
计算机视觉 17 Convolutional Networks1
Convolutional Neural Networks
Review: Multilayer Perceptions
MLP的层被称为全连接层,层与层之间通过激活函数相连
MLP的第一步是将图像拉成长向量
缺点:没有遵从像素间的关系,没有利用邻域之间关系
Three Important Priors in Vision
- 平移不变性:左右平移,语义内容保持不变,feature map跟着平移。显然MLP因为拉成长向量,平移后的长向量运算完可能输出不同,因而MLP不具备平移不变性

- 局部性:局部+权重共享的参数量少,而MLP作为全连接层有全局的感受野,参数量非常大
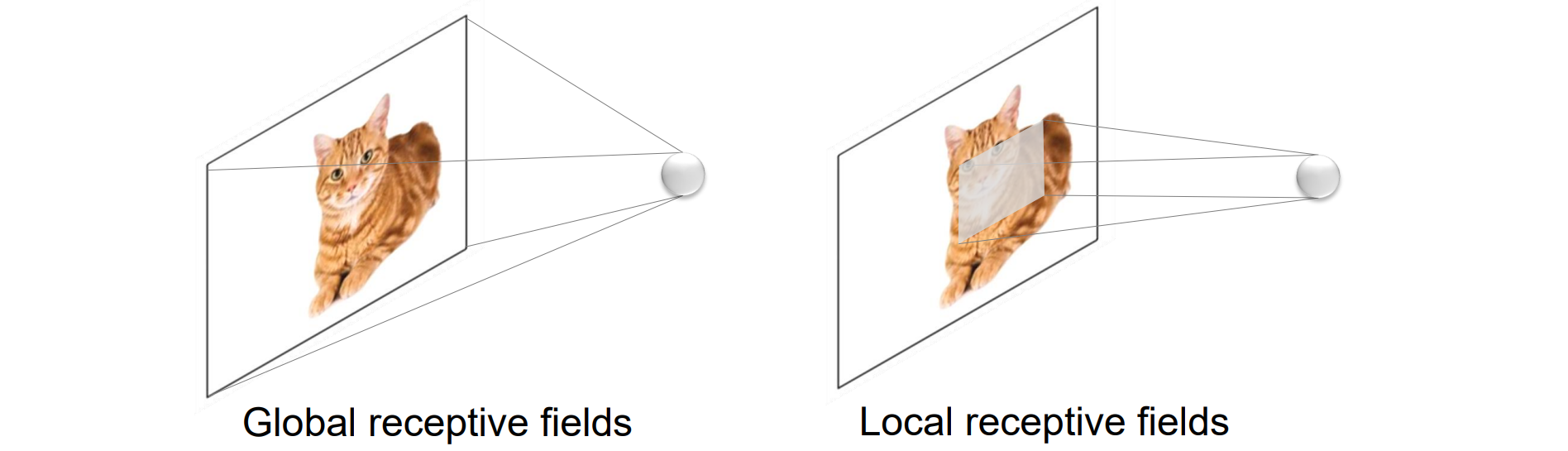
- 尺度不变性:尺度改变,语义内容不变;尺度改变会形成层级结构,逐步增加感受野,形成特征金字塔

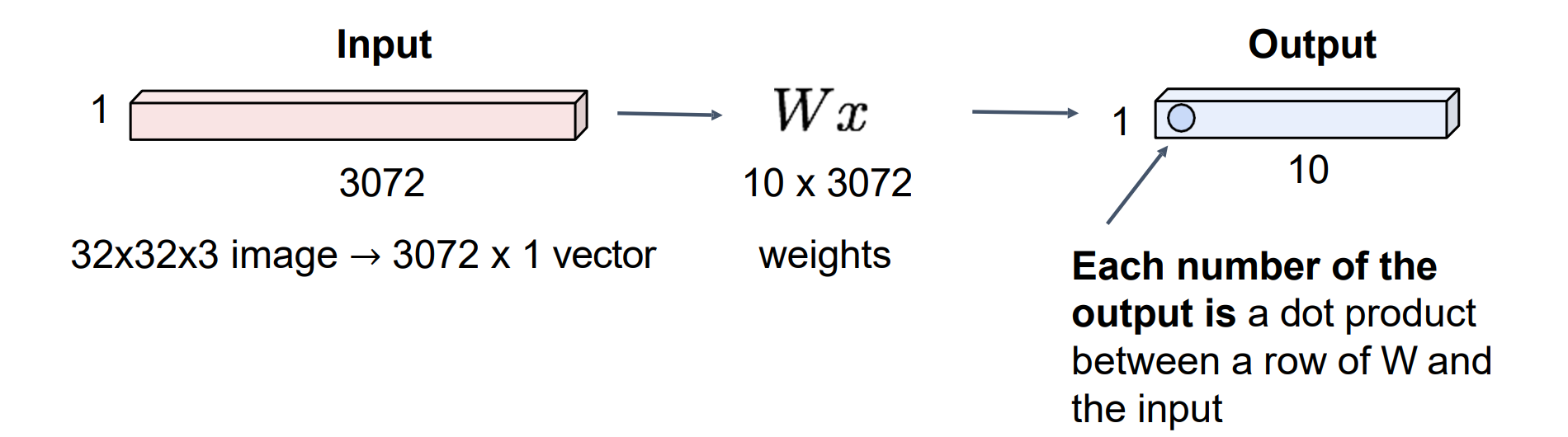
Convolution Layer
- 全连接层输出是weight和x矩阵的点乘结果:
- 卷积层则具有局部性,和局部对应的可以训练的weight(称为kernel)进行点乘,然后让kernel划过每个位置进行运算
