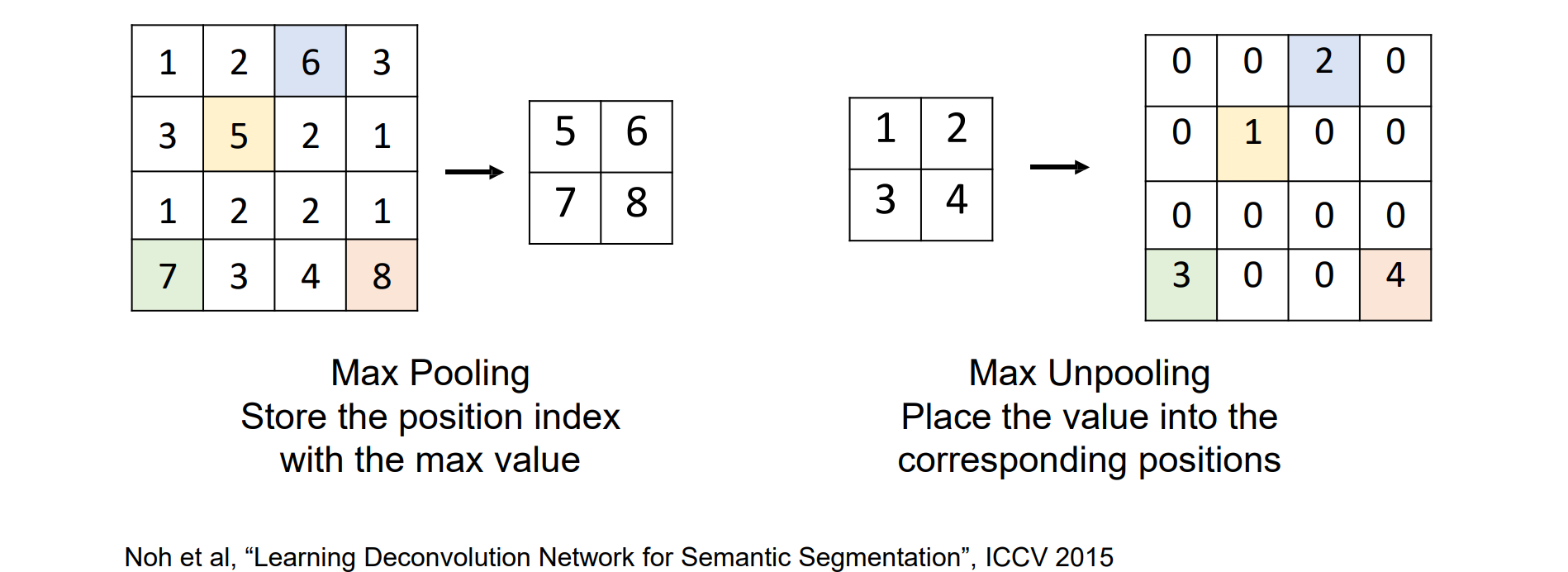
Upsampling with Unpooling
max pooling要存放下标表示最大值的位置
Max Unpooling:max放到对应位置,相当于max pooling的backward
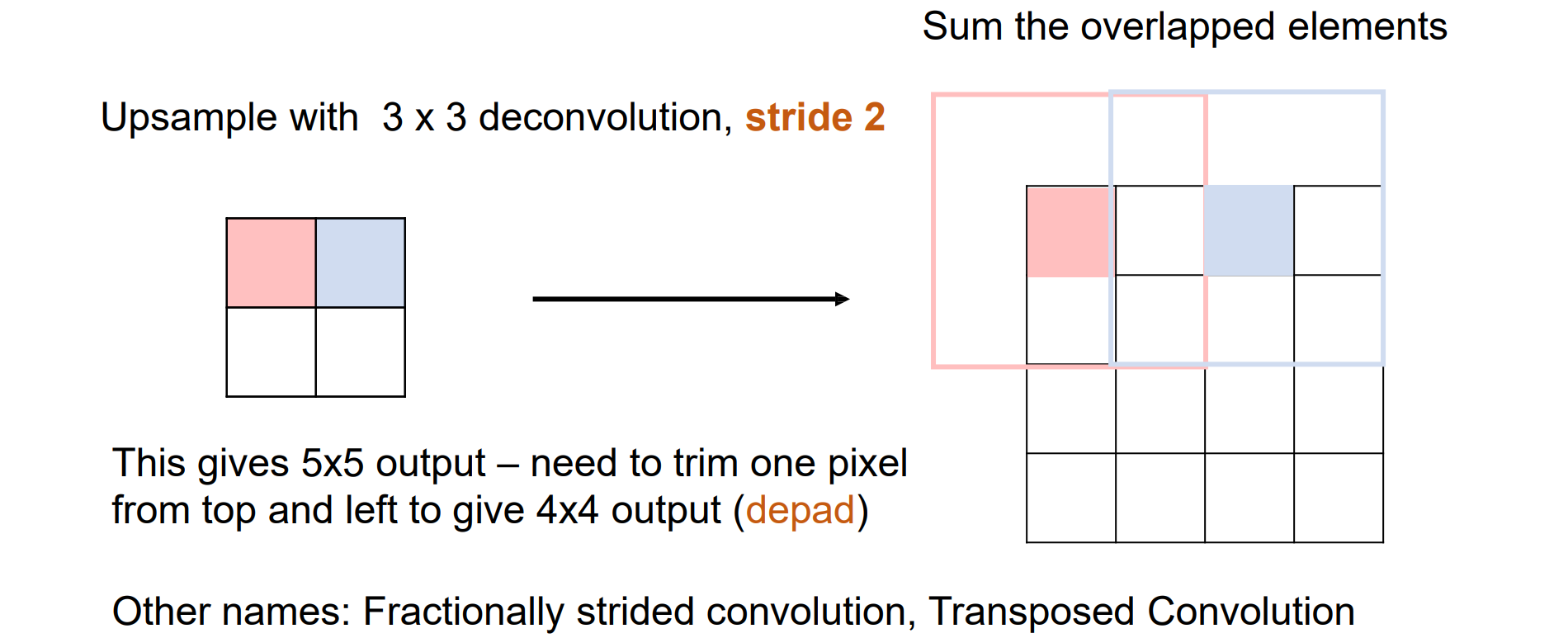
