
计算机视觉 14 Optimization
Optimization
Optimization with Grid Search
- 均匀采集样本点,遍历样本点遇到损失值更小的就进行更新
1 | best, bestScore = None, Inf |
优点:简单,只需要评估模型,对函数没有要求
缺点:计算代价高,高维求值困难
Optimization with Random Search
- 随机采样,与问题维度无关
1 | best, bestScore = None, Inf |
优点:简单:只需要评估模型,对函数无要求
缺点:维度高的时候可能因为随机采样点稀疏而错过最优解
When to Use Grid/Random Search
维度低
定义域受限
目标函数难以分析系
Random search与其他策略结合使用时通常更有效,Grid search使系统地测试某些内容变得容易
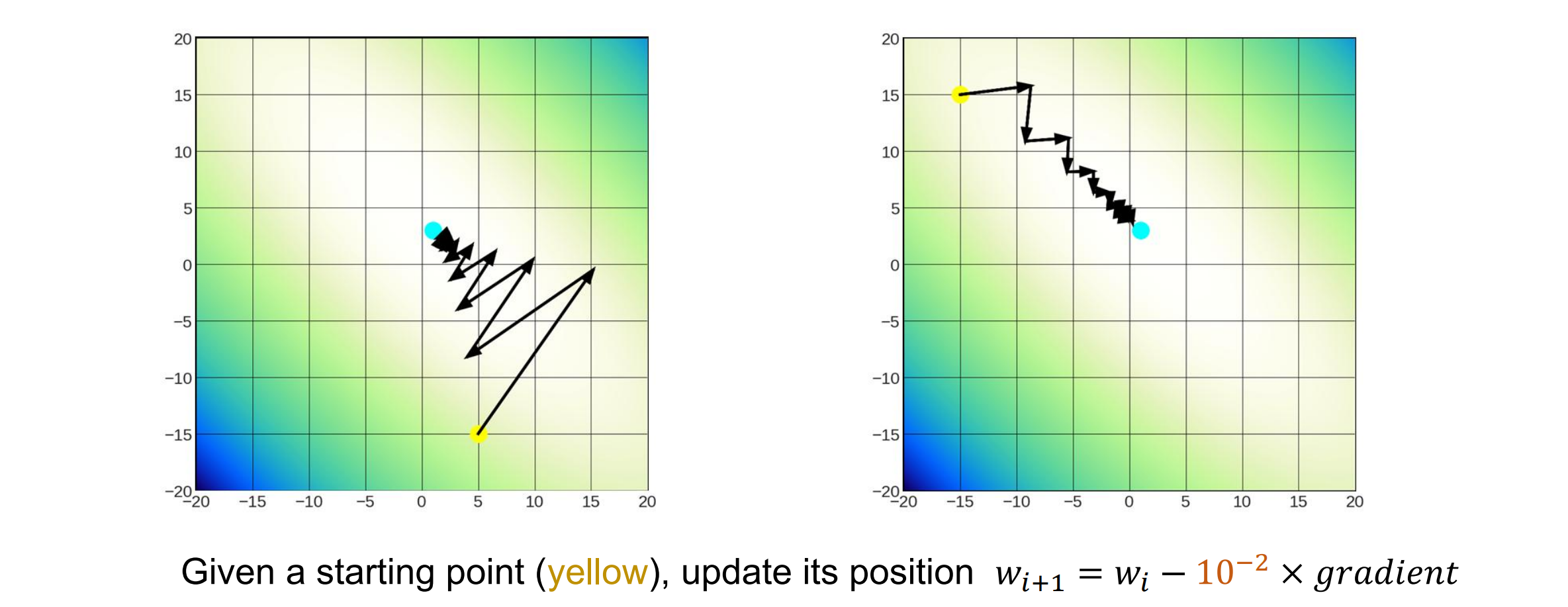
Optimization with Gradient Decent
梯度表示函数最快增长的方向和速率
Gradient Decent:在当前点沿函数的负梯度方向执行重复步骤,以找到函数的(局部)最小值
起始位置随机,不能保证全局最优,只能保证最后的梯度=0,即局部最优
Compute Gradients: Numerical Method(数值方法)
- 使用有限差分来近似导数,一般使用中心差分准确率最高
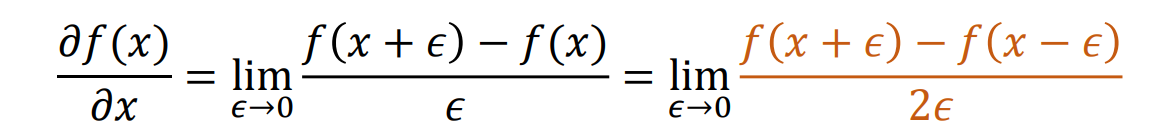

- Numerical gradient: approximate, slow, easy to write