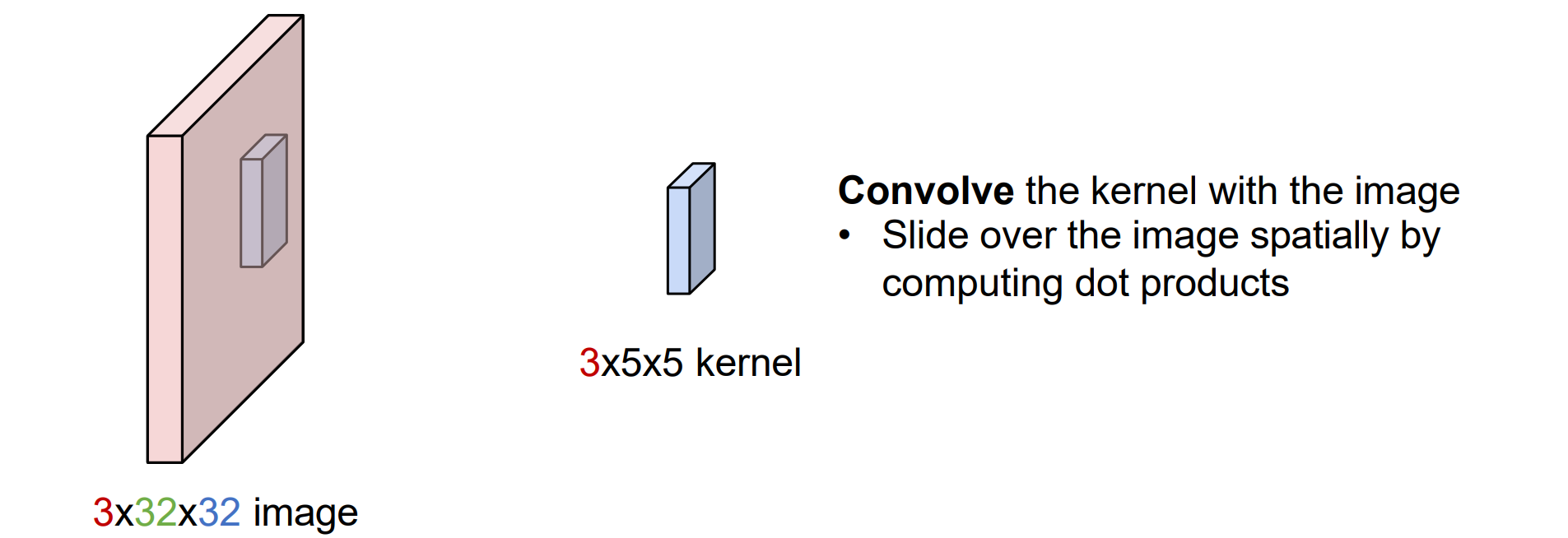
- 卷积层可以理解为局部的权重共享的MLP,因而具有平移不变性(权重不变)
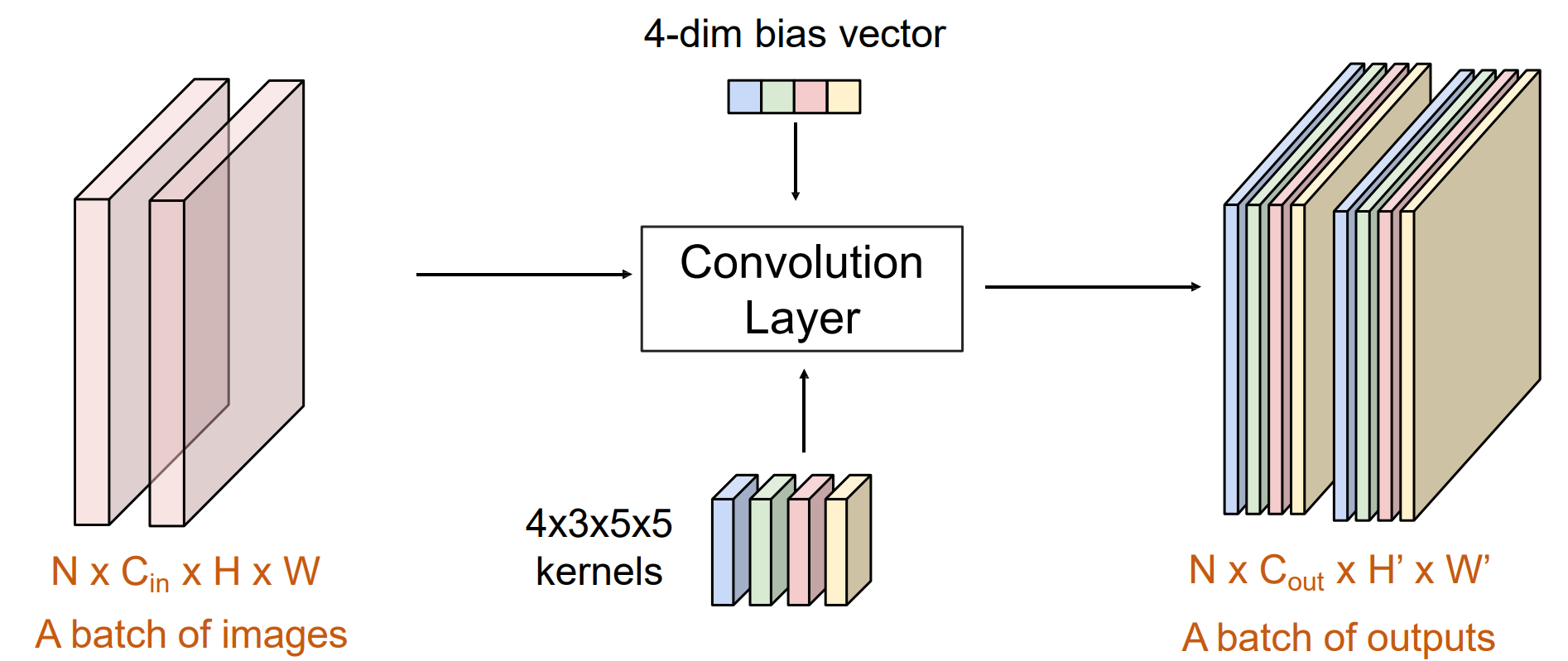
kernel的参数为:输出通道;输入通道;kernel的长;kernel的宽
N是batch_size
偏置bias的通道数和卷积层的输出通道数相同
Convolution Layer: Boundary Effects
- kernel到边界时,可能延伸到边界外,称为边界问题,处理方法:
- 忽略:会导致图像尺寸变化
- 补0
- 周期:顶行环绕到底行;最左边的列换行到最右边的列
- 反射:通过在边缘上反射在本地复制行/列

Stacking Convolutions
- 在卷积层间需要加入激活函数,卷积操作仍然可以理解为不同权重的线性操作,需要激活函数提供非线性性
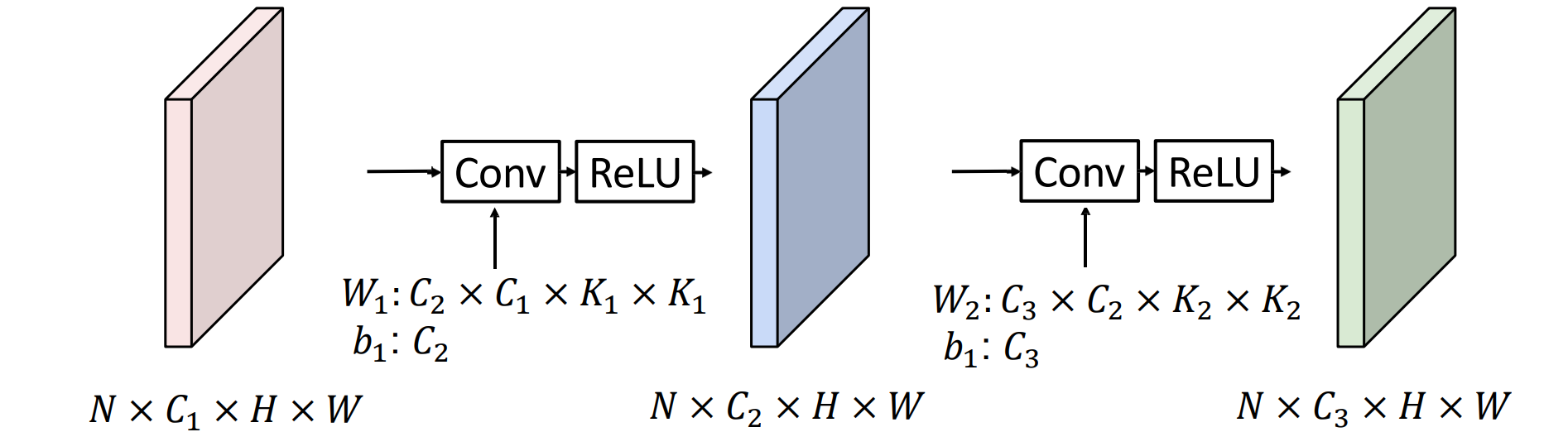
Receptive Fields
- 感受野的范围:每个连续的卷积都会将 K – 1 添加到感受野大小中,对于 L 层,感受野大小为 1 + L * (K – 1)
有限感受野:虽然经过很多层后感受野的范围很大,但是仍然对于边界的感受能力弱
