
生成模型基础 05 Debugging
DebuggingDebug通常是一件比较麻烦的事情
深度神经网络是复杂、不可解释的
超参数极多(模型结构,网络层数、宽度、学习率,batch size,优化器,dropout)
非线性模型,没有优化方法可以收敛到全局最优
如何debug训练问题 —— 训练
说明数据对应的代码和处理任务是正确的,优化器是正确的
迭代输入数值溢出:例如方差为0,经过 layer norm 后造成÷0,溢出
迭代步长过大:例如从一个极小值点跳到了另一个极小值点,且出不来
学习率问题:不同的优化器所要求的学习率不同
如何debug训练问题 —— 测试
模型参数:可以使用LoRA低秩分解可以降低可改变的参数
生成模型基础 04 Autoregressive models
Autoregressive modelsProbabilistic model in high-dimensional space
概率建模,生成模型:希望采样数据分布达到真实数据类似的效果
问题:高维数据
Image:sample出image = 给定image的概率为sample出每个像素概率 = 给定image概率的联合概率
Sentence:sample出句子的概率 = 给定句子的概率等于sample出每个词的概率 = 给定每个词的联合概率
General setting
高维数据可以由一个高位向量表示:Data 𝑥 = (𝑥1,𝑥2,…,𝑥𝑑):
Image:d表示image的大小(pixel x pixel),xi代表每个pixel的三通道RGB值
Language:d表示句子长度,xi表示对应位置的每个词
目标:model 𝑃(𝑋 = 𝑥) -> 联合概率分布:𝑃(𝑋1 = 𝑥1,…,𝑋𝑑 = 𝑥𝑑)
可以通过条件概率的chain ...
生成模型基础 03 Transformer Model
Transformer ModelTransformer componentsChallenging language understanding(NLP 问题)
Long term dependency:
e.g.指代消岐:我的书柜太宽了,而且非常重,我没有办法把它搬出书房,“它”的指代是?
解决方法:Attention
Sophisticated meaning:
e.g. 多重否定:我原以为这部电影挺无聊的,没想到还不错,“原以为”,“无聊”,“没”,“还不错”
解决方法:Feed Forward network
Word order matters a lot:
e.g. 词语顺序敏感:屡败屡战,屡战屡败
解决方法:Position encoding
Key module: attention layer for long-term interaction
假设词有独立含义,可以用有语义信息的向量表示(本质上是word embedding)
Attention的作用:已知词含义,求每个词在上下文关联中的含义
输入:n个词向量,输出:n个基于上下文理解 ...

智能机器人概论 07 运动控制
运动控制 Motion Control基本概念
开环控制–Open-Loop Control
闭环控制–Close-Loop Control,也称为反馈控制(Feed-back Control)
运动控制方法分类:
黑箱控制Black-box Control:PID Control
几何控制Geometric Control:Pure Pursuit Control
优化控制Optimal Control:MPC Control
基于学习的控制Learning-based Control:End-to-end Control
黑箱控制 Black-box Control– PID Control
u(t) 是控制量,e(t) 是误差,积分项是过去误差的累积,微分项是误差变化的趋势
问题:需要微调Kp、Ki、Kd
P控制–比例(Proportion)
比例控制局限性:u低于机器人驱动敏感区间的下界є后,机器人与目标保持et而不可达。误差小的时候不敏感
解决方法:加入误差累积,使得e(t)累积进入敏感状态
PI控制–积分(Integration)
积 ...