Computing Gradients: Analytic Method(解析法)
- 对于线性回归问题,梯度计算如下:
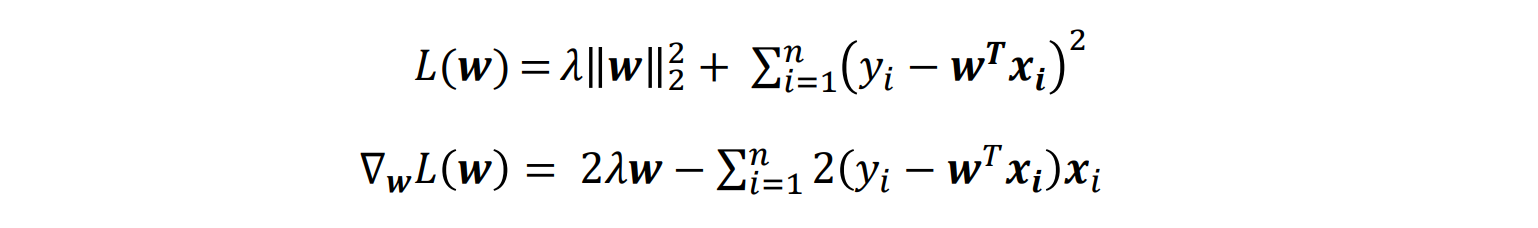
Analytic gradient: exact, fast, error-prone
在使用中通常使用Analytic gradient
Stochastic Gradient Descent: SGD
- 梯度下降的问题:当 N 很大时,计算总和代价很高
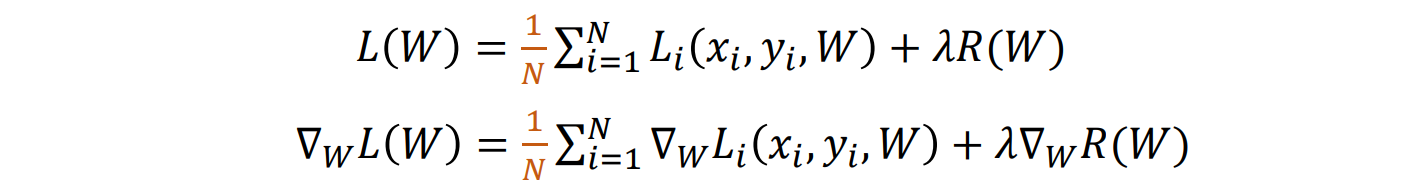
- 解决方法:蒙特卡洛积分,用minibatch来对N进行逼近
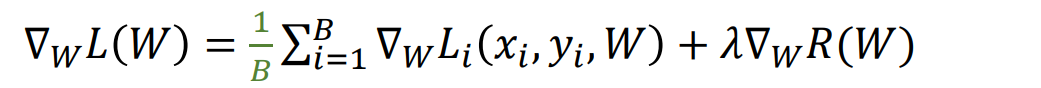
- 超参数:
- 迭代步数