问题:感受野增大的效率很低,每次只添加K-1
解决方法:可以进行降采样,构建特征金字塔(Hierarchy)
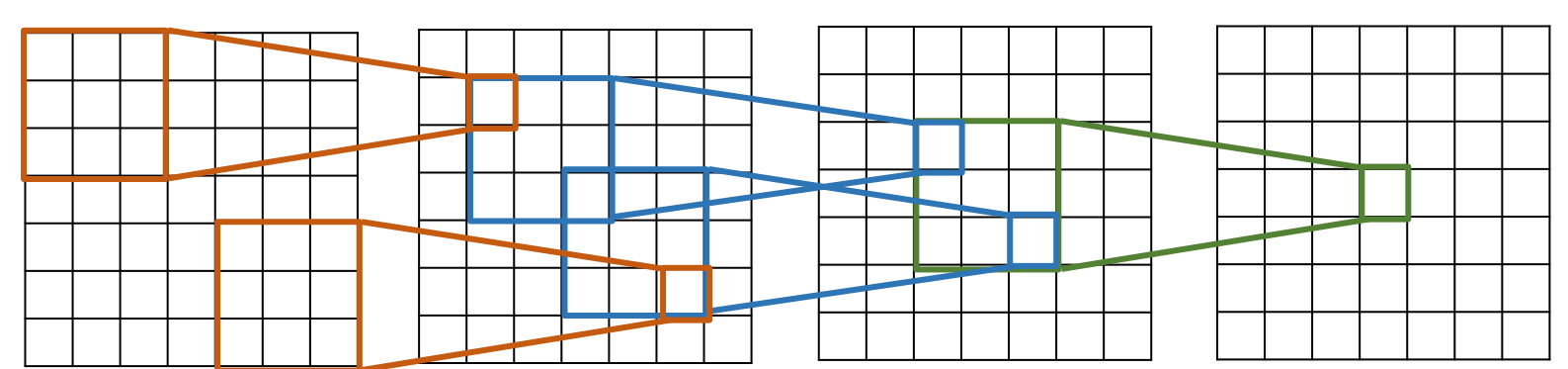
Pooling Layer
- 特征金字塔(Hierarchy):池化层在每个通道中独立地对特征进行空间下采样,生成不同分辨率的要素
上面池化层的 kernel size 和 stride 都是 2,这是常见的设置,尽管也可以使用其他 kernel sizes 和 stride,stride是步长
下采样也可以先进行平滑(高斯模糊)
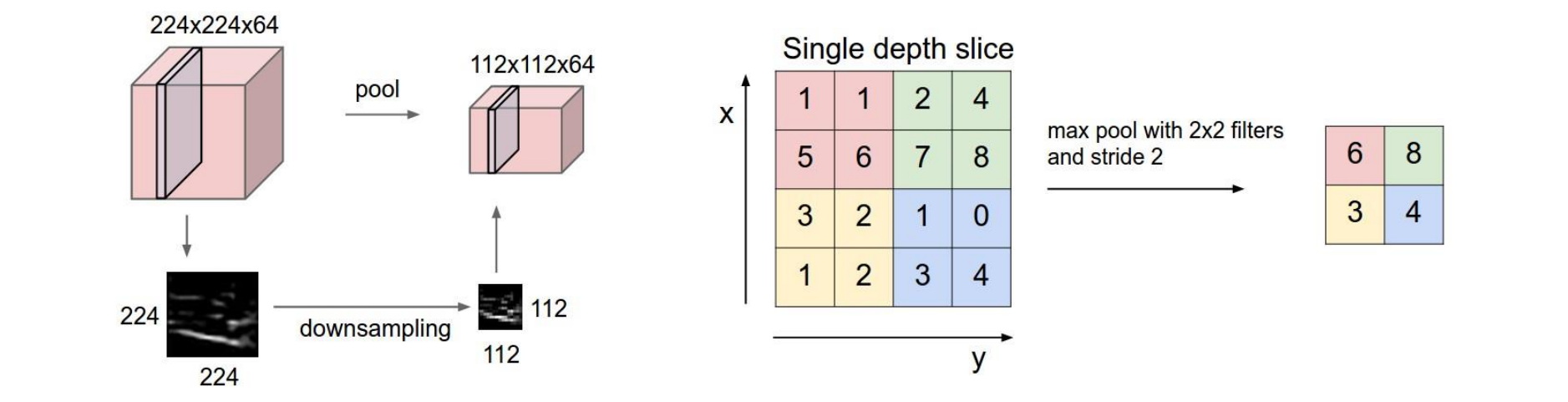
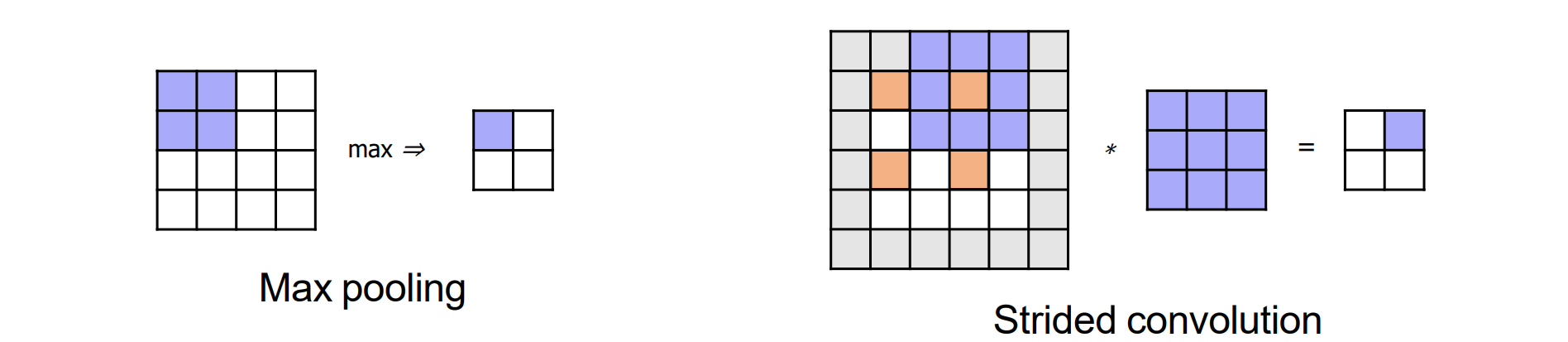
#1:合并MAX/AVGpooling以聚合信息
#2:以 >1(步幅) 的增量在图像上滑动卷积滤波
Grouped Convolution
对于较大的输入/输出通道,kernels(Cout,Cin,KH,KW)仍然有大量的参数,可能导致过拟合 + 计算慢
Grouped convolution:output 中的通道组仅取决于 Input 中相应的通道组
Depthwise convolution(深度卷积):组数等于通道数,缺点是通道之间无交互