智能机器人概论 05 激光雷达
激光雷达LiDAR – Light Detection and Ranging2D LiDAR
2D LiDAR基本原理:(红色)激光打到 mirror 反射至物体后,(蓝色)激光经过 mirror 返回,计算时间差
3D LiDAR
3D LiDAR’s Needs:无人驾驶技术
测距原理:ToF
Mechanical Spinning LiDAR
局限性:
点分辨率受限于阵列上的激光器
激光器阵列的校准在大规模生产中面临困难
系统设计与维护存在挑战
智能机器人概论 04 惯性传感器
惯性传感器惯性传感器Inertial Sensors
陀螺仪Gyro:测量角运动(角速度)
加速度计Accelerometer:测量线加速度
磁力计Compass:测量磁场方位
惯性导航系统INS/惯性测量单元IMU:组合惯性传感器,测量载体的位姿
应用:动捕系统,视觉动捕系统在运动幅度过大时不再适用,而惯性运动捕捉系统则可以根据惯性恢复动作(假设刚体)
惯性传感器的问题:测量加速度和力时,每帧误差累积,时间长误差累计高
陀螺仪(Gyroscope/Gyro)
陀螺仪:测量角运动(角速度)的惯性传感器,用于精密测量的陀螺仪,精度是他的一项重要性能指标
陀螺仪累计误差:角速度测量值,经积分得到角度变化,与真实值的差为累计误差
陀螺漂移Gyro drift:累计误差随时间而增大,称为陀螺漂移
漂移率ε(单位:度/小时):每小时的积累误差
主要误差来源:
干扰力矩,引起陀螺仪漂移误差的有害力矩
干扰力矩越大,陀螺仪的精度越低
在精度不高的转子式陀螺仪中,主要干扰力矩来自框架轴承内的摩擦力矩,及由陀螺仪中心与框架中心不重合和陀螺马 ...
智能机器人概论 03 运动传感器与位姿估计
运动传感器与位姿估计里程编码器(测量距离)
基本原理:记录刻度数,测量转角(转动端相对于固定端的转角),转换为弧长(≈行驶里程)
实质测量的是转角
里程编码器误差:里程编码器测量的里程≠真实里程。本质上是轮子(装有里程编码器)里程≠车的里程
e.g.:一个轮子气多,一个轮子气少;地面凹凸不平;光滑地面/沙地
测量车轮行驶里程的里程编码器又称车轮编码器Wheel Encoder
编码器数据
数据文件:COMPort_X_20130903_195003.txt
格式(文本):E Millisecond 1 Count
Count:累计计数,[1,30000]
单位计数对应的里程数:1 Count ≈ 0.003846154 meter
数据有跳跃是因为测量帧率不够高
惯性传感器
陀螺仪、加速度计、惯性测量单元(Inertial Measurement Unit, IMU)
见 04 惯性传感器
位姿估计
利用运动传感器和运动模型,可以对机器人的位置姿态进行估计
里程计法(Odometry):
利用轮速编码器等传感器和运动学 ...
智能机器人概论 02 机器人传感器