- batch size
- wight初始化
- lr
1 | w = initialize_weights() |
Problems of SGD: #1
- 目标函数在某一方向变化剧烈在另一方向变化很小。条件数差大的时候,梯度抖动很大

- 如果减小step size可以减小梯度抖动,但是更新速度会变慢
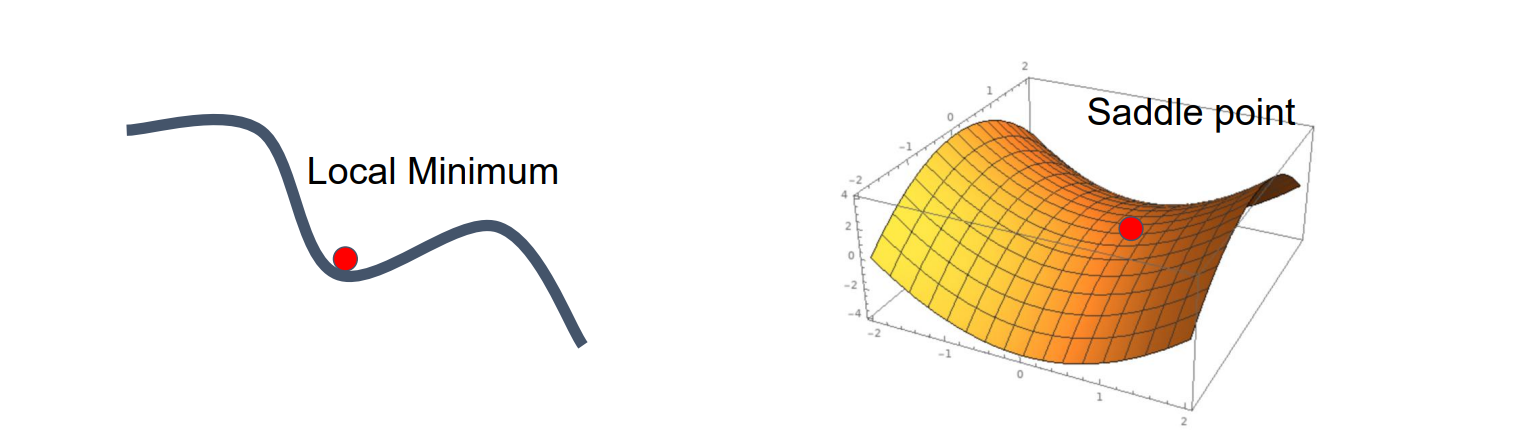
Problems of SGD: #2
- 难以跳脱局部最小值和鞍点
Problems of SGD: #3
- 噪声大,如果batch size << total sample number N
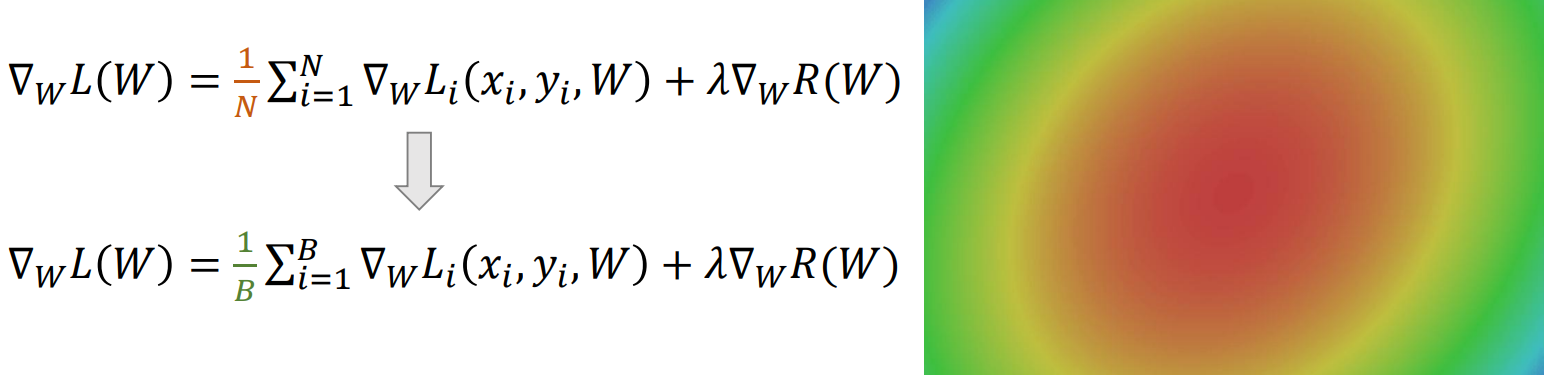
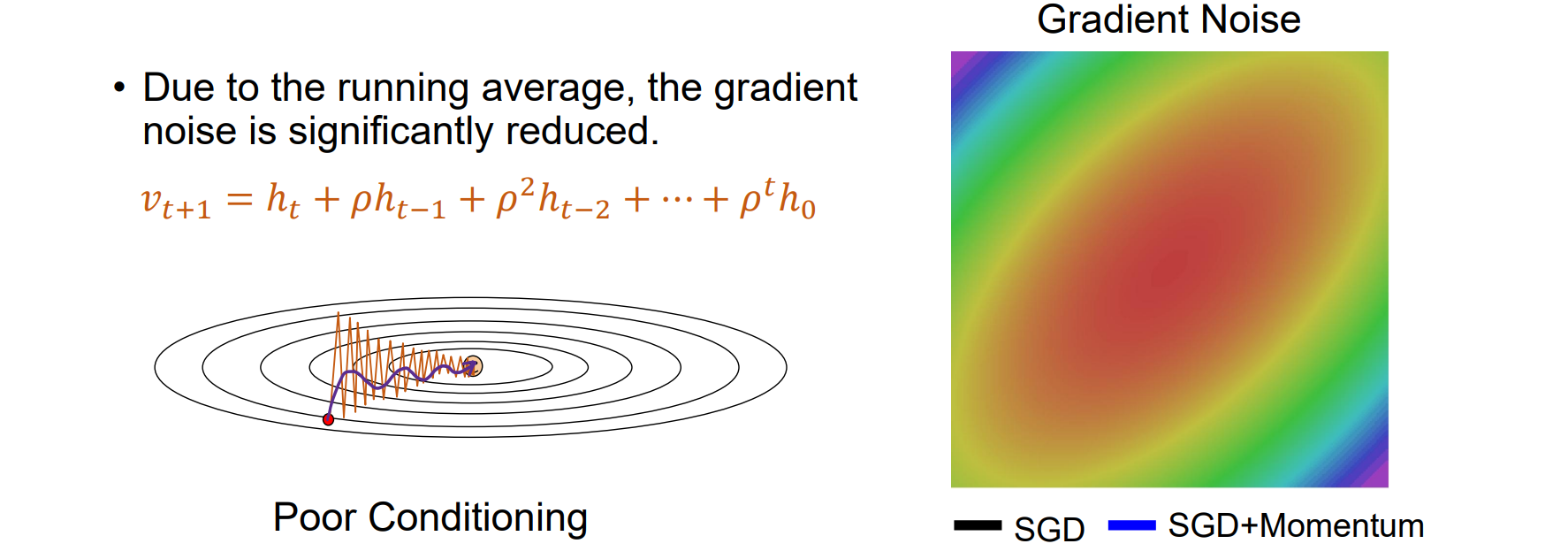