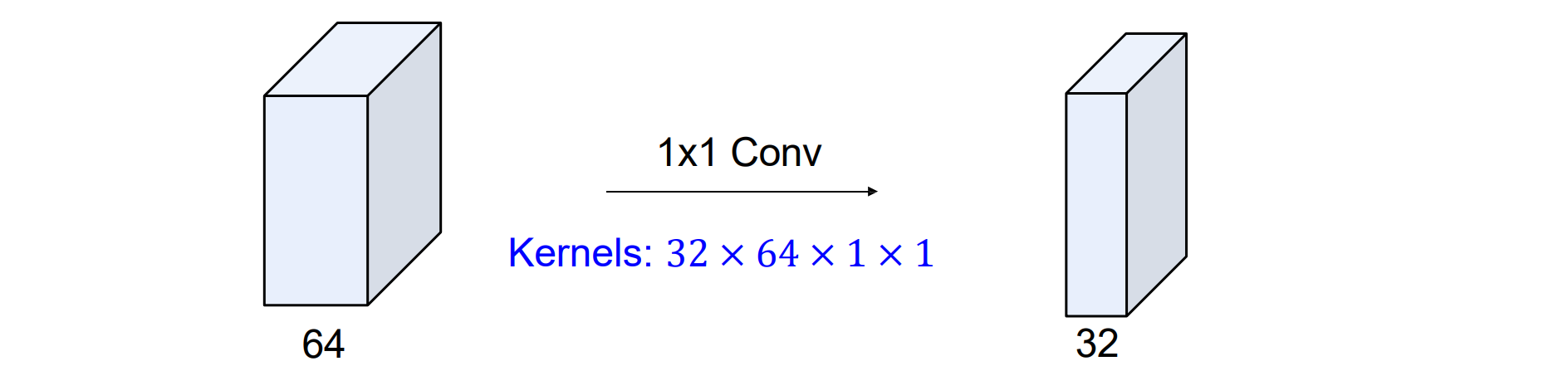
- Point-wise Convolution:也称为1x1convolution,通道间交互
Atrous / Dilated Convolution(空洞卷积)
空洞卷积可以避免进行降采样操作
空洞卷积可以获得更大的感受野
运用空洞卷积,则获取相同大小的图像需要添加更多填充

PyTorch Convolution Layers
- Conv2d:
1 | torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, dilation = 1, groups = 1, bias = True, padding_mode = 'zeros') |
- Conv1d:
1 | torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, dilation = 1, groups = 1, bias = True, padding_mode = 'zeros') |
- Conv3d:
1 | torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride = 1, padding = 0, dilation = 1, groups = 1, bias = True, padding_mode = 'zeros') |