Upsampling with Deconvolution
卷积的逆过程,将1x1像素放大成3x3后,将重叠部分相加而成
边界需要手动进行删除
Semantic Segmentation with U-Net
- U-Net中下采样和上采样是完全对称的
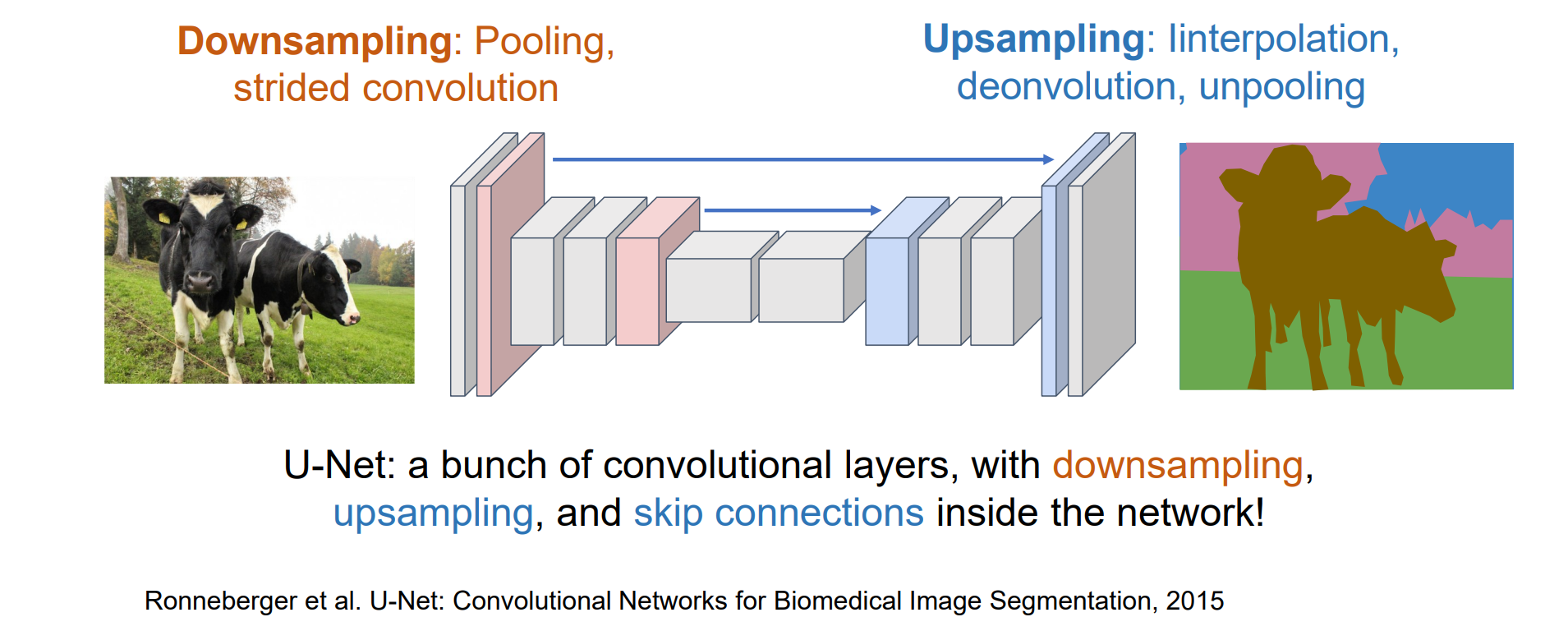