SGD with Momentum
- Key idea: Build up the velocity for loss decent as a running mean of gradients,每一次的更新受到历史因素的影响

- 考虑历史因素在局部最小或者鞍点仍有扰动
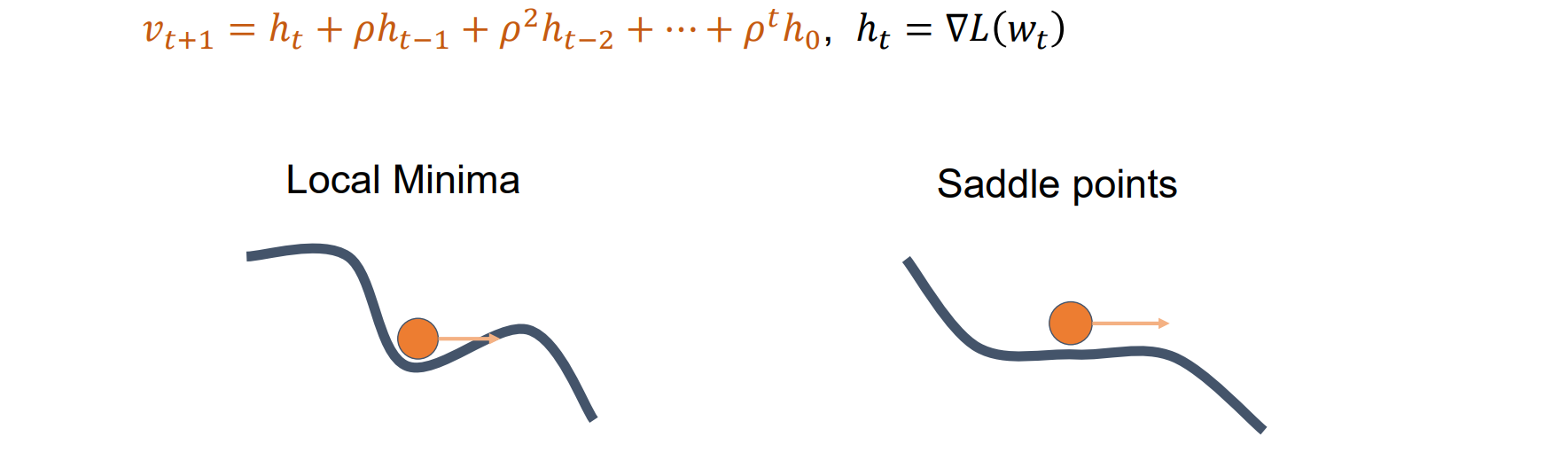
- SGD with Momentum抖动小,收敛更快,噪音低
Nesterov Momentum
- 先按照历史累计的v走一步到A,然后再在A处找梯度下降

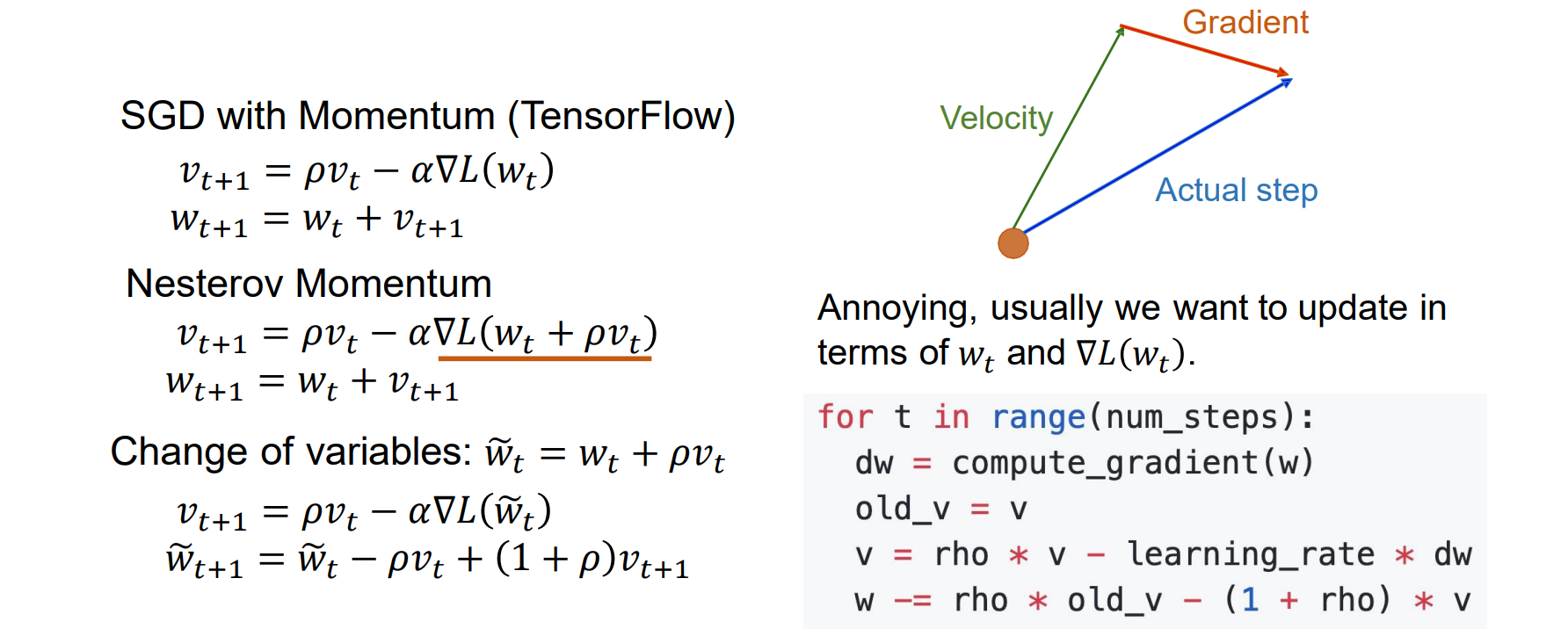
- Nesterov Momentum收敛速度更快,但是当lr太高的时候会导致overshooting