参数大小计算
Convolution
input: N x Cin x H x W
超参数:
- Kernel size: KH x KW
- Number filters: Cout
- Padding: P
- Stride: S
Kernel: Cout x Cin x KH x KW
Bias vector: Cout
Output size: N x Cout x H’ x W’:
- H’ = (H – K + 2P) / S + 1
- W’ = (W – K + 2P) / S + 1
Pooling
input: C x H x W
超参数:
- Kernel size: KH x KW
- Padding: P
- Stride: S
Pooling function (max, avg)
Output: C x H’ x W’
- H’ = (H – K) / S + 1
- W’ = (W – K) / S + 1
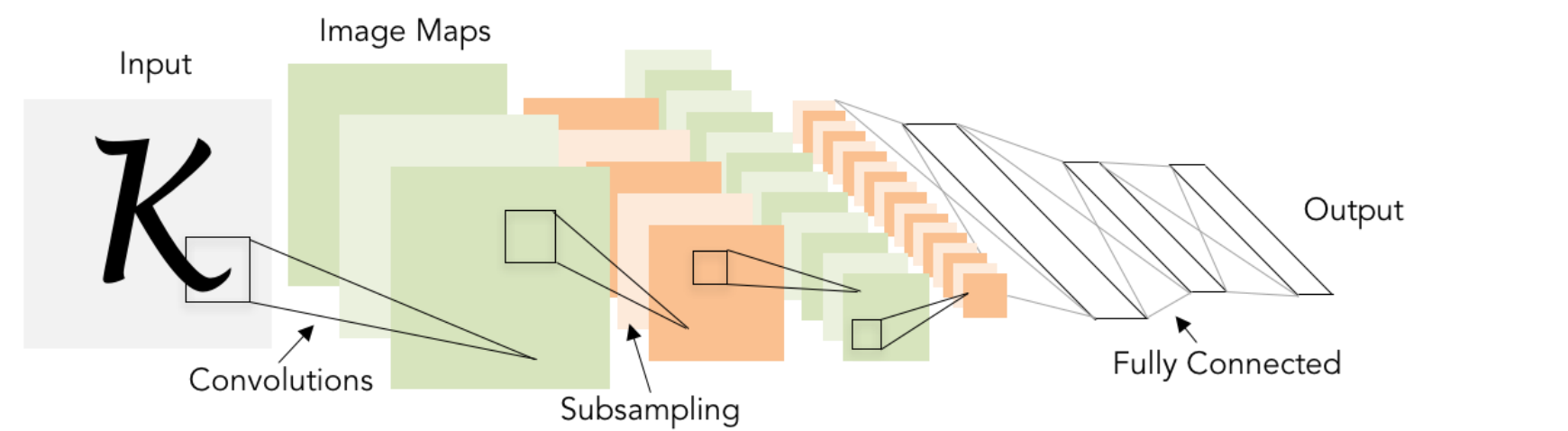
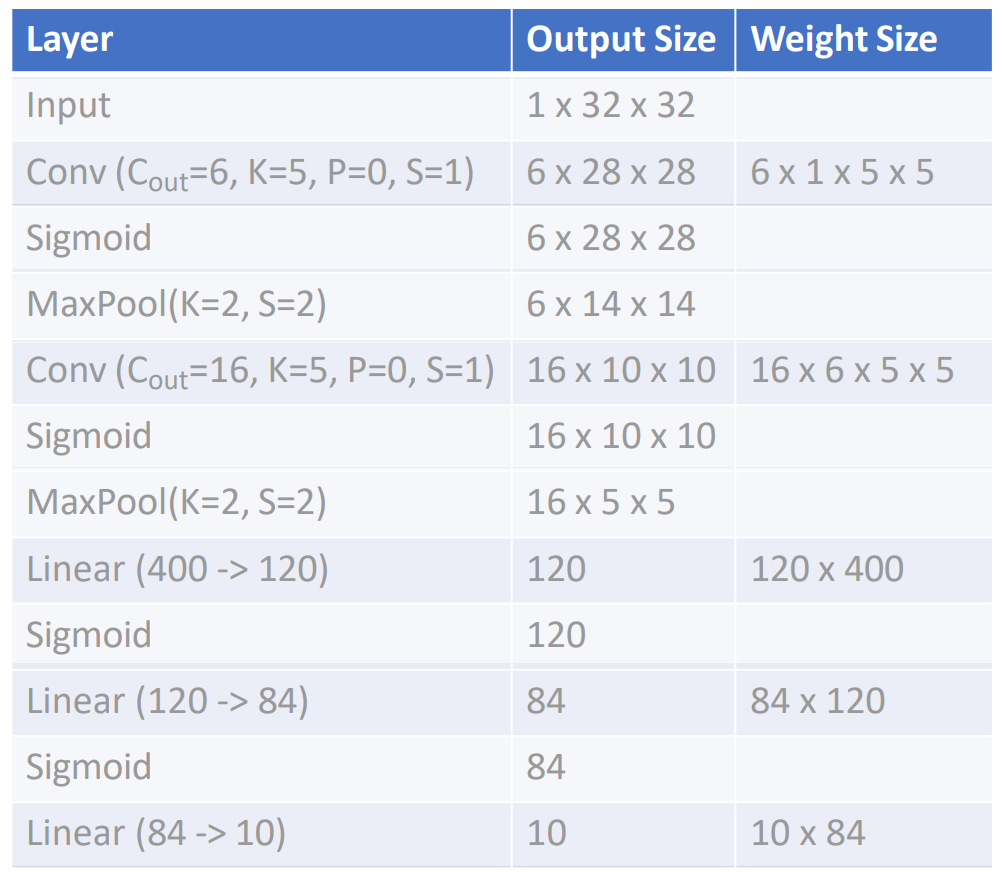