机器人传感器系统传感器与执行机构
输入:传感器
内部传感器、内部执行器:保证机器人的稳定运行
外部传感器、外部执行器:决定了机器人的功能、类型及规划控制方法
内部传感器:感知机器人自身状态,典型的内部传感器有编码器、IMU、电流传感器、力/扭矩传感器等等
外部传感器:感知外部环境与环境的交互,典型的外部传感器有摄像头、LiDAR、麦克风、超声波
内部传感器
内部传感器:感知“自我”,回答机器人自己处于什么状态、位置、方向、…
外部传感器
外部传感器:感知“世界”,回答机器人周围的环境是什么样的
基于功能的传感器分类
传感器基于功能可以分成三类:感知环境你、感知本体、感知交互
传感器原理介绍
内部传感器(感知本体):运动及位姿估计
编码器(关节\轮位移)
惯性传感器(加速度计、陀螺仪)、惯性测量单元IMU
外部传感器(感知环境):环境感知建模
视觉传感器:2D相机、RGB-D
距离传感器:激光雷达、毫米波雷达
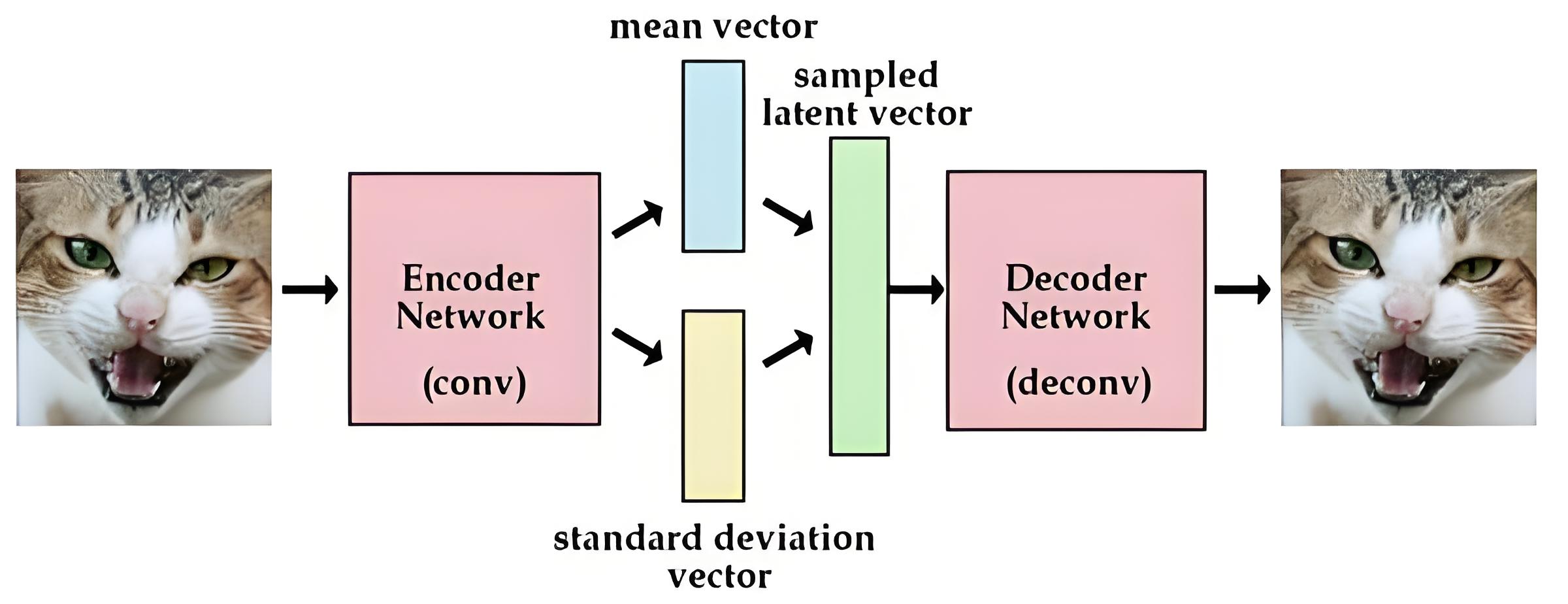
生成模型基础 02 Autoencoders
AutoencodersBasicsWhat is autoencoder?
autoencoder 是一种前馈神经网络,其功能是接收输入x并预测x
存在 Trivial (short-cut) solutions:神经网络可以学会恒等映射 𝑥 = 𝑓(𝑥),即输入为x,经过中间的神经网络后,输出也为x
Bottleneck architecture:
使用bottle neck结构:防止过拟合
可以分为encoder(编码、降维、提取特征)和decoder(解码、复原重构x)
Why autoencoder?
将高维数据映射至二维空间以实现可视化
数据压缩(降低通信成本)
无监督学习(预训练),通过加入扰动再去噪
生成模型,生成image
The simplest autoencoder(线性autoencoder)
最简结构的autoencoder包含单个具有linear activations的hidden layer
encoder通过线性投影到更小的空间,而decoder则通过线性投影还原到原来的维度,均为线性变化
...
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick StartCreate a new post1$ hexo new "My New Post"
More info: Writing
Run server1$ hexo server
More info: Server
Generate static files1$ hexo generate
More info: Generating
Deploy to remote sites1$ hexo deploy
More info: Deployment