- U-Net适合处理图像输入输出问题:深度图,图像上色,估计光流

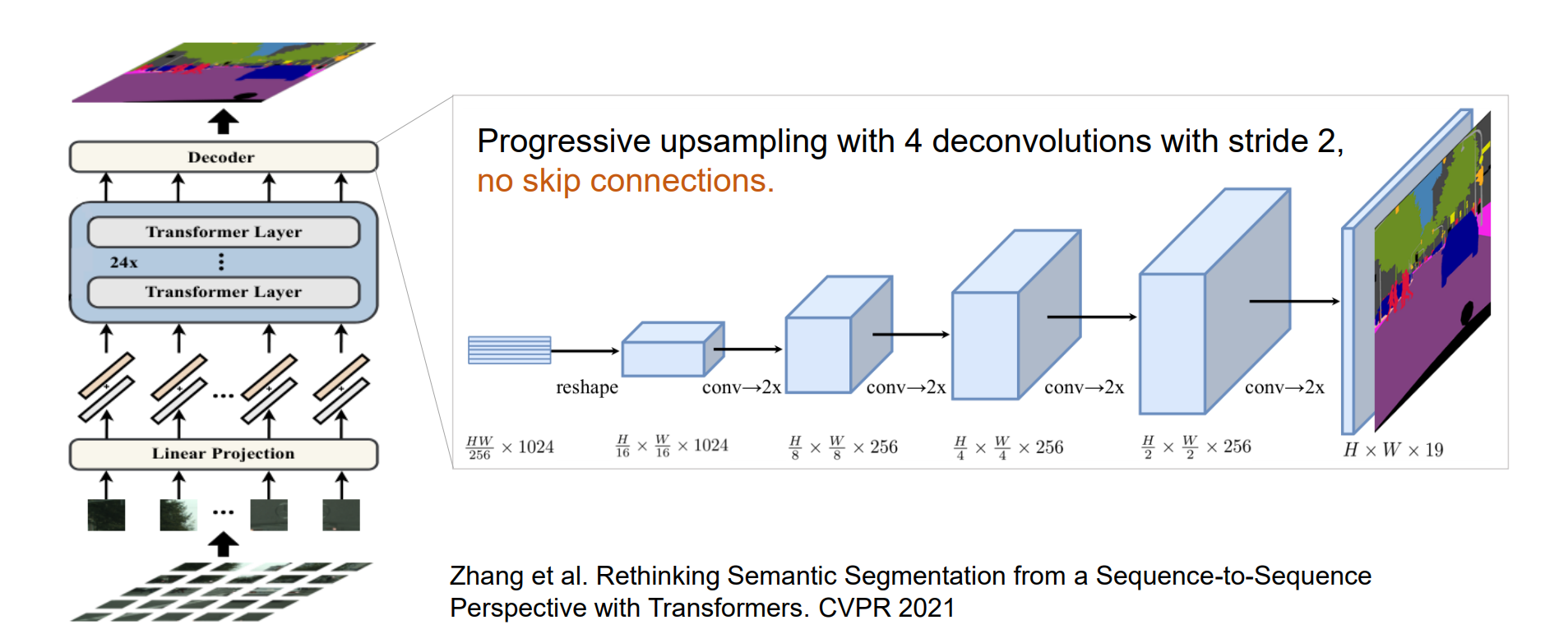
Transformers for Semantic Segmentation
如果encoder足够强大可以不用跳跃连接(skip connection)
缺点:训练集需要比较大