Convolutional Networks: LeNet-5
- 网络结构:[Conv, Sigmoid, Pool] x 2, [FC, Sigmoid] x 2, FC
Deep Convolutional Neural Networks
AlexNet: Deep CNNs for ImageNet Classification
“Several tricks”: ReLU(1), data augmentation(2), dropout(3) → Deep CNNs
ReLU 加快了训练速度;数据增强和 dropout 减少过拟合
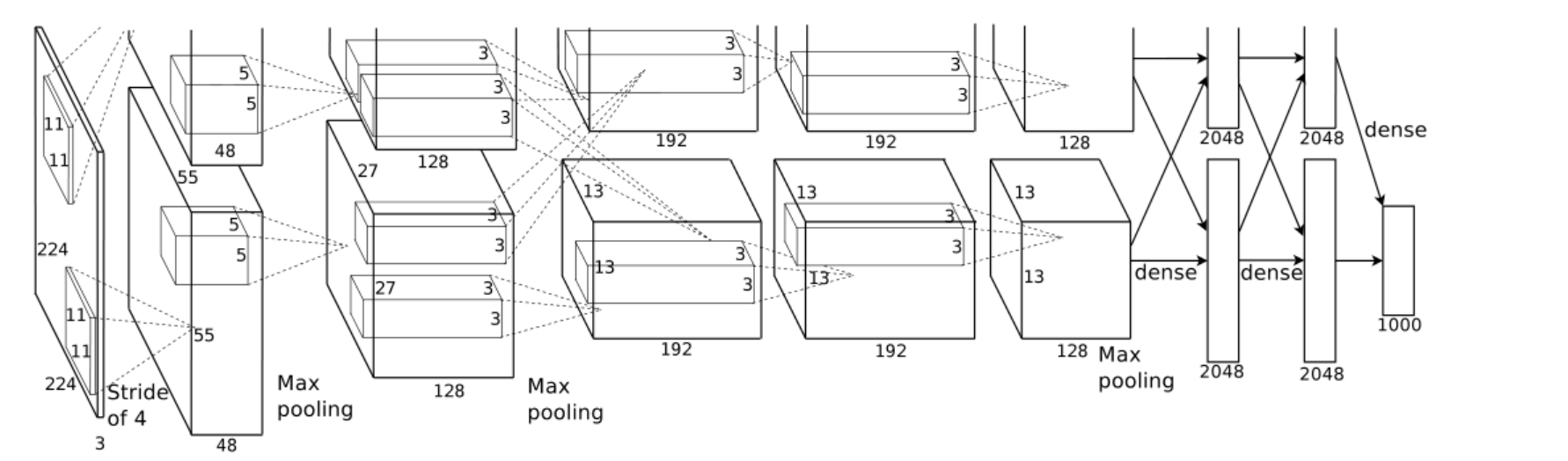
- deep:增加了3个卷积层;big:增加了很多可训练的参数
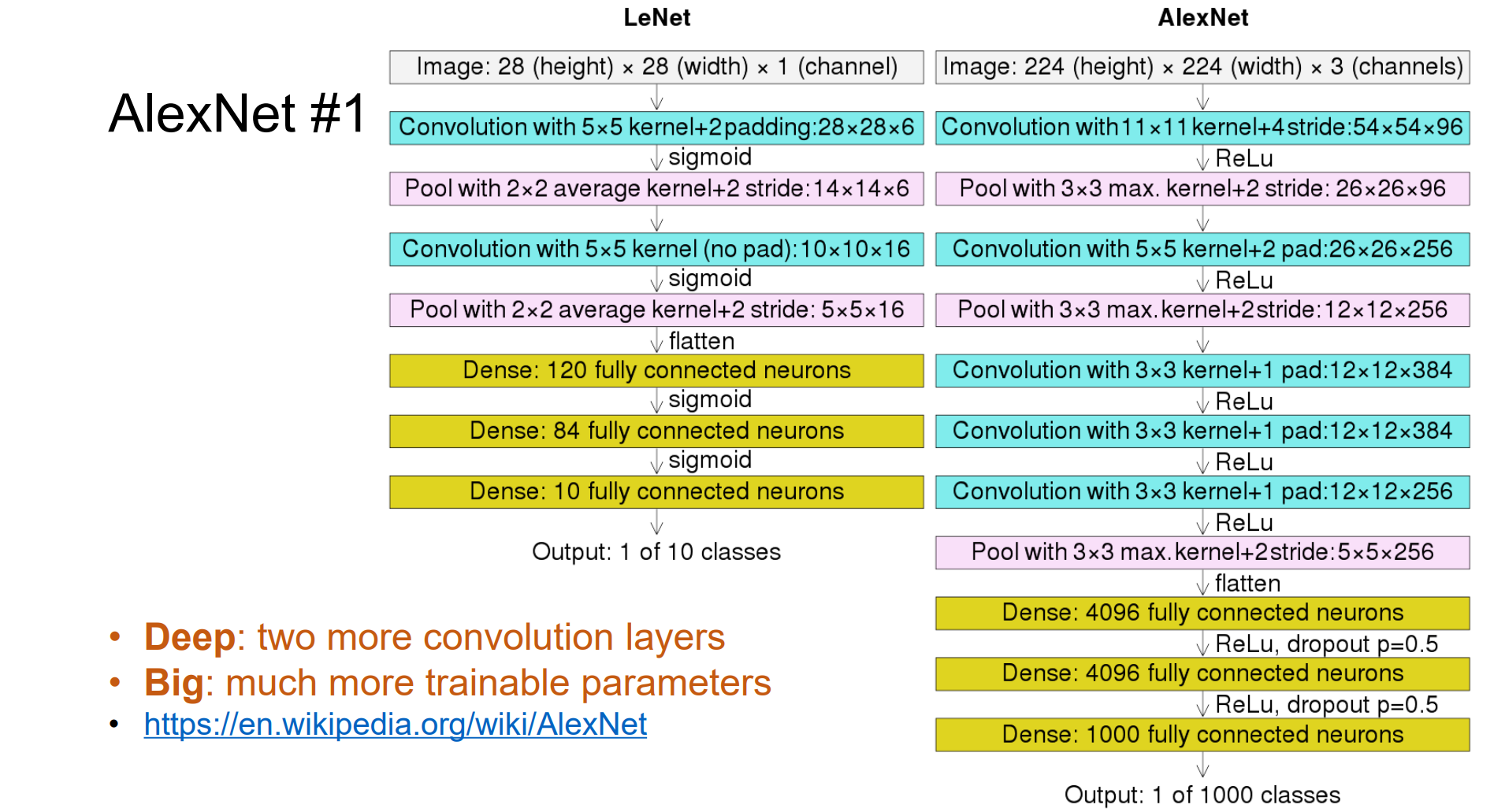
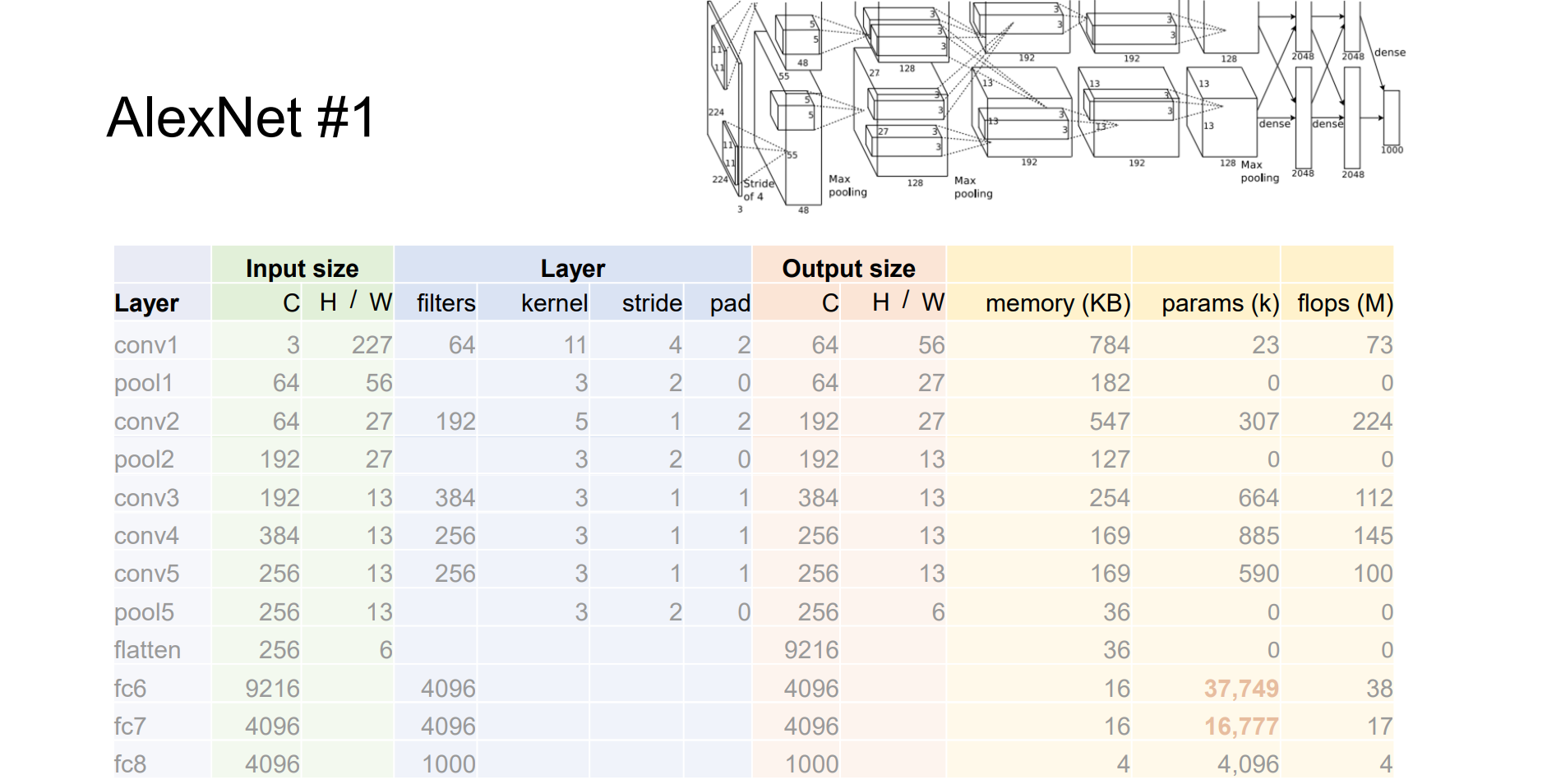
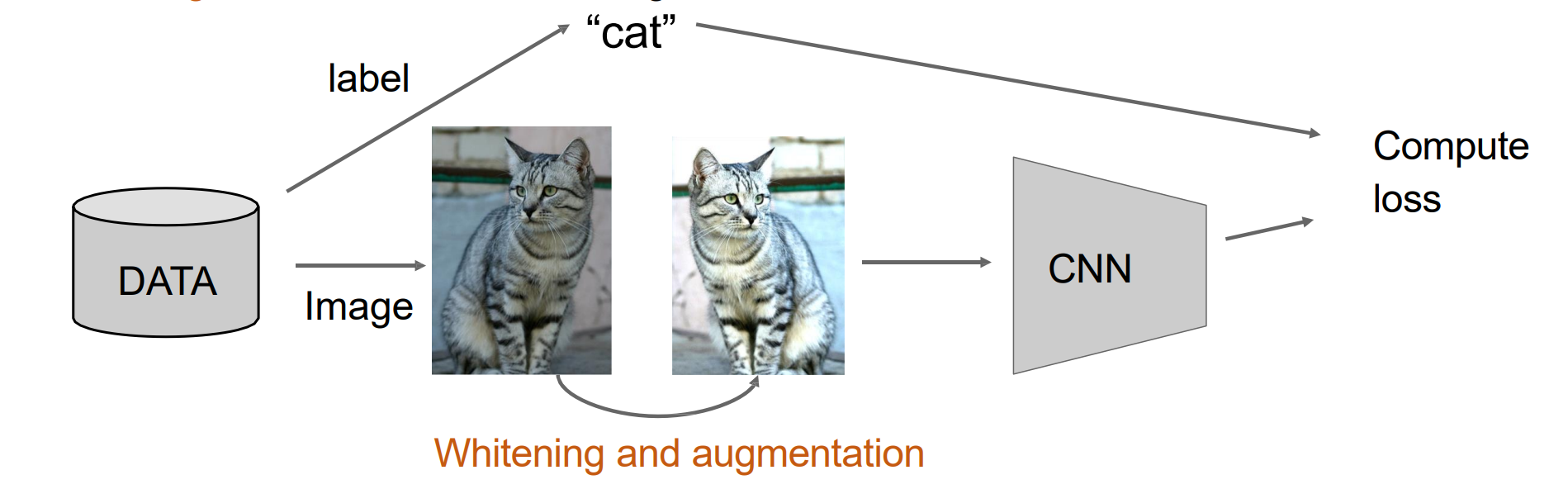
Image Whitening and Augmentation
Whitening:减去平均值并使用标准差进行归一化,使得特征重要性相同
Augmentation:使用随机变换变换图像