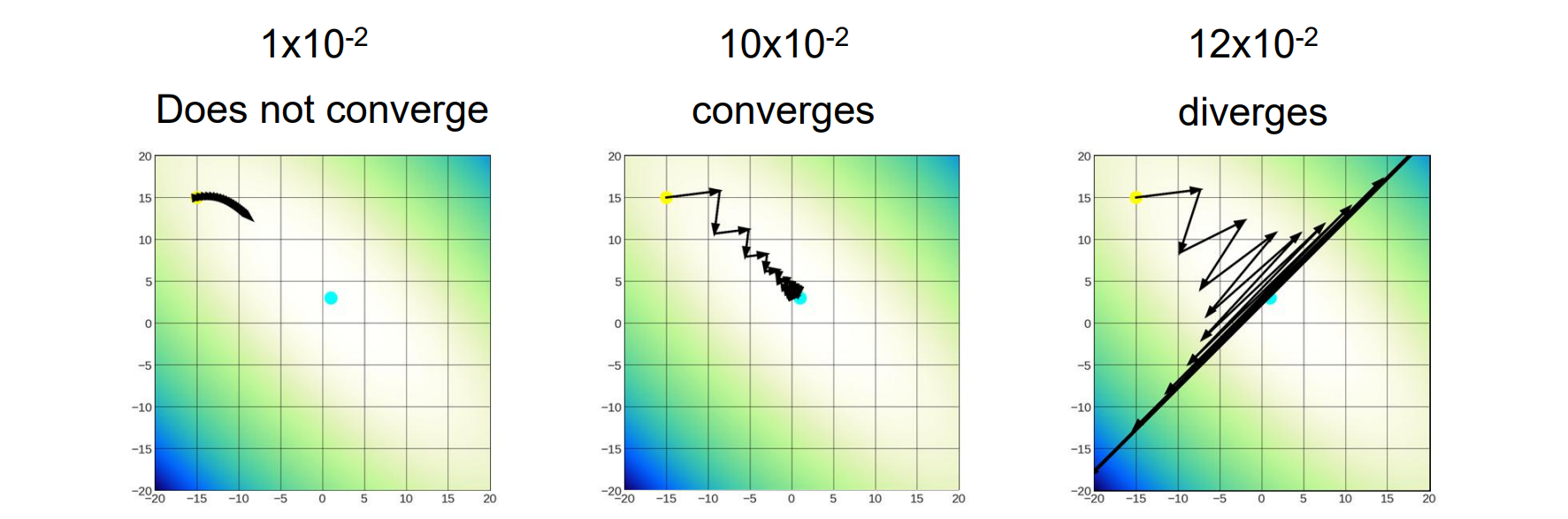
Learning Rate
- lr是一个重要的超参数:
- lr太小会导致更新速度太慢
- lr太大会导致overshooting
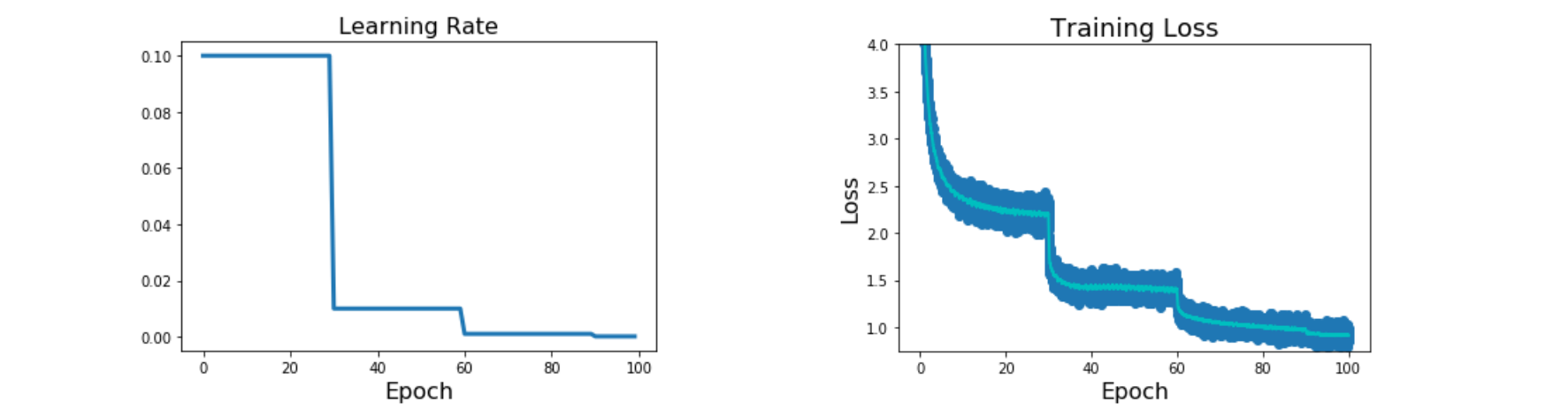
Stepwise Decay
Idea: Start with high learning rate, reduce it over time.Reduce by some factor at fixed iterations
在某个迭代次数后,lr下降
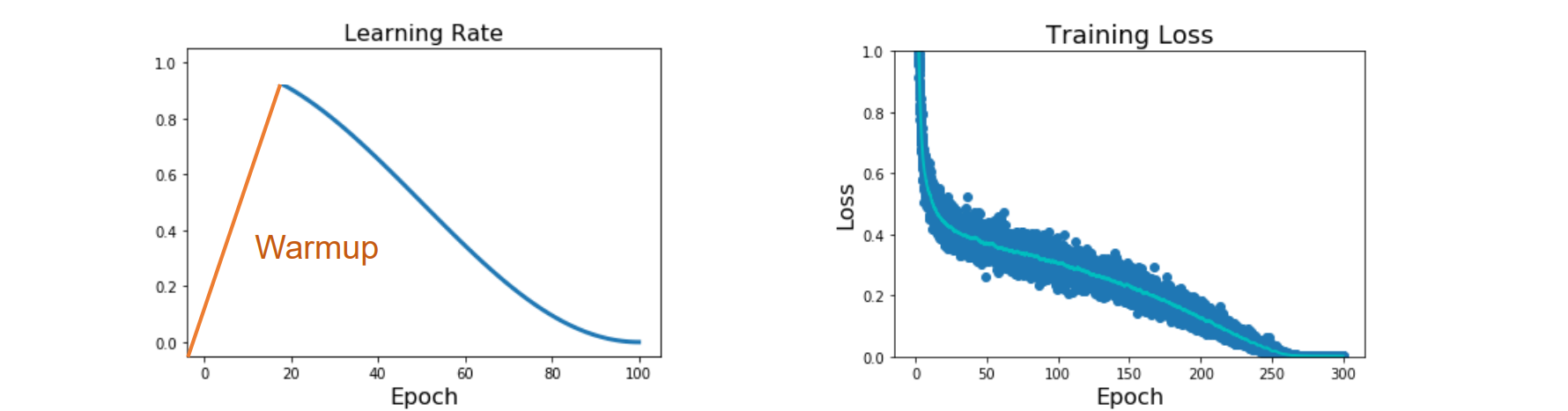
Cosine Decay
- Idea: Start with high learning rate, reduce it over time.reduce the learning rate following:
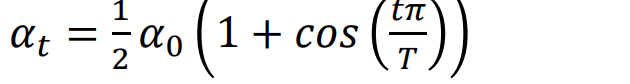
Adaptive Learning Rate Methods
- 稀疏梯度问题:当参数比较多时,很多梯度约等于0,且样本类出现次数不同,可能有的偶尔被激活,应该应用不同的lr
AdaGrad
调整学习率是一个代价很高的过程;因而希望自适应地调整学习率,甚至按参数进行调整
AdaGrad 根据每个维度中的历史平方和添加了梯度的元素缩放,这适用于稀疏梯度
1 | grad_squard = 0 |
- 问题:AdaGrad 积累grad_squared,从而不受限制地不断增长
RMSProp: “Leaky Adagrad”
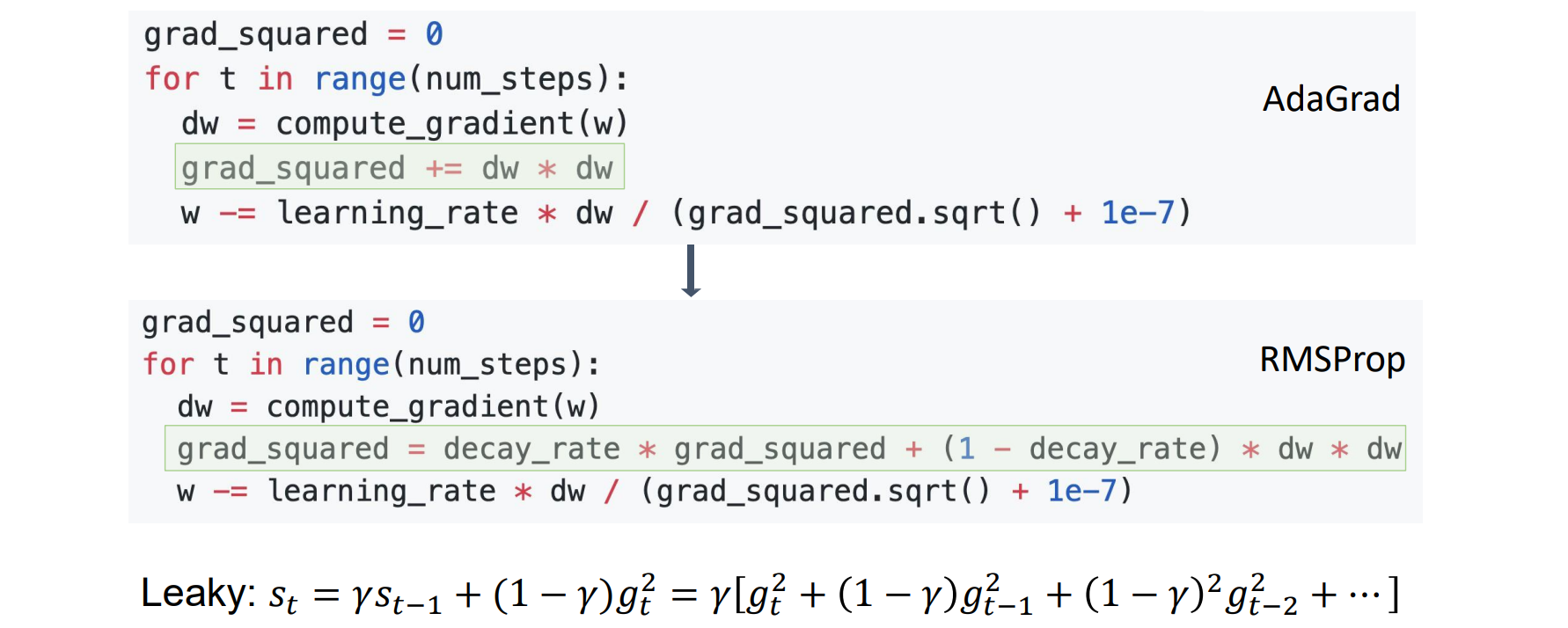
- 梯度归一化,而不是累加梯度,对grad_squared和dw*dw进行加权平均
Adam: RMSProp + Momentum
Adam (Adaptive Momentum) combines the benefits of RMSProp and Momentum
误差校正:用1/(1-β**t)进行校正
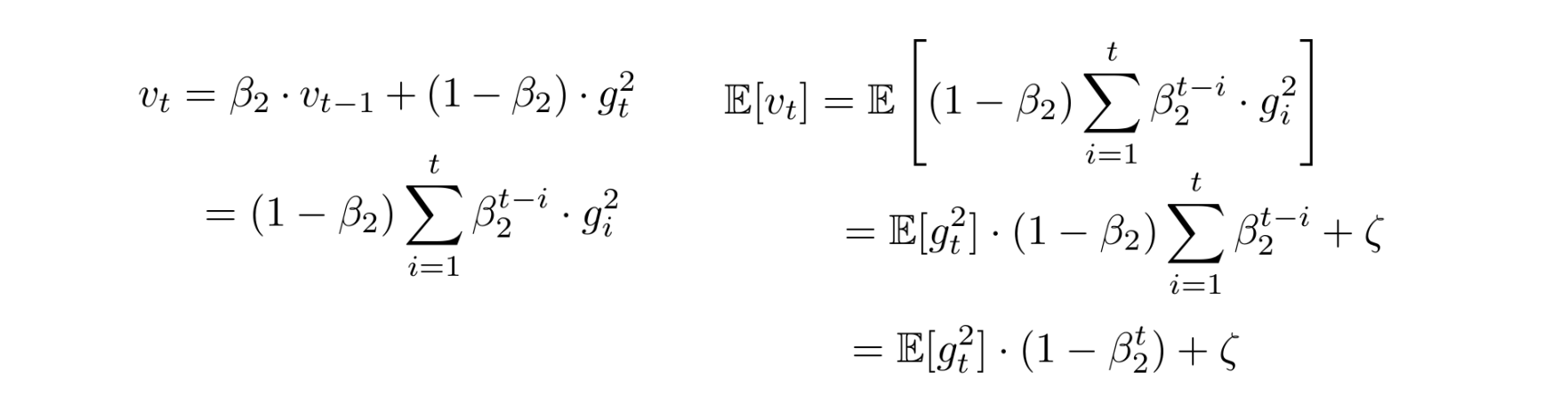
1 | moment1 = 0 |
- L2 Regularization vs Weight Decay:Due to the gradient normalization in Adam, Weight Decay is “canceled”,因此应该显式的加入weight decay