- Data Augmentation: Horizontal Flips

Data Augmentation: Random Crops and Scales
- PyTorch:torchvision.transforms.RandomResizedCrop
- 训练:裁剪图像的随机部分并将其调整为给定大小。用插值进行缩放,裁剪具有随机区域 (H * W) 和随机纵横比
- 测试:在图像中心裁剪部分
- 广泛用于训练深度神经网络
Data Augmentation: Color Jitter(随机更改图像的亮度、对比度、饱和度和色相)

- Regularization: CutOut
- 训练:将随机图像区域设置为 0 或随机值
- 测试:使用整个图像

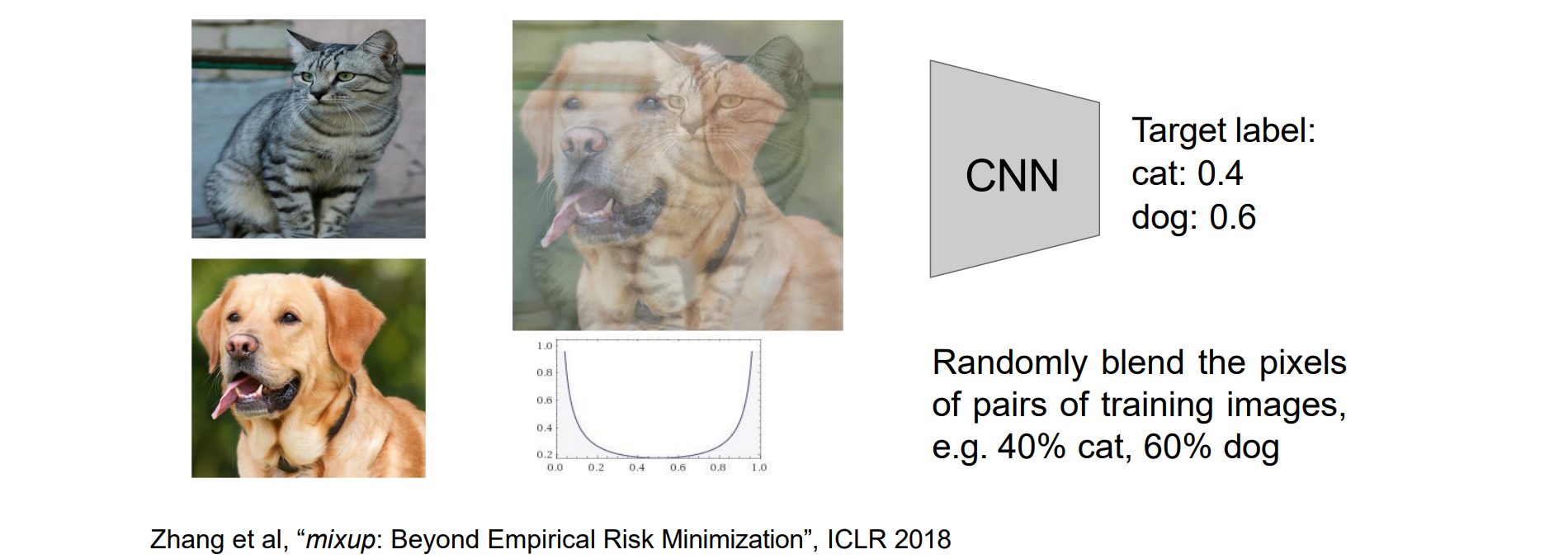
- Regularization: Mixup
- 训练:对图像的随机混合进行训练
- 测试:使用原始图像
- Regularization: CutMix
- 训练:对图像的随机混合进行训练
- 测试:使用原始图像

Dropout
加在全连接层中间,随机进行丢弃,形成稀疏链接可以避免过拟合,并提高模型的泛化能力
在测试期间,使用权重较小的整个网络
Example forward pass with a 3-layer network using dropout:

- 理解1:Dropout 强制网络阻止特征的协同适应,防止其互相迁就。给定若干个特征即可进行识别而非必须依赖全部特征
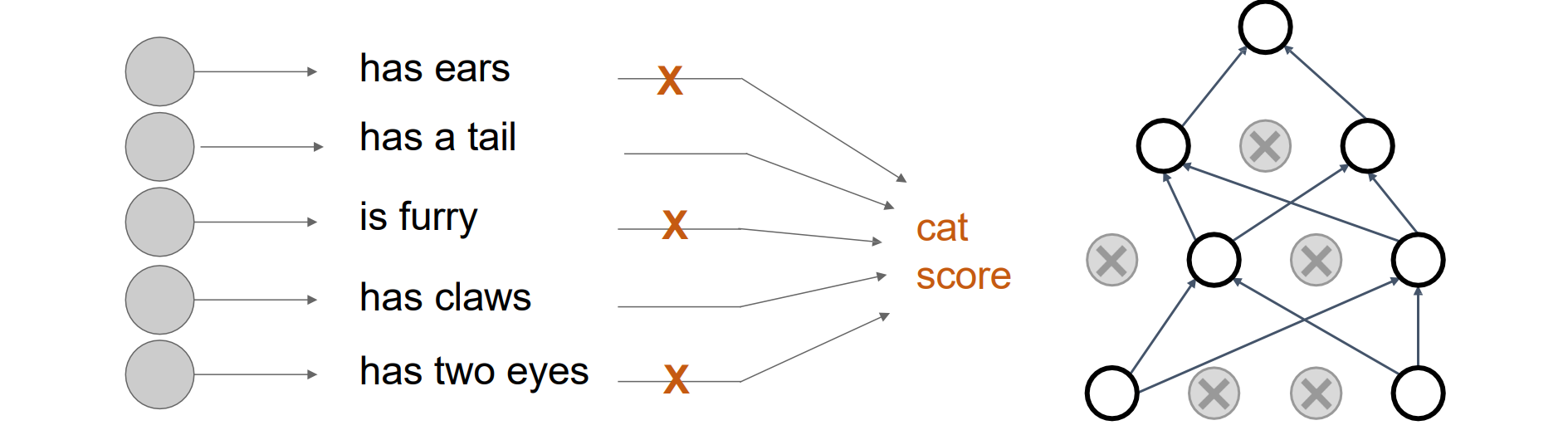
理解2:Dropout 正在训练共享参数的大型模型系综,通过mask一些神经元从而把大的模型变成小的多个神经网络一起训练;而在测试的时候所有神经元始终处于激活状态
问题:必须缩放激活,以便对于每个神经元:测试时的输出是训练时的预期输出
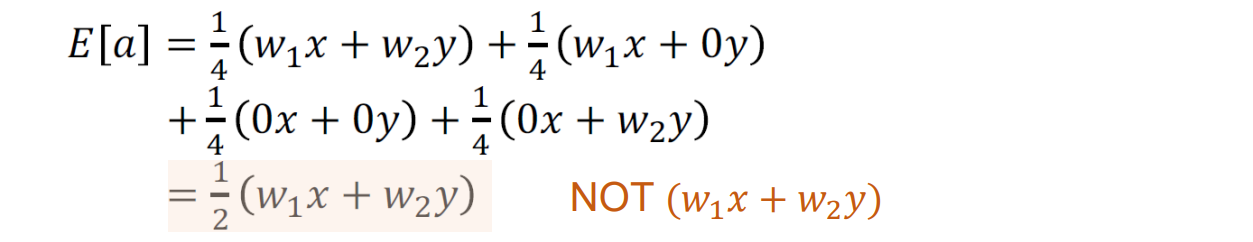
- 解决方法:训练的时候÷p,测试阶段的代码则不用修改

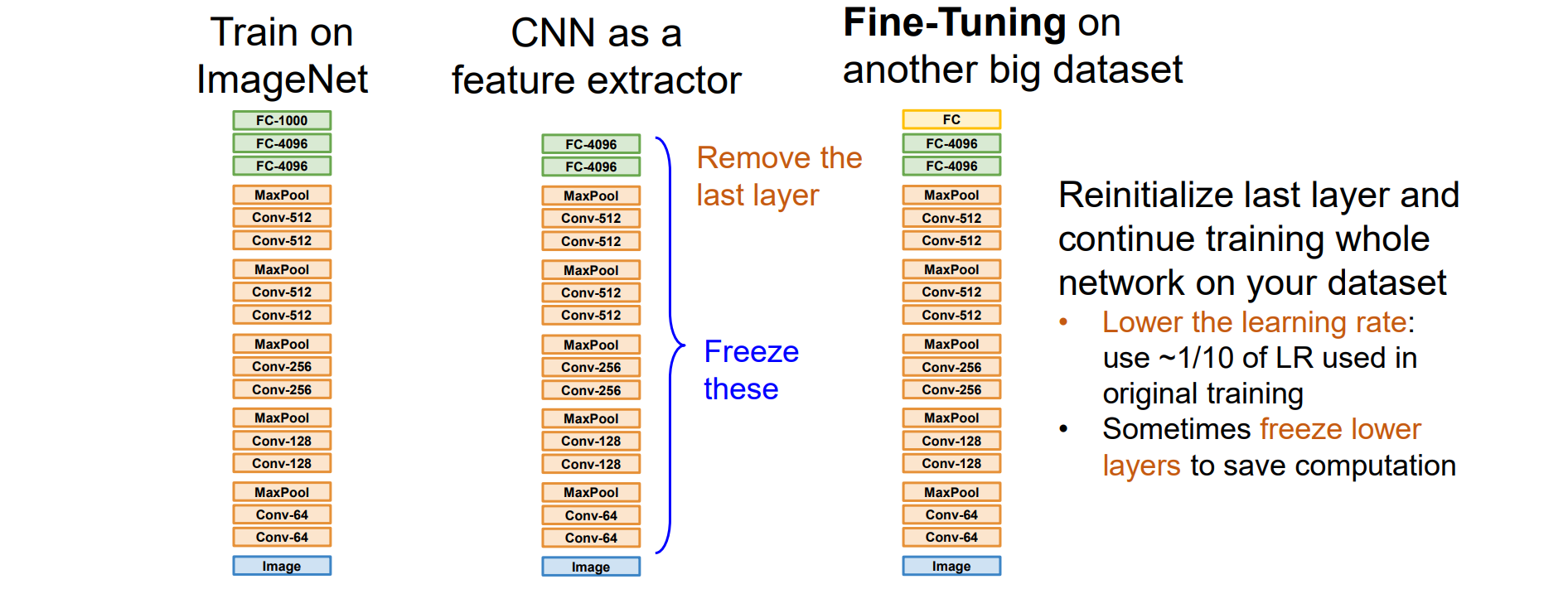
Transfer Learning: Feature Extraction
数据集不够的时候可以少训练一层,将CNN作为特征提取器后跟SVM,使用小型数据集在预训练的 CNN 特征之上训练线性分类器
重新初始化最后一层并继续在数据集上训练整个网络
- 降低学习率:使用原始训练中使用的 LR 的 ~1/10
- 有时冻结较低层以节省计算
- AlexNet:
1 | import torch |

